一种基于降维策略的油藏模拟快速拟合方法与流程
本发明涉及一种油藏数值模拟方法,尤其涉及一种基于降维策略的油藏模拟快速拟合方法。
背景技术:
油藏模拟历史拟合是油气田开发研究中的一项极其重要的工作,它主要是利用数值模拟技术通过拟合油水井实际生产动态数据来反演和修正油藏参数,使数值化的油藏模型符合实际油藏的开发状态,为后期油田开发方案的设计和制定提供基础。
目前工程人员普遍采用手工试算的方法进行历史拟合。在历史拟合过程中,由于地质参数如井间的孔隙度、渗透率、断层、裂缝等主要是通过井点测量值间接得到,这给地质模型带来了许多不确定性因素,因此,其可调模型参数的自由度就很大。采用手工试算方法进行拟合需要大量的拟合经验并取决于个人的判断,拟合过程带有较大的随机性和盲目性,拟合结果不唯一,很难确定地层实际情况,且拟合过程艰苦繁琐,耗费大量的人力与机时,难以取得最好的拟合结果。
油藏模拟自动历史拟合克服手工试算的不足,它是利用最优化方法自动修正和反演模型参数,力求尽量减小拟合时间并获得更高的拟合精度,因此自动历史拟合技术已成为当前油田开发研究中的关键和热点问题。自动历史拟合属于大规模系统反问题,最优化方法的选择是解决该问题的关键,现有的最优化方法主要包括梯度类算法和无梯度类优化算法。梯度类算法,如最速下降法、高斯牛顿法、BFGS、LBFGS等,是最为传统的求解方法,计算效率通常大大高于无梯度类算法,但是该方法中梯度的求取主要采用伴随方法进行计算,需要编写伴随矩阵嵌入到油藏模拟器中,计算过程极其复杂,不适于实际油藏问题的求解。
无梯度优化算法不需要梯度求解,仅涉及目标函数计算,实现过程简单,因此,易于和当前通用油藏模拟器相结合进行实际油藏历史拟合的求解。近年来,关于该类方法的研究受到更多的关注,如遗传算法、微粒群算法、随机扰动近似算法SPSA等,但该类方法收敛速度较慢,在求解大规模优化问题是往往需要成千上万次的计算才能收敛,由于油藏数值模拟运算本身耗时较大,所以,应用该类方法进行油藏模拟历史拟合的计算代价是难以承受的。
综上所示,如何快速、高效的进行历史拟合仍是油藏数值模拟技术中的难题,也是实现油田高效开发的关键手段。
技术实现要素:
本发明为了有效提高自动历史拟合效率,便于进行实际油藏历史拟合应用,提供了一种基于降维策略的油藏模拟快速拟合方法;
本发明的技术方案如下:
一种基于降维策略的油藏模拟快速拟合方法,其具体步骤为:
步骤1,输入数据;
输入先验油藏模型mpr、模型协方差阵CM、真实观测动态数据dobs(用户收集到的油田实际生产数据,如各井及区块整体的日产油、含水率、压力等)、观测数据协方差阵CD(该协方差阵是表示与生产动态数据的关系,对观测数据又叫生产动态数据,是油田实际生产数据);
步骤2,建立待优化的目标函数O(m);
历史拟合属于多解性问题,实际研究中一般只考虑所得油藏模型的数模结果是否与实际动态相符,而忽略了其与先验地质认识的偏差程度,由于实际动态数据本身存在误差和不确定性,这就易导致所得模型与真实油藏地质沉积规律相差较大,不能实际应用。
利用先验油藏模型mpr和模型协方差阵CM结合历史拟合方法,建立待优化目标函数O(m),如公式(1)所示:
其中,m为真实油藏的模型参数,其是由网格参数组成的Nm维向量,g为数值模拟计算得到的生产动态数据向量;;
目标函数O(m)由两项构成:第一项为计算模型与初始先验模型的偏差;第二项为模型的数值模拟结果与实际动态间的偏差;两项的不确定性程度均反映在各自的协方差阵CM和CD中。优化该函数就是使这两部分值达到最小,此时所得模型是在尽量吻合先验认识的条件下去拟合实际生产数据,这样就有效的降低了解的不确定性,保证了历史拟合后模型能够与实际地质沉积的特征相吻合。
步骤3,对待优化的目标函数O(m)进行降维处理,获取历史拟合目标函数O(p);
步骤4,利用所述历史拟合目标函数O(p)获取真实油藏的模型参数m。
所述步骤3包括:
步骤3-1,对所述模型参数的协方差阵CM进行平方根法分解,如公式(2)
所示:
CM=LLT (2);
其中,L与LT互为转置矩阵;L是下三角阵;
步骤3-2,对矩阵L进行第一次分解,如公式(3)所示:
LLT=UΛVTVΛTUT (3);
其中,U为Nm维方阵,V为Nm维方阵,Λ为对角阵,Λ中的元素为矩阵L的奇异值,U和V中列向量均为矩阵L*L的特征向量,且UUT和VTV均为单位阵;
步骤3-3,对矩阵L进行第二次分解:
设Λ中的非零奇异值的个数为Np,Np<<Nm,对公式(3)进一步分解,如公式(4)所示:
其中,Up为U的子矩阵,为Λ的转置子矩阵,且Λp的对角元素为Np个非零的奇异值;Up和Vp分别为与Λp相对应的奇异向量,为U的转置子矩阵,且UpUpT和VpTVp均为单位阵;
步骤3-4,将公式4代入公式(2),得到公式(5);
步骤3-5,求取所述模型参数的协方差阵CM的逆矩阵如公式(6)所示;
步骤3-6,将公式(6)代入公式(1)中的得到并设置变换变量p,将所述待优化目标函数O(m)转换为历史拟合目标函数O(p),变换变量p以及历史拟合目标函数O(p)的表达式如公式(7)、公式(8)所示:
其中,m(p)为变量p对应的真实油藏模型;
降维幅度根据不同的问题而不同,可降低几倍到几百倍;
历史拟合目标函数O(p)不存在求拟操作,更加易于计算,且自变量p的维数会大大小于实际模型m的维数,其与奇异值分解中较为显著的奇异值个数相同。
初始模型取为先验模型,即m=mpr,因此初始变换变量P为0向量;g(m(p))是预测的观测数据,即油藏模拟计算得到的动态数据。
所述步骤4包括:
步骤4-1,将初始变量计算对应的预测观测数与步骤1获取的真实观测数据代入公式(8),得到初始目标函数值O(p);
步骤4-2,采用无梯度优化算法对历史拟合函数O(p)进行迭代优化,并判断所述历史拟合函数O(p)是否收敛;
若收敛,则执行步骤4-5;
若不收敛,则顺序执行步骤4-3;
步骤4-3,判断所述历史拟合函数值是否下降;
若所述历史拟合函数值下降,则顺序执行所述步骤4-4;
若所述历史拟合函数值未下降,则重复执行所述步骤4-3;
(函数值下降是指当前迭代步对应的函数值比上一个迭代步值小,基初始值就是初始变换变量对应的目标函数值)
步骤4-4,更新优化变量:用当前迭代步对应的变量替换上一次迭代的最优变量,作为最优变量;
步骤4-5,通过逆变换方法获取真实油藏的模型参数m:由公式(7)利用P反求m,即m=mpr+UpΛpp;
在所述步骤3-1中,对所述模型参数的协方差阵CM进行Cholesky(平方根法)分解;
在所述步骤3-2中,对矩阵L进行奇异值分解。
在步骤4-2中,无梯度优化算法采用随机扰动算法(无梯度算法很多种,随机扰动算法(SPSA)就是其中一种无梯度算法,该算法优点是随机扰动梯度总是与梯度方向一致)对历史拟合函数O(p)进行迭代优化;该方法计算简单、每步仅需两次目标函数计算即可获得扰动梯度,该扰动梯度即为搜索方向,且该搜索方向能对于最大化问题来说恒为上坡方向。其计算公式如公式(9)所示:
其中,是随机扰动梯度;是在第l个迭代步所获得的最优参数变量;εl为扰动步长;Δl为Np维随机扰动向量,其中所包含元素Δl,i(i=1,2,…,Nu)为服从参数为±1的对称Bernoulli分布。在获得随机扰动梯度后,即可采用迭代法进行优化求解,在第l+1迭代步所获得的控制变量如公式(10)所示:
其中,αl为搜索步长。
本方法首先利用先验地质信息和统计学方法提出了一种大规模参数降维技术,可对自动历史拟合反演参数进行等效降维处理;将其与无梯度优化方法相结合,可以方便的和任意油藏模拟器相结合,进行油藏历史拟合问题求解。
本发明最终形成了配套的自动历史拟合软件,应用该软件进行了一些实例测试应用,结果显示该发明可大大减小人工历史拟合的工作量,有效提高拟合效率。
与现有技术相比,本发明提出的油藏模拟自动拟合方法可以和任何油藏模拟器匹配进行油藏自动历史拟合参数的反演和求解;且本方法有效的提高了历史拟合精度和效率,还可用于实际大规模油藏自动历史拟合问题的求解,具有极高的应用价值。
附图说明
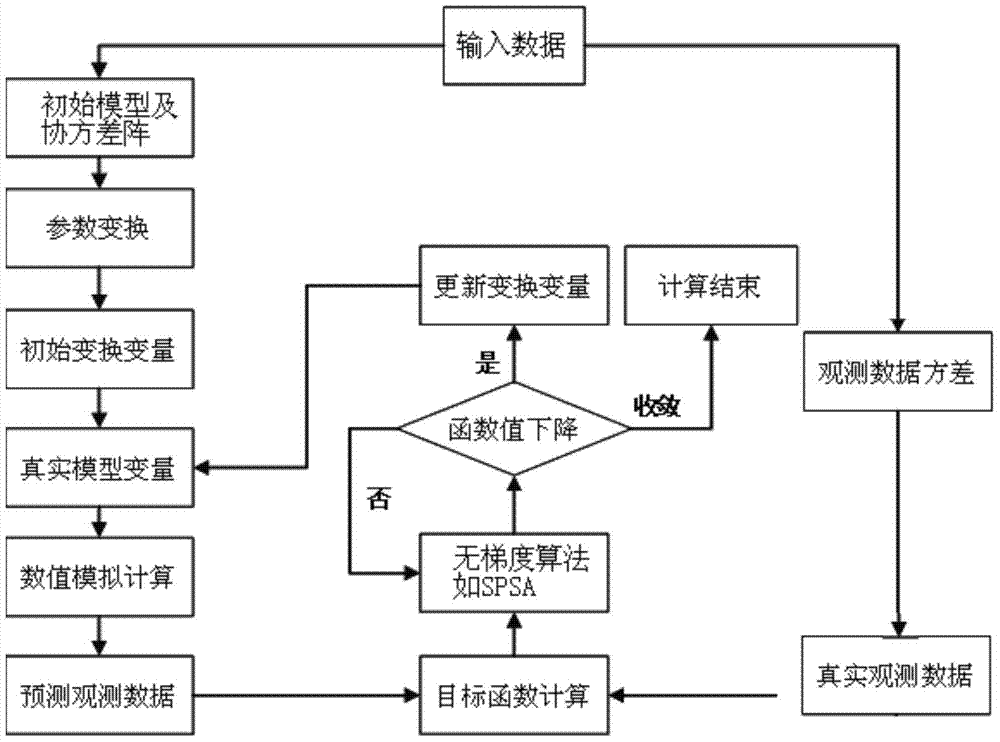
图1为本发明一种基于降维策略的油藏模拟快速拟合方法的流程图;
图2a为油井P1井底流压拟合结果
图2b为油井P10井底流压拟合结果
图2c为油井P15井底流压拟合结果
图2d为水井I1井底流压拟合结果
图3a为拟合前各层平面渗透率分布图;
图3b为拟合后各层平面渗透率分布图;
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细地说明,本发明的保护范围不局限于下述的具体实施方式。
如图1所示,一种基于降维策略的油藏模拟快速拟合方法;所述方法首先进行数据输入,包括初始先验油藏模型、模型协方差阵、真实观测动态数据及观测数据协方差阵等;其次,进行参数降维过程,进行参数变换,并得到降维后的初始变换变量,由初始变换变量进行逆变换得到真实的油藏模型变量,将其代入到油藏模拟中进行计算,得到预测的生产动态观测数据,将预测的观测数据和真实的观测数据代入到降维后的目标函数表达式中进行计算;最后利用无梯度优化算法对目标函数进行优化,如果目标函数值下降则更新优化变量,否则进行优化迭代直至使目标函数值下降,然后通过逆变换得到真实油藏模型变量,进行数值模拟运算并计算新的目标函数值,直至整个计算过程收敛为止。
所述方法的具体步骤为:
步骤1,输入数据;
输入先验油藏模型、模型协方差阵、真实观测动态数据、观测数据协方差阵;
步骤2,建立待优化的目标函数O(m);
利用先验地质信息结合历史拟合方法,建立待优化目标函数O(m),如公式1所示;
其中,m为真实油藏的模型参数,所述油藏模型是由网格参数组成的Nm维向量,mpr是先验油藏模型估计,CM为模型参数的协方差阵,dobs实际生产动态数据向量;g为数值模拟计算得到的生产动态数据向量;CD为生产动态协方差阵;
步骤3,对待优化的目标函数进行降维处理,获取历史拟合目标函数O(p);
步骤3-1,对所述模型参数的协方差阵CM进行Cholesky分解,如公式(2)所示:
CM=LLT (2);
其中,L与LT互为转置矩阵,L为方阵;
步骤3-2,对方阵L进行分解,如公式(3)所示:
LLT=UΛVTVΛTUT (3);
其中,U为Nm维方阵,V为Nm维方阵,Λ为对角阵,Λ中的元素为矩阵L的奇异值,U和V中列向量均为矩阵L*L的特征向量,且UUT和VTV均为单位阵;
步骤3-3,对方阵L进行奇异值分解,如公式(4)所示;
设Λ中的非零奇异值的个数为Np,Np<<Nm,对公式(3)进一步分解,如公式(4)所示:
其中,Up为U的子矩阵,为Λ的转置子矩阵,且Λp的对角元素为Np个非零的奇异值;Up和Vp分别为与Λp相对应的奇异向量,为U的转置子矩阵,且UpUpT和VpTVp均为单位阵;
步骤3-4,将公式(4)代入公式(2),得到公式(5);
步骤3-5,求取所述模型参数的协方差阵CM的逆矩阵如公式(6)所示;
步骤3-6,将公式(6)代入公式(1)中的得到并设置变量p,将所述待优化目标函数O(m)转换为历史拟合目标函数O(p),变量p以及历史拟合目标函数O(p)的表达式如公式(7)、公式(8)所示:
其中,mp为Np维的油藏模型;
步骤4,获取真实油藏的模型参数m;
步骤4-1,将初始变量计算对应的预测观测数与步骤1获取的真实观测数据代入公式(8),得到初始目标函数值O(p);
步骤4-2,采用SPSA算法对历史拟合函数O(p)进行迭代优化,并判断所述历史拟合函数O(p)是否收敛;
若收敛,则执行步骤4-5;
若不收敛,则顺序执行步骤4-3;
步骤4-3,判断所述历史拟合函数值是否下降;
若所述历史拟合函数值下降,则顺序执行所述步骤4-4;
若所述历史拟合函数值未下降,则重复执行所述步骤4-3;
步骤4-4,更新优化变量;
步骤4-5,通过逆变换方法获取真实油藏的模型参数m。
实施例
Brugge油藏模型含有9个小层,平面网格系统划分为139×48,总有效网格数为44,550,历史拟合中需要反演的参数包括每个网格的净毛比、渗透率、孔隙度及初始含油饱和度,共计267,000个。图2a-图2d中的dobs为观测数据,Prior Mean为未拟合模型计算井底流压曲线,MAP未拟合的井底流压曲线,因此说明了该方法拟合效率很高,全拟合上了。图2a-图2d为不同井井底流压拟合曲线。
在历史拟合中选用ECLIPSE商业模拟器进行油藏模拟计算,利用本发明提出的方法,经过211次计算,最终所得部分油井的动态数据拟合结果,如图3a、图3b所示;拟合前后油藏各层的渗透率分布图。
从图中可以看出,经过自动历史拟合计算,与拟合前的动态数据相比,拟合后的动态数据能够与实际生产动态指标相吻合,取得了良好的拟合效果;且拟合后各层的油藏渗透率分布较为光滑连续,仍能较好的匹配初始先验模型地质分布特征。
上述技术方案只是本发明的一种实施方式,对于本领域内的技术人员而言,在本发明公开了应用方法和原理的基础上,很容易做出各种类型的改进或变形,而不仅限于本发明上述具体实施方式所描述的结构,因此前面描述的方式只是优选地,而并不具有限制性的意义。
- 还没有人留言评论。精彩留言会获得点赞!