一种基于语义的海量数据处理方法与流程
本发明涉及数据处理技术领域,具体涉及一种基于语义的海量数据处理方法。
背景技术:
随着Web2.0技术的快速发展,互联网络经历了从信息(网页)与信息(网页)互连的WWW阶段、物与物互连的物联网时代、人与人互连的社会网络时代及其人与物与所有信息相融合的综合互连时代。人在互联网中产生的信息(BBS,评论,社交网络,微博等),尤其是机器(传感器及其各类处理器生成的分析数据等等)时时刻刻都在不断产生新的数据。根据国际数据公司IDC2011年发布的DigitalUniverseStudy,全球信息总量每过两年,就会增长一倍。仅在2011年,全球被创建和被复制的数据总量为1.8ZB(1.8万亿GB)。相较2010年同期上涨超过1ZB,到2020年这一数值将增长到35ZB。大数据已经成为当今信息处理最为关键的问题之一。随着互联网的飞速发展,云计算与物联网技术得到了飞速发展。海量数据,在国外一般又称为大数据(BigData)。IBM把海量数据概括成了三个V,即Volume(数据规模巨大)、Variety(数据类型及其来源广泛多样)和Velocity(快速化)。2011年2月11日美国出版的《科学》(Science)期刊专门出版了一期数据处理(DealingwithData)的专辑,其主题是围绕目前科学研究数据的海量增加展开讨论,说明海量数据对科学研究的重要性。随后的2011年9月4日,《自然》(Nature)也就海量数据处理设立了一个专门的专题,讨论分析了现代科学研究面临的一个巨大挑战就是如何处理已有的海量数据。云计算与物联网环境下海量数据的处理是一个极为复杂的问题。如何让上亿条数据查询计划能够在几秒内完成,如何能够快速定位到用户所需的数据块的位置,这些均给数据的处理提出了巨大的挑战。由于云计算与物联网的飞速发展,越来越多的云应用需要处理和管理海量的数据。用户对于海量文件的查询处理速度的需求等越来越高,从而如何处理这些海量数据将成为其中重要的一个环节。为了实现较好地处理这些云应用的海量数据,需要研究一种基于语 义的海量数据处理方法,为海量数据的处理计算提供较好的处理效率。
技术实现要素:
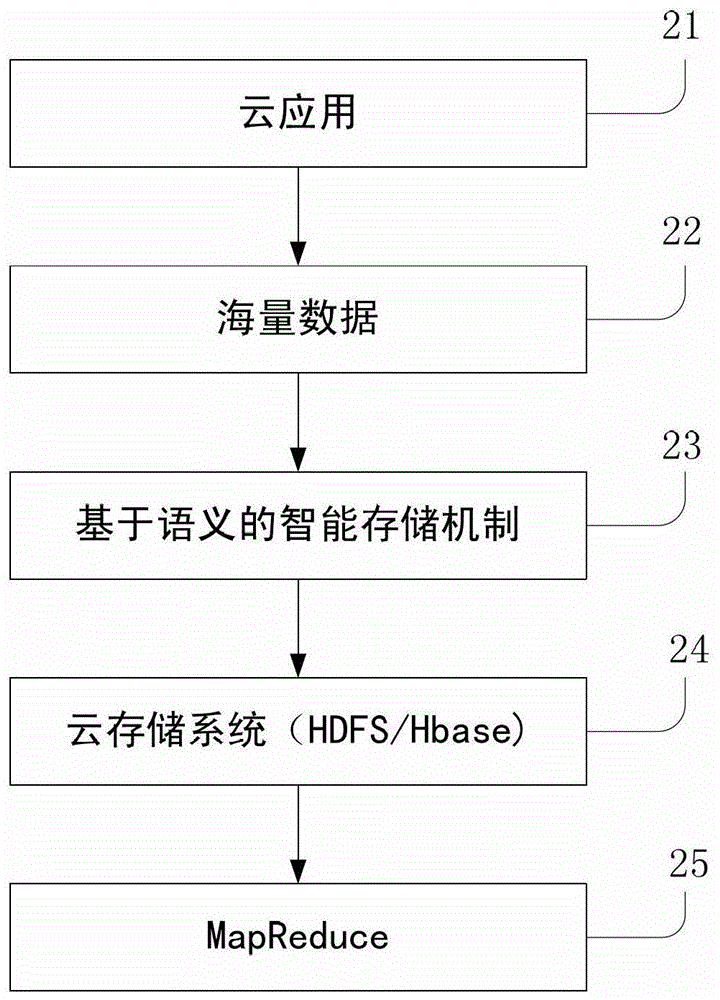
为了克服现有技术在处理海量数据能力上的不足,本发明的目的在于提供一种基于语义的海量数据处理方法,可以提高云环境海量数据的处理效率,从而更好地服务于人类需求。为实现以上目的,本发明采取以下的技术方案:一种基于语义的海量数据处理方法,其包括以下步骤:A、对不同的云应用,分别将所述云应用中的所有的海量数据进行语义处理,形成智能分布式的语义索引机制;B、对云应用中所有的元数据和数据按照所述语义索引机制进行语义存储到相应的云存储系统中,以使具有语义关联的数据存储紧密;C、对存储于云存储系统中的云应用执行海量数据的MapReduce计算。云应用,包括所有的云环境下的应用,如社交网络、电信应用、证券应用等等。所述步骤B包括以下步骤:B1、按照所述语义索引机制获得子云应用;B2、对所述子云应用的元数据分配到元数据服务器,其具体包括以下情况:B21、若子云应用的数量小于元数据服务器的数量,则每个子云应用的元数据均分配一个元数据服务器;B22、若子云应用的数量等于元数据服务器的数量,则每个子云应用的元数据均分配一个元数据服务器;B23、若子云应用的数量大于元数据服务器的数量,则按照以下步骤执行元数据库服务器的分配:B231、给每个元数据服务器均先分配一个子云应用的元数据;B232、剩余的子云应用的元数据继续按照一个子云应用的元数据对应分配给一个元数据服务器的方式进行分配,分配过程中,须使每个元数据服务器的元数据之和均衡;B233、重复步骤B232,直到将所有的子云应用的元数据分配完成;B3、将子云应用的数据分配到数据存储节点集群,其具体包括以下步骤:B31、计算每个子云应用的负载,并将所有的子云应用的负载求和获取负载和,根据所述数据存储节点集群的具体数量计算出每台数据存储节点的平均存储负载;B32、列出子云应用中所有负载位于平均存储负载阈值范围内的所有子云应用,并将这些满足条件的子云应用的数据分配到一台数据存储节点中;B33、计算子云应用的负载之和位于平均存储负载阈值范围内的所有子云应用,并将这些满足条件的子云应用的数据分配到一台数据存储节点中;B34、将子云应用的负载大于平均存储负载阈值的所有子云应用进行分割,分割后的负载尽量均位于平均存储负载阈值的范围内,并将分割后的子云应用所对应的所有数据分配至不同的数据存储节点;B35、重复步骤B31-B34,直到所有的子云应用的数据分配完成。所述平均存储负载阈值为[90%平均存储负载,110%平均存储负载]。所述子云应用为将一社区网络按照社会网络算法得到的子社区,其中,所述社区网络为各种基于社会网络的数据密集型应用的文件通过一个聚类或者社会网络算法得到的。所述社会网络算法为聚类算法。所述子云应用为将本体网络或标记网络进行分割,让有联系的元数据文件集中在一起,同时对该有联系的元数据文件进行相应的聚合而形成的相应的语义聚合对,其中,所述本体网络或标记网络为根据各种语义算法对各种来自分类的密集型应用的文件进行语义计算得到的。海量数据,包括所有的云环境下的应用所涉及到的各种海量数据,如社交网络的记录、电信应用的电话通信记录及其证券应用中的证券交易记录等等。同时,海量数据,既包括海量大文件也包括海量小文件,既包括海量结构化数据,也包括海量半结构化数据及其海量非结构化数据。所述云存储系统包括用来存储海量非结构化数据的云文件系统、以及用于存储海量结构化数据和海量半结构化数据的云数据库系统。所述云文件系统包括单一Master节点的云文件系统,以及大于一个Master节点的Master集群的云文件系统。所述云数据库系统包括单一Master节点的云数据库系统,以及大于一个Master节点的Master集群的云数据库系统。MapReduce,它是一种现有的处理海量数据的编程模型。只要能够实现较好的存储,则那些关系紧密的数据会存储在同一台机器上,会大大减少MapReduce的迁移时间,从而提高MapReduce的执行效率。本发明与现有技术相比,具有如下优点:本发明针对不同的云应用,分别将它们的所有海量数据进行一个语义处理,形成一种智能的分布式语义索引机制,同时云中的所有的元数据和数据将按照该语义索引机制进行语义存储到相应的云存储系统(如分布式文件系统或者云数据库系统)。按照这种基于语义的海量数据存储方法,将会使得那些具有语义关联比较高的数据存储的比较紧密,当各种云应用需要执行对海量数据的MapReduce计算时,会在同一台机器上对同一个作业执行较多的Map或者Reduce任务,从而减少数据迁移的时间消耗,将会较好地提高海量数据的处理效率。附图说明图1是本发明基于语义的海量数据处理方法的流程示意图;图2为本发明基于语义的海量数据处理方法的体系框架图;图3为本发明基于语义的智能存储机制框图;图4为本发明基于社会网络的数据密集型应用大小文件语义处理机制框图;图5为本发明基于分类的数据密集型应用的大小文件语义处理机制框图。具体实施方式下面结合附图和具体实施方式对本发明的内容做进一步详细说明。图2展示了基于语义的海量数据处理方法的基本框架。它主要包含如下几个部分:云应用21、海量数据22、基于语义的智能存储机制23、云存储系统24及其MapReduce25。云应用21是指云环境下的各种数据密集型或计算密集型的应用,包括所有的云环境下的应用,如社交网络、电信应用、证券应用等等。海量数据22,它是指各种云应用所产生的各种海量的TB级甚至PB级别的数据。海量数据22包括所有的云环境下的应用所涉及到的各种海量数据,如社交网络的记录、电信应用的电话通信记录及其证券应用中的证券交易记录等等。同时,海量数据,既包括海量大文件也包括海量小文件,既包括海量结构化数 据,也包括海量半结构化数据及其海量非结构化数据。基于语义的智能存储机制23,它是一种用来决定海量数据及其相关的元数据存储位置的一种智能机制。详细的分析请见对图3的说明。云存储系统24,它主要包括用来存储非结构化数据的云文件系统和用于存储结构化或者半结构化数据的云数据库系统,其中云文件系统既包括单一Master节点的云文件系统,也包括大于一个Master节点的Master集群的云文件系统。云数据库系统既包括单一Master节点的云数据库系统,也包括大于一个Master节点的Master集群的云数据库系统。MapReduce25,它是一种现有的处理海量数据的编程模型。只要能够实现较好的存储,则那些关系紧密的数据会存储在同一台机器上,会大大减少MapReduce的迁移时间,从而提高MapReduce的执行效率图3展示了基于语义的智能处理的总体框架。基于语义的智能处理的总体框架包括:数据密集型应用的判断31、各种数据密集型应用的海量数据32、基于社会网络的应用元数据存储节点集群分配33、基于分类的(本体分类或者标记分类等)应用元数据存储节点集群分配34、基于社会网络的应用数据存储节点集群分配35、基于分类的(本体分类或者标记分类等)应用数据存储节点集群分配36。根据云环境下数据密集型应用(包括存储密集型应用和计算密集型应用),我们总结了二种数据密集型应用,分别为基于社会网络的应用和基于分类的(本体分类或者标记分类)的数据密集型应用。1)首先使用数据密集型应用的判断方法对来自云环境的各种海量数据进行一个判断,然后将它们进行归类。在图3中我们展示了其中的两类:基于社会网络的应用和基于分类的(本体分类或者标记分类)的应用。2)对于那些社会网络的应用如(Twitter,FaceBook,人人网,腾讯微博及其新浪微博等)这种应用,则按照基于社会网络应用的元数据存储节点集群分配进行元数据分配,同时进行其对应的按照基于社会网络应用的数据存储节点集群分配进行数据分配。具体实施方式见图4所示。3)对于那些分类的应用如(本体关联比较大的应用等)这种应用,则按照基于分类的应用的元数据存储节点集群分配进行元数据分配,同时进行其对应的按照基于分类的应用的数据存储节点集群分配进行数据分配。具体实施方式 见图5所示。实施例一基于社会网络的数据密集型应用大小文件语义处理机制。具体的基于社会网络的数据密集型应用大小文件语义处理机制,请参阅图1和图4。对于社会网络的各种应用系统(Twitter,FaceBook,人人网,腾讯微博及其新浪微博等)非常适合这种存储方法。首先使用目前所有的各种社会网络算法(如:聚类算法就是其中的一种),对各种来自社会网络应用的文件进行一个聚类或者社会网络算法的其他操作。通过计算后得到一个巨大的社区网络。S11、按照社会网络的算法,将该巨大的社区网络进行语义处理,形成智能分布式的语义索引机制。S12、对云应用中所有的元数据和数据按照语义索引机制进行语义存储到相应的云存储系统中,具体是:1)根据语义索引机制得到该巨大的社区网络的子社区。图4显示了某个社会网络社区总共有5个子社区(或称之为圈子)。其中有些节点(图中的连接子社区之间的节点)是非常关键的节点,又称为结构洞。2)按照子社区,将元数据分配到元数据服务器集群中。其分配原则为:若子社区数量小于元数据集群中元数据服务器的数量,则每个子社区的元数据分配一个元数据服务器。当然这种情况并不多见。若子社区数量等于元数据集群中元数据服务器的数量,则每个子社区的元数据分配一个元数据服务器。当然这种情况也并不多见。若子社区数量大于元数据集群中元数据服务器的数量,则按照如下步骤执行分配:■步骤一:首先给每个子社区的元数据分配一个元数据服务器。■步骤二:剩余的子社区继续按照每个子社区分配一个元数据服务器的方式进行分配。但是在分配过程中尽量保持每个子社区的元数据的负载均衡。例如:假设某个元数据服务器A在已经分配的子社区的元数据量很小,在后面的分配中,则给其分配一个元数据量相对比较大的子社区的元数据。■步骤三:重复步骤二,直到将所有的子社区的元数据分配完成。子社区的元数据的分配不进行分割,只能分配在一台元数据服务器上。也就是说不将一个子社区的元数据分配给两台或者两台以上的元数据服务器上,主要原因是一个子社区的元数据放在同一元数据服务器会减少元数据维护时间,同时由于采用元数据集群的方式,元数据服务器的承载是在可接受的范围内的。图4所示的子社区1和子社区3的所有元数据分配给了元数据服务器1;子社区2和子社区4的所有元数据分配给了元数据服务器2;子社区5的所有元数据分配给了元数据服务器3.3)按照子社区,将数据分配到数据存储节点集群中(注意:这里只考虑主副本的分配,其他的副本随机即可)。它的分配原则和元数据的分配原则不同,它主要考虑负载均衡的问题,其分配方法可以按照如下步骤进行:步骤一:计算每个子社区的负载(即数据量),计算所有子社区的负载总和,计算每台数据存储节点的理想的平均存储负载。步骤二:计算出社区负载接近平均存储负载(假设阈值为:[90%平均存储负载,110%平均存储负载])的所有子社区,将满足这些条件的所有子社区分配给一台数据存储节点。步骤三:计算出那些小的子社区,并计算出那些子社区的负载之和接近平均存储负载(假设阈值为:[90%平均存储负载,110%平均存储负载])的所有子社区,将这些满足条件的子社区的组合分配给一台数据存储节点。步骤四:将那些大的子社区按照负载进行分割,例如某个大的子社区的负载等于6个平均存储负载,则将该大的子社区的所有数据存储负载分配给六台数据存储节点。步骤五:重复步骤一到步骤四,直到将所有子社区的数据分配完成。图4所示的子社区1的所有数据分配给了数据存储节点2;子社区2和子社区3的所有数据分配给了数据存储节点q;子社区4的所有数据分配给了数据存储节点2。S13、对存储于云存储系统中的所有云应用执行海量数据的MapReduce计算,根据步骤S12的存储方式可以在MapReduce计算过程中,会在同一台机器上对同一个作业执行较多的Map或者Reduce任务。实施例二基于分类的数据密集型应用的大小文件语义处理机制。对于一些基于分类的数据密集型应用(如语义搜索引擎等),请参阅图1和图5所示。首先使用目前所有的各种语义算法(如:本体生成算法、标记网络),对各种来自分类的密集型应用的文件进行各种语义计算得到一个本体网络或者标记网络等。S11、按照语义算法,将该巨大的社区网络进行语义处理,形成智能分布式的语义索引机制。S12、对云应用中所有的元数据和数据按照语义索引机制进行语义存储到相应的云存储系统中,具体是:1)对上述得到的本体网络或者标记网络进行分割,让有联系的元数据文件尽量集中在一起,同时对它们进行相应的聚合,形成相应的语义聚合对。2)分配给元数据存储节点集群,有关联的元数据尽量分配在同一个元数据存储节点。这些有关联的元数据聚合后形成的语义聚合对的具体分配步骤如下:若语义聚合对数量小于元数据集群中元数据服务器的数量,则每个语义聚合对的元数据分配一个元数据服务器。当然这种情况并不多见。若语义聚合对数量等于元数据集群中元数据服务器的数量,则每个语义聚合对的元数据分配一个元数据服务器。当然这种情况也并不多见。若语义聚合对数量大于元数据集群中元数据服务器的数量,则按照如下步骤执行分配:■步骤一:首先给每个语义聚合对分配一个元数据服务器。■步骤二:剩余的语义聚合对继续按照每个语义聚合对分配一个元数据服务器的方式进行分配。但是在分配过程中尽量保持每个语义聚合对的元数据的负载均衡。例如:假设某个元数据服务器A在已经分配的语义聚合对的元数据量很小,在后面的分配中,则给其分配一个元数据量相对比较大的语义聚合对的元数据。■步骤三:重复步骤二,直到将所有的语义聚合对的元数据分配完成。语义聚合对的元数据的分配不进行分割,只能分配在一台元数据服务器上。也就是说不将一个语义聚合对的元数据分配给两台或者两台以上的元数据服务器上,主要原因是一个语义聚合对的元数据放在同一元数据服务器会减少元数 据维护时间,同时由于采用元数据集群的方式,元数据服务器的承载是在可接受的范围内的。3)按照语义聚合对,将数据分配到数据存储节点集群中(注意:这里只考虑主副本的分配,其他的副本随机分配即可)。它的分配原则和元数据的分配原则不同,它主要考虑负载均衡的问题,其分配方法可以按照如下步骤进行:步骤一:计算每个语义聚合对的负载,计算所有语义聚合对的负载总和,计算每台数据存储节点的理想的平均存储负载。步骤二:计算出语义聚合对接近平均存储负载(假设阈值为:[90%平均存储负载,110%平均存储负载])的所有语义聚合对,将满足这些条件的所有语义聚合对分配给一台数据存储节点。步骤三:计算出那些小的语义聚合对,并计算出那些语义聚合对的负载之和接近平均存储负载(假设阈值为:[90%平均存储负载,110%平均存储负载])的所有语义聚合对,将这些满足条件的语义聚合对的组合分配给一台数据存储节点。步骤四:将那些大的语义聚合对按照负载进行分割,例如某个大的语义聚合对的负载等于6个平均存储负载,则将该语义聚合对所对应的所有数据分配给六台数据存储节点。步骤五:重复步骤一到步骤四,直到将所有语义聚合对的数据分配完成。S13、对存储于云存储系统中的所有云应用执行海量数据的MapReduce计算,根据步骤S12的存储方式可以在MapReduce计算过程中,会在同一台机器上对同一个作业执行较多的Map或者Reduce任务。上列详细说明是针对本发明可行实施例的具体说明,该实施例并非用以限制本发明的专利范围,凡未脱离本发明所为的等效实施或变更,均应包含于本案的专利范围中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1