一种在驱动中直连分片实现分布式数据库数据导入的高性能方法与流程
本发明涉及数据库技术领域。
背景技术:
数据库在备份、恢复、迁移等维护操作中,导入数据是一个常见的操作。分布式数据库一般应用于海量数据的场景,导入数据耗时往往很长。导入数据的性能,在生产环境中就尤为重要。导入数据的使用场景与正常使用的场景有所不同,它是一次性的,如失败可重做的,数据库一般处于低负载状态,各分片状态是良好而无显著差异的,各分片的SQL执行是相互独立的。利用这种场景的一些特征进行优化,是有可能获得一些针对性的性能提升。
技术实现要素:
本发明阐述了一个算法实现,可以在数据导入的场景中显著提升导入性能。算法有如下特征:
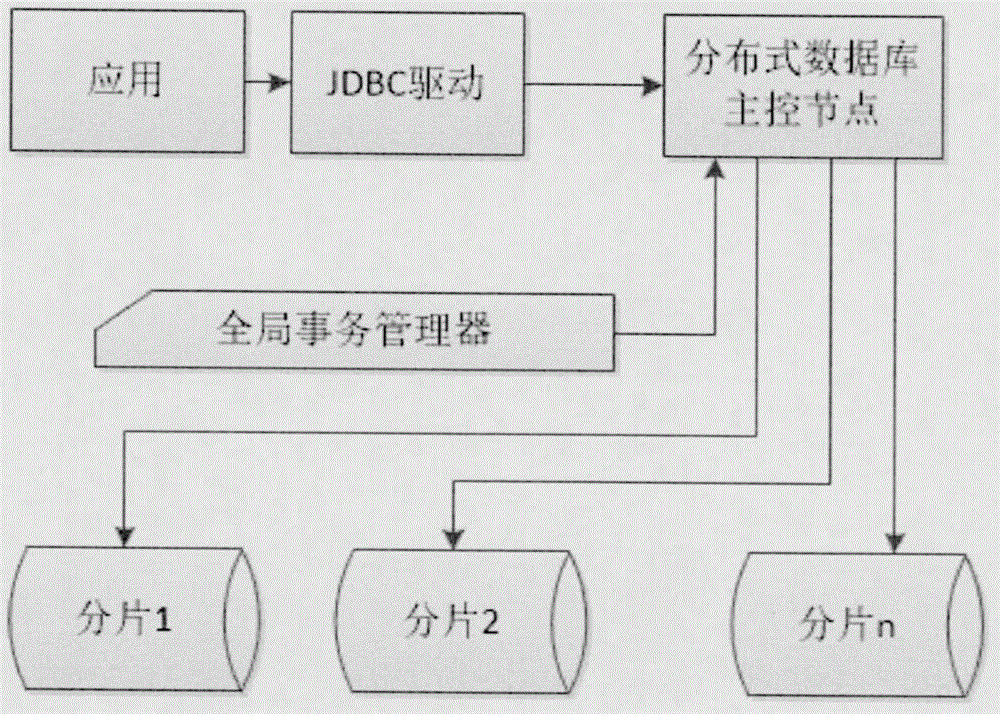
1、在数据库驱动中连接分布式数据库的主控节点,获取数据库的分片配置,冗余副本,分片规则等信息;
2、在数据库驱动中集成分片算法,绕开主控节点直接连接各分片节点;
3、对各分片待执行SQL建立阻塞队列。对SQL重新规划批次,按批提交到分片节点,写入数据;
4、各分片同步方式提供两种选择:一:性能优先,以最先完成SQL执行的分片速度控制整体事务进度;二:数据安全优先,以所有分片完成SQL执行为准控制整体事务进度。
本发明带来的性能提升主要来自两方面:一,绕开了主控节点,将导入数据的应用系统直连数据库分片节点,减少了一个中间传递步骤,去除了一个网络延迟环节,还减少了50%的网络流量,对性能提升效果是显著的;二,按批次提交SQL。算法在驱动中将SQL缓存到各分片的待执行阻塞队列中,在分片执行完成后立即组织下一批次SQL执行,在性能优先的模式下无需等待其他分片的完成,这可以将每个分片的性能潜力最大化的压榨出来。
附图说明
图1为本发明工作流程图。
图2为本发明的工作流程示意图。
具体实施方式
本发明的具体实施是通过改造原有数据库的JDBC驱动实现。具体改动由如下步骤:
1、继承原JDBC Connection对象,在构造函数中实现:
a)调用父构造函数完成既有的创建操作;
b)在父构造函数完成后,驱动与分布式数据库的主控节点已建立连接,使用恰当的管理SQL命令读取数据库的分片配置,冗余副本,分片规则等信息;
c)逐一建立与各分片节点的数据库连接;
d)为每个分片节点的数据库连接创建一个有界阻塞队列,其元素为Runnable类型;
e)为每个有界阻塞队列创建一个工作线程;
f)启动每个工作线程。工作线程从队列中取Runnable类型的对象:如有,检测对象是否是停止运行命令的实例:如是,退出线程运行,否则,运行这个Runnable对象;如队列为空,则线程阻塞,等待唤醒。
2、在此Connection对象的执行SQL方法中实现:
a)确定待执行SQL是否是可处理的类型。本发明确定的方法对SQL的最低要求是各分片SQL执行应相互独立,不能有跨节点计算。数据导入场景使用Insertinto类型的SQL是满足的。这是本发明的算法所主要针对的场景,但事实上应用场景不限于此,只要能保证无需跨节点计算,即便是多表join或子查询类型的复杂SQL也能支持。这需要根据分片上的数据库表信息结合SQL语法分析确定;
b)对不能执行的SQL,将SQL发送到数据库主控节点执行,方法结束返回;
c)对可以执行的SQL,创建一个分片节点连接到Runnable对象的映射;
d)使用集成的分片算法,遍历每条SQL。对每条SQL:创建一个Runnable对象,此对象携带了SQL和SQL执行的分片连接;
3、在全局事务管理器的同步方法中实现:
a)根据工作模式(性能优先或数据安全优先),确定线程同步的计数值。性能优先模式取值为1,数据安全优先取值为分片数。此计数值是原子整数对象;
b)遍历c)中所述映射的每个条目:按分片节点连接确定分片对应的SQL队列,将Runnable对象推到队列中;此前因队列空而阻塞的工作线程将即时被唤醒执行;
c)工作线程在SQL执行完成后,将a)中所述的计数值减一,并通知监听此计数值的同步方法线程再次读取计数值,工作线程自身再次进入读空队列而阻塞状态;
d)同步方法线程在读到计数值为零后,退出同步过程,此次SQL执行过程完成。
- 还没有人留言评论。精彩留言会获得点赞!