一种文本相关主题的推荐方法和装置与流程
一种文本相关主题的推荐方法和装置【技术领域】本发明涉及互联网应用技术领域,特别涉及一种文本相关主题的推荐方法和装置。
背景技术:
随着信息和网络技术的不断发展,网络互动问答平台,如百度知道、新浪爱问、谷歌问答、搜搜问问、雅虎知识堂等,为网民提供了一个可以进行互动交流的平台。用户可以通过知识搜索,查找在日常生活、学习或专业方面遇到的疑问的答案。用户还可以与其他有共同兴趣的人交流,问问题,找答案,互助交流,分享知识。在问答平台中通常有延伸阅读的需求,通过分析发现,用户的延伸阅读可分为对比阅读需求和扩展阅读需求两种。其中,对比阅读需求是指对同一个问题表示的知识点的多种解答的比较,而扩展阅读需求则是指对与问题相关的知识面的获取需求,对有相关联的问题资源的阅读。当前,大部分互动问答平台通过问题的“相关问题”展示在问答平台的问题页上,以问题标题进行检索得到的前N条结果,来满足用户的延伸阅读需求。这种通过检索得到的推荐结果形式只能满足用户的对比阅读需求,只能对于同一问题点进行推荐,并不能从相关主题面上进行推荐,对其扩展阅读需求则无法满足。
技术实现要素:
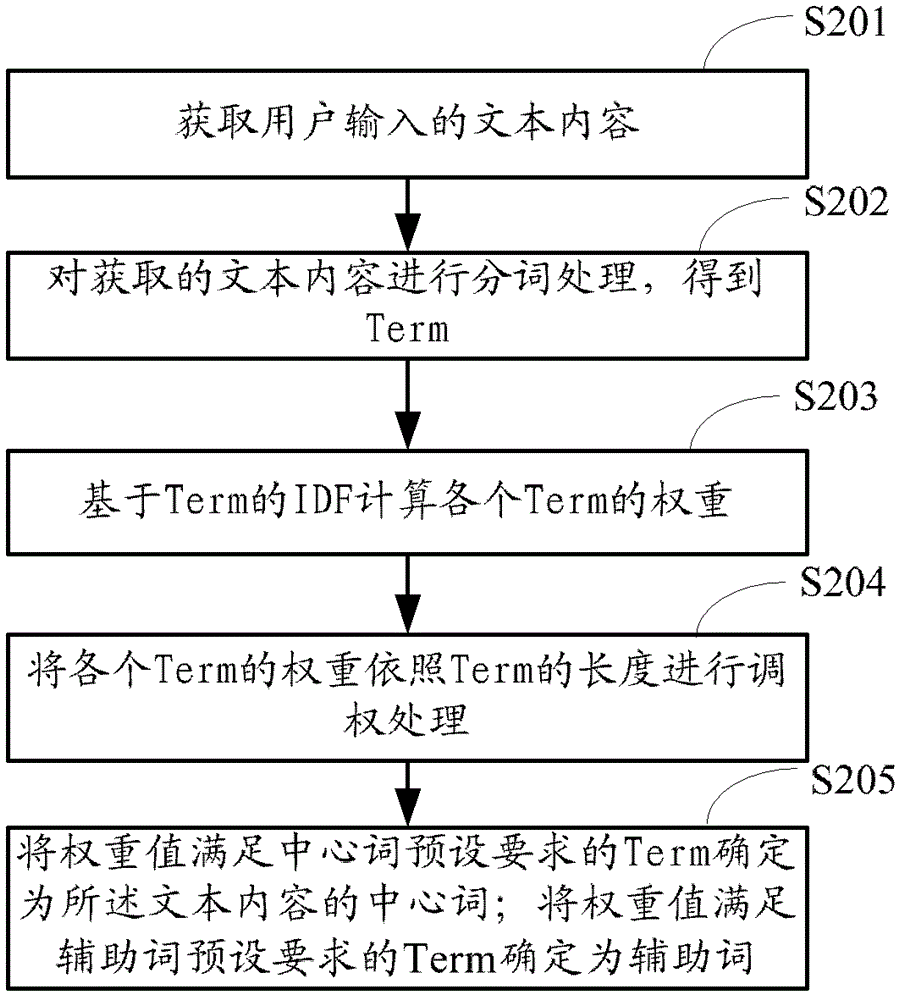
本发明提供了一种文本相关主题的推荐方法和装置,实现对用户的扩展阅读需求进行推荐,使得推荐结果更加准确、更接近用户的使用习惯,满足对相关主题延伸阅读需求。具体技术方案如下:一种文本相关主题的推荐方法,该方法包括以下步骤:S1、获取文本内容,对文本内容进行分词得到词项Term,计算各个Term的权重,根据Term的权重确定所述文本内容的中心词和辅助词;S2、利用所述中心词到已有的主题集合中进行匹配,将包含所述中心词的主题作为候选主题,构成候选主题集合;S3、根据候选主题对应的资源数和候选主题与所述辅助词的相关性,计算各候选主题的综合权重;S4、将综合权重满足预设要求的候选主题作为推荐的相关主题。根据本发明一优选实施例,所述步骤S1具体包括:获取文本内容;对获取的文本内容进行分词处理,得到Term;基于Term的倒文档率IDF计算各个Term的权重;将权重满足中心词预设要求的Term确定为所述文本内容的中心词;将权重满足辅助词预设要求的Term确定为辅助词。根据本发明一优选实施例,在所述基于Term的倒文档率IDF计算各个Term的权重后,还将各个Term的权重依据所述文本内容的长度进行调权处理。根据本发明一优选实施例,所述中心词预设要求包括:Term的权重排在前N1个;或者,Term的权重大于预设第一阈值Q1;或者,Term的权重大于预设第三阈值Q3且排在前N1个;对应地,辅助词预设要求包括:Term的权重排在前N1+1至前N2个;或者,Term的权重在预设第一阈值Q1和预设第二阈值Q2之间;或者,Term的权重大于预设第三阈值Q3且排在前N1+1至前N2个;其中,N1、N2为预设正整数,且N1<N2,0<Q2<Q1≤1,0<Q3≤1。根据本发明一优选实施例,所述已有的主题集合中采用中心词和标记词的组合表示各个主题,该主题集合的建立包括以下步骤:A1、从用户搜索日志中获取搜索关键词,将所述搜索关键词分成一个或多个Term,并记录各Term在搜索关键词中出现的位置;A2、将步骤A1确定的Term中指向某一实体的Term构成候选中心词集合,将候选中心词集合中在所述搜索关键词的首部没有出现的Term过滤掉,得到中心词集合;A3、将步骤A1确定的Term中描述实体特性的Term构成候选标记词集合,将候选标记词集合中在所述搜索关键词的尾部没有出现的Term过滤掉,得到标记词集合;A4、利用所述中心词集合和标记词集合中的Term得到中心词和标记词的组合,将在所述搜索关键词中没有出现的组合过滤掉,得到主题集合。根据本发明一优选实施例,所述步骤S3包括以下步骤:根据候选主题集合中各个候选主题对应的资源数,计算候选主题的第一权重W1;根据候选主题与辅助词的相关性,计算候选主题的第二权重W2;对计算得到的候选主题的第一权重W1和第二权重W2进行线性加权,得到候选主题的综合权重W。根据本发明一优选实施例,所述候选主题的第一权重W1为:所述候选主题对应的资源数与候选主题集合中各候选主题对应的最大的资源数的比值。根据本发明一优选实施例,所述候选主题的第二权重W2为:Ws与Ws_max的比值,其中Ws为所述候选主题的标记词与各所述辅助词之间的相关性之和,Ws_max为针对候选主题集合中各候选主题计算出的Ws的最大值。根据本发明一优选实施例,所述满足预设要求包括:候选主题的综合权重W排在前N3个,N3为预设正整数;或者,候选主题的综合权重W大于预设主题权重阈值Q4,0<Q4≤1。根据本发明一优选实施例,在所述步骤S4中还包括依据综合权重对各候选主题进行排序,且在排序时进行以下处理:将所包含标记词在所述文本内容中出现的候选主题的排序提前;或者,将与按照综合权重排在前面的候选主题存在字面重复的候选主题的综合权重降权。一种文本相关主题的推荐装置,该装置包括:中心词获取模块,用于获取文本内容,对文本内容进行分词得到词项Term,计算各个Term的权重,根据Term的权重确定所述文本内容的中心词和辅助词;候选主题获取模块,用于利用中心词获取模块获取的中心词到已有的主题集合中进行匹配,将包含所述中心词的主题作为候选主题,构成候选主题集合;候选主题权重计算模块,用于根据候选主题对应的资源数和候选主题与所述辅助词的相关性,计算候选主题集合中各候选主题的综合权重;相关主题确定模块,用于根据候选主题权重计算模块计算得到的各候选主题的综合权重,将综合权重满足预设要求的候选主题作为推荐的相关主题。根据本发明一优选实施例,所述中心词获取模块包括:文本获取单元,用于获取文本内容;分词单元,用于对获取的文本内容进行分词处理,得到Term;赋值单元,基于Term的倒文档率IDF计算各个Term的权重;选词单元,用于将权重满足中心词预设要求的Term确定为所述文本内容的中心词,将权重满足辅助词预设要求的Term确定为辅助词。根据本发明一优选实施例,所述中心词获取模块还包括调权单元,用于将所述赋值单元得到的各个Term的权重依据所述文本获取单元获取的文本内容的长度进行调权处理,将调权处理后的各个Term的权重提供给所述选词单元。根据本发明一优选实施例,所述中心词预设要求包括:Term的权重排在前N1个;或者,Term的权重大于预设第一阈值Q1;或者,Term的权重大于预设第三阈值Q3且排在前N1个;对应地,辅助词预设要求包括:Term的权重排在前N1+1至前N2个;或者,Term的权重在预设第一阈值Q1和预设第二阈值Q2之间;或者,Term的权重大于预设第三阈值Q3且排在前N1+1至前N2个;其中,N1、N2为预设正整数,且N1<N2,0<Q2<Q1≤1,0<Q3≤1。根据本发明一优选实施例,所述已有的主题集合中采用中心词和标记词的组合表示各个主题,该装置还包括:主题集合的建立模块,所述主题集合的建立模块具体包括:关键词获取单元,用于从用户搜索日志中获取搜索关键词,将所述搜索关键词分成一个或多个Term,并记录各该些Term在搜索关键词中出现的位置;中心词集合单元,用于将所述关键词获取单元确定的Term中指向某一实体的Term构成候选中心词集合,将候选中心词集合中在搜索关键词的首部没有出现的Term过滤掉,得到中心词集合;标记词集合单元,用于将所述关键词获取单元确定的Term中描述实体特性的Term构成候选标记词集合,将候选标记词集合中在搜索关键词的尾部没有出现的Term过滤掉,得到标记词集合;主题集合单元,用于利用所述中心词集合和标记词集合中的Term得到中心词和标记词的组合,将在搜索关键词中没有出现的组合过滤掉,得到主题集合。根据本发明一优选实施例,所述候选主题权重计算模块,包括:第一权重计算单元,用于根据候选主题集合中各个候选主题对应的资源数,计算候选主题的第一权重W1;第二权重计算单元,用于根据候选主题与辅助词的相关性,计算候选主题的第二权重W2;加权单元,用于对所述第一权重计算单元和第二权重计算单元计算得到的候选主题的第一权重W1和第二权重W2进行线性加权,得到候选主题的综合权重W。根据本发明一优选实施例,所述候选主题的第一权重W1为:所述候选主题对应的资源数与候选主题集合中各候选主题对应的最大的资源数的比值。根据本发明一优选实施例,所述候选主题的第二权重W2为:Ws与Ws_max的比值,其中Ws为所述候选主题的标记词与各所述辅助词之间的相关性之和,Ws_max为针对候选主题集合中各候选主题计算出的Ws的最大值。根据本发明一优选实施例,所述满足预设要求包括:候选主题的综合权重W排在前N3个,N3为预设正整数;或者,候选主题的综合权重W大于预设主题权重阈值Q4,0<Q4≤1。根据本发明一优选实施例,所述相关主题确定模块依据综合权重对各候选主题进行排序,且在排序时进行以下处理:将所包含标记词在所述文本内容中出现的候选主题的排序提前;或者,将与按照综合权重排在前面的候选主题存在字面重复的候选主题的综合权重降权。由以上技术方案可以看出,本发明提供的文本相关主题的推荐方法和装置,基于中心词匹配的主题判别,并利用主题资源数和基于标记词与辅助词之间的相关性wordsim进行综合权重的计算,依据该综合权重进行相关主题推荐,即从文本内容中挖掘与文本最相关的主题,实现对用户的扩展阅读需求进行推荐,使得推荐结果更加准确、更接近用户的使用习惯,提升用户的浏览体验。【附图说明】图1为本发明实施例一提供的文本相关主题的推荐方法流程图;图2为本发明实施例一提供的确定中心词的处理流程图;图3为本发明实施例一提供的“中心词+标记词”主题集合的形成方法流程图;图4为本发明实施例一提供的计算候选主题的综合权重的方法流程图;图5为本发明实施例二提供的文本相关主题的推荐装置结构图。【具体实施方式】为了使本发明的目的、技术方案和优点更加清楚,下面结合附图和具体实施例对本发明进行详细描述。实施例一、图1是本实施例提供的文本相关主题的推荐方法流程图,如图1所示,该方法包括:步骤S101、获取文本内容,对文本内容进行分词得到词项(Term),计算各个Term的权重,根据Term的权重确定所述文本内容的中心词和辅助词。用户通过在问答平台上发表知识或问题的文本内容,与其他用户进行分享知识或互助交流,或者,利用搜索引擎输入搜索词(query)进行知识搜索,找到疑问的答案。根据这些文本内容或者query,获得相关主题的推荐内容。图2是本实施例确定中心词的处理流程图,如图2所示,该处理过程具体包括以下步骤:步骤S201、获取文本内容。用户在问答平台上输入的文本内容包括标题和正文,例如,一个在百度知道中的问题,包括标题:“魔兽争霸攻略秘籍是什么?”和正文:“在什么时候输入这些东西?怎么输入?”因而,获取的文本内容可以包括文本的标题和正文。优选地,获取的文本内容仅包括文本的标题,对文本的标题进行分词等处理,在后续实施例的描述中均以文本的标题为例。同样地,针对利用query进行知识搜索的情况,则是获取用户输入的query。步骤S202、对获取的文本内容进行分词处理,得到Term。对获取的问题的标题进行分词、过滤等预处理,采用现有的分词和过滤方法进行预处理,例如采用正向最大匹配法进行分词,得到Term“魔兽争霸”、“攻略”、“秘籍”、“是”、“什么”;经过过滤,去掉停用词后,得到Term“魔兽争霸”、“攻略”、“秘籍”。步骤S203、基于Term的倒文档率(IDF)计算各个Term的权重。根据Term的IDF为各个Term赋予权重,Term的IDF值越大,Term的权重越大。一个文本标题所有Term的权重之和为1。对于上述例子,根据Term“魔兽争霸”、“攻略”、“秘籍”的IDF值为各个Term赋予权重,各个Term的权重之和为1,得到Term“魔兽争霸”的权重为0.5267,Term“攻略”的权重为0.2751,Term“秘籍”的权重为0.1982。步骤S204、将各个Term的权重依据所述文本内容的长度进行调权处理。由于各个文本标题的长度各异,字数及分词数或多或少,对于总和为1的权重值分配到各个Term上的权重会受到分词数的影响,短的文本标题通常分词数少,使得各个Term的权重相对于长的文本标题的高,因而有必要对各Term的权重进行调权处理,尤其是中心词预设要求和辅助词预设要求在采用预设阈值方式进行选取中心词和辅助词时。进行调权处理是将步骤S203得到的Term的权重×长度系数,其中,长度系数的计算公式是:长度系数=log(标题的字数)/log(最长标题的字数)其中,最长标题的长度可以根据实际获取的标题具体而定,也可以选定为一个常数值,如25或50。“魔兽争霸攻略秘籍是什么?”中,长度系数=log12/log25。值得一提的是,所述步骤S202中的过滤处理可以放在步骤S204之后进行处理,在完成根据Term的IDF值计算各个Term的权重的步骤和Term的权重进行调权处理后再进行过滤处理。步骤S205、根据Term的权重的大小,将权重满足中心词预设要求的Term确定为文本的中心词,将权重满足辅助词预设要求的Term确定为辅助词。其中,中心词预设要求可以是Term的权重排在前N1个、Term的权重大于预设第一阈值Q1或者Term的权重大于预设第一阈值Q1且排在前N1个。对应地,辅助词预设要求可以是Term的权重排在前N1+1至前N2个、Term的权重在预设第一阈值Q1和预设第二阈值Q2之间或者Term的权重大于预设第三阈值Q3且排在前N1+1至前N2个,其中,N1、N2为预设正整数,且N1<N2,0<Q2<Q1≤1,0<Q3≤1。例如,当中心词预设要求为Term的权重排在前N1,辅助词预设要求为Term的权重排在前N1+1至前N2时,假设N1=1,N2=3,则将权重排在第一位的Term作为中心词,将权重排在第二位和第三位的Term作为辅助词。可以确定中心词为“魔兽争霸”,辅助词为“攻略”和“秘籍”。根据标题的长度,设定如果长度小于50,则取权重最高的3个Term,如果长度大于50,则取权重最高的4个Term。将Term的权重大于0.2的最多两个Term作为标题的中心词,其余的Term作为辅助词。当获取的文本内容包括文本的正文时,则还对文本的正文进行分词,采用词频-倒文档率(TF-IDF)等方式为各个Term赋予权重,并对Term的权值进行调权处理后,根据Term的权重大小确定中心词和辅助词。继续参阅图1,步骤S102、利用所述中心词到已有的主题集合中进行匹配,将包含所述中心词的主题作为候选主题,构成候选主题集合。已有的主题集合是现有的平台系统中的问题资源,该些资源以一定的主题形式存储于平台系统中,各主题中包含中心词和标记词(tag)。在本实施例中,主题集合采用“中心词+标记词”的形式表示各个主题,例如,主题“魔兽争霸攻略”、“魔兽争霸秘籍”、“魔兽争霸冰封王座”等,其中,“魔兽争霸”是中心词,“攻略”、“秘籍”和“冰封王座”是标记词。下面结合图3对主题集合的形成过程进行描述,图3是本实施例“中心词+标记词”主题集合的形成方法流程图,如图3所示,包括以下步骤:步骤S301、从用户搜索日志中获取搜索关键词,将所述搜索关键词分成一个或多个Term,并记录各该些Term在搜索关键词中出现的位置。所述记录Term在搜索关键词中出现的位置主要是记录该Term是否在搜索关键词的首部或者尾部出现。如对于搜索关键词“魔兽世界下载”中,Term“魔兽世界”出现在该搜索关键词的首部,而Term“下载”出现在该搜索关键词的尾部。对于Term出现的位置的记录方式可以仅记录是否出现在首部或尾部,也可以记录在搜索关键词中出现的具体位置,本发明并不作限制。步骤S302、将步骤S301确定的Term中指向某一实体的Term构成候选中心词集合,将候选中心词集合中在搜索关键词的首部没有出现的Term过滤掉,得到中心词集合。所述指向某一实体的Term能够清晰、准确表达某一实体、具有实际意义的Term,如“魔兽世界”、“星际争霸”等等。将候选中心词集合中在搜索关键词的首部没有出现的Term过滤掉,例如,Term“下载”没有出现在搜索关键词的首部,则去除,不作为中心词。而Term“魔兽世界”出现在搜索关键词的首部,则保留作为中心词。步骤S303、将步骤S301确定的Term中描述实体特性的Term构成候选标记词集合,将候选标记词集合中在搜索关键词的尾部没有出现的Term过滤掉,得到标记词集合。所述描述实体特性的Term是描述实体某一方面特性的词,可以采用人工标记词,如博客中的标记词,也可以是其他的能描述实体的属性词。比如,“下载”、“外挂”、“秘籍”等都是针对游戏“魔兽世界”某一方面特性的Term,可以作为候选标记词集合中的Term。将候选标记词集合中在搜索关键词的尾部没有出现的Term过滤掉,例如,Term“魔兽世界”没有出现在搜索关键词的尾部,则去除,不作为标记词。而Term“下载”出现在搜索关键词的尾部,则保留作为标记词。步骤S304、利用所述中心词集合和标记词集合中的Term分别构成“中心词+标记词”的组合,将在搜索关键词中没有出现的组合过滤掉,得到主题集合。比如,由“魔兽争霸”和“攻略”构成“魔兽争霸+攻略”的组合,“魔兽争霸”在中心词集合中,且“攻略”在标记词集合中,在搜索日志中有搜索关键词为“魔兽争霸攻略”,则将“魔兽争霸攻略”加入主题集合。也就是说,“中心词+标记词”的形式出现在搜索关键词中才保留,所述中心词和标记词在同一个搜索关键词中可以不连续地出现。比如,如果搜索日志中有“魔兽争霸中文版攻略”的搜索关键词,也认为组成的“魔兽争霸攻略”的组合有出现在搜索关键词中。每个主题都通过“中心词+标记词”的形式表示,每个中心词可与多个不同的标记词构成多个不同的主题。例如,中心词为“魔兽争霸”,可以搭配攻略、秘笈和冰封王座等标记词。每个主题下包括若干个相关问题内容。例如,主题为“魔兽争霸冰封王座”下包括:“魔兽争霸3冰封王座1.20版秘籍”“魔兽争霸3冰封王座有哪些密码?”“请问哪里有魔兽争霸3冰封王座下载?”“魔兽争霸3冰封王座怎么联网玩啊?”等等继续参见图1中的步骤102,利用步骤S101获得的中心词“魔兽争霸”,则将主题集合中包含中心词“魔兽争霸”的主题作为候选主题。步骤S103、根据候选主题对应的资源数和候选主题与所述辅助词的相关性,计算各候选主题的综合权重。图4是本实施例计算候选主题的综合权重的方法流程图,如图4所示,具体包括以下步骤:步骤S401、根据候选主题集合中各个候选主题对应的资源数,计算候选主题的第一权重W1。将每个候选主题,即中心词+标记词作为query在平台系统中进行搜索,得到对应的问题数M,该问题数M即为所述候选主题对应的资源数。候选主题的第一权重W1=M/M_max,其中M_max是候选主题集合中各候选主题对应的问题数M中最大的问题数。此过程相当于,对候选主题对应的资源数进行归一化处理。例如,候选主题集合中有“魔兽争霸攻略”、“魔兽争霸秘籍”、“魔兽争霸下载”、“魔兽争霸冰封王座”等等主题。其中,“魔兽争霸攻略”对应的资源数为313795,“魔兽争霸秘籍”对应的资源数为227444,“魔兽争霸下载”对应的资源数为544330,“魔兽争霸冰封王座”对应的资源数为466296。可以得到“魔兽争霸攻略”的第一权重是0.5765,“魔兽争霸秘籍”的第一权重是0.4178,“魔兽争霸下载”的第一权重是1,“魔兽争霸冰封王座”的第一权重是0.8566。其中,最大的问题数M_max还可以采用将中心词作为query进行搜索得到的问题数。利用中心词“魔兽争霸”搜索得到资源数为11762721,得到“魔兽争霸攻略”的第一权重是0.0267,“魔兽争霸秘籍”的第一权重是0.0193,“魔兽争霸下载”的第一权重是0.0463,“魔兽争霸冰封王座”的第一权重是0.0396。步骤S402、根据候选主题与辅助词的相关性,计算候选主题的第二权重W2。获取候选主题的标记词,计算该标记词与步骤S101中确定的各个辅助词之间的相关性之和。计算标记词与辅助词之间的相关性Ws可以但不限于采用计算词与词之间的相关性wordsim的方法。计算词A与词B之间的相关性wordsim的具体过程包括如下:分别针对词A和词B确定特征向量,该特征向量的确定过程为:先将单个词(如,词A)作为query到搜索引擎中进行搜索,得到搜索结果,选取前X个页面的搜索结果,并对每个页面的内容进行分词并计算分词的TF-IDF作为各个分词的权重,再选取权重值排在前Y个的分词作为词A的特征向量。然后,计算词A的特征向量和词B的特征向量之间的相似度作为词A和词B的相关性wordsim,两个特征向量之间的相似度可以采用余弦相似度或者内积而得到。而后,再进一步进行归一化处理得到候选主题的第二权重W2。候选主题的第二权重W2=Ws/Ws_max,其中,Ws是所述候选主题的标记词与步骤S101确定的各个辅助词之间的相关性之和,Ws_max是针对候选主题集合中各候选主题计算出的Ws的最大值。对于已有的主题集合采用普通的存储方式时,例如,仅以中心词或者问题标题表示主题的方式,则计算辅助词与候选主题的中心词或问题标题之间的相关性,类似地,该相关性也可以通过现有的内积或余弦相似度的方法进行计算,而后得到各个候选主题的第二权重W2。步骤S403、对计算得到的候选主题的第一权重W1和第二权重W2进行线性加权,得到候选主题的综合权重W。采用的线性加权公式为:W=W1×a+W2×(1-a),其中,a是预设的调权因子,0<a<1。根据应用场景的不同,可设置不同的a,分配第一权重W1和第二权重W2的比例,加权得到综合权重W。继续参见图1,步骤S104、将综合权重满足预设要求的候选主题作为推荐的相关主题。根据步骤S103得到的候选主题的综合权重W对候选主题进行排序,将候选主题集合中满足预设要求的候选主题作为推荐的相关主题。所述满足预设要求包括候选主题的综合权重W排在前N3个,N3为预设正整数,或者候选主题的综合权重W大于预设主题权重阈值Q4,0<Q4≤1。例如,选取N3=5,则取出排在前5位的候选主题为推荐的相关主题。为了使推荐结果更加符合用户实际的需求,在对候选主题进行排序时,可以进行以下处理:第一,将所包含标记词在获取的文本标题中出现的候选主题排序提前。由于文本标题中有可能包括多个标记词,为了避免引起冲突,优选地,对依据综合权重排序后的候选主题,从后向前进行扫描,如果候选主题的标记词在文本标题中出现过,就将该候选主题提前至第一位。例如,当扫描到排在倒数第一位的候选主题T1符合要求,则将该候选主题T1提前至第一位,而后又扫描到排在倒数第二位的候选主题T2也符合要求,则将该候选主题T2提前至第一位,在候选主题T1的前面,此时候选主题T1居于第二位。扫描过后的候选主题不再进行再次扫描。第二,将与按照综合权重排在前面的候选主题存在字面重复的候选主题的综合权重进行降权处理。不同候选主题的标记词有可能出现字面语义重复的情况,比如标记词为“翻译”“译文”中字面上“译”有重复。当出现重复时,此两个候选主题为相似的候选主题,与此两个候选主题相关的内容可能会相同,出现重复推荐的情况。因而,需要对其中综合权重排在后面的候选主题进行调权。优选地,按照排序结果,对候选主题从前向后进行扫描,判断当前候选主题的标记词与排在其前面的候选主题的标记词是否有字面语义重复,如果是,则将该当前候选主题的综合权重进行减半处理。在采用上述方法处理之后,得到最终排序结果,将满足预设要求的候选主题作为推荐的相关主题。举个例子,在百度知道上输入query“魔兽争霸攻略秘籍是什么,如何顺利开启秘密关卡?”利用现有的推荐方法,仅从同一个问题点进行推荐,可以得到列在前面5个推荐的相关主题为“攻略秘籍关卡”、“魔兽争霸秘籍”、“魔兽争霸3秘籍”、“魔兽争霸秘籍怎么用”、“魔兽争霸三秘籍”,得到的这些主题均与“秘籍”相关。利用本发明的推荐方法,先经过步骤S101可以确定1个中心词和2个辅助词:中心词为“魔兽争霸”,辅助词为“攻略”和“秘籍”。经过步骤S102利用中心词“魔兽争霸”到已有的主题集合中匹配得到候选主题,包括:“魔兽争霸攻略”、“魔兽争霸秘籍”、“魔兽争霸秘密关卡”、“魔兽争霸冰封王座”、“魔兽争霸战役”、“魔兽争霸下载”等等。再经过步骤S103和步骤S104计算权重和排序处理后,将排在前N3=5个的候选主题作为推荐的相关主题,包括“魔兽争霸秘籍”、“魔兽争霸攻略”、“魔兽争霸冰封王座”、“魔兽争霸战役”、“魔兽争霸秘密关卡”。其中,“魔兽争霸冰封王座”、“魔兽争霸战役”可作为相关主题面的推荐主题,满足对用户的扩展阅读需求。以上是对本发明所提供的方法进行的详细描述,下面对本发明提供的文本相关主题的推荐装置进行详细描述。实施例二、图5为本实施例提供的文本相关主题的推荐装置结构图,如图5所示,该装置包括:中心词获取模块10,用于获取文本内容,对文本内容进行分词得到词项Term,计算各个Term的权重,根据Term的权重确定所述文本内容的中心词和辅助词。用户通过在问答平台上发表知识或问题的文本内容,与其他用户进行分享知识或互助交流,或者,利用搜索引擎输入query进行知识搜索,找到疑问的答案。根据这些文本内容或者query,获得相关主题的推荐内容。具体地,中心词获取模块10包括:文本获取单元101,用于获取文本内容。用户在问答平台上输入的文本内容包括标题和正文,例如,一个在百度知道中的问题,包括标题:“魔兽争霸攻略秘籍是什么?”和正文:“在什么时候输入这些东西?怎么输入?”因而,文本获取单元101获取的文本内容可以包括文本的标题和正文。优选地,获取的文本内容仅包括文本的标题,对文本的标题进行分词等处理,在后续实施例的描述中均以文本的标题为例。同样地,针对利用query进行知识搜索的情况,则是获取用户输入的query。分词单元102,用于对获取的文本内容进行分词处理,得到Term。对获取的问题的标题进行分词、过滤等预处理,采用现有的分词和过滤方法进行预处理,例如采用正向最大匹配法进行分词,得到Term“魔兽争霸”、“攻略”、“秘籍”、“是”、“什么”;经过过滤,去掉停用词后,得到Term“魔兽争霸”、“攻略”、“秘籍”。赋值单元103,基于Term的倒文档率IDF计算各个Term的权重。赋值单元103根据Term的IDF计算各个Term的权重,Term的IDF值越大,Term的权重越大。一个文本标题所有Term的权重之和为1。对于上述例子,根据Term“魔兽争霸”、“攻略”、“秘籍”的IDF值为各个Term赋予权重,各个Term的权重之和为1,得到Term“魔兽争霸”的权重为0.5267,Term“攻略”的权重为0.2751,Term“秘籍”的权重为0.1982。调权单元104,用于将赋值单元103得到的各个Term的权重依据文本获取单元101获取的文本内容的长度进行调权处理,将调权处理后的各个Term的权重提供给选词单元105。由于各个文本标题的长度各异,字数及分词数或多或少,对于总和为1的权重值分配到各个Term上的权重会受到分词数的影响,短的文本标题通常分词数少,使得各个Term的权重相对于长的文本标题的高,因而有必要对各Term的权重进行调权处理。调权单元104进行调权处理是将赋值单元103得到的Term的权重×长度系数,其中,长度系数的计算公式是:长度系数=log(标题的字数)/log(最长标题的字数)其中,最长标题的长度可以根据实际获取的标题具体而定,也可以选定为一个常数值,如25或50。“魔兽争霸攻略秘籍是什么?”中,长度系数=log12/log25。选词单元105,根据Term的权重,将权重满足中心词预设要求的Term确定为文本的中心词,将权重满足辅助词预设要求的Term确定为辅助词。其中,中心词预设要求包括:Term的权重排在前N1个;Term的权重大于预设第一阈值Q1;或者,Term的权重大于预设第三阈值Q3且排在前N1个。对应地,辅助词预设要求包括:Term的权重排在前N1+1至前N2个;Term的权重在预设第一阈值Q1和预设第二阈值Q2之间;Term的权重大于预设第三阈值Q3且排在前N1+1至前N2个。其中,N1、N2为预设正整数,且N1<N2,0<Q2<Q1≤1,0<Q3≤1。例如,当中心词预设要求为权重排在前N1,辅助词预设要求为权重排在前N1+1至前N2时,假设N1=1,N2=3,则将权重排在第一位的Term作为中心词,将权重排在第二位和第三位的Term作为辅助词。可以确定中心词为“魔兽争霸”,辅助词为“攻略”和“秘籍”。根据标题的长度,设定如果长度小于50,则取权重最高的3个Term,如果长度大于50,则取权重最高的4个Term。将Term的权重大于0.2的最多两个Term作为标题的中心词,其余的Term作为辅助词。当文本获取单元101获取的文本内容包括文本的正文时,分词单元102还对文本的正文进行分词,赋值单元103采用TF-IDF等方式为各个Term赋予权重,调权单元104对Term的权值进行调权处理,选词单元105根据Term的权重大小确定中心词和辅助词。候选主题获取模块20,用于利用中心词获取模块10获取的中心词到已有的主题集合中进行匹配,将包含所述中心词的主题作为候选主题,构成候选主题集合。已有的主题集合是现有的平台系统中的问题资源,该些资源以一定的主题形式存储于平台系统中,各主题中包含中心词和标记词。在本实施例中,主题集合采用“中心词+标记词”的形式表示各个主题,例如,主题“魔兽争霸攻略”、“魔兽争霸秘籍”、“魔兽争霸冰封王座”等,其中,“魔兽争霸”是中心词,“攻略”、“秘籍”和“冰封王座”是标记词。构成该主题集合的建立模块(图5中未示出)包括:关键词获取单元,用于从用户搜索日志中获取搜索关键词,将所述搜索关键词分成一个或多个Term,并记录各该些Term在搜索关键词中出现的位置。所述记录Term在搜索关键词中出现的位置主要是记录该Term是否在搜索关键词的首部或者尾部出现。如对于搜索关键词“魔兽世界下载”中,Term“魔兽世界”出现在该搜索关键词的首部,而Term“下载”出现在该搜索关键词的尾部。对于Term出现的位置的记录方式可以仅记录是否出现在首部或尾部,也可以记录在搜索关键词中出现的具体位置,本发明并不作限制。中心词集合单元,用于将关键词获取单元确定的Term中指向某一实体的Term构成候选中心词集合,将候选中心词集合中在搜索关键词的首部没有出现的Term过滤掉,得到中心词集合。所述指向某一实体的Term能够清晰、准确表达某一实体、具有实际意义的Term,如“魔兽世界”、“星际争霸”等等。将候选中心词集合中在搜索关键词的首部没有出现的Term过滤掉,例如,Term“下载”没有出现在搜索关键词的首部,则去除,不作为中心词。而Term“魔兽世界”出现在搜索关键词的首部,则保留作为中心词。标记词集合单元,用于将关键词获取单元确定的Term中描述实体特性的Term构成候选标记词集合,将候选标记词集合中在搜索关键词的尾部没有出现的Term过滤掉,得到标记词集合。所述描述实体特性的Term是描述实体某一方面特性的词,可以采用人工标记词,如博客中的标记词,也可以是其他的能描述实体的属性词。比如,“下载”、“外挂”、“秘籍”等都是针对游戏“魔兽世界”某一方面特性的Term,可以作为候选标记词集合中的Term。将候选标记词集合中在搜索关键词的尾部没有出现的Term过滤掉,例如,Term“魔兽世界”没有出现在搜索关键词的尾部,则去除,不作为标记词。而Term“下载”出现在搜索关键词的尾部,则保留作为标记词。主题集合单元,用于利用所述中心词集合和标记词集合中的Term构成“中心词+标记词”形式的组合,将在搜索关键词中没有出现的组合过滤掉,得到主题集合。比如,由“魔兽争霸”和“攻略”构成“魔兽争霸+攻略”的组合,“魔兽争霸”在中心词集合中,且“攻略”在标记词集合中,在搜索日志中有搜索关键词为“魔兽争霸攻略”,则将“魔兽争霸攻略”加入主题集合。也就是说,“中心词+标记词”的形式出现在搜索关键词中才保留,所述中心词和标记词在同一个搜索关键词中可以不连续地出现。比如,如果搜索日志中有“魔兽争霸中文版攻略”的搜索关键词,也认为组成的“魔兽争霸攻略”的组合有出现在搜索关键词中。每个主题都通过“中心词+标记词”的形式表示,每个中心词可与多个不同的标记词构成多个不同的主题。例如,中心词为“魔兽争霸”,可以搭配攻略、秘笈和冰封王座等标记词。每个主题下包括若干个相关问题内容。例如,主题为“魔兽争霸冰封王座”下包括:“魔兽争霸3冰封王座1.20版秘籍”“魔兽争霸3冰封王座有哪些密码?”“请问哪里有魔兽争霸3冰封王座下载?”“魔兽争霸3冰封王座怎么联网玩啊?”等等候选主题获取模块20利用中心词获取模块10获得的中心词“魔兽争霸”,则将主题集合中包含中心词“魔兽争霸”的主题作为候选主题。候选主题权重计算模块30,用于根据候选主题对应的资源数和候选主题与所述辅助词的相关性,计算候选主题集合中各候选主题的综合权重。具体地,候选主题权重计算模块30,包括:第一权重计算单元301,用于根据候选主题集合中各个候选主题对应的资源数,计算候选主题的第一权重W1。将每个候选主题,即中心词+标记词作为query在平台系统中进行搜索,得到对应的问题数M,该问题数M即为所述候选主题对应的资源数。候选主题的第一权重W1=M/M_max,其中M_max是候选主题集合中各候选主题对应的问题数M中最大的问题数。此过程相当于,对候选主题对应的资源数进行归一化处理。例如,候选主题集合中有“魔兽争霸攻略”、“魔兽争霸秘籍”、“魔兽争霸下载”、“魔兽争霸冰封王座”等等主题。其中,“魔兽争霸攻略”对应的资源数为313795,“魔兽争霸秘籍”对应的资源数为227444,“魔兽争霸下载”对应的资源数为544330,“魔兽争霸冰封王座”对应的资源数为466296。可以得到“魔兽争霸攻略”的第一权重是0.5765,“魔兽争霸秘籍”的第一权重是0.4178,“魔兽争霸下载”的第一权重是1,“魔兽争霸冰封王座”的第一权重是0.8566。其中,最大的问题数M_max还可以采用将中心词作为query进行搜索得到的问题数。利用中心词“魔兽争霸”搜索得到资源数为11762721,得到“魔兽争霸攻略”的第一权重是0.0267,“魔兽争霸秘籍”的第一权重是0.0193,“魔兽争霸下载”的第一权重是0.0463,“魔兽争霸冰封王座”的第一权重是0.0396。第二权重计算单元302,用于根据候选主题与辅助词的相关性,计算候选主题的第二权重W2。获取候选主题的标记词,计算该标记词与中心词获取模块10确定的各个辅助词之间的相关性之和。计算标记词与辅助词之间的相关性Ws可以但不限于采用计算词与词之间的相关性wordsim的方法。计算词A与词B之间的相关性wordsim的具体过程包括如下:分别针对词A和词B确定特征向量,该特征向量的确定过程为:先将单个词(如,词A)作为query到搜索引擎中进行搜索,得到搜索结果,选取前X个页面的搜索结果,并对每个页面的内容进行分词并计算分词的TF-IDF作为各个分词的权重,再选取权重值排在前Y个的分词作为词A的特征向量。然后,计算词A的特征向量和词B的特征向量之间的相似度作为词A和词B的相关性wordsim,两个特征向量之间的相似度可以采用余弦相似度或者内积而得到。而后,再进一步进行归一化处理得到候选主题的第二权重W2。候选主题的第二权重W2=Ws/Ws_max,其中,Ws是所述候选主题的标记词与步骤S101确定的各个辅助词之间的相关性之和,Ws_max是针对候选主题集合中各候选主题计算出的Ws的最大值。对于已有的主题集合采用普通的存储方式时,例如,仅以中心词或者问题标题表示主题的方式,则计算辅助词与候选主题的中心词或问题标题之间的相关性,类似地,该相关性也可以通过现有的内积或余弦相似度的方法进行计算,而后得到各个候选主题的第二权重W2。加权单元303,用于对所述第一权重计算单元和第二权重计算单元计算得到的候选主题的第一权重W1和第二权重W2进行线性加权,得到候选主题的综合权重W。加权单元303采用的线性加权公式为:W=W1×a+W2×(1-a),其中,a是预设的调权因子,0<a<1。根据应用场景的不同,可设置不同的a,分配第一权重W1和第二权重W2的比例,加权得到综合权重W。相关主题确定模块40,用于根据候选主题权重计算模块30计算得到的各候选主题的综合权重,将综合权重满足预设要求的候选主题作为推荐的相关主题。所述满足预设要求包括:候选主题的综合权重W排在前N3个,N3为预设正整数;或者,候选主题的综合权重W大于预设主题权重阈值Q4,0<Q4≤1。如选取N3=5,则取出排在前5位的候选主题为推荐的相关主题。为了使推荐结果更加符合用户实际的需求,相关主题确定模块40对候选主题进行排序时,可以进行以下处理:第一,将所包含标记词在获取的文本标题中出现的候选主题排序提前。由于文本标题中有可能包括多个标记词,为了避免引起冲突,优选地,对依据综合权重排序后的候选主题,从后向前进行扫描,如果候选主题的标记词在文本标题中出现过,就将该候选主题提前至第一位。例如,当扫描到排在倒数第一位的候选主题T1符合要求,则将该候选主题T1提前至第一位,而后又扫描到排在倒数第二位的候选主题T2也符合要求,则将该候选主题T2提前至第一位,在候选主题T1的前面,此时候选主题T1居于第二位。扫描过后的候选主题不再进行再次扫描。第二,将与按照综合权重排在前面的候选主题存在字面重复的候选主题的综合权重进行降权处理。不同候选主题的标记词有可能出现字面语义重复的情况,比如标记词为“翻译”“译文”中字面上“译”有重复。当出现重复时,此两个候选主题为相似的候选主题,与此两个候选主题相关的内容可能会相同,出现重复推荐的情况。因而,需要对其中综合权重排在后面的候选主题进行调权。优选地,按照排序结果,对候选主题从前向后进行扫描,判断当前候选主题的标记词与排在其前面的候选主题的标记词是否有字面语义重复,如果是,则将该当前候选主题的综合权重进行减半处理。在采用上述处理之后,得到最终排序结果,将满足预设要求的候选主题作为推荐的相关主题。本发明提供的推荐方法和装置,基于中心词匹配的主题判别,并利用主题资源数和基于标记词与辅助词之间的相关性wordsim进行排序,从文本内容中挖掘与文本最相关的主题,尤其为问题等短文本构成的条目内容(item)进行挖掘,实现对用户的扩展阅读需求进行推荐,使得推荐结果更加准确、更接近用户的使用习惯,提升用户的浏览体验。本发明的推荐方法和装置可以用于问答平台中答案页面的推荐,知识搜索的搜索结果的推荐,或者进行页面浏览时相关主题的推荐等应用场景。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1