一种基于在线注意力神经网络的工业过程故障检测方法
本发明属于工业过程故障检测,涉及一种基于在线注意力神经网络的工业过程故障检测方法。
背景技术:
1、在这样的背景下,工业过程故障检测技术显得至关重要。随着工业工业控制系统的不断发展和传感器技术的广泛应用,大量数据可被实时获取,促进了基于深度学习的故障检测技术的广泛应用。
2、1drganomaly网络是工业过程监控领域的新型算法,2023年由deng提出。然而在过程监控中,1drganomaly网络对监控模型中的特征成分处理均衡,但在故障发生时,并非所有特征成分都能有效反映故障信息。某些特征对故障更为敏感,而其他特征可能保持正常状态,这可能导致含有故障信息的变量被其他变量掩盖。因此,如何通过在线检测过程中衡量特征的变化程度进而对敏感特征成分筛选,并对这些敏感特征进行差异化权重分配,是需要解决的关键问题。
技术实现思路
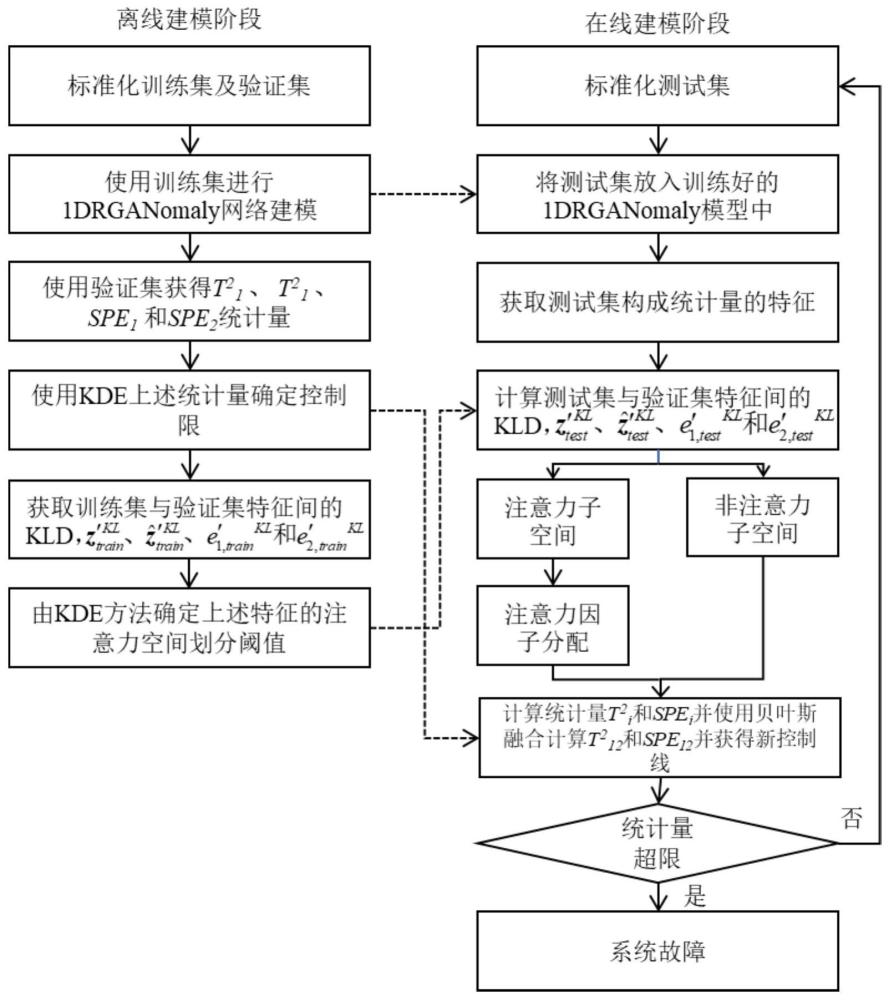
1、本发明针对1drganomaly网络对特征成分分配相同的权重,但当故障发生时,并非所有的特征成分都对故障敏感,容易导致这些故障敏感特征成分被掩盖的问题,提供一种基于在线注意力神经网络的工业过程故障检测方法。该方法设计了一种深度子空间划分和注意力因子分配策略,提出了一种基于在线注意力神经网络的工业过程故障检测方法,含有以下步骤:
2、(一)分别采集历史数据库中正常操作工况下的过程数据作为训练数据xtrain和验证数据xval,并利用训练数据xtrain的均值和标准差对训练数据xtrain和验证数据xval进行标准化处理,得到标准化后的训练数据xtrain′和验证数据xval′;
3、(二)使用训练数据xtrain′利用梯度下降方法构建1drganomaly网络,将训练数据xtrain′输入1drganomaly网络,获取深度特征ztrain和与残差特征e1,train和e2,train;
4、(三)将验证数据xval′输入步骤(二)所得到的1drganomaly网络,可获取深度特征zval和与残差特征e1,val和e2,val,计算相应统计量t12、spe1和spe2统计量,给定置信水平α,通过核密度估计方法计算统计量t12所对应的控制限所对应的控制限统计量spe1所对应的控制限spe1,lim和统计量spe2所对应的控制限spe2,lim;
5、(四)采用滑动窗分别计算训练数据xtrain′特征ztrain、e1,train和e2,train与验证数据xval′特征zval、e1,val和e2,val间的kl散度和给定置信水平β使用核密度估计方法确定特征间的注意力空间划分阈值和
6、(五)采集测试数据xtest,利用训练数据xtrain的均值和标准差对测试数据xtest进行标准化处理,得到标准化后的测试数据xtest′,将xtest′输入1drganomaly网络,获取深度特征ztest和与残差特征e1,test和e2,test;
7、(六)采用滑动窗分别计算测试数据xtest′的特征ztest、e1,test和e2,test与验证数据xval′的特征zval、e1,val和e2,val间的kl散度通过注意力空间划分阈值和分别将ztest、e1,test和e2,test特征分别划分到注意力空间和非注意力空间;
8、(七)在注意力空间和非注意力空间中,依据测试数据特征相对验证数据特征的变化,对测试数据特征赋予不同的权值,计算加权后的特征;
9、(八)由特征和计算对应新的统计量spe1,t和spe2,t,给定置信水平γ,使用贝叶斯融合获取在线注意力1drganomaly网络的统计量和spe12,t与控制限和spelim,若任意统计量超限,则判断测试数据xtest′发生故障。
10、进一步的,所述步骤(一)中,训练数据xtrain进行标准化处理,具体过程为:
11、利用训练数据xtrain的均值和标准差通过公式(1)对训练数据xtrain进行标准化处理,公式(1)的表达式为:
12、
13、训练数据xtrain经上述公式(1)标准化化处理后即可获得标准化后的训练数据xtrain′。
14、利用训练数据xtrain的均值和标准差通过公式(2)对验证数据xval进行标准化处理,公式(2)的表达式为:
15、
16、验证数据xval经上述公式(2)标准化化处理后即可获得标准化后的验证数据xval′。
17、进一步的,所述步骤(二)中,用公式(3)和(4)计算1drganomaly网络的中的生成器损失函数ld-net和判别的损失函数lg-net,待两个网络的损失函数完全收敛后保存各自的训练权重。
18、minld-net=ladv (3)
19、minlg-net=λ1lcon+λ2lenc+λ3ladv (4)
20、式中λ1、λ2和λ3分别是输入重构损失lcon、编码器重构损失lenc和对抗损失ladv的系数。lcon、lenc和ladv由公式(5)-(7)所示为:
21、
22、
23、
24、式中z为编码器1的输出,为编码器2的输出,x为输入,为解码器的输出,f(·)为判别的器输出。
25、将训练数据xtrain输入1drganomaly网络后即可获得深度特征ztrain和与残差特征e1,train和e2,train,其中
26、进一步的,步骤(三)中,将验证数据xval′输入1drganomaly网络,可获取深度特征zval和与残差特征e1,val和e2,val,其中依据特征zval、e1,val和e2,val,由公式(8)-(11)分别构造统计量t12、spe1和spe2统计量,公式(8)-(11)的表达式为:
27、
28、
29、
30、spe2=||e1,val||1 (11)
31、式中,σ1和σ2分别为ztrain和的协方差矩阵,||·||1和||·||2分别表示曼哈顿距离和欧几里德距离。
32、给定置信水平α,通过核密度估计方法计算统计量t12所对应的控制限所对应的控制限统计量spe1所对应的控制限spe1,lim和统计量spe2所对应的控制限spe2,lim。
33、进一步的,步骤(四)中,以特征z为例,特征ztrain与特征zval之间的kl散度计算公式入公式(12)所示:
34、
35、式中,其中代表t时刻特征ztrain第i个分量的kl散度,μi、σi为特征zval的第i个分量对应的均值和方差,为t时刻特征ztrain第i个分量对应的均值和方差。和可以通过滑动窗技术计算,由公式(13)和(14)所示:
36、
37、
38、式中,w表示滑动窗的宽度。
39、由此可获得ztrain与zval间的kl散度其中同理,可获得与间的kl散度e1,train与e1,val间的kl散度和e2,train与e2,val间的kl散度其中,r为特征数,m为特征数。
40、给定置信水平β,使用核密度估计方法可确定特征间的注意力空间划分阈值同理,可确定特征间的注意力空间划分阈值特征间的注意力空间划分阈值和特征间的注意力空间划分阈值
41、进一步的,步骤(五)中,利用训练数据xtrain的均值和标准差通过公式(15)对测试数据xtest进行标准化处理,公式(14)的表达式为:
42、
43、测试数据xtest经上述公式(15)标准化化处理后即可获得标准化后的测试数据xtest′。将测试数据xtest′输入1drganomaly网络,可获取深度特征ztest和与残差特征e1,test和e2,test。
44、进一步的,步骤(六)中,以特征z为例,特征ztest与特征zval之间的kl散度计算公式入公式(16)所示:
45、
46、式中,其中代表t时刻特征ztest第i个分量的kl散度,μi、σi为特征zval的第i个分量对应的均值和方差,为t时刻特征ztest第i个分量对应的均值和方差。和可以通过滑动窗技术计算,参见公式(13)和(14)。由此可获得ztest与zval间的kl散度其中同理,可获得与间的kl散度e1,test与e1,val间的kl散度和e2,test与e2,val间的kl散度其中,r为特征数,m为特征数。
47、以特征ztest为例,将与注意力空间划分阈值进行对比,若当大于阈值时可将ztest,t,i为注意力子空间,当小于等于阈值时可将ztest,t,i划分为非注意力子空间。同理,可将特征e1,test和e2,test进行注意力空间划分。
48、进一步的,步骤(七)中,以特征z为例,依据相对于的变化对特征ztest赋予权重wz,test,具体内容如下:
49、特征z的注意力权重设计公式如式(17)所示。
50、
51、式中,wz,t,i表示t时刻特征z第i个分量的注意力因子,表示为t时刻特征z第i个分量的kl散度,为特征z第i个分量的注意力空间划分阈值,e为自然数。
52、如公式(18)所示通过将注意力权重wz,t,i与对应特征ztest,t,i进行点乘可获得对应的注意力特征
53、
54、同理,可以得到深度特征对应的自适应注意力特征及其残差特征和其中,r为深度特征个数,m为输入数据的特征个数。
55、进一步的,步骤(八)中,对应的统计量对应的统计量对应的统计量spe1,t和对应的统计量spe2,t计算公式如公式(19)到(22)所示:
56、
57、
58、
59、
60、式中,σ1和σ2分别为ztrain和的协方差矩阵,||·||1和||·||2分别表示曼哈顿距离和欧几里德距离。
61、对于每个子统计量,对于给定的测试向量x,后验故障概率和如公式(23)和(24)所示。
62、
63、
64、式中,和为故障的先验概率。和为故障条件下的条件概率。和为样本出现的概率,可由式(25)和(26)计算。
65、
66、
67、式中,和为先验正常概率。和为正常工况下出现的概率。先验的正常概率和故障概率可以从工艺知识中确定,通常将它们分别设置为置信水平γ和显著水平1-γ。
68、将所有统计量转换为故障概率后,通过贝叶斯推理机制构建全局监测统计量,如式(27)和(28)所示。
69、
70、
71、控制限和spelim即为置信水平γ,若任意统计量或spe12,t超限,即或spe12,t≥spelim则判断测试数据xtest′发生故障。
- 还没有人留言评论。精彩留言会获得点赞!