一种分布式文件系统以及数据处理的方法与流程
本发明涉及分布式系统领域,尤其涉及一种分布式文件系统以及数据处理的方法。
背景技术:
HadoopDistributedFileSystem,简称HDFS,是一个分布式文件系统。在HDFS架构中必要角色有三个,Namenode(控制节点)、Datanode(数据节点)和Client(客户端),其中Namenode为集群单点,在整体架构中,Namenode既充当Client的Server,也充当Datanode的Server。在分布式文件系统中,FSImage是数据镜像,Editlog是数据日志,两者合并即为完整的数据。对于任何对文件系统元数据产生修改的操作,Namenode都会使用一种称为EditLog的事务日志记录下来。例如,在HDFS中创建一个文件,Namenode就会在Editlog中插入一条记录来表示;同样地,修改文件的副本系数也将往Editlog插入一条记录。Namenode在本地操作系统的文件系统中存储这个Editlog。整个文件系统的名字空间,包括数据块到文件的映射、文件的属性等,都存储在一个称为FsImage的文件中,这个文件也是放在Namenode所在的本地文件系统上。按照每秒1000个请求数来计算,一天就有24*2600*1000≈8千万条日志,运行一个月就有20亿条日志。如果是Namenode扩容,新加入的Namenode需要把FSImage和20亿左右的Editlog做一次合并,需要花费的时间至少需要20多个小时;如果是整个集群系统升级新版本,全部停机重启,每个Namenode的启动过程,都需要经过至少一次镜像合并,这个时间会在1天以上;原生HDFS的Namenode是单点故障,即Namenode服务器一旦发生故障,整个HDFS集群服务即处于瘫痪状态。这些故障包含但不仅限于:服务器进程crash;这时要恢复服务,需要重启Namenode进程,重启花费时间在几千万文件的情况下,大概需要30分钟;服务器硬盘故障;这时候数据会损坏,服务部分瘫痪。可以用多Namespace间接解决。网络故障;该Namenode所在的服务器网络中断,无法连接。排除此故障需要人工介入解决,然后重启Namenode。无论是哪种故障,服务恢复的时间都非常长,作为基础平台,很明显无法满足需求。硬件错误是常态,而非异常情况,HDFS可能是有成百上千的server组成,任何一个组件都有可能一直失效,因此错误检测和快速、自动的恢复是HDFS的核心架构目标。针对上述问题,发明人发现现有的解决方案或多或少都存在一些无法解决的问题:现有的解决方案1:在Namenode上配置多个NameSpace,同时配备secondaryNamenode;该方案1的缺点是:数据有损,会存在少许丢失;切换过程纯手工化;故障恢复时间:1到2小时。现有的解决方案2:LinuxHeartbeat配备DRBD,HB解决自动切换,DRBD解决数据一致性;该方案2的缺点是:故障恢复时间至少在30分钟左右。现有的解决方案3:AvatarNode方案;该方案的缺点是:依赖于外部NFS存储,无法满足极大量的读请求。
技术实现要素:
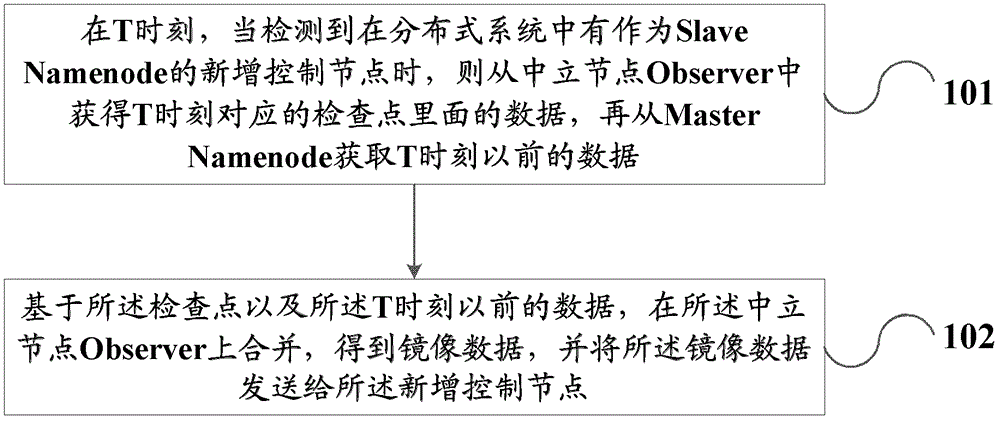
本申请实施例提供了一种分布式文件系统以及数据处理的方法,用以解决基于HDFS的读写分离架构上,Namenode服务器一旦发生故障,或者需要增加Namenode时,数据的一致性以及启动时延长的问题。本申请实施例在读写分离架构的基础上,引入Observer(中立控制节点)角色,该节点不处理任何读写操作,只负责定时的数据合并和启动加速。由于FsImage和Editlog文件合并花费时间较长,Observer即为保存最近的合并数据,用于任何SlaveNamenode启动加速和整个集群的重新启动加速。因此在处理数据之前,本申请实施例提供了一种确定中立控制节点的方法,应用在分布式文件系统中,所述分布式文件系统包括至少两个控制节点,与所述至少两个控制节点分别连接的至少一个数据节点,其中,所述至少两个控制节点包括用于写数据的第一控制节点以及用于读数据的第二控制节点,所述第一控制节点与所述第二控制节点为不相同的节点,所述方法包括:通过自由选举算法从所述第二控制节点中选举出一个控制节点作为第三控制节点,所述第三控制节点用于合并数据镜像及数据日志的中立控制节点;或者,当检测到在所述分布式系统中有新增控制节点时,接收所述新增控制节点的用于推选自己作为所述中立控制节点的请求;基于所述请求,判断所述分布式文件系统中是否存在所述第三控制节点且在存在的情况下所述第三控制节点的状态是否为有效状态;如果所述第三控制节点不为有效状态,则确定所述新增控制节点为所述中立控制节点。本申请实施例还提供一种数据处理的方法,应用在分布式文件系统中,所述分布式文件系统包括至少三个控制节点,与所述至少三个控制节点分别连接的至少一个数据节点,其中,所述至少三个控制节点中包括一个用于负责数据写入的第一控制节点,至少一个用于负责数据读取的第二控制节点,以及一个作为用于合并数据镜像及数据日志的中立控制节点,所述第一、第二控制节点以及所述中立控制节点为各不相同的节点,所述方法包括:在T时刻,当检测到在所述分布式系统中有作为所述第二控制节点的新增控制节点时,则从所述中立控制节点获得所述T时刻对应的检查点里面的数据,再从所述第一控制节点获取所述T时刻以前的数据;所述检查点是基于数据镜像以及数据日志合并而成的;所述数据镜像以及数据日志为从所述第一控制节点获取的数据;基于所述检查点以及所述T时刻以前的数据,在所述中立控制节点上合并,得到镜像数据,并将所述镜像数据发送给所述新增控制节点;或者,在T1时刻,当检测到所述第二控制节点中有无效状态,并在T2时刻恢复有效状态的的第二控制节点时,则从所述第一控制节点获取所述T1到所述T2时间段内的数据。如上所述的数据处理方法,在所述检测到在所述分布式系统中有作为所述第二控制节点的新增控制节点之前,包括:确定所述新增控制节点是否为所述第一控制节点;如果不为所述第一控制节点,则确定所述新增控制节点是否为所述中立控制节点。所述确定所述新增控制节点是否为所述第一控制节点,包括:接收所述新增控制节点的用于推选自己作为所述第一控制节点的请求;基于所述请求,判断所述分布式文件系统中是否存在所述第一控制节点且在存在的情况下所述第一控制节点的状态是否为有效状态;如果所述第一控制节点不为有效状态,则确定所述新增控制节点为所述第一控制节点;如果所述第一控制节点为有效状态,则推选失败,确定所述新增控制节点是否为所述中立控制节点。所述确定所述新增控制节点是否为所述中立控制节点,包括:接收所述新增控制节点的用于推选自己作为所述中立控制节点的请求;基于所述请求,判断所述分布式文件系统中是否存在所述中立控制节点且在存在的情况下所述中立控制节点的状态是否为有效状态;如果所述中立控制节点不为有效状态,则确定所述新增控制节点为所述中立控制节点;如果所述中立控制节点为有效状态,则确定所述新增控制节点为所述第二控制节点。中立控制节点中立控制节点中立控制节点中立控制节点中立控制节点其中,所述分布式系统还包括与所述三个控制节点以及所述数据节点连接的一致性节点,所述数据处理方法还包括:当接收到所述一致性节点发送的第二控制节点断开消息,将与所述断开消息对应的第二控制节点断开TCP连接,并将所述断开消息对应的第二控制节点从本地缓存中移除。进一步的,所述方法还包括:当检测到所述一致性节点与所述第一控制节点的TCP连接断开时,产生一连接断开事件,并将该连接断开事件发送给所述第二控制节点;通过自由选举算法从所述第二控制节点中选举出一个控制节点作为新的第一控制节点;向所述一致性节点发送所述新的第一控制节点的注册信息;建立所述新的第一控制节点与所述第二控制节点的TCP连接,开启数据同步任务。本申请实施例还提供一种分布式文件系统,所述系统包括:至少三个控制节点;所述至少三个控制节点中包括一个第一控制节点、至少一个第二控制节点、一个中立控制节点;与所述至少三个控制节点分别连接的至少一个数据节点;其中,所述第一控制节点作为用于负责数据写入的节点,所述第二控制节点作为用于负责数据读取的节点,所述中立控制节点作为用于合并数据镜像及数据日志的节点,所述第一、第二控制节点以及所述中立控制节点为各不相同的节点;第一检测获取单元,用于在T时刻,当检测到在所述分布式系统中有作为所述第二控制节点的新增控制节点时,则从所述中立控制节点获得所述T时刻对应的检查点里面的数据,再从所述第一控制节点获取所述T时刻以前的数据;所述检查点是基于数据镜像以及数据日志合并而成的;所述数据镜像以及数据日志为从所述第一控制节点获取的数据;基于所述检查点以及所述T时刻以前的数据,在所述中立控制节点上合并,得到完整的数据,并将所述完整的数据发送给所述新增控制节点。进一步的,所述系统还包括:第二检测获取单元,用于在T1时刻,当检测到所述第二控制节点中有无效状态,并在T2时刻恢复有效状态的的第二控制节点时,则从所述第一控制节点获取所述T1到所述T2时间段内的数据。进一步的,所述系统还包括:第一确定单元,用于在所述检测到在所述分布式系统中有作为所述第二控制节点的新增控制节点之前确定所述新增控制节点是否为所述第一控制节点;第二确定单元,用于在如果不为所述第一控制节点,则确定所述新增控制节点是否为所述中立控制节点。所述第一确定单元包括:第一接收单元,用于接收所述新增控制节点的用于推选自己作为所述第一控制节点的请求;第一判断单元,用于基于所述请求,判断所述分布式文件系统中是否存在所述第一控制节点且在存在的情况下所述第一控制节点的状态是否为有效状态;如果所述第一控制节点不为有效状态,则确定所述新增控制节点为所述第一控制节点;如果所述第一控制节点为有效状态,则推选失败,确定所述新增控制节点是否为所述中立控制节点。中立控制节点中立控制节点所述第二确定单元,包括:第二接收单元,用于接收所述新增控制节点的用于推选自己作为所述中立控制节点的请求;第二判断单元,用于基于所述请求,判断所述分布式文件系统中是否存在所述第三控制节点且在存在的情况下所述第三控制节点的状态是否为有效状态;如果所述第三控制节点不为有效状态,则确定所述新增控制节点为所述中立控制节点。进一步的,所述系统还包括:与所述三个控制节点以及所述数据节点连接的一致性节点;检测发送单元,用于当检测到所述一致性节点与所述第一控制节点的TCP连接断开时,产生一连接断开事件,并将该连接断开事件发送给所述第二控制节点;选举单元,用于通过自由选举算法从所述第二控制节点中选举出一个控制节点作为新的第一控制节点;注册信息发送单元,用于向所述一致性节点发送所述新的第一控制节点的注册信息;建立连接单元,用于建立所述新的第一控制节点与所述第二控制节点的TCP连接,开启数据同步任务。一种数据处理的方法,本申请通过以上实施例提供的技术方案,具有以下有益技术效果或者优点:1、在数据读写分离的基础上,引入一个中立控制节点的角色,该中立控制节点不负责任何读写工作,只负责数据镜像FsImage和数据日志Editlog的定时合并,使得任何SlaveNamenode的启动过程加速和整个集群的重新启动加速;2、在MasterNamenode发生故障而失效时,切换过程自动化,且切换时间在秒级别;3、在切换过程中,只中断MasterNamenode数据的写入,对于SlaveNamenode,依然提供读取文件的服务,该服务不会被中断,数据读取影响极小;数据无损,基本不存在丢失;4、冗余安全级别高;即使集群中有1个Namenode存活,服务即可运转,只是性能有损失;5、硬件安全;Namenode硬盘损坏,直接关机更换硬盘,重启即可。6、MasterNamenode具有同步记忆功能,如果某个SlaveNamenode在一段时间内故障然后恢复,MasterNamenode会将这个时间段内的数据同步到SlaveNamenode,同步数据量相对于镜像同步,减少了95%以上。附图说明图1为本申请实施例1提供的分布式文件系统架构信息交互图;图2为本申请实施例1提供的数据处理的方法流程图;图3为本申请实施例2提供的分布式文件系统的结构图。具体实施方式本申请实施例提供了一种分布式文件系统以及数据处理的方法,用以解决基于HDFS的读写分离架构上,Namenode服务器一旦发生故障,或者需要增加Namenode时,数据的一致性以及启动时延长的问题。本发明为了解决上述技术问题,总体思路如下:本申请实施例在读写分离架构的基础上,引入Observer(中立控制节点)角色,该节点不处理任何读写操作,只负责定时的数据合并和启动加速。由于FsImage和Editlog文件合并花费时间较长,Observer即为保存最近的合并数据,用于任何SlaveNamenode启动加速和整个集群的重新启动加速。实现读写分离时,针对HDFS原生的write-one-read-many访问模型,提出了(1+N)多Namenode模式,其中1个Namenode作为MasterNamenode,一般情况下只负责所有写入类操作,另外N个Namenode作为SlaveNamenode,只负责所有读取操作。而MasterNamenode和SlaveNamenode通过自由选举算法在启动HDFS时从所有的Namenode中产生,产生出一个MasterNamenode,其余的都作为SlaveNamenode。N个SlaveNamenode之间具备负载均衡算法,保证每个SlaveNamenode的请求负载数在一段时间内完全一样。下面结合说明书附图用具体的实施例对上述技术方案进行详细的说明。实施例1如图1所示,为本申请实施例提供的分布式文件系统架构信息交互图,引入了Zookeeper(一致性节点)组成的分布式集群,该Zookeeper运行在Namenode之上,在本申请实施例中将Namenode与Zookeeper的比例设置为一一对应关系,当然不一定是一一对应关系,这里使用了一一对应的关系,是为了更好最大化的使用资源,这个关系是不固定的。可以根据实际情况来设置该比例。理论上来讲,Zookeeper集群数量越大,性能相对越好,但是这个性能的提升相对于多使用的服务器硬件来说,是微不足道的,也就是性价比其实很低。Namenode与Zookeeper的比例设置为一一对应关系是个比较好的一个性价比模式。MasterNamenode备份Metadata到所有的SlaveNamenode,该数据同步过程是异步的。其中,该数据同步包含发送接受和处理两个步骤,其中发送接受是同步过程,数据处理是异步过程,即保证数据可以发送到所有的SlaveNamenode,而不用等待所有的SlaveNamenode处理完成。引用了Observer角色,不负责任何的读写数据工作,只负责定时的数据合并和启动加速。由于FsImage和Editlog文件合并花费时间较长,Observer即为保存最近的合并数据,用于任何SlaveNamenode启动加速和整个集群的重新启动加速。Client和Datanode与Namenode之间建立长连接Session,用于事件回调和通知。因此在处理数据之前,本申请实施例提供了一种确定中立控制节点的方法,应用在分布式文件系统中,该分布式文件系统包括至少两个控制节点,与所述至少两个控制节点分别连接的至少一个数据节点,其中,所述至少两个控制节点包括用于写数据的第一控制节点以及用于读数据的第二控制节点,第一控制节点与第二控制节点为不相同的节点,所述方法包括:方法一,通过自由选举算法从第二控制节点中选举出一个控制节点作为第三控制节点,所述第三控制节点用于合并数据镜像及数据日志的中立控制节点;或者,方法二,步骤一,当检测到在所述分布式系统中有新增控制节点时,接收所述新增控制节点的用于推选自己作为所述中立控制节点的请求;步骤二,基于所述请求,判断所述分布式文件系统中是否存在所述第三控制节点且在存在的情况下所述第三控制节点的状态是否为有效状态;如果所述第三控制节点不为有效状态,则确定所述新增控制节点为所述中立控制节点。在本申请实施例中,第一控制节点即为MasterNamenode,第二控制节点即为SlaveNamenode,第三控制节点即为Observer,在HDFS系统第一次引用Observer角色的时候,可以从所有的SlaveNamenode中通过自由选举算法选举产生出作为Observer角色的Namenode;如果在HDFS系统中已经存在了Observer,那么在读取数据的请求量过大时,需要动态增加一个Namenode用作数据读取,那么该Namenode加进该集群时,会首先推选自己作为Observer,由于已经存在了Observer,所以,该推选过程会失败;假如,系统中存在的Observer发生故障,失效,则推选过程可能会成功,并将该Namenode当作Observer的角色。如图2所示,为本申请实施例提供的一种数据处理的方法流程图,应用在如图1所示的分布式文件系统中,所述方法包括:步骤101,在T时刻,当检测到在分布式系统中有作为SlaveNamenode的新增控制节点时,则从中立控制节点Observer中获得T时刻对应的检查点里面的数据,再从MasterNamenode获取T时刻以前的数据;其中,该检查点是基于数据镜像FsImage以及数据日志Editlog定时合并而成的;而合并的时间间隔可以根据具体应用来设置,如果请求数据量很多,则可以很短的间隔就合并一次数据,反之亦然,不再赘述;所述数据镜像以及数据日志为从所述MasterNamenode获取的数据;步骤102,基于所述检查点以及所述T时刻以前的数据,在所述中立控制节点Observer上合并,得到镜像数据,并将所述镜像数据发送给所述新增控制节点;也就是先从Observer里面获得即时数据,从MasterNamenode中获取差额数据,然后在Observer上将两者结合起来,得到最新的镜像数据,并将该数据发送给所述新增的Namenode,这样就完成了数据的镜像同步。所述方法还包括:在T1时刻,当检测到有无效状态,并在T2时刻恢复有效状态的的SlaveNamenode时,则从所述MasterNamenode获取所述T1到所述T2时间段内的数据。MasterNamenode具有同步记忆功能,如果某个SlaveNamenode在一段时间内故障然后恢复,MasterNamenode会将这个时间段内的数据批量同步到SlaveNamenode,同步数据量相对于镜像同步,减少了95%以上。例如,如图1所示的HDFS架构中,有一个从控制节点在2012年2月23日9点钟发生故障,但在十分钟过后,恢复正常工作,则主控制节点会将9点到9点10分这十分钟的数据批量同步到该从控制节点中,而批量同步数据量相对于镜像同步,减少了95%以上。镜像同步,就是把100%的数据,全部推送过去;批量同步,就是把一段时间的数据,可能是1%,2%,一次性同步过去。实施例2如图3所示,为本申请实施例提供的一种分布式文件系统的结构图,该系统包括:一个MasterNamenode(主控制节点)201,用于负责数据写入的节点至少一个SlaveNamenode(从控制节点)202,用于负责数据读取的节点;一个Observer(中立控制节点)203,用于合并数据镜像及数据日志的节点;第一检测获取单元204,用于在T时刻,在T时刻,当检测到在分布式系统中有作为SlaveNamenode的新增控制节点时,则从中立控制节点Observer中获得T时刻对应的检查点里面的数据,再从MasterNamenode获取T时刻以前的数据;该检查点是基于数据镜像FsImage以及数据日志Editlog定时合并而成的;而合并的时间间隔可以根据具体应用来设置,如果请求数据量很多,则可以很短的间隔就合并一次数据,反之亦然,不再赘述;所述数据镜像以及数据日志为从所述MasterNamenode获取的数据;基于所述检查点以及所述T时刻以前的数据,在所述中立控制节点上合并,得到完整的数据,并将所述完整的数据发送给所述新增控制节点。进一步的,所述系统还包括:第二检测获取单元205,用于在T1时刻,当检测到所述第二控制节点中有无效状态,并在T2时刻恢复有效状态的的第二控制节点时,则从所述第一控制节点获取所述T1到所述T2时间段内的数据。进一步的,所述系统还包括:第一确定单元,用于在所述检测到在所述分布式系统中有作为所述第二控制节点的新增控制节点之前确定所述新增控制节点是否为所述第一控制节点;第二确定单元,用于在如果不为所述第一控制节点,则确定所述新增控制节点是否为所述中立控制节点。进一步的,第一确定单元包括:第一接收单元,用于接收所述新增控制节点的用于推选自己作为所述第一控制节点的请求;第一判断单元,用于基于所述请求,判断所述分布式文件系统中是否存在所述第一控制节点且在存在的情况下所述第一控制节点的状态是否为有效状态;如果所述第一控制节点不为有效状态,则确定所述新增控制节点为所述第一控制节点;如果所述第一控制节点为有效状态,则推选失败,确定所述新增控制节点是否为所述中立控制节点。进一步的,第二确定单元,包括:第二接收单元,用于接收所述新增控制节点的用于推选自己作为所述中立控制节点的请求;第二判断单元,用于基于所述请求,判断所述分布式文件系统中是否存在所述第三控制节点且在存在的情况下所述第三控制节点的状态是否为有效状态;如果所述第三控制节点不为有效状态,则确定所述新增控制节点为所述中立控制节点。中立控制节点中立控制节点进一步的,所述系统还包括:与所述三个控制节点以及所述数据节点连接的一致性节点;检测发送单元,用于当检测到所述一致性节点与所述第一控制节点的TCP连接断开时,产生一连接断开事件,并将该连接断开事件发送给所述第二控制节点;选举单元,用于通过自由选举算法从所述第二控制节点中选举出一个控制节点作为新的第一控制节点;注册信息发送单元,用于向所述一致性节点发送所述新的第一控制节点的注册信息;建立连接单元,用于建立所述新的第一控制节点与所述第二控制节点的TCP连接,开启数据同步任务。运用本申请实施例提供的如图1所示的HDFS架构,如果系统读请求较高,则需要动态增加一台新的Namenode,本申请实施例提供的系统可以动态的扩容Namenode节点,且实现启动时间快,数据不丢失,其工作原理如下:1)新增的Namenode启动,向Zookeeper服务发送注册信息,首先推选自己为MasterNamenode,如果集群中已经存在MasterNamenode,且该MasterNamenode为有效状态,则该推选过程会失败;否则,再看集群配置,在满足最少第二控制节点(SlaveNamenode)数N的基础上,N大于等于零,再推选自己为中立控制节点;当N=0的时候,意味着读写请求都在第一控制节点之上,因此,此时将新增控制节点作为SlaveNamenode,作为专门负责读数据的节点,实现读写分离。由于如图1所示的系统集群配置中,有至少两个SlaveNamenode,因此,该新增控制节点推选自己为中立控制节点,如果该系统存在有效中立控制节点,则推选失败,所以,该新增控制节点作为第二控制节点,否则作为中立控制节点。集群中必须有1个第一控制节点(MasterNamenode),至少N(N>=0,看系统如何设置)个SlaveNamenode配置节点,在满足这个前提后,新加入的控制节点才会去竞选中立控制节点,否则会先推选出第一控制节点,再凑足N个第二节点控制节点。2)如果该新增控制节点以ObserverNamenode启动,则进行ObserverNamenode节点的工作,负责定时的完成FsImage和Editlog的合并工作,生成checkpoint(检查点)。3)如果该新增控制节点以SlaveNamenode启动,则从ObserverNamenode上获取最新的CheckPoint并加载,然后从MasterNamenode获取差额数据,在CheckPoint基础上合并成最新的镜像数据。4)如果该新增控制节点作为MasterNamenode启动,则开启批量同步数据任务,向其他控制节点同步数据。同理,运用本申请实施例提供的如图1所示的HDFS架构,如果系统读请求较低,不需要那么多用作读数据的SlaveNamenode,则可以动态缩容Namenode节点,其工作原理如下:1)关闭一台SlaveNamenode;2)Zookeeper集群检测到Session(会话)连接断开,产生NodeDisconnect(节点断开)事件,并将所述NodeDisconnect下发到所有的Client和Namenode;3)Client将该SlaveNamenode地址从本地缓存移除,与该SlaveNamenode的所有连接事务都断开。4)同时,MasterNamenode也断开与该SlaveNamenode的同步连接。MasterNamenodefailover过程:1)当Master节点失效的时候,Zookeeper集群感知到与Master节点的TCP连接断开,产生Disconnect事件,并下发到所有的Client、Namenode和Datanode。2)所有的Namenode接收到此事件,通过自由选举算法开始新一轮的选举,如果选举失败,则关闭原先的同步连接,等待向新MasterNamenode注册。3)如果选举成功,则产生一个新的MasterNamenode,此时,先关闭与SlaveNamenode的所有TCP连接,应用完缓冲队列中的所有数据,然后开启注册端口,并向Zookeeper集群标注自己已经是Master节点。4)Zookeeper节点向所有的Namenode下发最新的Namenode列表,其他竞争失败的SlaveNamenode接收此事件,向新的MasterNamenode注册。5)新的MasterNamenode建立起所有的连接,开启常规的数据同步任务,至此自动切换完成。在此切换过程中,SlaveNamenode依然提供读取文件的服务,该服务不会被中断。该数据的同步是半异步过程。即MasterNamenode发送数据到SlaveNamenode,收到来自SlaveNamenode合法的ACK报文,即认为同步完成。同步数据的应用,是异步过程。该同步对整个数据写入过程的损耗较低。本申请通过以上实施例提供的技术方案,具有以下有益技术效果或者优点:1、在数据读写分离的基础上,引入一个中立控制节点的角色,该中立控制节点不负责任何读写工作,只负责数据镜像FsImage和数据日志Editlog的定时合并,使得任何SlaveNamenode的启动过程加速和整个集群的重新启动加速;2、在MasterNamenode发生故障而失效时,切换过程自动化,且切换时间在秒级别;3、在切换过程中,只中断MasterNamenode数据的写入,对于SlaveNamenode,依然提供读取文件的服务,该服务不会被中断,数据读取影响极小;数据无损,基本不存在丢失;4、冗余安全级别高;即使集群中有1个Namenode存活,服务即可运转,只是性能有损失;5、硬件安全;Namenode硬盘损坏,直接关机更换硬盘,重启即可。6、MasterNamenode具有同步记忆功能,如果某个SlaveNamenode在一段时间内故障然后恢复,MasterNamenode会将这个时间段内的数据同步到SlaveNamenode,同步数据量相对于镜像同步,减少了95%以上。尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1