一种变外形飞行器智能模型预测控制系统及控制方法
本发明属于航空宇航科学与,具体涉及一种变外形飞行器智能模型预测控制系统及控制方法。
背景技术:
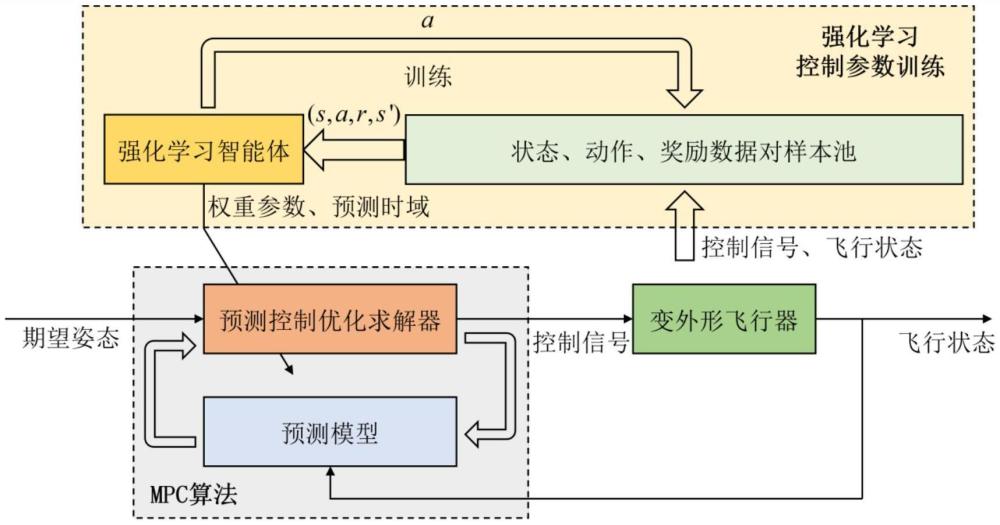
1、变外形飞行器外形改变会使飞行器的质量分布和气动参数发生显著变化,此外外部扰动以及变形时产生的惯性力和力矩会极大影响飞行器的稳定性,因此控制变外形飞行器的飞行姿态尤为重要。
2、传统飞行器控制方法主要包括pid、最优控制、增益调参、鲁棒控制等。其中pid控制方法结构简单,不依赖于精确的动态模型,具有较强的自适应性和鲁棒性。song等首次将pid控制引入到变外形飞行器控制系统中,并结合拉格朗日方程、伪逆控制、动态逆控制和经典pid方法,解决了滑动蒙皮机翼变形建模和控制问题。但pid控制器在可变形机翼多输入多输出(mimo)系统和强耦合系统条件下难以保持控制器的性能。
3、线性二次型调节器(lqr)控制是最优控制的一种,可以解决mimo问题,因此被应用于变外形飞行器控制系统设计中。filip svoboda等采用有限元法和以theodorsen函数为代表的非定常空气动力学方法对柔性变形机翼进行建模,并采用分布式lqr进行飞行控制,较好地抑制了可变形机翼的振颤抑制问题。
4、随着人工智能技术的发展,智能控制理论也逐步应用于控制领域。目前变外形飞行器控制系统的智能控制方法主要包括神经网络和强化学习两类。
5、神经网络控制指在控制系统中采用神经网络这一工具对难以精确描述的复杂的非线性对象进行建模,或充当控制器,或优化计算,或进行推理,或故障诊断等。
6、j lee等设计了一种基于反馈线性化的变外形飞行器的非线性控制与稳定性增强系统,采用两层前馈离线神经网络进行模型反演,且并不局限于特定变形方式的变外形飞行器,接着研究了几种神经网络结构和反向传播算法的组合,以避免过拟合现象,从而降低了整个系统对不确定性和噪声的敏感性。
7、在姿态控制研究方面,线性变参数方法将变体飞行器建模为以变形参数为变量的线性参变系统(linear parameter varying,lpv),通过适用于lpv系统的控制方法设计变体飞行器的全局控制器,能够很好地刻画某一调参变量对系统整体特性的影响。由于单一lpv控制器可能无法满足预期的性能指标,目前多采用切换lpv控制方法进行变体飞行器的控制系统分析。
8、对于平滑切换lpv控制,王青等考虑变体飞行器采用滑动蒙皮实现连续变形的特性,引入时变权重建立飞行器纵向运动链式平滑切换系统,进而结合有限时间稳定概念设计鲁棒控制器保证变形过程中的稳定。
9、由于变体飞行器飞行过程中气动参数会随飞行器的高度、马赫数和动压等的改变而发生变化,变体飞行器的数学模型参数也会随之而发生变化,仅靠一套飞行控制系统参数难以兼顾变体飞行器较大包线范围内的飞行品质,所以需要让控制器参数随高度、马赫数和动压的变化而变化,这就是增益调参的思想。其优点在于:在每个工作点附近都可以充分运用已经成熟的线性设计理论来设计控制器;系统能对调度参数的变化迅速作出反应,达到较为理想的性能指标。
10、殷明等在建立lpv模型的基础上,为保证变体过程的稳定,采用鲁棒增益调度控制方法设计了全局控制器,仿真结果表明所设计控制器能实现预期的运动过程,并保证变体过程的全局稳定。
11、当变体飞行器的非线性特性较强时,lpv方法不适用,需要采用非线性控制方法。目前应用于变体飞行器的非线性控制方法主要有滑模控制和抗扰动控制两类。
12、滑模控制(sliding mode control,smc)也叫变结构控制,本质上是一类特殊的非线性控制,且非线性表现为控制的不连续性。该方法可以在动态过程中,根据系统当前的状态有目的地不断变化,迫使系统按照预定“滑动模态”的状态轨迹运动。由于滑动模态可以进行设计且与对象参数及扰动无关,这就使得滑模控制具有快速响应、对应参数变化及扰动不灵敏等优点。nuan wen等将有限时间收敛滑模控制(fsmc)方法应用于线性时不变(lti)系统,设计成变体飞行器lpv系统,以线性矩阵不等式(lmi)约束的形式导出了降阶滑模存在的充分条件,证明了fsmc能够在有限时间内驱动lpv系统向预设的切换面运动,保证控制系统的稳定性和l2增益性能。
13、由于飞行环境的复杂,变体飞行器控制系统应该能够在存在内部不确定性和外部干扰的情况下稳定飞行。ligang gong等研究了变体飞行器纵向动力学的抗扰动控制问题,在建立非线性切换系统的基础上,通过所设计的扰动观测器实现对扰动的抑制,采用反步法对纵向运动模型的速度子系统和高度子系统分别设计了两个独立的控制器,并严格地证明了闭环系统的所有信号都受所提出的控制方案的约束。
14、对于强化学习控制方法,ligang gong等采用下三角形式的非线性切换系统来描述纵向高度运动,基础控制器基于扩展状态观测器的思想,设计了改进的干扰观测器来估计扰动,并结合径向基函数神经网络建立了常用的虚拟控制律,补充控制器基于强化学习设计,可以在线调整参数,进一步降低高度跟踪误差。
15、2017年,温暖等以一种抽象化的变外形飞行器为对象,给出其外形变化公式与最优外形函数等,并结合深度学习与确定性策略梯度强化学习,设计深度确定性策略梯度学习步骤,使飞行器经过训练学习后具有较高的自主性和环境适应性,提高其在战场上的生存、应变和攻击能力。
16、2019年,闫斌斌等基于强化学习理论,以变外形飞行器为研究对象提出一种新型的变外形飞行器翼型自适应控制方法,可以很好地满足变外形飞行器在多任务状态下保持最优性能的需要,设计的高度子系统的三回路法向过载控制器和速度子系统的滑模控制器可以确保飞行器在变体过程中保持稳定,但q函数和奖惩函数均与飞行状态无关,所得到的最优翼型变形策略也与飞行状态无关。
17、2020年,桑晨等基于ddpg算法,提出了变外形飞行器对称变形条件下的飞行控制方法,同时,考虑到非对称的变形条件下变形量等飞行状态对气动特性的影响,提出了一种新型主动姿态变化操纵机构。
18、(1)模型预测控制
19、模型预测控制(model predictive control,mpc)提出于上世纪70年代,已从最初在工业过程中应用的启发式控制算法发展成为一个具有丰富理论和实践内容的新的学科分支。预测控制在复杂工业过程中所取得的成功,已充分显现出其处理复杂约束优化控制问题的巨大潜力。
20、模型预测控制具有预测模型、滚动优化与滚动实施控制作用和反馈校正三大基本特征。
21、1)预测模型:预测模型功能是根据对象的历史信息和未来输入预测其未来输出。传递函数、状态方程、模糊模型、神经网络模型等都可以作为预测模型。因此,预测模型的准确性直接影响到模型预测控制的实际效果。
22、2)滚动优化与滚动实施控制作用:在算法理论研究和工业应用中,预测控制一般都是在线优化的。预测控制这种优化控制算法是通过某一性能指标的最优来确定未来的控制作用,与通常的最优控制算法有很大的差别,主要表现在优化不是采用一个不变的全局优化目标,而是滚动式的、通常是有限时域的优化策略。在每一个采样时刻,优化性能指标仅与未来有限时间相关,而到下一采样时刻,这一优化时域同时向前推移,该优化过程是反复在线进行的,即滚动优化。滚动实时控制作用表明滚动优化出的未来控制序列并不全都作用于对象,只有控制序列的前几步真实地作用于对象。这也是预测控制与其他控制的根本不同。该方法能够顾及模型时变、干扰等因素引起的不确定性,及时弥补。因此,滚动优化的有限时域的大小选取影响到预测控制的计算负荷和优化性能。
23、3)反馈校正:模型预测控制利用反馈提高闭环优化预测控制的性能。
24、综上所述,模型预测控制在处理复杂系统动态和多重约束方面具有优势,而飞行器的姿态控制则恰好有这些特点,因此模型预测控制在飞行器姿态控制领域具有应用价值。目前已有学者将模型预测控制应用到旋翼飞机、空天飞行器等对象的姿态控制器设计当中。
25、现有技术中存在如下缺陷:
26、一是,传统的模型预测控制通常需要构建一个简化的被控对象动力学模型以用于预测,并基于预测,在一定的约束条件下搜索控制最优解。但这种方法依赖于动力学模型的精度。为了提高控制性能,通常的做法是搭建更加复杂的动力学模型,或使用非线性的优化求解器。对变外形飞行器这一类复杂非线性系统而言,对其进行足够精确的建模是非常困难的,过于复杂的动力学模型和非线性优化必然带来过高的计算负荷和存储需求,导致这种方法难以进一步走向能大规模应用的低成本控制器。
27、二是,现有的智能控制方法通常基于机器学习算法,但机器学习的性能非常依赖于训练数据的数量,然而,在很多的应用领域难以获取大量有效的训练数据。同时,机器学习的很多方法被视为黑盒子,其性能难以被解释。一旦学习失败,机器学习通常难以保证安全,这种失效对于很多安全性要求比较高的工程应用是难以接受的。
技术实现思路
1、有鉴于此,本发明提供一种变外形飞行器智能模型预测控制系统及控制方法,能够实现变外形飞行器的精确控制。
2、实现本发明的技术方案如下:
3、第一方面,本技术实施例一种变外形飞行器智能模型预测控制系统,包括强化学习控制参数训练模块及模型预测控制算法模块;
4、强化学习控制参数训练模块,用于根据控制信号与变外形飞行器的飞行状态,获得控制量权重参数和预测时域,并输出至模型预测控制算法模块;
5、模型预测控制算法模块,根据所述权重参数、所述预测时域及期望姿态,生成执行机构动作控制序列,实现对变外形飞行器的控制。
6、进一步地,本发明所述强化学习控制参数训练模块的训练过程为:设置变外形飞行器动力学模块和判断模块,与强化学习控制参数训练模块和模型预测控制算法模块共同构成训练网络;
7、强化学习控制参数训练模块,用于根据控制信号与变外形飞行器的飞行状态,获得控制量权重参数和预测时域,并输出至模型预测控制算法模块;
8、模型预测控制算法模块,根据所述权重参数、所述预测时域及期望姿态,生成执行机构动作控制序列,输出至变外形飞行器动力学模块;
9、变外形飞行器动力学模块,用于根据所述执行机构动作控制序列预测变外形飞行器的下一时刻的状态;
10、判断模块,当所述下一时刻的状态满足设定要求时,结束本轮训练,否则将下一时刻的状态输出至强化学习控制参数训练模块,继续训练。
11、进一步地,本发明所述强化学习控制参数训练模块,通过设定强化学习控制参数训练模块的动作空间、状态空间及奖励函数训练获得,其中所述动作空间为:将强化学习控制参数训练模块的动作空间设计为离散动作,将预测时域和权重系数对角元素的值两两组合,共num(np)·num(rk)个离散动作,num(np)和num(rk)分别表示预测时域值可选择的个数和权重系数值可选择的个数。
12、进一步地,本发明所述状态空间包括飞行器状态的至少一种组合形式,所述飞行器状态包括:攻角α、侧滑角β、倾侧角σ、滚转角速度p、俯仰角速度q、偏航角速度r、攻角偏差量δα、侧滑角偏差量δβ、倾侧角偏差量δσ及变形量η。
13、进一步地,本发明所述强化学习的奖励函数有如下奖励值中任一组合形式构成:
14、飞行状态与预期姿态的偏差的奖励值(rα、rβ、rσ);飞行器姿态未偏离预期姿态设定阈值时的固定奖励值rs;飞行器的姿态发散导致控制终止时的负奖励值rd;舵偏角指令超过最大限幅时的负奖励值rp;舵偏角速度的总奖励值舵偏角加速度的总奖励值预测时域设计附加奖励值rnp。
15、进一步地,本发明所述舵偏角速度的总奖励值和所述舵偏角加速度的总奖励值为:
16、
17、式中,表示第i个舵面的偏转角速度奖励函数的设置参数,表示第i个舵面的偏转加速度奖励函数的设置参数,表示第i个舵面的偏转角速度;表示第i个舵面的偏转角加速度,为舵偏角速度的总奖励值,为舵偏角加速度的总奖励值。
18、进一步地,本发明所述预测时域设计附加奖励值rnp为:
19、
20、式中,np为预测时域,a为预设参数。
21、进一步地,本发明所述模型预测控制算法模块的离散预测模型的目标函数为:根据状态量权重、控制量权重及变形干扰权重进行设置,目标函数为:
22、
23、其中,q为状态量权重对角矩阵,r为控制量权重对角矩阵,np为预测时域,nc为控制时域,e(k+i)为第k+i时刻的预测状态量与第k+i时刻的期望值之间偏差、e′(k+i)为e(k+i)的转置,δν(k+i-1|k)为第k+i-1时刻的控制量与第k+i-2时刻的控制量之间的偏差,δν'(k+i-1|k)为δν(k+i-1|k)的转置。
24、进一步地,本发明所述强化学习控制参数训练模块的训练过程如下:
25、(1)设定强化学习控制参数训练模块的动作空间、状态空间及奖励函数;
26、(2)随机生成飞行器初始姿态和期望姿态,
27、(3)根据所述状态空间参数和动作空间,生成动作指令;基于所述动作指令计算出飞行器下一时刻的状态;
28、(4)利用奖励函数计算出当前状态采用当前动作的奖励值,并作为数据对存储在样本池中;若达到动作网格训练条件,则进入步骤(5),若达到episode终止条件,则返回步骤(2),若达到训练终止条件,根据当前得到的网格结构及参数,获取预测时域和权重系数,完成训练;
29、(5)从样本池中抽取样本数据,训练更新动作网络结构及参数,若达到episode终止条件,则返回步骤(2),若达到训练终止条件,根据当前得到的网格结构及参数,获取预测时域和权重系数,完成训练;否则返回步骤(3)。
30、第二方面,本技术实施例一种变外形飞行器智能模型预测控制方法,具体过程为:
31、步骤一,根据飞行器当前飞行状态和控制信号,强化学习控制参数训练模块生成预测时域及控制量权重参数;
32、步骤二,根据所述预测时域及控制量权重参数,模型预测控制算法模块计算飞行器执行机构动作控制序列,实现对变外形飞行器的控制。
33、第三方面,本技术实施例一种变外形飞行器智能模型预测控制方法,具体过程为:
34、第1步:根据飞行器当前飞行状态和控制信号,强化学习控制参数训练模块生成预测时域及控制量权重参数,转入步骤2;
35、第2步:预测时域、控制时域的值传入模型预测控制算法模块,模型预测控制算法模块计算飞行器执行机构动作控制序列,实现变外形飞行器的控制;
36、第3步:在执行机构动作序列传入真实的变外形飞行器后,获得下一时刻飞行器的状态,若满足控制精度要求,转入第4步,否则转入第1步,利用下一时刻的状态进行计算;
37、第4步:完成变外形飞行器姿态控制,算法结束。
38、有益效果:
39、第一,本发明结合模型预测控制和强化学习控制参数训练模块辅助控制的变外形飞行器姿态控制方法,能够实现对变外形飞行器的精确控制。
40、第二,本发明强化学习控制参数训练模块设计方法,在状态空间、动作空间、奖励函数设计时,全面考虑了变外形飞行器的要素,因此从而满足设计结果的可靠性。
- 还没有人留言评论。精彩留言会获得点赞!