信息检索方法及装置与流程
本发明涉及信息检索领域,具体而言,涉及一种信息检索方法及装置。
背景技术:
现有搜索技术,都是对单一数据库进行单一搜索,获取的搜索结果检索精度较低。其主要原因是,仅根据单一数据库的单一搜索结果,不仅不能克服单一语言表示存在的局限性,无法对搜索结果进行决策性分析,比如通过对搜索排序结果进行自动比对、自动校验,减少排序结果的随机性,提高排序结果的系统确定性。更不可能通过对基于多语言表示数据库的多搜索结果,进行信息聚合,以提高最终搜索结果的检索精度。此外,现有跨语言搜索的常见方法是,根据第一语言搜索请求翻译成第二语言搜索请求,利用第二语言搜索请求在第二语言数据库中搜索,得多个第二语言结果,再将上述多个第二语言结果翻译成多个第一语言结果。因此,在现有跨语言搜索技术中的关键特征是,第一语言数据库与第二语言数据库的内容是不重叠,从第二语言数据库搜索获得的结果,再翻译成第一语言结果,是对用户经常进行的采用第一语言搜索请求对第一语言数据库搜索的补充。更重要的是,由于第一语言数据库的内容与第二语言数据库的内容是互为独立,互不重叠的,利用第一语言搜索请求在第一语言数据库中获得的第一语言搜索结果与利用第二语言搜索请求在第二语言数据库中获得的第二语言搜索结果也是不相容、不重叠的。显然,上述跨语言搜索方案所获取的理想搜索结果的精度较低,影响用户的体验。针对相关技术中的上述问题,目前尚未提出有效的解决方案。
技术实现要素:
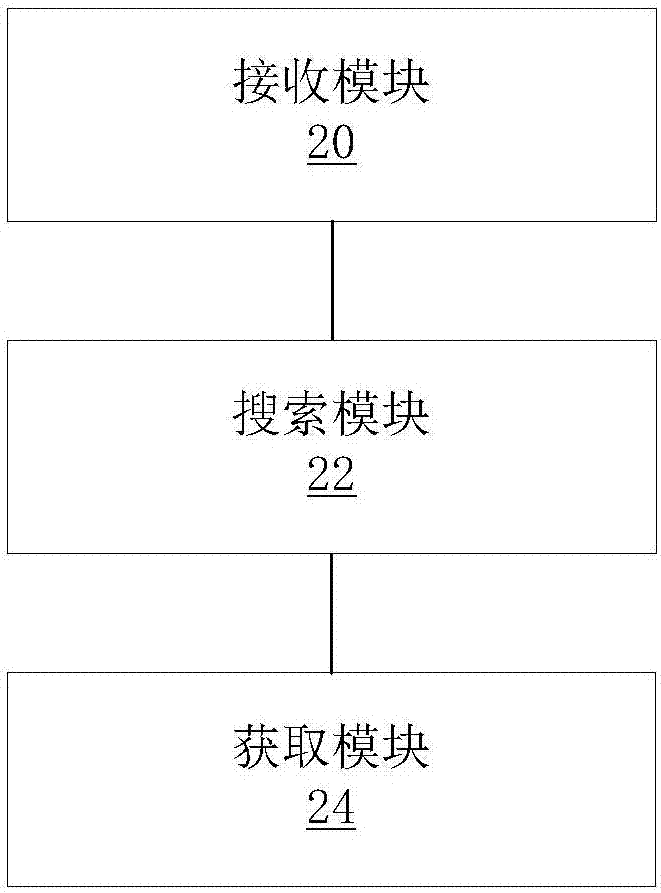
本发明的目的在于,提供一种信息检索方法及装置,以至少解决上述技术问题。根据本发明的一个方面,提供了一种信息检索方法,包括:接收搜索请求;根据所述搜索请求在第一语言数据库和第二语言数据库中进行搜索,分别得到第一搜索结果和第二搜索结果,其中,所述第一语言数据库中的内容和所述第二语言数据库中的内容互为翻译;根据所述第一搜索结果和第二搜索结果获取最终搜索结果。优选地,根据所述搜索请求在第一语言数据库和第二语言数据库中进行搜索,包括:在所述搜索请求的触发下,按照第一搜索条件在第一语言数据库进行搜索,以及按照第二搜索条件在第二语言数据库中进行搜索,其中,所述第一搜索条件与所述第二搜索条件相同,或者互为翻译。优选地,按照第一搜索条件在第一语言数据库进行搜索,以及按照第二搜索条件在第二语言数据库中进行搜索之后,还包括:对所述第一搜索结果中的条目按照与所述第一搜索条件的相关度进行排序和对所述第二搜索结果中的条目按照与所述第二搜索条件的相关度进行排序。优选地,根据所述第一搜索结果和第二搜索结果获取最终搜索结果,包括:对所述第一搜索结果和所述第二搜索结果按排序位置进行交叉插入并去除重复条目,获得所述最终搜索结果。优选地,上述方法还包括:对同时出现在所述第一搜索结果中和所述第二搜索结果中的条目进行标示处理。优选地,对以下排序位置的条目进行标示处理:所述第一搜索结果中排序位置的第一位,所述第二搜索结果中排序位置的第一位;或者,所述第一搜索结果中排序位置的前三位,所述第二搜索结果中排序位置的前三位。优选地,所述第二语言数据库为至少为两个,其中,每个所述第二语言数据库的语种不同。优选地,根据所述第一搜索结果和第二搜索结果获取最终搜索结果,包括:对所述第一搜索结果和所述至少两个以上的第二语言搜索结果按排序位置进行多数投票表决插入并去除重复条目,获得所述最终搜索结果。优选地,将以下至少之一以界面的形式进行独立或联合显示:所述第一搜索结果、所述第二搜索结果、所述最终搜索结果。根据本发明的另一个方面,提供了一种信息检索装置,包括:接收模块,用于接收搜索请求;搜索模块,用于根据所述搜索请求在第一语言数据库和第二语言数据库中进行搜索,分别得到第一搜索结果和第二搜索结果,其中,所述第一语言数据库中的内容和所述第二语言数据库中的内容互为翻译;获取模块,用于根据所述第一搜索结果和第二搜索结果得到最终搜索结果。优选地,所述搜索模块,用于在所述搜索请求的触发下,按照第一搜索条件在第一语言数据库进行搜索,以及按照第二搜索条件在第二语言数据库中进行搜索,其中,所述第一搜索条件与第二搜索条件相同,或者互为翻译。优选地,所述搜索模块用于在以下情况下,进行搜索:所述第二语言数据库至少为两个,其中,每个所述第二语言数据库的语种不同。通过本发明,采用根据搜索请求在第一语言数据库和第二语言数据库中进行搜索,并根据得到的搜索结果得到最终搜索结果,其中,所述第二语言数据库和所述第一语言数据库互为翻译的技术手段,解决了相关技术中,单一数据库搜索方案所获取的搜索结果的检索精度较低等技术问题,从而提高了获取理想搜索结果的检索精度,提升了用户体验。附图说明此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:图1为根据本发明实施例的信息检索方法的流程图;图2为根据本发明实施例的信息检索装置的结构框图;图3为根据本发明优选实施例2的进行语言翻译的装置结构示意图;图4为根据本发明优选实施例2的信息检索方法的流程图;图5为根据本发明优选实施例2的信息检索装置的结构框图;图6为根据本发明优选实施例2的聚合结果形成的流程图;图7为根据本发明优选实施例2的多数表决结果排序流程图。图8为根据本发明优选实施例2的搜索结果排序输出图片;图9为根据本发明优选实施例2的搜索结果排序输出图片;图10为根据本发明优选实施例2的搜索结果排序示意图。具体实施方式下文中将参考附图并结合实施例来详细说明本发明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。以下实施例的主要设计思想在于:不同语言对于同一世界的表示各有千秋,且往往是互补的。不同语言对同类事物的表示,提供不同的语言视角,有助于克服单一语言表示存在局限性。从计算语言角度看,通过对同类事物的不同语言表示,提供构建不同语言模型的可能,从而提高对该同类事物的表示、检索精度。例如,对于同一个关于汽车的专利发明,分别通过中文、英文表示,利用中文、英文语言模型的差异性与互补性,可以提供对同一关于汽车发明的相关、不同的视角表示。这些通过不同语言表示同类事物的模型,相关但不相同,互补而不冗余,提供了新的相关、互补信息源、决策源与检索源。并以此为基础,创造出全新信息检索、排序模式。以下详细说明。针对相关技术中,单一数据库搜索方案所获取的理想搜索结果的检索精度不高等技术问题,以下结合实施例提供了相应的解决方案,现详细说明。图1为根据本发明实施例的信息检索方法的流程图。如图1所示,该方法包括以下处理步骤:步骤S102,接收搜索请求。步骤S104,根据上述搜索请求在第一语言数据库和第二语言数据库中进行搜索,分别得到第一搜索结果和第二搜索结果,其中,第一语言数据库中的内容和第二语言数据库中的内容互为翻译,此时,第二语言数据库可以为通过对第一语言数据库按照第二语言数据库对应的第二语言进行翻译得到的数据库。该处理步骤中,上述搜索过程可以表现为以下形式:上述搜索请求携带或本身即为一个搜索条件,在第二语言数据库中进行搜索之前,可以将该搜索请求翻译为第二语言,然后再进行搜索。对等地,在第一语言数据库中进行搜索之前,可以将该搜索请求翻译为第一语言,然后再进行搜索。当然,上述搜索条件也可以是预先设置的。不管搜索条件是预先设置或在搜索请求中携带或者在进行搜索之前获取,其均可以通过以下处理过程进行搜索:在搜索请求的触发下,按照第一搜索条件在第一语言数据库进行搜索,以及按照第二搜索条件在第二语言数据库中进行搜索,其中,第一搜索条件与第二搜索条件相同,或者互为翻译。在两个搜索条件互为翻译时,可以在进行搜索之前,将搜索条件翻译成语言数据库对应的语种,例如,可以将第一搜索条件翻译为第二语言,从而得到上述第二搜索条件。对等地,可以将第二搜索条件翻译为第一语言,从而得到上述第一搜索条件。在进行搜索请求或搜索条件的翻译时,可以使用人工或计算机机器翻译技术,此为公知技术,此处不再赘述。当然,在进行语言数据库的翻译时,也可以采用人工或机器翻译技术。步骤S106,根据所述第一搜索结果和第二搜索结果获取最终搜索结果。该步骤的实现方式有多种,例如,将第一搜索结果和第二搜索结果进行叠加处理,得到最终搜索结果。此处叠加处理实现的方式有多种,例如可以随机叠加,可以将第一搜索结果排在第二排序结果前面,也可以进行交叉插入,对于最后一种实现方式,可以通过以下形式实现:对第一搜索结果和第二搜索结果按排序位置进行交叉插入并去除重复条目,获得最终搜索结果。在本实施例中,为了使用户更易查找到理想结果,可以对搜索结果进行按各种公知排名运算法则(ranking)的排序。例如,在按照第一搜索条件在第一语言数据库进行搜索,以及按照第二搜索条件在第二语言数据库中进行搜索之后,对第一搜索结果中的条目按照与第一搜索条件的相关度进行排序和对第二搜索结果中的条目按照与第二搜索条件的相关度进行排序,其中相关度计算是公知排名法则,可以是但不限于以下内容:搜索条件向量与搜索结果条目向量间的内积值;或,搜索条件中关键词出现在搜索结果条目文档中的频率等因子。为了减少搜索排序结果的不确定性,帮助用户确定是否进一步浏览该条目。可以对同时出现在第一搜索结果中和第二搜索结果中的条目进行标示处理。特别对同时出现在第一搜索结果中第一指定位置的条目和第二搜索结果中第二指定位置的条目进行标示处理。例如,第一指定位置为第一搜索结果中排序位置的第一位,第二指定位置为第二搜索结果中排序位置的第一位;或者,第一指定位置为第一搜索结果中排序位置的前三位(也可以是该前三位中的至少一个位置上的条目),第二指定位置为第二搜索结果中排序位置的前三位(也可以是该前三位中的至少一个位置上的条目)。在本实施例中,上述第二语言数据库可以为一个或多个(即至少为两个),其中,每个第二语言数据库的语种是不同。也就是说,为了提高检索精确度,可以建立多个不同语种的语言数据库,在多个不同语言数据库中进行搜索。在第二语言数据库至少为两个时,步骤S104可以通过以下处理过程实现:将第一搜索结果和所述至少两个以上的第二语言搜索结果按排序位置进行多数投票表决插入并去除重复条目,获得所述最终搜索结果,即当存在至少两个以上的语言搜索结果时,可以通过多数投票表决方法确定在最终搜索结果中的排序位置。在本实施例中,可以将以下至少之一以界面的形式进行独立或联合显示:第一搜索结果、第二搜索结果、最终搜索结果。此处联合显示的含义可以为在同一界面显示上述三个搜索结果中的其中至少两个搜索结果。在本实施例中提供了一种信息检索装置,用于实现上述实施例及优选实施方式,已经进行过说明的不再赘述,下面对该装置中涉及到的模块进行说明。如以下所使用的,术语“模块”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。图2为根据本发明实施例的信息检索装置的结构框图。如图2所示,该装置包括:接收模块20,连接至搜索模块22,用于接收搜索请求;搜索模块22,连接至获取模块24,用于根据上述搜索请求在第一语言数据库和第二语言数据库中进行搜索,分别得到第一搜索结果和第二搜索结果,其中,所述第一语言数据库中的内容和所述第二语言数据库中的内容互为翻译,此时第二语言数据库可以但不限于通过以下方式得到:通过对第一语言数据库按照第二语言数据库对应的第二语言进行翻译得到;获取模块24,用于根据第一搜索结果和第二搜索结果得到最终搜索结果,例如可以将第一搜索结果和第二搜索结果进行叠加处理,得到最终搜索结果。通过上述各个模块实现的功能,也可以解决单数据库搜索方案所获取的搜索结果的检索精度较低等技术问题。在本实施例中,上述搜索模块22,用于在上述搜索请求的触发下,按照第一搜索条件在第一语言数据库进行搜索,以及按照第二搜索条件在第二语言数据库中进行搜索,其中,第一搜索条件与第二搜索条件相同,或者互为翻译。在本实施例中,上述搜索模块22用于在以下情况下,进行搜索:第二语言数据库至少为一个或一个以上,其中,每个第二语言数据库的语种不同。为了更好地理解上述实施例,以下结合优选实施例详细说明。实施例1在本实施例中,首先,需要将第一语言数据库翻译为第二语言数据库;第一语言搜索请求(可以理解为第一搜索条件)自动翻译为第二语言搜索请求(可以理解为第二搜索条件);第一语言搜索请求在第一语言数据库下,应用现有语义相关技术进行检索并排序:第一语言搜索请求在第一语言数据库下进行检索,并按相关度排序,其中相关度计算可以是但不限于是第一搜索条件向量与第一搜索结果条目向量间的内积值,或搜索条件中关键词出现在搜索结果条目文档中的频率等因子;第二语言搜索请求在第二语言数据库下,应用现有语义相关技术进行检索并排序:第二语言搜索请求在第二语言数据库下进行检索,并按相关度排序,其中相关度计算可以是但不限于是第二搜索条件向量与第二搜索结果条目向量间的内积值,或搜索条件中关键词出现在搜索结果条目文档中的频率等因子。由于第一语言数据库与第二语言数据库的内容是重叠、对称的,利用第一语言搜索请求在第一语言数据库中获得的第一语言搜索结果与利用第二语言搜索请求在第二语言数据库中获得的第二语言搜索结果也是相容、部分重叠;将得到的两个排序结果,根据重叠聚合规则,形成新排序结果。其重叠聚合原则为,对两个排序结果:第一语言第一排序文档号为聚合结果(最终结果)的第一排序结果,第二语言第一排序文档号结果与聚合结果第一排序文档号结果相同时,标记该聚合结果的第一排序文档号结果和/或对应第一、第二语言的第一排序文档号;否则,第二语言第一排序文档号插入聚合结果的第二排序结果;第一语言第二排序文档号与已经插入聚合结果的文档号比较,如重复,则标记该聚合结果的对应排序文档号结果和/或对应第一、第二排序文档号;否则,第一语言第二排序文档号插入聚合结果的下一排序结果;第二语言第二排序文档号与已经插入聚合结果的文档号比较,如重复,则标记该聚合结果的对应排序文档号结果和/或对应第一、第二排序文档号;否则,第二语言第二排序文档号插入聚合结果的下一排序结果;对第一、第二语言排序结果进行重复循环处理;当第一语言排序结果即第一语言排序文档数到达第一指定阈值时,针对第一语言数据库的排序结束,否则继续排序;当第二语言排序结果即第二语言排序文档数到达第二指定阈值时,针对第二语言数据库的排序结束,否则继续排序;当插入聚合结果排序文档数到达聚合结果指定阀值时,聚合排序结束。第一、第二、聚合结果指定阈值可以是相同或不同。实施例2图3为根据本发明优选实施例2的进行语言翻译的装置结构示意图。如图3所示,该装置,包括:第一语言文档数据库30;从第一语言到第二语言的翻译部件32,用于将第一语言文档数据库翻成第二语言文档数据库;从第一语言到第n语言的翻译部件34,将第一语言文档数据库翻成第n语言文档数据库,n为不小于2的自然数;已翻译成第二语言的第一语言文档数据库的第二语言文档数据库36;已翻译成第n语言的第一语言文档数据库的第n语言文档数据库38。在对本领域技术人员理解本发明实施例没有实质性差别条件下,为了简化说明,在本实施例中,多语言数据库的数量n取值为2,以下会详细说明。图4为根据本发明优选实施例2的信息检索方法的流程图。如图4所示,该方法包括以下处理步骤:步骤S402,获取搜索请求;步骤S404,在第一语言数据库下搜索结果并排序;步骤S406,将第一语言搜索请求翻译成第二语言搜索请求,在第二语言数据库下搜索结果并排序;步骤S408,将第一语言数据库下的搜索排序结果与在第二语言数据库下的搜索排序结果聚焦融合,形成新的排序结果。图5为根据本发明优选实施例2的信息检索装置的结构框图。如图5所示,该装置包括:搜索请求获取单元50,用于获取搜索项(或称为搜索请求);第一搜索排序单元52,用于将第一语言搜索请求在第一语言数据库下搜索结果并排序;第二搜索排序单元54,用于将第一语言搜索请求翻译成第二语言搜索请求,在第二语言数据库下搜索结果并排序;重排序单元56,用于将第一语言数据库下的搜索排序结果与在第二语言数据库下的搜索排序结果聚焦融合,形成新的排序结果。以下详细说明,上述新的排序结果的形成过程,如图6所示,该过程包括:步骤S600,开始,i=0,i为当前第一语言、第二语言排序文档号序号变量,m=0,m为当前聚合结果(相当于实施例中的最终搜索结果)的待插入序号变量;步骤601,将第一语言第一排序文档号设为聚合结果的第一排序结果;步骤602,将m设为1;步骤S603判定第二语言第i(此处i=0)排序文档号结果是否已在聚合结果中,如果是,转步骤S604,否则转步骤S605;步骤S604,根据在聚合结果中匹配序号值对聚合结果进行标记,比如,如果匹配是在聚合结果的第一位置(m=0),则该聚合结果项(第一项)标红色,如果匹配项m是1或2,则该聚合结果项标绿色,同时,还可以对相对应的第一语言、第二语言排序结果项进行标记,继续步骤S606;步骤S605,将第二语言第i(此处i=0)排序文档号插入聚合结果的m(此处为1),并m加1为2;步骤S606,对i加1;步骤S607,判断i是否已经到达预定第一语言、第二语言排序表的项数N,或m是否已经到达预置聚合排序结果表项数M,如果是转步骤S608,结束处理,如果不是,继续步骤S609;步骤S608,结束处理;步骤S609,判定第一语言第i(此处i=1)排序文档号结果是否已在聚合结果中,如果是,转步骤S610,并如S604对聚合结果等进行相应标记;否则转步骤S611;步骤S611,将第一语言第i排序文档号插入聚合结果的第m位,并m加1;步骤S612,判断m是否已经到达预置聚合排序结果表项数M,如果是转S608结束处理,如果不是,继续步骤S603。必须说明,第一、第二排序结果的项数N可以是相同或不同。而且交叉插入先取第一语言搜索结果可以改变,例如,先取第二语言搜索结果也可以。更进一步,对于同在第i位置的第一语言文档、第二语言文档的文档号,可以根据第一语言文档与第一语言搜索请求的相关度、第二语言文档与第二语言搜索请求的相关度大小进行排序,取相关度大的对应语言文档先插入聚合排序结果表中。图7为根据本发明优选实施例2,并取多语言数据库的数量n为大于2的搜索结果排序流程图。如图7所示,从左至右依次为:第一语言搜索结果第i排序文档号、第二语言搜索结果第i排序文档号、第n语言搜索结果第i排序文档号。其中,第一语言搜索结果为在第一语言数据库下搜索得到的排序结果;第二语言搜索结果为在第二语言数据库下搜索得到的排序结果;第n语言搜索结果为第n语言数据库下搜索得到的排序结果,其中n为大于2的正整数。与仅有2个语言数据库进行搜索排序的结果聚合,无法实现多数表决算法来形成的新的排序结果对比,本实施例提供新的排序、决策算法与改进。以下提供基于多数表决算法进行聚合排序的步骤。步骤S700、S710、S720分别表示在第j位置获得第一、第二、第n语言搜索结果的文档号,为R[i][j],其中i为1到n的正整数;步骤S730,对输入n个R[i][j]文档号,相对已聚合结果进行去除重复处理,剩下k个结果,其中k<=n;步骤S740,对剩下k个结果按相同文档号分组聚类,同时可以计算组内平均相关度或最大相关度;步骤S750,根据每组包含个数多少进行多数表决排序,包含个数多排序在前,如包含个数相同,则可按预定交叉排序或其它预定规则,如根据分组内平均相关度值从大到小排序或分组内最大相关度值从大到小排序;步骤S760,按排序顺序插入最终聚合结果表。图8和图9为根据本发明优选实施例2的搜索结果输出图片。本实施例的第一语言数据库为中国专利申请全文库,第二语言数据库为中国专利申请英文库。搜索请求为pab/CN101102838,其中pab是对该专利申请进行新颖性语义相关搜索,CN101102838是中国专利申请公开号。显然,该搜索请求对第一语言数据库、第二语言数据库都相同。图中列出了第一、第二语言搜索排序输出结果。图10为对图8和图9输出排序结果进行聚合排序的示意图。如图10所示,从左至右依次为:第一语言排序结果、第二语言排序结果、聚合的最终排序结果。其中,第一语言排序结果为在第一语言数据库下搜索得到的相关度排序结果;第二语言排序结果为在第二语言数据库下搜索得到的相关度排序结果;最终排序结果为第一语言数据库下的搜索排序结果与在第二语言数据库下的搜索排序结果聚焦融合,形成的新的排序结果。图中,第一语言排序结果第1排序文档号CN1225603同时出现在第二语言排序结果第1排序位置,为此对该结果标红色(用点线框示意);第一语言第2排序结果CN18819916没有出现在第二语言第2、或第3排序结果,为此,插入最终排序结果的第2位置,不标颜色;第二语言第2排序结果CN1607979出现在第一语言第3排序位置,为此,标绿色(用虚线框示意);。为了验证本发明。申请人对专利局审查员的检索报告(ISR)进行了自动测试(仅采用专利的公开号为搜索条件、无其它任何检索策略)。在测试中,以审查员给出的X文献为正确,如果排序结果中出现该X文献号,则定为命中,其它均为不命中。第一语言数据库(中国专利申请中文库)下搜索并得到排序结果的命中率为:第一排序位置命中率为8.99%;在前20排序位置命中率为27.40%;在前100排序位置命中率为43.73%;在前400排序位置命中率为59.44%。第二语言数据库(中国专利申请英文库)下搜索并得到排序结果的命中率为:第一排序位置命中率为9.1%;在前20排序位置命中率为27.76%;在前100排序位置命中率为44.78%;在前400排序位置命中率为61.15%。将第一语言数据库下的搜索排序结果与在第二语言数据库下的搜索排序结果聚焦融合,形成新的排序结果的命中率为:第一排序位置命中率为9.1%;在前20排序位置命中率为29.79%;在前100排序位置命中率为47.15%;在前400排序位置命中率为63.43%,各项命中率除了第一位命中率与第二语言数据库第一排序位置命中率相同(因为在本实施例中,第二语言数据库的排序结果在交叉排序中取为第1),都有10%左右提高。更为重要的是,在对第一语言、第二语言搜索结果发生聚焦的那些输出,即第一语言、第二语言排序结果的第1位相同,其命中率提高到20.47%,前3位聚焦结果的命中率为34.33%,前20位聚焦结果的命中率为67.97%。就是说,如果用户看到第一位输出结果被系统标上红色(被系统聚焦),该篇文献就是审查员认定的X文献的比例从9.1%提升到20.47%。如果用户看到前3位中至少有1篇被标上绿色(也可以用其它颜色表示),则3篇被标注绿色的文献中至少有1篇就是审查员认定的X文献的比例是34.33%,而要达到如此高的命中率,如果仅对第一、第二语言数据库进行单独搜索,用户需要阅读20多篇(单一数据库前20位命中率28%<34.33%)才能达到。在测试例中,第1位结果被聚焦的概率为26%。显然,根据本发明构建的新的语言数据库,不仅提供了新的检索数据源,而且提供了新的检索决策源。在另外一个实施例中,还提供了一种软件,该软件用于执行上述实施例及优选实施方式中描述的技术方案。在另外一个实施例中,还提供了一种存储介质,该存储介质中存储有上述软件,该存储介质包括但不限于:光盘、软盘、硬盘、可擦写存储器等。显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,并且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。以上仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1