基于多令牌环的加速器与处理器的耦合结构的制作方法
本发明属于多核处理器技术领域,具体涉及处理器与面向特定应用的加速器之间的互联结构。
背景技术:
传统的多核处理器在处理器间通信上没有对局部通信与全局通信作更多的区分,其典型代表就是基于虫洞调度的包交换(Packetswitch)片上网络,这种处理器核间通信机制每经过一个包交换路由器数据都会有一个延迟(latency)。另一种核间通信机制就是电路交换(Circuitswitch)片上网络,这种核间通信机制在建立路径上花费的时间开销随着路径长度的增加而增加,同样造成数据传输的latency较大。传统的多核处理器在加速器与处理器的耦合上不够紧密,加速器排列成阵列的形式通过片上网络与处理器耦合,当处理器访问其中某个加速器时同样需要在建立从处理器到加速器的路径上花费一定时间,而且加速器与加速器之间通信也不方便。因此,传统的耦合方式注重加速器的共享性而忽略了加速器与处理器通信的紧密性。在上述的处理器核间通信互联和加速器与处理器耦合方式这两个方面,传统的多核处理器没有注重局部通信,而在实际应用中往往存在全局通信弱而局部通信强的特点。因此需要设计一种强化局部通信(包括处理器与处理器、处理器与加速器通信)的核间互联与耦合结构。
技术实现要素:
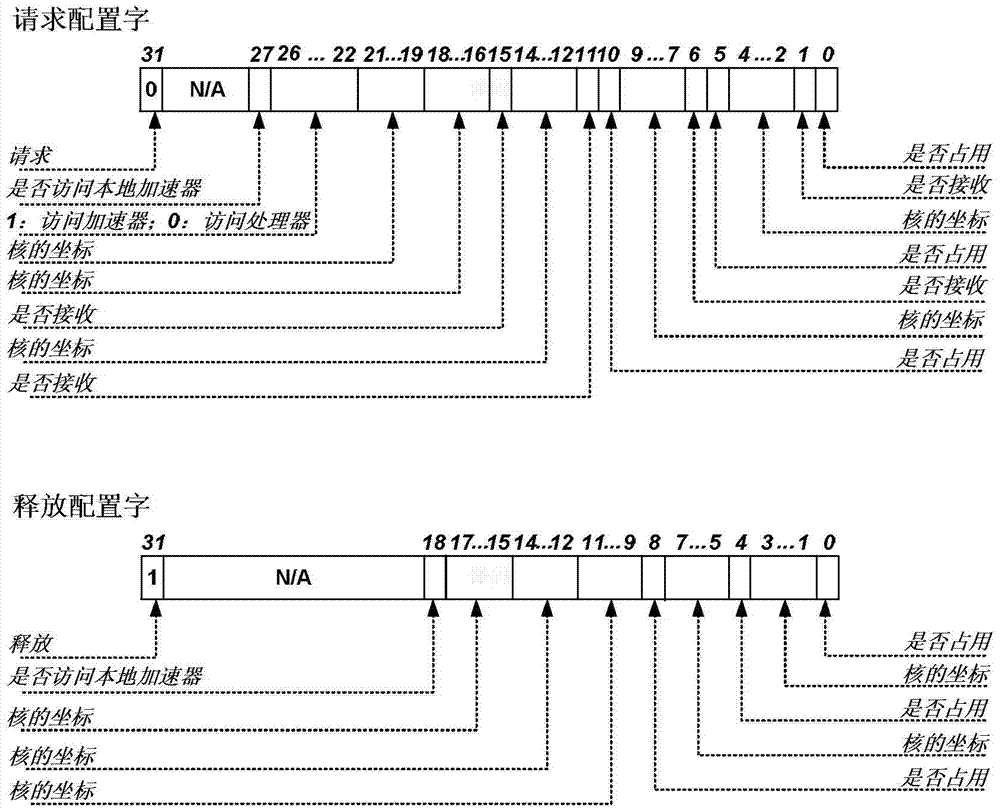
本发明的目的在于提供一种能够缩短数据传输延迟,强化局部通信的加速器与处理器耦合结构。本发明提供的加速器与处理器耦合结构,是通过多令牌环将局部的八个处理器和加速器节点连接在一起,路径的建立或释放时间都是固定的一个时钟周期,而与路径的长度无关,减小了数据传输的latency。而且,这种结构支持处理器与处理器、处理器与加速器、加速器与加速器的通信。通过复用多令牌环大大缩短了数据传输延迟,强化了局部通信。本发明提出的基于多令牌环的加速器与处理器耦合结构,具体包括:多令牌内环(沿顺时针方向传递数据,包括环节点和控制器)、多令牌外环(沿逆时针方向传递数据,包括环节点和控制器)、处理器、加速器以及它们之间的接口模块(Local_acce_wrap、Ring_wrap和Pipeline_interface)。其中,所述内环、外环结构相同,都包含八个环节点和一个控制器;所述处理器是基于MIPS指令集的六级流水线处理器;所述加速器是面向特定应用的运算单元,比如通信领域中常用的fft(快速傅里叶变换)运算单元等;所述接口模块有三个,其中,Local_acce_wrap模块是加速器的接口模块,用于在本地处理器与环上其它的处理器或加速器之间切换对加速器的访问权,选择加速器的结果是送往本地处理器还是送往环上其它的处理器或加速器;Ring_wrap模块是环的接口模块,用于在加速器与处理器之间切换对令牌环的占用权;Pipeline_interface模块是处理器的接口模块,用于在本地加速器或环上的其它处理器或加速器之间切换送往处理器的数据源,解析处理器发出的建立路径或释放路径等信息,发往环的控制器。本发明中,令牌环分为内环和外环,内环和外环相互独立,数据传输路径短,数据单周期到达。本发明耦合结构支持对加速器的访问权可在本地处理器与环上其它的处理器或加速器之间切换,支持加速器的结果送往本地处理器或环上其它的处理器或加速器,增强了加速器的共享性。本发明耦合结构支持对于令牌环的占用者在加速器与处理器之间切换,增强了环的可复用性。本发明耦合结构支持对于送往处理器的数据源在本地加速器或环上的其它处理器或加速器之间切换。综上,与传统的加速器与处理器耦合方式相比,本发明提供的基于多令牌环的加速器与处理器耦合结构,不但减小了由于建立路径时间过长和路径节点延迟所造成的数据传输延迟,而且能支持处理器与处理器、处理器与加速器、加速器与加速器的数据传输,强化了处理器通信的局部性,提高了环的可复用性和加速器的共享性。附图说明图1是多令牌环的结构图。图2是建立路径所用的请求配置字与释放路径所用的释放配置字的格式示意图。图3是加速器的接口模块(Local_acce_wrap)的结构图。图4是环的接口模块(Ring_wrap)的结构图。图5是处理器的接口模块(Pipeline_interface)的结构框图。图6是包括加速器、处理器和图3、图4、图5三个接口模块的结构总图。图7是处理器与加速器通信的示意图。具体实施方式下面结合附图和实例,进一步描述本发明。图1展示了一个多令牌环的内部结构图,主要包括八个环节点(图中用n表示)和一个环控制器。控制器的功能是将处理器发出的请求配置字或释放配置字(请求配置字即处理器为建立环的路径而向环控制器发出的配置信息,释放配置字即处理器为释放环的路径而向环控制器发出的配置信息,在图2中详细解释其格式及意义)通过判断逻辑解析出来,判断出相关的环节点是否是接收节点,是否是发送节点。比如解析出来的某节点的r_token(接收令牌)为1,表明该节点是接收节点,又如某节点的t_token(发送令牌)为1,表明该节点是发送节点。环节点的功能就是将处理器发出的配置信息传递给环控制器,并根据控制器解析出来的接收令牌、发送令牌等信息来选择数据。比如若t_token(发送令牌)为1,则选择来自本节点处的处理器的数据(local_data)传输到下一个节点(next_node_data),否则将选择来自上一个节点的数据(prev_node_data)传输到下一个节点(next_node_data)。若r_token(接收令牌)为1,表明本节点是接收节点,则将来自上一个节点的数据(prev_node_data)传输到本地的处理器(local_data)。图2展示了请求配置字和释放配置字的具体格式及意义。请求配置字是为了建立路径。值得说明的是,一个环中路径最长可以包括五个节点,比如图1中从节点0到节点7(按顺时针方向传),即依次为节点0、节点1、节点2、节点3、节点7。那么假如节点0要向节点6传输数据,则可以选择外环(按逆时针方向传),建立一条经过节点0、节点4、节点5、节点6的路径即可,这样就避免了路径过长(超过5个节点)的问题。因此无论是请求配置字还是释放配置字都要携带5个节点的信息,即从发出信息的那个节点到接下来的4个节点(按照环的方向)。以请求配置字为例,比特21到19为发出该信息的节点处处理器的坐标,比特18到16即为下一个节点处处理器的坐标,比特15表示该节点是否为接收节点,如此依次往下,就不一一描述了。图3展示了加速器的接口模块(Local_acce_wrap)。该模块选择从环或者本地处理器来的数据送给加速器,并将加速器的运算结果送往环或者本地处理器,选择控制信号由环控制器通过解析配置字给出。图4展示了环的接口模块(Ring_wrap)。该模块选择来自加速器或者处理器的数据送往环上其它节点,并选择从环来的数据是送往处理器还是加速器,同样地,选择控制信号来自环控制器。图5展示了处理器的接口模块(Pipeline_interface)。该模块根据来自处理器流水线的写使能、写地址、写数据等信息通过译码、判断逻辑解析出送往加速器的数据和使能信号,同样地解析出送往环的请求、释放、数据有效、数据等信号,并将来自加速器和环的数据等信号传送给处理器。图6展示了包含加速器、处理器及图3、图4、图5三个接口模块的结构总图,即挂载在环上的一个节点的具体结构。可以按照下面的思路来理解该图。发送给处理器的数据来源有三个:外环、内环或本地加速器;发送给加速器的数据来源有三个:外环、内环或本地处理器;发送给外环的数据来源有两个:本地处理器或本地加速器;发送给内环的数据来源有两个:本地处理器或本地加速器。图7展示了处理器与加速器通信的示意图。该图表示节点1的处理器调用节点2的加速器的过程。一共包括4个步骤:第一步,节点1的处理器发出数据到内环;第二步,节点2的加速器从内环接收数据;第三步,节点2的加速器将算出的结果发送到外环;第四步,节点1的处理器从外环接收数据。图中黑色部分即表示数据的传输通路。本发明这种结构支持处理器与处理器之间、处理器与加速器之间以及加速器与加速器之间的数据传输,具有很强的灵活性。一个节点上的加速器可以被挂载在令牌环上的任何一个处理器访问,具有很强的共享性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1