一种基于随机特征子空间的半监督文本情感分类方法与流程
本发明属于自然语言处理技术与模式识别领域,具体地说是一种基于随机特征子空间的半监督文本情感分类方法。
背景技术:
近年来,随着互联网的快速发展,越来越多的互联网用户乐于在互联网上发表自己的观点和评论,产生了大量源于用户创造的主观性文本。这类主观性文本包含着用户观点、意见和态度等情感信息,因此,分析主观性文本中所表达的情感信息,识别出其情感倾向,对于互联网用户有着重要的作用。对文本情感进行分析,需要大量的有标记样本,但在实际应用中,收集大量的无标记样本相当容易,对这些无标记样本进行样本标记需要花费大量的人力和物力,从而利用大量的无标记样本和少量的有标记样本进行学习的半监督学习方法得到广泛应用。传统协同训练方法作为半监督学习方法中最常用的方法之一,其主要思想是利用交叉验证的方式进行协同训练,利用两个基分类器相互协同完成分类,但是在协同训练过程中存在大量误分的样本,随着训练样本中误分样本的增加,各个基分类器的分类精度逐渐降低,从而导致传统协同训练方法的分类准确性不高。而通过多个基分类器来帮助一个基分类器进行训练,已被广泛应用于图像识别等领域,但是目前还没有研究将多个基分类器来帮助一个基分类器的思想应用到半监督文本情感分类领域中。此外,现有的半监督学习方法主要通过Bootstrapping的方式产生多个基分类器,而对于文本情感分类问题来说,文本数据存在高维特性,通过Bootstrapping的方式产生的分类器间差异性较小而影响分类精度,同时也会影响分类器的训练速度。
技术实现要素:
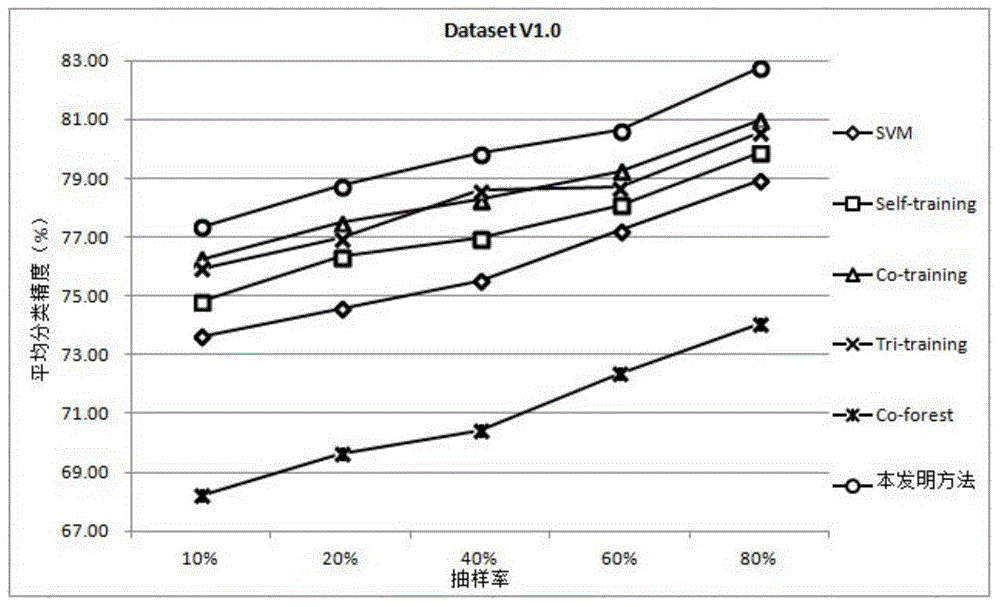
本发明为了克服现有技术存在的不足之处,提出了一种基于随机子空间的半监督文本情感分类方法,以期能解决传统协同训练算法训练过程中存在大量误分样本,以及半监督文本情感分类方法中各基分类器差异性小的问题,从而进一步提高文本情感分类方法的准确性。本发明为解决技术问题采用如下技术方案:本发明一种基于随机特征子空间的半监督文本情感分类方法的特点是按如下步骤进行:步骤1、构建全局特征集合T:步骤1.1、获取n条评论文本构成评论文本集合D,记为D={d1,d2,…di…,dn},di表示所述评论文本集合D中的第i个评论文本;1≤i≤n;n表示所述评论文本集合D中的评论文本总数;步骤1.2、去除所述评论文本集合D中所有停用词,并用N-gram的方法来表示第i个评论文本di的特征,从而获得第i个评论文本di的特征集合表示第i个特征集合Ti中第si个特征词,ri表示所述第i个特征集合Ti中的特征总数,1≤si≤ri;步骤1.3、将n个评论文本的特征集合取并集,从而构成所述评论文本集合D的全局特征集合T={t1,t2,…,tc,…,tm},tc表示所述全局特征集合T中第c个特征词,m表示所述全局特征集合T的特征词总数,1≤c≤m;步骤2、将所述评论文本集合D表示成向量形式:步骤2.1、将所述评论文本集合D中的所有评论文本映射到所述全局特征集合T上,并利用TF-IDF计算第i个评论文本di中第c个特征词tc的权值wc,i;步骤2.2、重复步骤2.1,从而获得第i个评论文本di中m个特征词在所述全局特征集合T上的权值Wi={w1,i,w2,i,…,wc,i,…,wm,i},从而获得n条评论文本的权值{W1,W2,…,Wi,…,Wn};步骤2.3、将第i个评论文本di表示成向量形式:xi={(t1,w1,i),(t2,w2,i),...,(tc,wc,i),…,(tm,wm,i)};从而获得n条评论文本的向量形式:{x1,x2,…,xi,…,xn};步骤3、对所述评论文本集D中l个评论文本进行情感极性标注,获得标记样本集,记为L={(x1,y1),(x2,y2),…,(xq,yq),…,(xl,yl)},xq表示所述标记样本集L中第q个评论文本的向量形式;yq表示所述标记样本集L中第q个评论文本的向量形式xq的情感标记,并有yq∈Y={Ω1,Ω2,…,Ωλ,…,Ωτ},Y表示标记样本集L的情感标记总集,Ωλ表示第λ个情感标记;τ表示所述情感标记的总数,τ≥2;l表示所述标记样本集L的评论文本总数,1≤q≤l≤n,1≤λ≤τ;则所述评论文本集D中剩余的n-l个文本作为未标记样本集,记为U={xl+1,xl+2,…,xl+b,…,xl+u},xl+b表示所述未标记样本集U中的第b个评论文本的向量形式,u表示所述未标记样本集U中的评论文本总数,1≤b≤u;步骤4、计算全局特征集合T中的所有特征词的特征权重:步骤4.1、根据所述标记样本集L,使用Lasso方法计算所述全局特征集合T中第c个特征词tc与所述类别标记总集Y中每个情感标记的关联性强度,获得第c个特征词tc的重要性得分γc;从而获得m个特征词的重要性得分集合γ={γ1,γ2,…,γc,…,γm};步骤4.2、利用式(1)对所述第c个特征词tc的重要性得分γc进行归一化处理,获得第c个特征词tc的特征权重δc,从而获得m个特征词的特征权重集合δ={δ1,δ2,…,δc,…,δm},γθ表示第θ个特征词tθ的重要性得分,1≤θ≤m:步骤5、构建r维的随机子空间:步骤5.1、定义抽出次数为z,定义随机子空间总数为Z;并初始化z=1;步骤5.2、以第c个特征权重δc作为所述第c个特征词tc的抽取概率,从所述全局特征集合T中随机抽取r个特征词,构成第z次抽取的投影矩阵表示第z次抽取的第g个特征词;1≤g≤r≤m;步骤5.3、分别将所述标记样本集L和未标记样本集U分别投影到所述第z次抽取的投影矩阵Vz上,从而分别构成第z个标记样本的随机子空间和第z个未标记样本的随机子空间表示所述第z个标记样本的随机子空间中第q个评论文本的向量形式;并有表示所述第z个未标记样本的随机子空间中第b个评论文本的向量形式,并有:步骤5.4、将z+1赋值给z,并重复步骤5.2和步骤5.3,直到z=Z为止;从而获得Z个标记样本集L的随机子空间集合和Z个未标记样本集U的随机子空间集合步骤6、利用所述未标记样本集U进行学习,得到最终的分类器集合步骤6.1、定义迭代次数为j,最大迭代次数为J;并初始化j=1;步骤6.2、以SVM作为基分类器,以第j次迭代的Z个标记样本集L的随机子空间集合作为第j次训练样本,并在所述第j次训练样本上进行训练,获得第j次迭代的Z个分类器集合表示第j次迭代的第z个分类器;步骤6.3、定义被帮助分类器为fa,并初始化a=1;步骤6.4、选取第j次迭代的第a个分类器作为被帮助分类器,则除第j次迭代的第a个分类器以外的(Z-1)个分类器,作为帮助分类器;步骤6.5、利用所述(Z-1)个帮助分类器对第j次迭代的(Z-1)个未标记样本集U的随机子空间集合中每个元素的第b个样本组成的集合进行预测;从而获得第j次迭代的第b个样本的情感标记集合,记为表示第j次迭代的第z个未标记样本的随机子空间中的第b个样本的向量形式的情感标记;并有步骤6.6、利用式(2)获得所述情感标记集合y(l+b),j中为第λ个情感标记Ωλ的置信度从而获得所述第b个样本的情感标记集合y(l+b),j中分别为τ个情感标记的置信度集合式(2)中,表示第λ个情感标记Ωλ在情感标记集合y(l+b),j中出现的次数;步骤6.7、重复步骤6.5和步骤6.6,从而分别获得第j次迭代的u个样本的情感标记集合,记为{y(l+1),j,y(l+2),j,…,y(l+b),j,…y(l+u),j}以及第j次迭代的u个样本的情感标记的置信度集合,记为步骤6.8、从所述第j次迭代的置信度集合中选取前ψλ个置信度最高的第λ个情感标记Ωλ所对应的样本;并判断所选取的ψλ个样本的置信度是否均大于置信度阈值σ,若均大于,则将所选取的ψλ个样本加入第j次迭代的第a个候选样本集合中;否则,从所选取的ψλ个样本中删除置信度小于所述置信度阈值σ的样本,获得剩余的ψλ′个样本,并将ψλ′赋值给ψλ,从而将ψλ个样本加入第j次迭代的第a个候选样本集合中;步骤6.9、重复步骤6.8,从而使得τ个情感标记所对应的个样本均加入所述第j次迭代的第a个选样本集合中;步骤6.10、将所述第j次迭代的第a个候选样本集合中所有样本以及与其相对应的τ个情感标记,均加入到所述第j次迭代的第a个标记样本的随机子空间中,从而获得更新的第a个标记样本的随机子空间步骤6.11、将a+1赋值给a,并返回步骤6.4顺序执行,直到a=Z;从而获得第j次迭代的Z个候选样本集合以及第j次迭代的更新的Z个标记样本集L的随机子空间集合步骤6.12、将第j次迭代的Z个候选样本集合取并集,获得优化的第j次迭代的候选样本集合Φj,并将所述优化的第j次迭代的候选样本集合Φj从所述第j次迭代的Z个未标记样本集U的随机子空间集合中删除,获得更新的第j+1次迭代的Z个未标记样本集U的随机子空间集合并重新计算未标记样本集U的未标记样本数为u′,并将u′赋值给u;步骤6.12、判断均为空集或Z次所添加的样本数量均为零是否满足,若满足,则结束第j+1次迭代,并将第j次迭代的Z个分类器作为最终的分类器集合若没有满足,则将j+1赋值给j;并返回步骤6.2,直至j=J,并将第J次迭代的Z个分类器作为最终的分类器集合步骤7、利用式(3),以主投票的方式将Z个分类器进行集成,从而获得最终的集成分类器F(xε);式(3)中,xε表示任意需要标记样本的向量表示,βλ表示分类器是否将任意需要标记样本的向量表示xε的情感标记预测为Ωλ,其值可根据式(4)计算得到;式(4)中,表示分类器对任意需要标记样本的向量表示xε进行预测的結果。与已有技术相比,本发明有益效果体现在:1、本发明通过改进RandomSubspace方式产生多个基分类器,并通过多个基分类器帮助一个基分类器进行协同训练,进而获得分类准确性高的文本情感分类方法,从而克服了传统协同训练算法协同训练过程中存在大量误分的样本的问题,同时也解决了文本数据维度高的情况下,各个分类器间差异性小和分类器训练速度慢的问题,进而提高了文本情感分类方法的准确性和学习效率。2、本发明通过基于Lasso方法的改进RandomSubspace的方式来产生多个随机子空间,并在随机子空间上训练得到多个基分类器,增大了各个基分类器间的差异性,同时通过改进RandomSubspace的方式降低了文本数据的维度,克服了Bootstrapping方式产生的基分类器间差异性小和数据维度高的情况下学习效率低的问题,减少了训练时间并提高了学习效率。3、本发明将多个基分类器帮助一个基分类器的思想应用到文本情感分类领域中,采用多个基分类器投票的方式来估计未标记样本的置信度,同时设定置信度阈值和选取置信度最高的样本来减小未标记样本的误分,克服了传统协同训练算法协同训练过程中存在大量误分样本的问题,进而提高了分类准确性。4、本发明能够利用未标记样本的信息,在实际应用中只需少量的有标记样本,无需人工对样本进行标注,通过对训练样本的合理选取,在有标记样本数量很少的情况下,本发明方法同样可以取得很高的准确性。5、本发明可以用于对互联网上的用户评论进行分析与决策,还可以用于舆情监控和信息预测等领域,本发明应用范围广泛。附图说明图1是本发明流程示意图;图2是本发明DatasetV1.0上分类精度实验结果;图3是本发明DatasetV2.0上分类精度实验结果。具体实施方式本发明对评论文本进行预处理操作来构建全局特征集合,并将所有评论文本表示成向量形式,再对部分评论文本的情感极性进行标记,得到标记样本集和未标记样本集;然后利用Lasso方法计算全局特征集合中所有特征词的特征权重,并以特征权重为概率抽取部分特征词构建随机子空间,将标记样本集映射到随机子空间上并训练分类器,同时利用未标记样本集进行协同训练,得到最终的分类器;最后以主投票的方式集成Z个分类器,并获得最终的集成分类器F(xε)。具体地说,如图1所示,本发明方法包括以下步骤:步骤1、构建全局特征集合T:步骤1.1、获取n条评论文本构成评论文本集合D,记为D={d1,d2,…di…,dn},di表示评论文本集合D中的第i个评论文本;1≤i≤n;n表示评论文本集合D中的评论文本总数;步骤1.2、去除评论文本集合D中所有停用词,并用N-gram的方法来表示第i个评论文本di的特征,从而获得第i个评论文本di的特征集合表示第i个特征集合Ti中第si个特征词,ri表示第i个特征集合Ti中的特征总数,1≤si≤ri;N-gram模型假设第N个词的出现只与前面(N-1)个词相关,N根据具体情况自行设定,本实施例中,选取N=3;步骤1.3、将n个评论文本的特征集合取并集,从而构成评论文本集合D的全局特征集合T={t1,t2,…,tc,…,tm},tc表示全局特征集合T中第c个特征词,m表示全局特征集合T的特征词总数,1≤c≤m;步骤2、将评论文本集合D表示成向量形式:步骤2.1、将评论文本集合D中的所有评论文本映射到全局特征集合T上,并利用TF-IDF计算第i个评论文本di中第c个特征词tc的权值wc,i;TF-IDF公式如下:式(1)中,hc,i表示第i个评论文本di中第c个特征词tc在第i个评论文本di中出现的次数,hp,i表示第i个评论文本di中第p个特征词tp在第i个评论文本di中出现的次数,1≤p≤m;表示出现过特征词tc的文档数;步骤2.2、重复步骤2.1,从而获得第i个评论文本di中m个特征词在全局特征集合T上的权值Wi={w1,i,w2,i,…,wc,i,…,wm,i},从而获得n条评论文本的权值{W1,W2,…,Wi,…,Wn};步骤2.3、将第i个评论文本di表示成向量形式:xi={(t1,w1,i),(t2,w2,i),...,(tc,wc,i),…,(tm,wm,i)};从而获得n条评论文本的向量形式:{x1,x2,…,xi,…,xn};步骤3、对评论文本集D中l个评论文本进行情感极性标注,获得标记样本集,记为L={(x1,y1),(x2,y2),…,(xq,yq),…,(xl,yl)},xq表示标记样本集L中第q个评论文本的向量形式;yq表示标记样本集L中第q个评论文本的向量形式xq的情感标记,并有yq∈Y={Ω1,Ω2,…,Ωλ,…,Ωτ},Y表示标记样本集L的情感标记总集,Ωλ表示第λ个情感标记;τ表示情感标记的总数,τ≥2;l表示标记样本集L的评论文本总数,1≤q≤l≤n,1≤λ≤τ;则评论文本集D中剩余的n-l个文本作为未标记样本集,记为U={xl+1,xl+2,…,xl+b,…,xl+u},xl+b表示未标记样本集U中的第b个评论文本的向量形式,u表示未标记样本集U中的评论文本总数,1≤b≤u;步骤4、计算全局特征集合T中的所有特征词的特征权重:步骤4.1、根据标记样本集L,使用Lasso方法计算全局特征集合T中第c个特征词tc与类别标记总集Y中每个情感标记的关联性强度,获得第c个特征词tc的重要性得分γc;从而获得m个特征词的重要性得分集合γ={γ1,γ2,…,γc,…,γm};Lasso方法具体为:将获得的数据表示成一个样本矩阵xp=(xp1,xp2,…,xpc,…,xpm)T,其中xp为预测变量,yp为因变量,假设个体间相互独立或给定预测变量xpc的条件下,yp是相互独立的,则Lasso估计可以定义为:式(2),μ≥0为惩罚参数,当μ的值取较大时,某些相关度低的变量系数就会被压缩为0,从而将这些变量删除,以达到特征选择的目的;当μ的值很小时,不再具有约束作用,此时所有的属性将被选择并形成一个变量选择序列,μ可根据具体情况设定,本实施例中设定μ=10-6,计算各特征量对应的回归系数;步骤4.2、利用式(3)对第c个特征词tc的重要性得分γc进行归一化处理,获得第c个特征词tc的特征权重δc,从而获得m个特征词的特征权重集合δ={δ1,δ2,…,δc,…,δm},γθ表示第θ个特征词tθ的重要性得分,1≤θ≤m:步骤5、构建r维的随机子空间:步骤5.1、定义抽出次数为z,定义随机子空间总数为Z;并初始化z=1;随机子空间总数Z可根据具体情况进行确定,本实施例设置Z=20;步骤5.2、以第c个特征权重δc作为第c个特征词tc的抽取概率,从全局特征集合T中随机抽取r个特征词,构成第z次抽取的投影矩阵表示第z次抽取的第g个特征词;1≤g≤r≤m;r表示随机子空间中的特征词总数,可根据具体情况自行设定,本实施例设置步骤5.3、分别将标记样本集L和未标记样本集U分别投影到第z次抽取的投影矩阵Vz上,从而分别构成第z个标记样本的随机子空间和第z个未标记样本的随机子空间表示第z个标记样本的随机子空间中第q个评论文本的向量形式;并有表示第z个未标记样本的随机子空间中第b个评论文本的向量形式,并有:步骤5.4、将z+1赋值给z,并重复步骤5.2和步骤5.3,直到z=Z为止;从而获得Z个标记样本集L的随机子空间集合和Z个未标记样本集U的随机子空间集合步骤6、利用未标记样本集U进行学习,得到最终的分类器集合步骤6.1、定义迭代次数为j,最大迭代次数为J;并初始化j=1;J可根据具体情况设定,本实施例中,设定J=200;步骤6.2、以SVM作为基分类器,以第j次迭代的Z个标记样本集L的随机子空间集合作为第j次训练样本,并在第j次训练样本上进行训练,获得第j次迭代的Z个分类器集合表示第j次迭代的第z个分类器;步骤6.3、定义被帮助分类器为fa,并初始化a=1;步骤6.4、选取第j次迭代的第a个分类器作为被帮助分类器,则除第j次迭代的第a个分类器以外的(Z-1)个分类器,作为帮助分类器;步骤6.5、利用(Z-1)个帮助分类器对第j次迭代的(Z-1)个未标记样本集U的随机子空间集合中每个元素的第b个样本组成的集合进行预测;从而获得第j次迭代的第b个样本的情感标记集合,记为表示第j次迭代的第z个未标记样本的随机子空间中的第b个样本的向量形式的情感标记;并有步骤6.6、利用式(4)获得情感标记集合y(l+b),j中为第λ个情感标记Ωλ的置信度从而获得第b个样本的情感标记集合y(l+b),j中分别为τ个情感标记的置信度集合式(4)中,表示第λ个情感标记Ωλ在情感标记集合y(l+b),j中出现的次数;步骤6.7、重复步骤6.5和步骤6.6,从而分别获得第j次迭代的u个样本的情感标记集合,记为{y(l+1),j,y(l+2),j,…,y(l+b),j,…y(l+u),j}以及第j次迭代的u个样本的情感标记的置信度集合,记为步骤6.8、从第j次迭代的置信度集合中选取前ψλ个置信度最高的第λ个情感标记Ωλ所对应的样本;并判断所选取的ψλ个样本的置信度是否均大于置信度阈值σ,若均大于,则将所选取的ψλ个样本加入第j次迭代的第a个候选样本集合中;否则,从所选取的ψλ个样本中删除置信度小于置信度阈值σ的样本,获得剩余的ψλ′个样本,并将ψλ′赋值给ψλ,从而将ψλ个样本加入第j次迭代的第a个候选样本集合中;ψλ表示第λ个情感标记Ωλ添加的样本数,可根据具体情况设定,本发明实验设定τ个情感标记添加的样本数均为5;置信度阈值σ可根据具体情况设定,本实施例中设定σ=0.8;步骤6.9、重复步骤6.8,从而使得τ个情感标记所对应的个样本均加入第j次迭代的第a个选样本集合中;步骤6.10、将第j次迭代的第a个候选样本集合中所有样本以及与其相对应的τ个情感标记,均加入到第j次迭代的第a个标记样本的随机子空间中,从而获得更新的第a个标记样本的随机子空间步骤6.11、将a+1赋值给a,并返回步骤6.4顺序执行,直到a=Z;从而获得第j次迭代的Z个候选样本集合以及第j次迭代的更新的Z个标记样本集L的随机子空间集合步骤6.12、将第j次迭代的Z个候选样本集合取并集,获得优化的第j次迭代的候选样本集合Φj,并将优化的第j次迭代的候选样本集合Φj从第j次迭代的Z个未标记样本集U的随机子空间集合中删除,获得更新的第j+1次迭代的Z个未标记样本集U的随机子空间集合并重新计算未标记样本集U的未标记样本数为u′,并将u′赋值给u;步骤6.12、判断均为空集或Z次所添加的样本数量均为零是否满足,若满足,则结束第j+1次迭代,并将第j次迭代的Z个分类器作为最终的分类器集合若没有满足,则将j+1赋值给j;并返回步骤6.2,直至j=J,并将第J次迭代的Z个分类器作为最终的分类器集合步骤7、利用式(5),以主投票的方式将Z个分类器进行集成,从而获得最终的集成分类器F(xε);式(5)中,xε表示任意需要标记样本的向量表示,βλ表示分类器是否将任意需要标记样本的向量表示xε的情感标记预测为Ωλ,其值可根据式(6)计算得到;式(6)中,表示分类器对任意需要标记样本的向量表示xε进行预测的結果。针对本发明方法进行实验论证,具体包括:1、标准数据集:本发明使用SentencePolarityDatasetV1.0和SentencePolarityDatasetV2.0两个数据集作为标准数据集验证基于随机子空间的半监督文本情感分类方法的有效性,SentencePolarityDatasetV1.0数据集包含5331个正情感类文本和5331个负情感类文本,SentencePolarityDatasetV2.0数据集包含1000个正情感类文本和1000个负情感类文本,以上两个数据集的文本内容均是对电影的评价;2、评价指标本发明使用目前文本情感分类领域常用的评价指标:平均分类精度(AverageAccuracy)作为本实施例的评价指标,其计算公式如式(7):式(7)中,TP(TruePositive)表示分类模型正确预测的正样本数,TN(TrueNegative)表示分类模型正确预测的负样本数,FP(FalsePositive)表示分类模型错误预测的正样本数,FN(FalseNegative)表示分类模型错误预测的负样本数;3、实验流程为了验证本发明所提方法的有效性,本发明选用文本情感分类领域常用的分类器SVM作为基分类器,对比实验选用四种常见的半监督学习方法进行比较:Self-training、Co-training、Tri-training和Co-forest方法,Self-training、Co-training、Tri-training方法均以SVM作为基分类器,Co-forest采用RandomTree作为基础分类器。SVM算法通过WEKA下的SMO模块来实现,Tri-training和Co-forest方法借鉴了其他研究者的源代码,Self-training和Co-training方法通过自行编程来实现。实验选取了10%、20%、40%、60%、80%样本作为初始训练集,采用平均分类精度为评价指标对四种半监督学习方法和本发明方法的性能进行分析比较,随机子空间总数取20。为了提高实验结果的可信度和有效性,实验过程使用10次10倍交叉验证法,本发明的实验结果均为10次10倍交叉验证的平均值。4、实验结果为了验证本发明所提方法的有效性,本发明在SentencePolarityDatasetV1.0和SentencePolarityDatasetV2.0两个数据集上进行实验,并将本发明方法的分类结果与SVM、Self-training、Co-training、Tri-training和Co-forest方法取得的结果进行了比较。实验结果如图2和图3所示,图2和图3中横坐标表示抽样率,纵坐标表示平均分类精度。由图2和图3可以看出,在抽样率分别为10%、20%、40%、60%和80%的情况下,本发明方法在两个数据集上取得的平均分类精度均高于SVM、Self-training、Co-training、Tri-training和Co-forest方法取得的平均分类精度;并且随着抽样率的增加,本发明方法取得的平均分类精度也越来越高,实验结果验证了本发明方法的有效性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1