基于动态事件驱动的多智能体指定时间一致性控制方法
本发明属于多智能体协同控制,具体涉及一种基于动态事件驱动的多智能体指定时间一致性控制方法。
背景技术:
1、受集群动物的启发,多智能体系统的分布式跟踪控制因其在完成多个任务时具有良好的可拓展性和鲁棒性而受到广泛关注。其中,收敛性能往往是评价一个控制器好坏的重要指标,它表征着多智能体系统在任务执行时的稳定性和收敛速度。此外,控制器的参数优化可以最大限度地提升控制器的性能,确保系统在达到稳态之前,能够更快速、更平滑地将控制输入调整到期望的范围。
2、基于对收敛时间上界的保守性,二阶多智能体分布式跟踪控制算法可分为有限时间跟踪控制算法和固定时间跟踪控制算法。有限时间跟踪控制算法的收敛时间受智能体初始状态的影响,而固定时间控制算法的收敛时间上限不仅受控制器参数的影响,还相对保守。为了实现更加平缓地控制输入和节省系统的能量消耗,指定时间跟踪控制算法应运而生。与前两个算法相比,指定时间跟踪控制算法的一个显著优点是可以预设系统的稳定时间,允许用户根据不同的任务需求为多智能体系统设定收敛时间。这一算法消除了对收敛时间上限保守估计的需要,并保证了用户提前设定的稳定时间与系统的初始状态和控制器参数无关。
3、资源分配是分布式控制中一个至关重要的问题,其必要性主要可以从单个智能体和整个系统两个角度来说明。单个智能体的通信资源和计算能力是有限的,若智能体之间频繁通信,可能会造成延迟和数据丢包的问题。当系统达到稳定且允许具有一定水平的跟踪误差时,相邻智能体之间的控制输入误差通常需要在可允许的范围内,并且同一智能体在连续时间点的位置误差通常较小。这表明相邻智能体之间其实不需要连续通信。为了能尽量减少不必要的通信,多智能体系统的触发机制被提出。该机制仅在测量的状态误差超过某一阈值时,才会通过更新控制器来运行。触发机制可进一步分为静态触发机制和动态触发机制。其中,动态触发机制包含了一个自适应的阈值变量,可以根据智能体的实际状态实时进行调整。所以相比于静态触发机制,动态触发机制可以在降低智能体通信频率的同时保持良好的控制性能。然而,现有的动态触发机制无法保证执行后动态变量的非负性,会发生zeno行为,不可避免地增加通信负担。因此,针对二阶多智能体系统,建立一种新形式的动态触发指定时间控制算法是一个很有前景的研究课题。
技术实现思路
1、本发明的目的在于提供一种基于动态事件驱动的多智能体指定时间一致性控制方法,以解决上述背景技术中提出的问题。
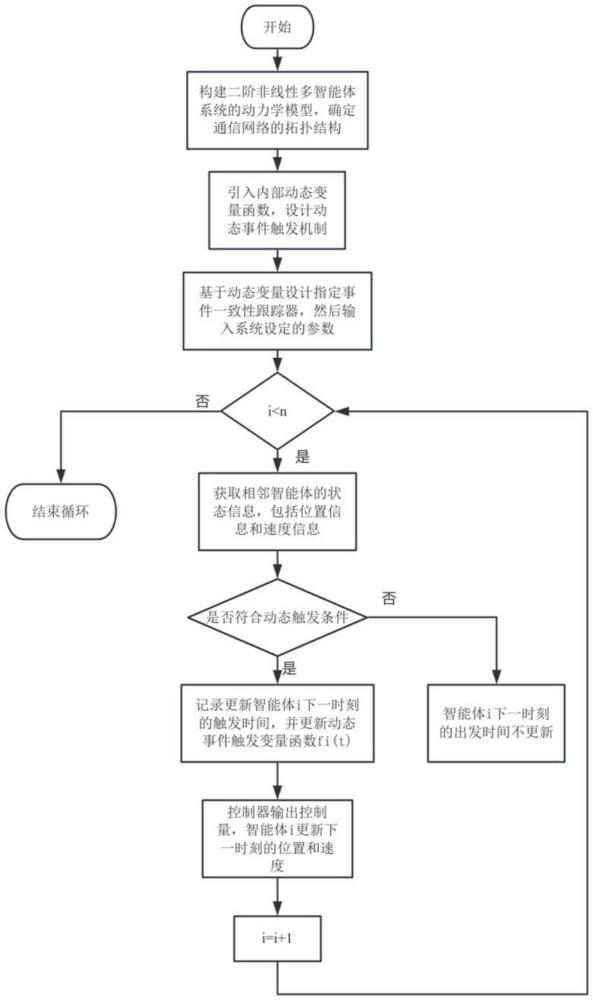
2、本发明提出的一种基于动态事件驱动的多智能体指定时间一致性控制方法,包括以下步骤:
3、步骤一、建立多智能体系统的通信网络拓扑图。
4、步骤二、构建多智能体系统的动力学模型。
5、步骤三、设计动态事件触发条件。
6、步骤四、建立多智能体系统的一致性跟踪控制器ui(t):
7、ui(t)=δi(t)[γθi(t)+sig(θi(t))α+s(θi(t))]
8、其中,δi(t)为增益函数;θi(t)为第i个智能体与其他智能体及虚拟领导者之间的速度误差、位置误差的线性组合;sig(θi(t))α=[sign(θi1(t)|θi1(t)|α),...,sign(θim(t)|θim(t)|α)]t;m为智能体位置坐标和速度状态的维度;n为智能体的数量;γ,α,q均为预设的参数,q,γ>0,0<α<1。
9、步骤五、多智能体系统在动态事件触发条件和一致性跟踪控制器的作用下随虚拟领导者移动,并在指定时间达到位置和速度一致。
10、作为优选,所述的步骤四中,增益函数δi(t)的表达式为:
11、
12、其中,χ,ξ为预设参数,χ,ξ>0;t为指定的稳定时间;
13、作为优选,所述的步骤一中,网络拓扑结构的每个节点都代表一个智能体,每条边则代表两两智能体之间的通信关系;多智能体系统的网络拓扑结构图可记为有向图gn(v,e,a);其中,v为多智能体的集合;e为智能体之间通信关系的集合;a为邻接矩阵。多智能体系统网络拓扑结构的邻接矩阵a的表达式为:
14、
15、其中,aij为第i个智能体和第j个智能体之间边的权重;若第i个智能体能够从第j个智能体接收信息,则aij>0(j≠i);若第i个智能体不能够从第j个智能体接收信息,则aij=0;j=1,2,...,n。
16、作为优选,所述的线性组合θi(t)的表达式为:
17、
18、其中,为第,个智能体在最近一次触发动态事件时刻的位置坐标;为第i个智能体在最近一次触发动态事件时刻的位置坐标;为第j个智能体在最近一次触发动态事件时刻的速度状态;为第i个智能体在最近一次触发动态事件时刻的速度状态;η,σ为预设参数,σ,η>0。
19、作为优选,所述的动态事件触发条件为:
20、
21、其中,为下一次触发动态事件的时刻;为第i个智能体的最近一次触发动态事件的时刻;inf(·)为取集合下界运算;λi(t)的表达式为:
22、
23、其中,wxi(t)为第i个智能体在当前时刻t的位置耦合误差;wvi(t)为第i个智能体在当前时刻t的速度耦合误差;为第i个智能体在最近一次触发动态事件时刻的位置耦合误差;为第i个智能体在最近一次触发动态事件时刻的速度耦合误差;b0,b1,b2为预设参数,b0,b1,b2>0;fi(t)为内部动态变量。
24、作为优选,所述的内部动态变量fi(t)的计算方法如下:
25、
26、其中,b3,b4为预设参数,b3,b4>0;fi(0)>0。
27、作为优选,所述的预设参数η,σ,b0满足以下关系式:
28、
29、
30、其中,δi为增益函数δi(t)的最大值;γ为预设的参数,γ>0;τmin为矩阵的最小特征值;为矩阵的最小特征值;dt为所有事件触发时间间隔最大的上界;为特征矩阵,表达式为m为定义转化矩阵,表达式为为有向图gn(v,e,a)的拉普拉斯矩阵;diag{a10,...,an0}为对角矩阵;im为阶数为m的单位矩阵;l1,l2为预设参数,l1,l2>0。
31、作为优选,所述的位置耦合误差wxi(t)和以及速度耦合误差wvi(t)和的表达式分别为:
32、
33、其中,exi(t)为第i个智能体在当前时刻t的位置误差,evi(t)为第i个智能体在当前时刻t的速度误差,和分别为第i个智能体在最近一次触发时刻的位置和速度;为第i个智能体与多智能体系统的位置误差总和,为第i个智能体与多智能体系统的速度误差总和,和分别为第j个智能体在最近一次触发时刻的位置和速度。
34、作为优选,所述的步骤二中,构建的动力学模型的表达式为:
35、
36、其中,为第i个智能体的位置坐标xi(t)的导数;为第i个智能体的速度状态vi(t)的导数;ui(t)为第i个智能体的控制输入;ci(xi(t),vi(t))为非线性项,其满足以下不等式:
37、||ci(xi(t),vi(t))-c0(x0(t),v0(t))||≤l1||xi(t)-x0(t)||+l2||vi(t)-v0(t)||
38、其中,c0(x0(t),v0(t))为虚拟领导者的非线性项;x0(t)为虚拟领导者在t时刻的位置坐标;v0(t)为虚拟领导者在t时刻的速度状态;l1,l2为预设参数,l1,l2>0。
39、作为优选,所述的步骤二中,虚拟领导者的控制输入u0(t)均设置为0;以第i个智能体与虚拟领导者的相对位置作为第i个智能体在t时刻的位置坐标xi(t);以第i个智能体与虚拟领导者的相对速度作为第i个智能体在t时刻的速度状态vi(t);构建以虚拟领导者为参考状态的扩展通信拓扑图gn+1;扩展通信拓扑图gn+1中包含邻接矩阵b=(a10,a20,...,an0);ai0为第i个智能体与虚拟领导者之间的权重;若第i个智能体能够从虚拟领导者接收信息,则ai0>0;若第i个智能体不能够从虚拟领导者接收信息,则ai0=0。
40、本发明具有的有益效果是:
41、1、本发明提出了一种新的一致性控制协议,以协调多智能体系统在指定时间内达成一致性,使得用户可以根据任务的具体需求,自主地选择指定的调节时间来增强系统的收敛性能。同时,本发明在设计一致性控制协议时引入了不同类型的增益函数,不仅增强了控制器的泛化能力,而且保证了输出保持在稳定范围内,进而加强了控制器的鲁棒性和自适应性。
42、2、本发明所提出的动态触发条件不仅考虑了相邻智能体在各自触发时刻的状态误差,还引入了动态变量的倒数项来补偿系统在不连续通信时的不稳定性,解决了以往动态触发机制在系统达到一致后仍存在zeno行为的问题。
- 还没有人留言评论。精彩留言会获得点赞!