一种航天器多脉冲追击轨道智能优化方法
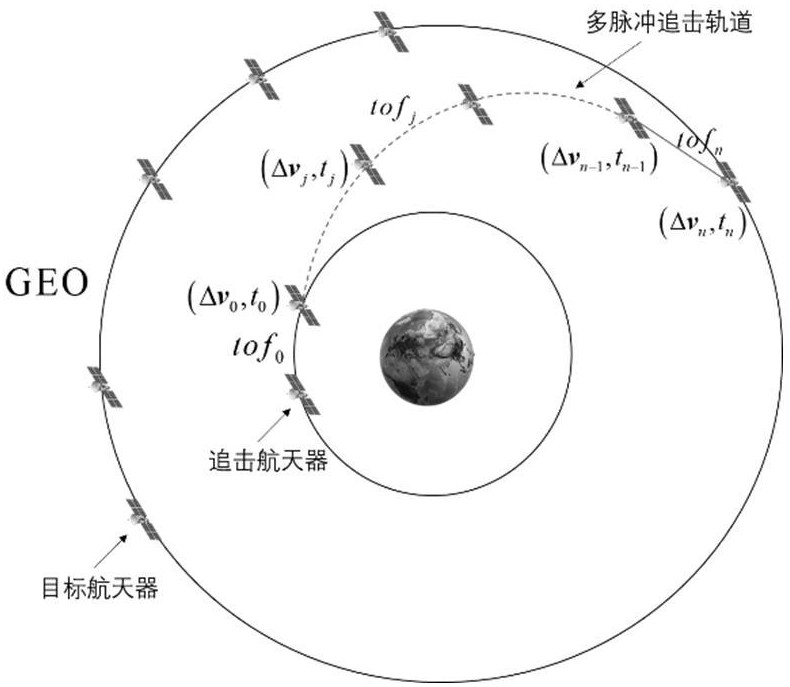
本发明属于新一代信息,具体涉及一种航天器多脉冲追击轨道智能优化方法。
背景技术:
1、轨道追逃是航天器轨道博弈的基础,诸如交会对接、在轨操控等任务皆可简化为不同末端约束的轨道追逃问题。考虑到目标航天器的非合作特性,追击航天器需要根据实时感知信息不断更新优化调整追击轨迹以应对目标的逃逸行为。因此,如何在高动态复杂环境下高效精准的求解给定初始状态的最优多脉冲追击轨迹是现阶段亟待解决的关键问题。
2、现阶段多脉冲轨迹优化方法可以分为三类:基于梯度计算的方法、启发式方法和人工智能方法。文献ellithy, a., abdelkhalik, o.,and englander, j. impact ofusing analytic derivatives in optimization for n-impulse orbit transferproblems ,journal of the astronautical sciences, 69, 218–250 (2022)中,将前n-1次脉冲作为设计变量,最后一段采用lambert算法,基于拉格朗日公式推导出了lambert问题的偏导数,从而推导出了n脉冲轨道转移问题的解析梯度。这种基于梯度的方法需要目标函数可微且连续,需要对动力学模型进行线性化简化以便于求解梯度信息,适用条件相对严苛。文献刁华飞,尚晓龙,王培等.高轨卫星远程抵近轨道优化研究,上海航天(中英文),2022,39(02): 15-23中,给出多脉冲抵近问题涉及的独立变量、约束条件和目标函数,建立了多脉冲抵近轨道优化设计的数学模型,并使用差分进化算法完成燃耗最优交会轨迹优化;这类启发式算法,不需要求解梯度信息,但优化过程涉及大量的迭代运算导致计算负担重,不利于在高动态复杂环境下快速规划追击航天器的追击轨迹。
3、基于人工智能的方法具体包括基于深度学习和基于强化学习两类。现有文献y. -h. zhu and y. -z. luo, fast approximation of optimal perturbed long-durationimpulsive transfers via artificial neural networks, ieee transactions onaerospace and electronic systems,57(2):1123-1138,2021中,通过分析多脉冲交会的最优速度增量随初始升交点赤经差和转移时间增加的变化规律,生成了“赤经渐近型”交会解、“赤经相交型”交会解和“赤经渐远型”交会解三个神经网络训练数据集,利用神经网路规划追击航天器的多脉冲交会轨迹。这类基于深度学习的方法需要生成大量的高质量训练数据样本集,且神经网络泛化能力较差,场景迁移能力不足。文献longwei xu, gangzhang, shi qiu, xibin cao, optimal multi-impulse linear rendezvous viareinforcement learning, space sci technol,2023,3:0047中,提出了一种基于强化学习的方法用于设计线性相对运动中的多脉冲交会轨迹,通过部署策略网络,可实现在线多脉冲交会轨迹求解。该方法虽然能够快速规划多脉冲交会轨迹,但收敛性能较差。综上所述,目前尚未有学者提出一种具有良好收敛性能的多脉冲交会轨迹快速优化方法,因此可以看出当前的技术任存在提高上升的空间。
技术实现思路
1、针对上述现有技术的不足,本发明的目的在于提供一种航天器多脉冲追击轨道智能优化方法,以解决现有技术中基于梯度方法中的梯度难以计算,基于数值优化方法需要多次迭代优化导致计算负担重,并克服了现有基于深度强化学习的多脉冲轨迹优化方法训练收敛性差、场景迁移能力不足等问题,实现了航天器多脉冲追击轨道的高效优化解算。
2、为达到上述目的,本发明采用的技术方案如下:
3、本发明的一种航天器多脉冲追击轨道智能优化方法,所述方法包括步骤如下:
4、步骤一:将航天器追击策略转化为多脉冲轨迹优化问题,建立针对固定脉冲次数的马尔可夫决策模型,包括定义基于追逃双方开普勒轨道根数的状态空间、转移时间拓展的四维动作空间以及基于lambert的多脉冲转移轨道状态演化模型;
5、步骤二:设计基于剩余交会速度增量的过程奖励函数和任务奖励函数,在所述任务奖励函数中引入标准值以改善训练的收敛性,所述标准值通过数值优化算法得到;
6、采用基于确定性策略梯度算法ddpg的深度强化学习方法对步骤一中所建立的马尔可夫决策模型进行训练,得到训练好的智能体;
7、步骤三:以追击航天器和目标航天器双方的初始轨道状态和任务周期作为所述智能体的输入,输出给定脉冲次数条件下追击航天器的最优脉冲机动信息,所述追击航天器的最优脉冲机动信息包括脉冲机动的速度增量矢量以及转移时间。
8、进一步的,所述步骤一具体包括:
9、s11,以目标航天器的轨道根数以及追击航天器与目标航天器之间轨道根数的差异定义马尔可夫状态空间:
10、;
11、s12,将脉冲施加时刻和速度增量作为优化变量,追击航天器每次的动作包括脉冲机动速度增量和时间窗口信息,所以马尔可夫决策模型的动作空间设计为包含施加脉冲后的转移时间tof和每次施加的速度增量的四维空间,如下式所示,其中速度增量矢量在球坐标下描述:
12、;
13、式中,为每次施加的速度增量,为脉冲矢量在追击航天器轨道坐标系下的投影与轨道坐标系轴的夹角,为脉冲矢量与追击航天器轨道坐标系中平面的夹角,则每一次追击航天器施加的脉冲矢量表示如下:
14、;
15、动作空间表示为:;
16、其中,为时间比例系数;
17、每一次施加脉冲机动动作后的转移时间表示为:
18、;
19、式中,表示施加第次脉冲机动时还剩余的总的任务时间;
20、s13,将轨道状态演化模型划分为:等待段、机动段以及lambert追击段;等待段为指追击航天器自初始轨道状态演化至第一次轨道机动时刻的过程,如下式所示:
21、;
22、式中,表示轨道积分函数,是等待段飞行时间,;
23、机动段是指追击航天器自第一次机动时刻到第次机动时刻的多脉冲转移过程,共施加次轨道机动动作;具体过程如下:首先,在机动时刻追击航天器速度突变,;然后对突变后的轨道状态进行递推至下一次机动时刻,重复上述操作直至第次机动时刻:
24、;
25、式中,为施加第j次机动时追击航天器的位置,为对突变后的轨道状态进行递推至下一次机动时刻航天器的位置,tofj为施加第j次机动后航天器的飞行时间;
26、lambert追击段是指追击航天器最后双脉冲交会目标过程,如下式所示:
27、;
28、式中,表示lambert求解函数,是追击航天器施加第次轨道机动动作后的末端位置,是追击航天器交会目标航天器的末端位置,是追击航天器交会目标航天器的末端速度,是lambert追击段飞行时间,和是通过求解lambert函数得到的追击航天器施加第n-2次轨道机动动作后的出发速度和末端速度,是追击航天器施加第n-1轨道机动动作前的速度矢量,是追击航天器施加第次轨道机动动作的速度增量矢量,是追击航天器施加第次轨道机动动作的速度增量矢量。
29、进一步的,所述过程奖励函数的设计如下:
30、;
31、式中,是将剩余任务时间进行离散化处理,通过循环求解追击航天器与目标航天器之间的lambert转移轨迹,得到最小交会速度所对应的最优转移时间;是初始等待时间奖赏权重系数,为速度奖赏权重系数,为末端lambert交会时间奖赏权重系数;为脉冲机动次数;为任务时间;为等待段飞行时间;表示末端时刻追逃双方之间的距离,为目标航天器的轨道半长轴;表示追击航天器不施加脉冲机动动作时,在无脉冲机动剩余任务时长内基于lambert双脉冲交会目标航天器所需要的速度增量,表达式如下:
32、;
33、式中,下标p、e分别代表追击航天器和目标航天器,表示施加第次机动前追击航天器的飞行时间,表示施加第次机动前目标航天器的位置速度,表示目标航天器轨道递推后的位置速度,表示追击航天器施加第次机动动作前的位置速度,和表示追击航天器进行双脉冲lambert转移的出发速度和末端速度;
34、过程奖励函数中的变量表示追击航天器以施加第次机动动作后的末端状态为起始轨道状态,在有脉冲机动剩余任务时长内基于lambert双脉冲交会目标航天器所需要的速度增量:
35、;
36、式中,下标p,e分别代表追击航天器和目标航天器,表示施加第次机动后追击航天器的飞行时间,表示施加第次机动动作后目标航天器的位置速度,表示追击航天器施加第次机动动作后的位置速度,表示目标航天器递推后的位置速度,和分别表示追击航天器进行双脉冲lambert转移的出发速度和末端速度;
37、lambert追击段的飞行时间由ddpg智能体的动作网络actor给出,如下式所示:
38、;
39、式中,为当前时刻航天器的状态,表示ddpg根据当前时刻航天器状态输出脉冲机动动作,表示施加第次脉冲机动速度增量时还剩余的总的任务时间。
40、进一步的,过程奖励函数中的变量是将剩余任务时间进行离散化处理,通过循环求解追击航天器与目标航天器之间的lambert转移轨迹,得到最小交会速度所对应的最优转移时间,有:
41、将有脉冲剩余任务时长以步长进行离散化处理,得到一组转移时间序列:;
42、;
43、式中,表示目标航天器当前时刻的位置速度,表示目标航天器递推时间后的位置速度,表示追击航天器施加第n-1次脉冲机动时的位置,是追击航天器以为转移时间求解lambert转移轨迹得到的出发速度和末端速度,将时间序列中的每一个元素代入上式,重复求解上式,得到每一个转移时间所解算的速度增量,从中选出最小值所对应的转移时间,该转移时间即为。
44、进一步的,所述任务奖励函数设置如下:
45、;
46、式中,为最优速度增量奖赏权重系数,为速度增量偏差惩罚权重系数,为常值参数;表示目标航天器交会追击航天器所需要的总的速度增量;是由数值优化算法得到的标准值,在固定脉冲机动次数下,已知任务时间,将追逃双方的初始轨道状态、输入数值优化算法,得到追击航天器次脉冲交会目标航天器所需要的总的最优速度增量:
47、;
48、式中,为数值优化算法;
49、若,则给予智能体成功奖励;反之,则给予智能体惩罚;
50、则,总的奖励函数为。
51、进一步的,采用基于确定性策略梯度算法的深度强化学习方法对步骤一中所建立的马尔可夫决策模型进行训练具体为:
52、首先初始化追击航天器的动作网络actor和策略网络critic;离线构造训练样本集作为actor网络的输入;actor网络输出当前时刻下的追击航天器的动作,智能体执行动作并观察环境的反馈,将反馈储存在经验池中;
53、在训练时,actor网络输出前次追击航天器的脉冲机动动作,包括速度增量矢量以及转移时间,追击航天器第次的脉冲转移时间通过actor网络输出,第次和第次的脉冲机动动作的速度增量矢量通过求解末端lambert转移轨迹得到:
54、;
55、式中,和是lambert追击段解得的速度增量矢量,ddpg输出如下:
56、;
57、式中,为当前时刻航天器的状态,表示ddpg根据当前时刻航天器状态输出脉冲机动动作;
58、随后从经验池中随机抽取若干数量的样本用于交替更新actor网络和critic网络直至达到最大训练代数,智能体训练完毕。
59、进一步的,所述步骤三具体包括:ddpg训练完备后,将追逃双方的初始轨道根数以及任务周期输入给ddpg智能体,ddpg通过已经训练好的动作网络actor直接输出追击航天器的最优脉冲机动信息,包括脉冲机动时间以及速度增量矢量,即表达式如下:
60、。
61、本发明的有益成果:
62、本发明建立了针对固定脉冲次数的马尔可夫决策模型,设计了基于剩余交会速度增量的过程奖励函数和基于最优速度增量的任务奖励函数,提升了ddpg训练的收敛性能,克服了场景迁移能力不足等问题,实现了航天器多脉冲追击轨道的高效优化解算。以脉冲次数代替深度强化学习中的传统时间步长从而建立了针对固定脉冲次数的马尔可夫决策模型,包括定义了基于追逃双方开普勒轨道根数的状态空间、转移时间拓展的四维动作空间以及包含等待段、机动段、lambert追击段的轨道状态演化模型;设计了基于剩余交会速度增量的过程奖励函数和基于标准值诱导的任务奖励函数,标准值是数值优化算法得到的最优速度增量;构造离线样本集,作为actor网络的输入,以加快ddpg智能体的训练速度;训练完备的智能体以追逃双方的初始轨道状态和任务周期为输入,输出给定脉冲次数条件下的最优脉冲机动信息。整体思路新颖,有较强的创新性和工程应用前景。
- 还没有人留言评论。精彩留言会获得点赞!