基于大数据的生物制药智能纯化工艺控制系统的制作方法
本发明创造涉及生物制药纯化领域,具体涉及一种基于大数据的生物制药智能纯化工艺控制系统。
背景技术:
1、近年来,生物制药行业快速发展,对纯化工艺的要求也越来越高。传统的纯化工艺主要依赖于操作人员的经验和一些简单的控制手段,这种方式在应对复杂的生产环境和不断变化的市场需求时显得力不从心。随着大数据和人工智能技术的迅猛发展,利用机器学习技术对生物制药纯化工艺进行控制变得可行且高效。通过对大量的历史数据和实时监测数据进行深入分析,机器学习算法能够准确预测生物制品的产量、纯度和质量,从而优化生产过程中的参数设置,提高整体生产效率和产品质量。该系统能够通过智能化的调整和优化,实现对生产过程中关键参数的精确控制。具体而言,机器学习算法可以捕捉到影响药物纯度和产量的各种关键因素,建立参数与纯化结果之间的关系模型,并在生产过程中实时监控和调整这些参数。这不仅能够确保在不同的生产条件下都能保持稳定高效的运行,还能够大幅度提高药物的纯度和生产效率,满足日益严格的质量要求。此外,系统还可以通过不断学习和更新数据,持续优化算法模型,适应生产工艺的变化。这种动态调整的能力使得系统在面对不同批次、不同条件的生产任务时,依然能够保持高水平的稳定性和可靠性。通过应用大数据和人工智能技术,生物制药行业的纯化工艺正在迈向更加智能化、精细化的未来。
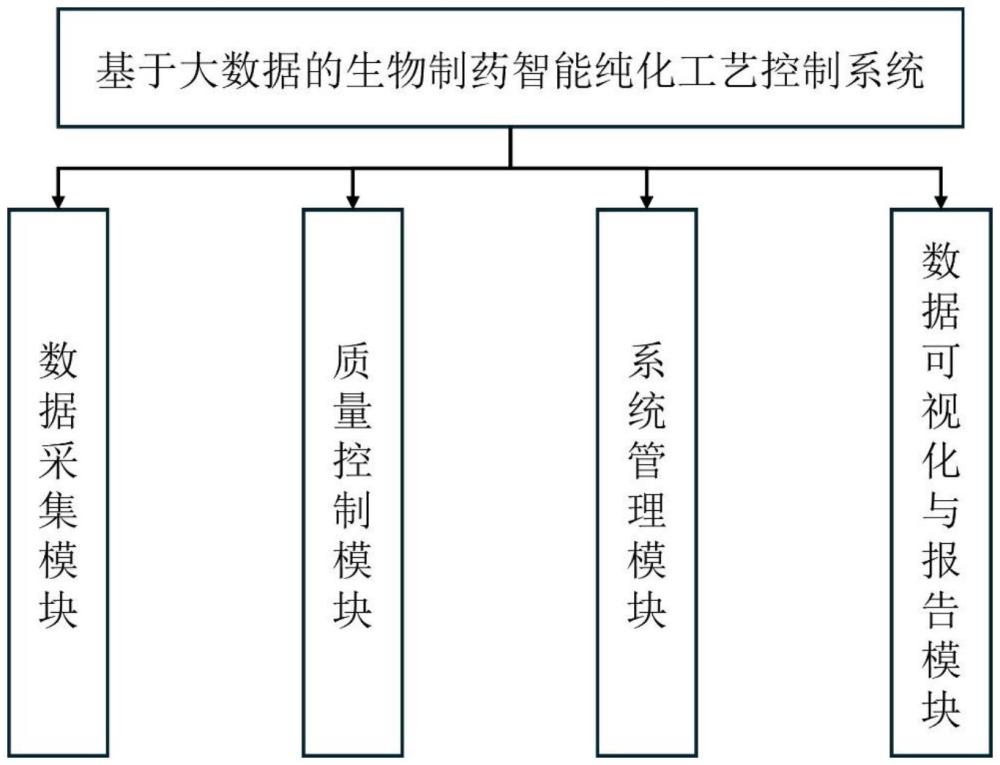
2、一种基于大数据的生物制药智能纯化工艺控制系统,该系统包括了数据采集模块、质量控制模块、系统管理模块、数据可视化与报告模块。其中质量控制模块提出了通过cnn-lstm算法提高系统纯化效果的技术。卷积神经网络(cnn)具有强大的特征提取能力,能够有效识别数据中的局部模式和结构。在生物制药纯化工艺中,关键参数(如温度、压力、流速、ph值、溶解氧含量等)的变化往往包含重要的特征信息。通过cnn,可以从这些数据中提取出有用的特征,为后续的预测提供高质量的输入。长短期记忆网络(lstm)擅长处理时间序列数据,能够捕捉数据中的长时间依赖关系。在生物制药纯化工艺中,生产过程中的参数变化往往具有时序性,过去的参数变化会影响到未来的生产结果。通过lstm,可以有效地预测这些时间序列数据的变化趋势,提高对生产过程的智能化控制和优化能力。将cnn的特征提取能力与lstm的时间序列预测能力结合起来,可以充分发挥两者的优势。在实际应用中,首先利用cnn从生产数据中提取特征,然后通过lstm对这些特征进行时间序列建模和预测。这样可以更准确地捕捉关键参数的变化规律,提高生产过程的预测准确性和控制效果。通过cnn-lstm网络,系统能够自动识别和调整关键参数,以优化生产条件,确保生产过程中的药物纯度和生产效率达到最佳状态。此外,cnn能够处理大量的复杂数据,提取出关键特征,减少数据的维度,提升数据处理效率。lstm能够捕捉长时间依赖关系,提供更准确的时间序列预测,帮助优化生产参数设置。系统可以实时监控生产过程中的关键参数,通过预测结果进行智能化调整,确保生产过程的稳定性和高效性。基于机器学习模型,系统可以在不同生产条件下进行优化调整,提高药物纯度和生产效率,满足日益严格的质量要求。通过引入cnn-lstm网络,本系统能够更好地识别和预测生产过程中的关键参数变化,实现对生物制药纯化工艺的智能化控制和优化。这样不仅提高了生产效率和产品质量,还增强了系统的稳定性和适应性,满足现代生物制药行业对高效、安全和高质量生产的需求。
技术实现思路
1、针对上述问题,本发明旨在提供一种基于大数据的生物制药智能纯化工艺控制系统。
2、本发明创造的目的通过以下技术方案实现:
3、一种基于大数据的生物制药智能纯化工艺控制系统,包括数据采集模块、质量控制模块、系统管理模块、数据可视化与报告模块,其中:
4、数据采集模块,用于使用传感技术采集生物制药纯化过程中的参数,并记录在控制系统中;质量控制模块有两个功能,首先将历史数据进行分组,其次,通过历史分组数据,利用机器学习算法建立控制工艺中的参数与药物纯度的函数关系,实现对生产过程的智能化调整和优化,提高药物纯度;系统管理模块,包括系统维护与监控功能和安全与权限控制功能,系统维护与监控功能起到监控系统性能和故障检测的作用,安全与权限控制功能起到用户身份验证和权限控制的作用;数据可视化与报告模块,提供直观的数据可视化界面,展示控制过程中的数据和分析结果,并生成分析报告。
5、进一步的,所述数据采集模块包括传感技术应用单元、实时数据采集单元、数据记录与存储单元、数据预处理单元、接口与通信单元,其中:传感技术应用单元,用于监测和采集生物制药纯化过程中的温度、压力、流速、ph值、溶解氧含量,传感器布置在纯化设备内部;实时数据采集单元,通过高速数据接口与数据采集模块相连,实现毫秒级的数据采集频率,并通过数据采集系统实时传输到中央控制系统;数据记录与存储单元,具备数据存储能力,对采集到的数据进行分类和存储,采用冗余存储技术,并定期备份数据;数据预处理单元,在数据采集过程中对数据进行预处理,包括去除噪声、异常值检测和数据校正,并标记时间戳;接口与通信单元,支持与质量控制模块、系统管理模块、数据可视化与报告模块进行对接,通过网络接口实现与远程服务器连接,对数据进行远程监控和分析。
6、进一步的,所述质量控制模块包括历史数据分组单元、机器学习算法单元、模型训练与更新单元、数据反馈与预警单元、用户定义参数设置单元,其中:历史数据分组单元,用于将历史数据根据温度、压力、流速、ph值、溶解氧含量特征(溶解氧含量为溶解于水中的氧气的含量,单位为mg/l)进行分组,以便于分析和比较生产结果,提供数据基础;机器学习算法单元,通过对历史分组数据进行分析,利用机器学习算法建立控制工艺中的特征与药物纯度之间的函数关系,能够捕捉数据特征的变化对药物纯度的影响;智能调整与优化单元,基于机器学习算法建立的模型,对生产过程进行实时监控和智能化调整,智能调整与优化单元能够自动识别和调整参数;模型训练与更新单元能够利用新数据不断改进和优化模型,适应生产工艺的变化,控制温度、压力、流速、ph值、溶解氧含量特征在预设范围内能精确预测生物药物的产量和纯度;数据反馈与预警单元,通过对实时数据的监测和分析,当发现生产过程中的参数出现异常和偏离预设范围时,系统能够及时发出预警并反馈给操作人员,确保能够迅速采取措施,避免生产事故和质量问题的发生;用户定义参数设置单元,允许用户根据需求调整参数设置,并通过机器学习算法的优化,结合历史数据和实时监测结果,提供个性化的参数优化方案,提高生产灵活性和效率。
7、进一步的,质量控制模块中的历史数据分组单元将系统中数据采集模块的数据从数据库中获取,模块读取历史数据集,历史数据自变量集记为x={x1,x2,x3,...,xp,...,xn},历史数据因变量集记为y={y1,y2,y3,...,yp,...,yn},其中xp,yp为提纯类型设计特征类型集合,x,y集合中的编号1,2,3,..,p,..,n别为历史数据中第1,2,3,..,p,...,n条数据,记为xp={xw1,xw2,xw3,xw4,xw5},其中,xw1为温度特征、xw2为压力特征、xw3为流速特征、xw4为ph值、xw5为溶解氧含量特征,将生物药物的纯化结果yp特征视为因变量集合,记为yp={yw1,yw2},其中,yw1为药物的纯度,yw2为药物产量,记为分类区间集合其中1,2,…,n1为分类区间的编号,m记为分组编号,k记为分类方式,为分类数据,在本系统中,使用经验公式分组、聚类分组、分类树分组三种进行分类,其中,经验公式的分组方法具体为:确定温度、压力、流速、ph值、溶解氧含量的具体范围,设置温度(t)的范围为tmin至tmax,其中tmin为纯化过程的最低温度,tmax为纯化过程的最高温度,设置压力(p)的范围为pmin至pmax,其中pmin为纯化过程的最低压力,pmax为纯化过程的最高压力,设置流速(f)的范围为fmin至fmax,其中fmin为纯化过程的最低流速,fmax为纯化过程的最高流速,设置ph值(ph)的范围为phmin至phmax,其中phmin为纯化过程的最低ph值,phmax为纯化过程的最高ph值,设置溶解氧含量(do)的范围为domin至domax,其中domin为纯化过程的最低溶解氧含量,domax为纯化过程的最高溶解氧含量,通过多项式拟合的启发式方法,建立经验公式s对纯度预测,并根据s由小到大对数据进行分组,共分为20组,记分组集合为gm1,其中m为分组编号,最大值为20,预测公式具体如下:
8、s=at·bp·cf+d(ph)+e(do)+r
9、其中,a、b、c、d、e、r为通过启发式算法拟合的参数,记聚类方法具体为将x集合中的每个元素xi,计算xi与分组中心μm的中心欧几里得距离,将xi分配给距离最近的分组,记gm2为第m个分组的集合,μm为m分组集合的中心点,μml为任一分组集合的中心点则:
10、
11、其中,对于gm2,计算更新的分组中心μm′:
12、
13、其中,为gm2集合中数元素个数,记分类树方法具体为梯度提升决策树算法,对于每个特征(温度、压力、流速、ph值、溶解氧含量)的数据有分类树模型:
14、f0(x)=arg minγ∑jle(yj,γ)
15、其中f0(x)为初始预测值,γ为叶子节点预测值,le为损失函数,fx为x集合中的预测值,rnj为模型预测残差,为f在上一步的预测值,
16、
17、并拟合一个新的决策树,为在输入为xj的决策树模型:
18、
19、hx为通过拟合模型得到的新决策树,更新模型,
20、fn(x)=fn-1(x)+0.1hx(x)
21、fn(x)为最新模型预测值,fn-1(x)为fn(x)前一步模型预测值,最终分类结果将分类方法的集合c={gmk,m∈{1,2,3,...o},k∈{1,2,3}},k中的1,2,3分别表示经验公式法,聚类法,分类树法,记o为第k类分类方式的分类组数,将c中的元素按照最小粒度进行分类,生成集合其中,1,2,...,n4为集合中元素的编号,为分组区间,其中1,2,...,n2为分类区间的编号,为分类数据,有
22、进一步的,质量控制模块中的机器学习算法单元包括输入层、cnn层、lstm层、全连接层,其中:输入层用于接收从历史数据分组单元传递过来的分组数据,cnn层:cnn层用于提取输入数据中的特征,通过卷积操作提取参数的局部特征,设定卷积核为w,卷积操作结果为h=f(w*x),其中f为cnn层激活函数,*为卷积运算;lstm网络层用于捕捉输入数据中的时序信息,lstm网络由状态单元、遗忘门、输入门、输出门组成:其中状态单元的功能为将遗忘门、输入门、输出门单元保存的信息进行传递,状态单元记为ct,状态单元ct通过前一个时间步的状态单元ct-1与该时刻的输入xt来更新,状态单元的更新方式为:其中ft为遗忘门的输出,表示遗忘的比例,it表示输入门,表示保留的新信息比例,表示新的候选记忆内容,遗忘门ft的输出决定了前一时间步的状态单元ct-1规定部分需要被遗忘,数学公式如下:ft=σ(wf·[ht-1,xt]+bf),其中,σ为sigmoid激活函数,输出值范围在0到1之间,wf为遗忘门的权重矩阵,bf为遗忘门的偏置向量,ht-1为前一时间步的隐藏状态,xt为当前时间步的输入,在lstm每一层添加层归一化,加快收敛速度并提高泛化能力,对于lstm网络的输入xt和隐藏状态ht-1,层归一化后的计算为:
23、
24、
25、其中,μ和σ分别表示均值和标准差,∈是一个常数防止除零,本发明通过自适应函数α(t)动态调整lstm门控单元的输出权重,提高模型的泛化能力,
26、
27、其中,t为制药周期,输入门it决定了当前时间步的输入xt需要被加入到状态单元ct中的部分,数学公式如下:it=σ(wi·[ht-1,xt]+bc),新的候选记忆内容ct=tanh(wc·[ht-1,xt]+bc)表示添加到状态单元中的新信息,数学公式如下:其中,tanh为双曲正切激活函数,输出值范围在-1到1之间,wi为输入门的权重矩阵,bi为输入门的偏置向量,wc为候选记忆内容的权重矩阵,bc为候选记忆内容的偏置向量;输出门ot的输出决定了当前时间步的隐藏状态ht包含多少部分的状态单元ct信息,数学公式如下:ot=σ(wo·[ht-1,xt]+bo)表示当前时间步的隐藏状态ht表示经过输出门过滤后的状态单元信息,数学公式如下:ht=ottanh(ct),其中,wo为输出门的权重矩阵,bo为输出门的偏置向量;设定lstm的输入为卷积层的输出h,通过lstm,得到输出h1=lstm(h);全连接层用于将卷积层输出的高维特征映射到预测结果,设定全连接层的权重为v,y=g(v·h1),其中g为全连接层激活函数,对于cnn-lstm网络,损失函数为l,权重矩阵为w,则l2正则化的损失函数表示为:
28、
29、其中,λ是正则化系数,θ为cnn-lstm模型学习率,为了动态调整cnn-lstm模型的学习率,cnn-lstm模型引入一种基于模型性能和历史梯度信息的自适应学习率调整算法,设梯度
30、
31、通过时间步t,计算损失函数l(θt)和梯度并使用指数平滑更新移动平均损失函数值lavg,t:
32、lavg,t=γlavg,t-1+(1-γ)l(θt)
33、计算梯度历史指数加权平均值:
34、ht=δht-1+(1-δ)gt2
35、更新学习率:
36、θt+1=θt-αtgt
37、其中,α为控制cnn-lstm模型学习率的参数,γ:控制移动平均损失函数值的平滑系数,本系统设置为0.9,δ:控制梯度历史影响的平滑系数,本系统设置为0.99,η:调节系数,用于控制学习率调整的敏感度。
38、进一步的所述系统管理模块包括系统维护与监控单元、安全与权限控制单元、数据备份与恢复单元、日志记录与审计单元、系统更新与升级单元、用户支持与帮助单元,其中:系统维护与监控单元,用于实时监控系统性能,进行故障检测和诊断,确保系统的稳定运行,系统维护与监控单元能够自动识别并修复故障,同时提供诊断报告,便于维护人员进行深入分析和处理;安全与权限控制单元,包括用户身份验证和权限控制,安全与权限控制单元能够确保系统数据的安全性,防止未经授权的访问和操作,通过权限设置,系统管理员定义和分配不同用户的操作权限,确保操作的合规性和安全性;数据备份与恢复单元,定期对系统数据进行备份,确保在发生数据丢失以及系统崩溃时,能够快速恢复数据,减少对生产的影响;日志记录与审计单元,记录系统的所有操作和事件日志,便于审计和追踪,日志记录与审计单元能够记录每个用户的操作行为,确保在出现问题时能够快速定位和解决;系统更新与升级单元,定期检查并更新系统软件,确保系统始终运行在最新版本,以获得最新的功能和安全补丁;用户支持与帮助单元,提供系统使用指南、技术问题解答和技术支持,帮助用户快速上手并解决使用过程中遇到的问题,提高用户体验和满意度。
39、进一步的,所述系统维护与监控单元构建了帕累托函数集合,帕累托函数集合包含了系统的cpu使用率、内存使用率、网络流量、错误日志、服务打分五类指标,存在个可用算力服务于本系统,帕累托函数集合pa表示为:
40、
41、其中cpu1为系统第1个算力的cpu使用率,memory1为系统第1个算力的内存使用率,stream1为系统第1个算力的网络流量,elog1系统第1个算力的错误日志,qos1为系统第1个算力的服务打分,cpu2为系统第2个算力的cpu使用率,memory2为系统第2个算力的内存使用率,stream2为系统第2个算力的网络流量,elog2系统第2个算力的错误日志,qos2为系统第2个算力的服务打分,为系统第个算力的cpu使用率,为系统第个算力的内存使用率,为系统第个算力的网络流量,系统第个算力的错误日志,为系统第个算力的服务打分,有:
42、pav=[cpuv memoryv streamv elogv qosv]
43、其中,pav为系统第v个算力的帕累托函数集合,cpuv为系统第v个算力的cpu使用率,memoryv为系统第v个算力的内存使用率,streamv为系统第v个算力的网络流量,elogv系统第v个算力的错误日志,qosv为系统第v个算力的服务打分,对进行特征变换,有:
44、
45、其中,为特征变换后的,构建帕累托函数最优集合pa*,有
46、
47、其中,indexa和indexb均为中的元素,temp和temp`为索引数,ftemp和ftemp`分别为第temp个目标函数和第temp`个目标函数,其中目标函数为:
48、
49、其中,functi n为目标函数,包含index和λ,其中,index为pa*中的元素,λ为约束因子,有λ∈{λ1,λ2,λ3,λ4,λ5},λ1,λ2,λ3,λ4,λ5分别为cpu、memory、stream、elog和qos的约束因子,wcpu、wmemory、wstream、welog、wqos分别为cpu、memory、stream、elog和qos的权重因子,fcpu(index)、fmemory(index)、fstream(index)、felog(index)、fqos(index)分别为cpu、memory、stream、elog和qos的子目标函数
50、目标函数有约束函数如下:
51、
52、其中,分别为cpuv,memoryv,streamv,elogv,qosv的权重因子,λl为第l个约束因子,indexl为cpu、memory、stream、elog,qos中的第l组元素。
53、进一步的,所述数据可视化与报告模块包括数据可视化单元、历史数据分析单元、报告生成单元,其中:数据可视化单元,提供直观的图形界面,展示控制过程中的数据,数据可视化单元能够生成折线图、柱状图、饼图,帮助用户快速理解数据的变化趋势和分布情况,实时监控面板,用于实时显示生产过程中的温度、压力、流速、ph值、溶解氧含量,用户通过实时监控面板实时监控生产状态,及时发现和处理异常情况;历史数据分析单元,用于对生产过程中的历史数据进行分析,生成趋势图和统计报告,用户通过历史数据分析单元了解生产过程中的长期变化趋势,辅助优化生产工艺;报告生成单元,自动生成分析报告,包括参数的变化趋势、异常事件的记录和处理结果;用户自定义视图,允许用户根据需要自定义数据展示界面和报告内容,用户选择需求参数和时间段,生成个性化的数据视图和报告,满足不同的分析需求;数据导出与共享单元,支持将可视化数据和报告导出为word、excel、pdf文件格式。
54、本发明有益效果:能够实现对生产过程的智能化调整和优化,确保药物纯度和生产效率达到最佳状态。通过历史数据和实时数据的采集和分析,聚类分类法能获取数据隐藏的数据关系,决策树分类法能获取数据显性的数据关系,经验公式可以得到数据的常规分类结果,按照分类结果的最小粒度划分从而优化分类效果,利用cnn提取关键参数特征,并通过lstm进行时间序列预测,能够精准捕捉生产过程中的参数变化,提供精确的数据基础和优化方案,提高生产效率和产品质量,本发明能实时监控生产过程中的关键参数,通过机器学习算法自动识别和调整生产条件,确保生产过程的稳定性和一致性,避免人为操作带来的误差,提高生产过程的自动化程度。系统内置的模型训练与更新单元能够定期对模型进行训练和更新,利用新数据不断改进和优化模型,适应生产工艺的变化,确保系统在不同的生产条件下始终保持高效运行,通过对实时数据的监测和分析,当发现生产过程中的关键参数出现异常或偏离预设范围时,系统能够及时发出预警并反馈给操作人员,确保能够迅速采取措施,避免生产事故或质量问题的发生。系统允许用户根据生产需求和经验定义和调整关键参数设置,并通过机器学习算法的优化,结合历史数据和实时监测结果,提供个性化的参数优化方案,提高生产灵活性和效率。通过智能化调整和优化,系统能够在不同生产条件下实现对关键参数的精确控制,确保药物纯度和生产效率的稳定性和一致性,满足日益严格的质量要求,本发明结合了卷积神经网络(cnn)的强大特征提取能力和长短期记忆网络(lstm)的时间序列预测能力,通过智能化的控制系统,实现了生物制药纯化工艺的全面优化和高效管理,为生物制药行业提供了强大的技术支持。权利要求7中通过分析cpu使用率、内存使用率、网络流量、错误日志、服务打分五类指标,建立了帕累托函数集合,从而实现对系统性能的全面监控和优化。具体来说,帕累托优化方法能够识别出不同算力服务之间的最优组合,即在多个性能指标上同时达到最优而不损失其他指标的优化结果,避免了单一指标的局限性,使得系统能够在不同性能需求之间达到平衡,尤其是在系统资源有限的情况下,确保资源的最优分配,提高整体系统的运行效率和可靠性。通过帕累托函数集合,系统能够动态调整不同算力服务的资源分配,在不影响关键性能指标的情况下,充分利用系统资源,避免资源浪费,并且系统自动化地进行性能监控和优化,减少了人工干预的需要,降低了运维成本。通过本发明的智能纯化工艺控制系统,能够显著提升生物制药生产的自动化、智能化水平,提高药物生产的质量和效率,满足现代生物制药行业对高效、安全和高质量生产的需求。
- 还没有人留言评论。精彩留言会获得点赞!