一种基于Web信息的本体概念属性学习方法与流程
本发明涉及本体学习技术和互联网技术领域,特别涉及到一种基于Web信息的本体概念属性学习方法。
背景技术:
语义Web直是计算机研究的热点领域,其研究重点主要是围绕如何把Web中的信息表示为机器所能够理解和处理的形式,即带有语义。本体作为种能在语义和知识层次上描述概念模型的建模工具,是语义Web中语义描述的核心和关键。目前,本体已经作为提供领域知识支持的重要资源广泛地应用于知识工程、信息检索、问答系统等各种智能信息处理任务中。本体学习是通过机器学习、统计学方法和自然语言处理等技术自动或半自动地从已有的数据资源中获取期望的本体知识。由于实现完全自动的知识获取技术尚不现实,所以,通常本体学习是在用户指导下进行的一个半自动的过程。在本体论概念知识搭建中,描述某一概念模型时,不仅要给出概念名词,而且要给出概念所反映的客观实体的属性描述,称这些属性为概念属性。本体属性作为领域本体知识库构建和应用的重要组成部分,是领域本体知识库自动或半自动构建的一个基础性研究工作的重点,目前国内外相关研究主要集中在本体概念实例及属性的提取,或是概念属性与属性值对的提取,并取得了一定的进展。本体概念属性提取的研究方法主要分为三类:基于规则的方法:它首先构造基于词语、词性以及语义的模式规则集合并把它们存储起来。在属性提取时,运用语言学知识将欲处理的语句片段与模式规则集合中存储的模式进行匹配,如果匹配成功,则认为该语句具有相对应模式的关系。基于规则的方法需要领域专家参与制定模式规则,此方法代价昂贵,且缺少领域可移植性;基于统计的机器学习方法:基于统计的机器学习的方法是现阶段进行概念属性提取过程中广泛应用的一种方法。首先利用机器学习算法将人工标注的语料训练成个分类器模型,然后将构建的分类器用于对未标注的语料的预测上,实现对预先定义的类别进行识别。该方法当前使用比较广泛,也取得了客观的成绩。基于半结构化/结构化数据文档的方法:通过分析半结构/结构化数据文档结构从中提取概念属性也是当今进行概念属性提取的一种主要方法。但这种方法的不足之处在于其只适应于文档格式比较固定且完整的文档,缺乏泛化能力。
技术实现要素:
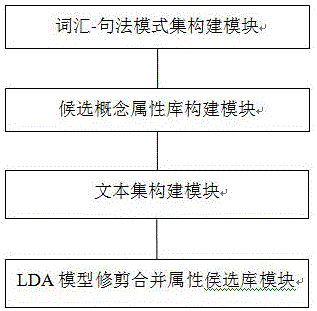
本发明的目的提供出一种基于Web信息的本体概念属性学习方法,结合基于语言学模式和基于概率统计等技术进行本体概念属性学习,将LDA模型应用于本体的概念属性选取阶段,以达到更加准确有效地生成本体概念属性。为了达到上述发明目的,本发明提出种基于规则和机器学习的、与文档结构无关的混合方法进行本体概念属性学习,采用词汇-句法模式构建模式集,以Web作为语料库进行候选概念属性词提取,并根据提取结果构建文本集作为LDA模型的输入,利用Gibbs抽样获取LDA模型的训练参数,运行LDA模型后根据提取结果对本体候选概念属性词库进行修剪与合并,得到最终的概念属性集合。本发明给出下述技术方案:一种基于Web信息的本体概念属性学习方法,其特征在于,包括如下步骤:(1)词汇-句法模式集的构建。根据已有的基本语言模式集,利用词汇-语义模式构建并合并表示包含关系的动词形式扩充模式集,最终建立表达概念属性的模式集,作为候选概念属性抽取算法输入的一部分。(2)候选概念属性库的构建。以Google搜素引擎作为Web数据来源(语料库),首先构建语言模式集,作为Google的查询输入,提取对应的网页查询片段集合和源网址URL集合。然后根据查询得到的网页片段,根据词频统计获得候选属性词(词频率越高,为属性词的可能性越大),经过简单筛选就可以得到候选概念属性词集。(3)文本集的构建。根据候选词库中的属性词,保留其对应的源网址并进行网页提取。对提取的网页文档集合,采用Apache的开源工具OpenNLP作文本预处理,主要是用OpenNLP作词性标注。(4)LDA修剪合并概念属性集。根据输入的文本集,结合Gibbs抽样参数估计的结果,运行LDA模型。根据LDA模型多次迭代的提取结果修剪和合并候选概念属性词库,得到最终的概念属性集合。上述本体概念属性学习方法中,所述步骤(2)中具体包括:1)根据模式集P中的每个模式pi,分别在Google中执行每个查询pi;2)对每个查询pi返回的总查询结果页数N中的每个n,如果(查询结果包含在<em></em>标签中),则提取相应的网页片段Si和提取对应的源网址(URL)Ui,直到模式集P都查询完成;3)网页片段集中的每个片段Si,作词频统计Cwi和剔除非名词Wn。上述本体概念属性学习方法中,所述步骤(3)中具体包括:1)对URL集中的每个Ui,提取对应的网页内容存为文档di;2)对文档集D中的每个文档di,用OpenNLP作预处理;3)如果wi的词性为NN/NNS/NNP/NNPS,提取词wi,直到处理完文档集D。上述本体概念属性学习方法中,所述步骤(4)中具体包括:1)在主题层,对主题词集T中的每个主题词z,抽取混合参数2)在文档层,对文档集D中的每篇文档d,抽取混合参数和从泊松分布中抽取个值作为文档长度,即每篇文档的长度Nd∶Poiss(ξ);3)在2)条件下的词层,对文档d中词集Nd中的每个词n,抽取主题和抽取术语词4)不断重复步骤1)、2)、3)三个步骤构成随机生成过程,直到把D篇文档全部遍历。本发明的技术方案利用Web作为语料库解决模式学习的过程中经常出现数据稀疏问题,使用LDA模型修剪合并候选概念属性词库,能够较大地提高提取结果的准确率,从而使得半自动化地构造本体成为可能,为自动化构建本体奠定基础。附图说明图1为本发明本体概念属性学习的模型架构图;图2为图1模型架构图的整体框架图;图3为图2中LDA模型的结构图;图4为图1模型架构图在car领域中得到的属性提取结果图。具体实施方式如图1的模型架构图所示,根据本发明具体实施例的本体概念属性学习方法包括如下步骤:1)词汇-句法模式集构建模块模式作用:语言模式集作为Google查询必要的输入,因此需要首先构建模式集。根据目前已有的自然语言处理技术,构造基于词语、词性以及语义的模式规则集合(即语言模式),通过模式匹配,识别文本中感兴趣的关系。本实施例中研究一种语言模式——词汇-句法模式(lexical-syntacticpatterns),根据已有的基本语言模式集,利用词汇-语义模式构建并合并表示包含关系的动词形式扩充模式集,最终建立表达概念属性的模式集,作为候选概念属性词提取算法输入的一部分。词汇-句法模式的含义可以直观的从下面的例子中看出:设目标串为cdabfdbab,模式串为ab,则模式匹配后查找到目标串中与模式串相同的子串的首位置是3和8。本实施例中选择car为概念主题,它的概念属性检测模式如表1所示。表1概念属性检测模式其中,通用模式中的NP可以是任意概念名词(本实施例中为car),举例中的黑色粗体词就是car的属性候选词。2)候选概念属性词库构建模块模块作用:基于Web的候选概念属性提取,建立候选概念属性词库。以Google搜素引擎作为Web数据来源(语料库),以语言模式集作为Google的查询输入,提取对应的网页查询片段集合和源网址URL集合。然后根据查询得到的网页片段,根据词频统计获得候选属性词(词频率越高,为属性词的可能性越大),经过简单筛选就可以得到候选概念属性词集。根据候选概念属性提取算法的提取结果,本实施例中提取到的部分网页片段、候选属性词及其对应属性词的词频结果如表2所示。表2部分网页提取结果示例本实施例中,采用语言模式在Web中进行候选属性词提取后,由于概念属性词都是名词词性,因此剔除非名词词性的单词,最终得到一个候选属性词库。3)文本集构建模块模式作用:候选属性词库并不能确立为最终的属性词集,还需要使用LDA模型进步提取概念属性相关的词。文本集是LDA模型的个重要输入。在上述Web的候选概念属性提取过程中,不仅可以得到候选属性词库,还可以得到源网址集合。根据候选词库中的属性词,保留其对应的源网址并进行网页提取。对提取的网页文档集合,采用Apache的开源工具OpenNLP做基本的预处理,如词性标注等。以名词组成的文本集作为LDA模型输入的一部分。这样,结合Gibbs抽样参数估计的结果,就可以运用LDA模型做属性词提取。4)LDA模型修剪合并候选属性库模块模块作用:用LDA模型的提取结果对候选概念属性词库进行修剪和合并,提高属性学习结果的准确率。具体算法可用伪代码表示如下:i.在主题层,对主题词集T中的每个主题词z,是从一个从参数为β的Dirichlet先验分布中抽取出来的Multinomial分布,即抽取混合参数ii在文档层,对文档集D中的每篇文档,从泊松分布中抽取一个值作为文档长度,即每篇文档的长度Nd∶Poiss(ξ),再从一个参数为α的Dirichlet先验分布中抽取出个Multinomial分布作为该文档d里面出现每个主题下词的概率,即抽取混合参数iii.在ii条件下的词层,即对于文档d中的第n个词,首先从该文档中出现每个主题下词的Multinomial分布中抽取个主题然后再在这个主题对应的词的Multinomial分布中抽取个词作为文档d中词集Nd中的每个词n,即抽取术语词iv.不断重复步骤i、ii、iii三个步骤构成的随机生成过程,直到把D篇文档全部遍历。上述算法中,w是观测数据,θ和z是待估计的潜在变量,α和β分别是模型中的恒定超参数和在和θ上的Dirichlet先验,具体的变量信息如表3所示。表3LDA模型中的参数含义最终,运行LDA模型,以car为示例,可得到提取结果如表4所示。本实施例中根据提出的基于Web信息的本体概念属性学习方法,提取了该领域的概念属性词集。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1