鲁棒强化学习与对抗强化学习的无人机控制方法及装置
本发明涉及计算机,特别是指一种基于鲁棒强化学习与对抗强化学习的无人机控制方法及装置。
背景技术:
1、四旋翼无人机具有高机动、可悬停、结构简单等特点,在诸如军事、救灾、测绘、农业等很多领域已经取得广泛应用。考虑到现实环境中存在各种不确定因素,如外界风扰、环境变化、通信延迟等,要求无人机的控制器能够具备自主优化能力,以适应复杂的环境,而传统的控制方法在复杂情况下难以满足控制要求。近年来,深度强化学习在很多领域都取得了成功。深度强化学习是一种无需人工干涉,主动与环境交互,通过试错来学习的方法。将深度强化学习用于无人机控制可以让控制器具备自主优化能力,通过训练抵消扰动等系统不确定性,提高控制性能。
2、考虑到系统训练的成本和安全性,直接使用深度强化学习可能需要大量训练和试错,因此成本高风险大。需要利用已知的系统信息,结合具备基础控制能力的基础控制器,以在训练初期为系统提供基础的性能保证。考虑到现实环境中由于存在计算延迟、执行器延迟、通信延迟导致的输入延迟问题,传统的深度强化学习控制方法难以处理延迟问题,需要对深度强化学习方法进行改进,以抵消延迟带来的影响。此外,考虑到仿真环境中不确定性扰动的建模很可能与真实环境存在差别,导致训练好的控制器抗扰能力较差,不能满足真实环境下一些极端情况的控制性能。因此需要采用更加合理的训练方式,提高控制器的抗扰能力。
技术实现思路
1、为了解决现有技术存在的仿真环境中不确定性扰动的建模很可能与真实环境存在差别,导致训练好的控制器抗扰能力较差,不能满足真实环境下一些极端情况的控制性能的技术问题,本发明实施例提供了一种基于鲁棒强化学习与对抗强化学习的无人机控制方法及装置。所述技术方案如下:
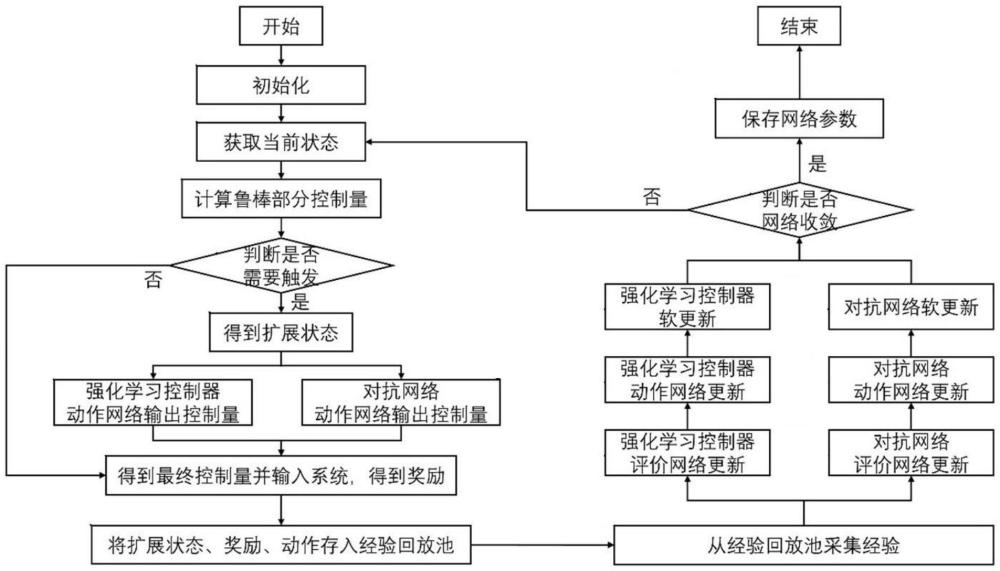
2、一方面,提供了一种基于鲁棒强化学习与对抗强化学习的无人机控制方法,方法包括:
3、s1、初始化无人机系统,获取无人机的当前状态;
4、s2、基于当前状态,计算无人机的鲁棒部分控制量,基于鲁棒部分控制量判断是否需要触发强化学习控制,若是,则进行鲁棒部分控制量的扩展,并通过强化学习控制器和对抗网络分别输出准确控制量;若否,则直接将鲁棒部分控制量作为准确控制量;
5、s3、将准确控制量输入至无人机系统,得到奖励;
6、s4、将奖励、动作以及准确控制量作为经验,对强化学习控制器和对抗网络进行更新,并判断强化学习控制器和对抗网络是否收敛,若否,则返回s2;若是,则保存网络参数,完成基于鲁棒强化学习与对抗强化学习的无人机控制。
7、可选地,s1中,初始化无人机系统,获取无人机的当前状态,包括:
8、初始化无人机的强化学习控制模块的评价网络和动作网络;
9、初始化鲁棒控制模块参数;
10、从环境中采集得到当前的状态x(t)。
11、可选地,s2中,基于当前状态,计算无人机的鲁棒部分控制量,基于鲁棒部分控制量判断是否需要触发强化学习控制,若是,则进行鲁棒部分控制量的扩展,并通过强化学习控制器和对抗网络分别输出准确控制量;若否,则直接将鲁棒部分控制量作为准确控制量,包括:
12、将当前状态x(t)输入到鲁棒控制模块,得到当前的鲁棒控制模块的控制量ur(t);
13、基于鲁棒部分控制量判断是否需要触发强化学习控制:
14、若是,则从动作缓存器中获得上一步的强化学习动作url(t-1),得到当前的扩展状态xe(t)=[x(t),url(t-1)];将当前的扩展状态xe(t)输入到强化学习控制模块的策略网络,得到当前的强化学习控制模块的动作url(t),并给动作url(t)增加正态分布噪声;将当前的扩展状态se(t)输入到对抗强化学习部分的策略网络,得到当前的对抗强化学习部分的输出danti(t),并添加正态分布噪声;获得准确控制量为u(t)=ur(t)+url(t);
15、若否,则直接将鲁棒部分控制量作为准确控制量。
16、可选地,触发的时间间隔为强化学习控制模块的控制周期,控制周期设为大于等于延迟时间。
17、可选地,s2还包括:
18、将对抗强化学习的输出danti(t)各个通道随机乘以1或者-1,使对抗扰动对称。
19、可选地,s3中,将准确控制量输入至无人机系统,得到奖励,包括:
20、将准确控制量输入至无人机系统;
21、从环境中采集得到下一步的状态为x(t+1),计算下一步的扩展状态为xe(t+1)=[x(t+1),url(t)],计算此时强化学习控制模块的即时奖励r(t)以及对抗强化学习的即时奖励ranti(t);
22、采集当前的扩展状态se(t),下一步的扩展状态xe(t+1),当前强化学习控制模块的动作url(t),对抗强化学习的输出danti(t),强化学习控制模块的即时奖励r(t)以及对抗强化学习的即时奖励ranti(t),存入经验回放池。
23、可选地,s3中,将奖励、动作以及准确控制量作为经验,对强化学习控制器和对抗网络进行更新,并判断强化学习控制器和对抗网络是否收敛,若否,则返回s2;若是,则保存网络参数,完成基于鲁棒强化学习与对抗强化学习的无人机控制,包括:
24、从经验回放池中采集一批将奖励、动作以及准确控制量作为经验,对强化学习控制器的评价网络、动作网络进行更新,对强化学习控制器的目标评价网络和目标动作网络进行软更新;对对抗网络的评价网络以及动作网络进行更新,对对抗网络的目标评价网络和目标动作网络进行软更新;
25、判断强化学习控制器和对抗网络是否收敛,若否,则返回s2;若是,则保存网络参数,完成基于鲁棒强化学习与对抗强化学习的无人机控制。
26、另一方面,提供了一种基于鲁棒强化学习与对抗强化学习的无人机控制装置,该装置应用于基于鲁棒强化学习与对抗强化学习的无人机控制方法,该装置包括:
27、初始化模块,用于初始化无人机系统,获取无人机的当前状态;
28、强化学习控制模块,用于基于当前状态,计算无人机的鲁棒部分控制量,基于鲁棒部分控制量判断是否需要触发强化学习控制,若是,则进行鲁棒部分控制量的扩展,并通过强化学习控制器和对抗网络分别输出准确控制量;若否,则直接将鲁棒部分控制量作为准确控制量;
29、经验回放模块,用于将准确控制量输入至无人机系统,得到奖励;
30、网络更新与控制模块,用于将奖励、动作以及准确控制量作为经验,对强化学习控制器和对抗网络进行更新,并判断强化学习控制器和对抗网络是否收敛,若否,则返回强化学习控制模块;若是,则保存网络参数,完成基于鲁棒强化学习与对抗强化学习的无人机控制。
31、另一方面,提供一种基于鲁棒强化学习与对抗强化学习的无人机控制设备,所述基于鲁棒强化学习与对抗强化学习的无人机控制设备包括:处理器;存储器,所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,实现如上述基于鲁棒强化学习与对抗强化学习的无人机控制方法中的任一项方法。
32、另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现上述基于鲁棒强化学习与对抗强化学习的无人机控制方法中的任一项方法。
33、本发明实施例提供的技术方案带来的有益效果至少包括:
34、本发明提供的方法本发明在控制器中使用鲁棒强化学习方法,可以通过不断迭代优化控制器,提高控制器性能,抵消外界扰动。同时也减少了训练时间开销,保证了训练前期的安全性。针对输入延迟问题改进了强化学习方法,通过扩展状态和扩展控制周期方法,在不显著增加计算复杂度的情况下,利用一步历史控制器信息来重构扩展状态,解决延迟问题。本发明使用对抗强化学习方法,对抗强化学习通过对目标策略进行攻击,降低目标的性能来与目标策略进行博弈。对于无人机系统来说,在训练前期这种零和博弈很可能因为扰动太大造成控制器失效。因此通过设计对抗网络的奖励函数,在训练的不同阶段对强化学习控制模块施加合适干扰,以提高强化学习控制模块的抗扰能力。
- 还没有人留言评论。精彩留言会获得点赞!