动态影像的物件辨识方法及自动截取目标图像的互动式影片建立方法与流程
本发明涉及一种物件辨识方法,特别是涉及一种动态影像的物件辨识方法及自动截取目标图像的互动式影片建立方法。
背景技术:
一种中国台湾公开号数第201508671号专利所公开的「网络商品推荐方法及装置」发明专利申请案,主要是通过图像辨识技术,针对包括有一个主商品的待查询商品图片,寻找与待查询商品图片具有共同性的待推荐商品图片。借此,可以在网络购物时,从大量的商品中发掘出相似的商品。
惟,目前市面上的图像辨识技术,都如前述第201508671号公开案,只能针对静态的2D图片进行辨识,且必须先建置资料库储存推荐商品图片以及机器学习时间(Machine Learning),才能与待查询商品图片进行比对,资料库愈大,就愈耗费储存空间,有比对时间受到影响而拖长,及浪费管理时间、人力等缺点。
技术实现要素:
本发明的目的在于提供一种能够针对动态影像进行辨识且速度快的动态影像的物件辨识方法及自动截取目标图像的互动式影片建立方法。
本发明的动态影像的物件辨识方法,以一个辨识系统为工具,该物件辨识方法包含下列步骤:
步骤a:该辨识系统获取一个动态影像与一个图像。
步骤b:该辨识系统对该图像进行边缘侦测,而决定一个目标物件。
步骤c:该辨识系统根据该目标物件的影像特征建立一个模型。
步骤d:该辨识系统撷取该动态影像的影像序列中的n个关键画面,n的起始值为1。
步骤e:该辨识系统比对前述关键画面中是否有与该模型相符的物件,如果是,进行步骤f,如果否,进行步骤g。
步骤f:该辨识系统撷取该关键画面为一个目标图像。
步骤g:该辨识系统使n=n+1,并回到步骤d。
本发明的动态影像的物件辨识方法,步骤f的辨识系统会同时获知该目标图像出现在该动态影像的影像序列中的时间点。
本发明的动态影像的物件辨识方法,步骤c的辨识系统建立的模型为一个立体模型,且步骤e的辨识系统会比对前述关键画面中是否有与该模型任一个角度相符的物件。
本发明的动态影像的物件辨识方法,步骤e包括
步骤e-1:该辨识系统根据该立体模型的轮廓线比对前述关键画面中是否有与前述轮廓线相似度介于50%~100%的物件,如果是,进行步骤e-2,如果否,进行步骤g,
步骤e-2:该辨识系统撷取前述关键画面中该物件的影像特征,
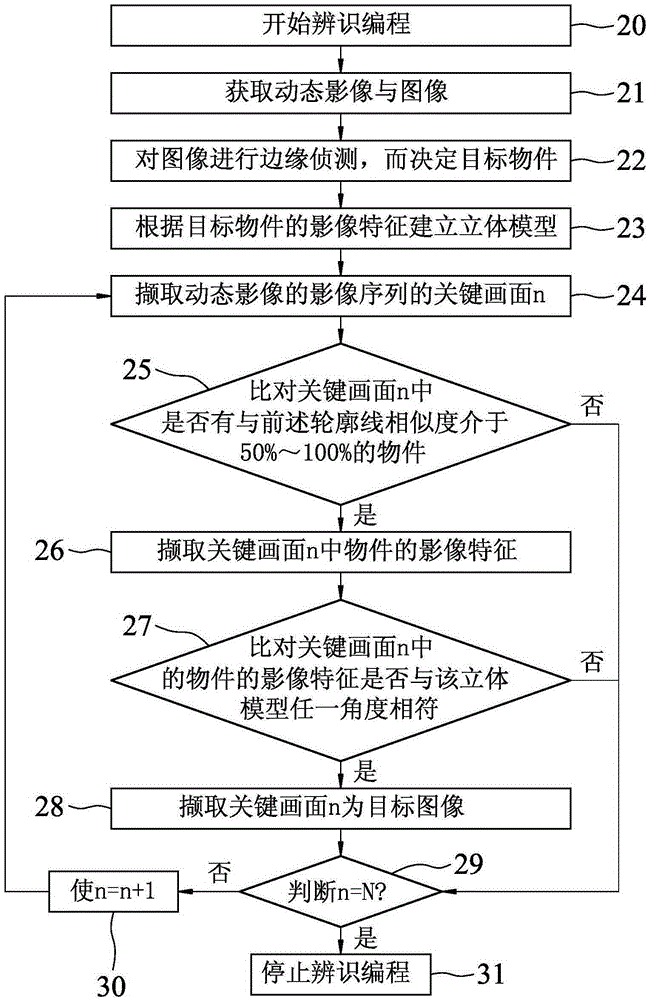
步骤e-3:该辨识系统比对该关键画面中的物件的影像特征是否与该立体模型任一个角度相符,如果是,进行步骤f,如果否,进行步骤g。
本发明的动态影像的物件辨识方法,n具有一个最大值,且步骤g包括步骤g-1:该辨识系统判断n是否等于最大值,如果是,进行步骤g-2:该辨识系统停止辨识,如果否,进行步骤g-3:该辨识系统使n=n+1,并回到步骤d。
本发明的动态影像的物件辨识方法,该动态影像与该图像来自于与该辨识系统联机的任一个储存媒体。
本发明的动态影像的物件辨识方法,该辨识系统包含撷取该动态影像的一个影像撷取装置,该动态影像为该影像撷取装置现场所撷取的即时画面。
本发明自动截取目标图像的互动式影片建立方法,包含下列步骤:
在步骤f后的步骤h:该辨识系统媒合并合并前述动态影像与被选择的目标图像为一个互动式影片。
步骤i:该辨识系统通过发布一个线上影音播放介面,该线上影 音播放介面包括浏览前述动态影像的一个第一框架,及浏览前述目标图像的一个第二框架。
本发明的自动截取目标图像的互动式影片建立方法,该辨识系统通过网络将该线上影音播放介面嵌入一个网页、一个应用编程其中的一个。
本发明的自动截取目标图像的互动式影片建立方法,前述目标图像随该第一框架内的动态影像的时间轴为顺序显示、同步显示其中一种显示方式显现在该第二框架内。
本发明的自动截取目标图像的互动式影片建立方法,还包含在步骤h前步骤f后的步骤j-1:该辨识系统呈现所有的目标图像,步骤j-2:该辨识系统根据点选任一个目标图像的一个触发讯息,呈现预载有该动态影像、该目标图像的一个设定版面,步骤j-3:该辨识系统根据通过该设定版面输入的条件设定相关于该目标图像的内容属性,前述内容属性至少包括连接网址。
本发明的自动截取目标图像的互动式影片建立方法,前述内容属性还包括名称、价格。
本发明的自动截取目标图像的互动式影片建立方法,该辨识系统包含一个第一电子装置,及与该第一电子装置联机的一个第二电子装置,该第二电子装置通过一个应用编程传送至少一个指令,使该第一电子装置根据前述指令执行前述步骤。
本发明的有益效果在于:可以彻底有别于现有做法,在不需要机器学习时间以及不需要建置资料库的情形下,可以针对任何无法预期的动态影像,立即辨识出需求的物件,不但能够打破先前技术只能针对2D图像进行辨识的限制,且辨识速度快、精准,而能够广泛运用在日常生活、商务等领域。
附图说明
本发明的其他的特征及功效,将于参照图式的实施方式中清楚地呈现,其中:
图1是一个方块图,说明本发明动态影像的物件辨识方法的一个第一实施例;
图2是该第一实施例的一个流程图;
图3是一个示意图,说明该第一实施例建立一个立体模型;
图4是一个示意图,说明该第一实施例撷取一个动态影像的影像序列中的n个关键画面;
图5是一个示意图,说明该第一实施例截取出数个目标图像;
图6是一个方块图,说明本发明自动截取目标图像的互动式影片建立方法的一个第二实施例;
图7是该第二实施例的一个流程图;
图8是该第二实施例通过一个设定版面设定内容属性的一个示意图;及
图9是该第二实施例播放一个互动式影片的一个示意图。
具体实施方式
在本发明被详细描述之前,应当注意在以下的说明内容中,类似的元件是以相同的编号来表示。
参阅图1,本发明动态影像的物件辨识方法的一个第一实施例以一个辨识系统1为工具。在本实施例中,该辨识系统1包含一个第一电子装置11,及与该第一电子装置11联机的一个储存媒体12、一个影像撷取装置13。该第一电子装置11可以是电脑、或手持式第二电子装置如:笔记本电脑、平板电脑、触控电脑、或行动通讯装置如:智能手机、或个人数码助理装置,并包括一个通讯模块111,及与该通讯模块111电连接的一个处理模块112。该储存媒体12可以是安装在该第一电子装置11的硬盘、或与该第一电子装置11连接且可抽拔的随身盘、可携式硬盘、或通过该通讯模块111与该第一电子装置11通讯的云端硬盘、或通过无线通讯技术传送资讯的储存设备。该影像撷取装置13可以直接与该第一电子装置11连接,或通过无线通讯技术、网络与该第一电子装置11通讯。
参阅图2,并配合图3、图4、图5所示,以下针对本发明动态影像的物件辨识方法结合实施例步骤说明如下:
步骤20:该第一电子装置11的处理模块112开始辨识编程。
步骤21:该第一电子装置11的处理模块112获取一个动态影像4与一个图像51。前述动态影像4的格式可以是以一种网络视讯格式编译而成,如flv、H.263、H.264、f4v、rm、wmv、m4v、mov、webm 等格式,前述图像51的格式可以是BMP、GIF、JPG/JPEG、PNG、TIF等格式,且该图像51的来源可以是前述与该第一电子装置11连接的储存媒体12,或云端的储存媒体12、或直接截取动态影像4中的画面。
重要的是,该动态影像4的来源除了可以是前述与该第一电子装置11连接的储存媒体12,或云端的储存媒体12,如youtube、youku外,还可以是由该影像撷取装置13现场所撷取的即时画面。
步骤22:该第一电子装置11的处理模块112对该图像51进行边缘侦测,而决定一个目标物件511。
值得说明的是,前述图像51的边缘侦测技术可以使用目前在该领域广泛使用的方式,由于本领域中具有通常知识者根据以上说明可以推知扩充细节,因此不多加说明。
步骤23:该第一电子装置11的处理模块112根据该目标物件511的影像特征建立一个立体模型6。
值得说明的是,前述影像特征的撷取可以使用图像识别和描述演算法(Speeded Up Robust Features,SURF),辨识前述图像中具有缩放、旋转不变量的特征点,及计算前述特征点的特征向量后,编译成影像特征码后,取得影像特征。将2D图像51中的目标物件511转成3D的立体模型6,可以使用目前在该领域广泛使用的方式,由于本领域中具有通常知识者根据以上说明可以推知扩充细节,因此不多加说明。
步骤24:该第一电子装置11的处理模块112撷取该动态影像4的影像序列V1~Vx中的n个关键画面,n的起始值为1,n并具有一个最大值N。
举例来说,该动态影像4的影像序列V1~Vx中共有100个关键画面n,则N=100。
步骤25:该第一电子装置11的处理模块112根据该立体模型6的轮廓线,比对前述关键画面n中是否有与前述轮廓线相似度介于50%~100%的物件41,如果是,进行步骤26,如果否,进行步骤29。
步骤26:该第一电子装置11的处理模块112撷取前述关键画面n中该物件41的影像特征。
步骤27:该第一电子装置11的处理模块112比对该关键画面n中的物件41的影像特征是否与该立体模型6任一个角度相符,如果是,进行步骤28,如果否,进行步骤29。
步骤28:该第一电子装置11的处理模块112撷取该关键画面n为一个目标图像52(在此,图5仅以关键画面n的物件41来说明目标图像52),并获知该目标图像52出现在该动态影像4的影像序列V1~Vx中的时间点。
举例来说,当100个关键画面n中的第20个关键画面n=20出现了与该立体模型6中任一个角度相符的物件41,就会撷取第20个关键画面n为目标图像52。
步骤29:该第一电子装置11的处理模块112判断n是否等于最大值N,如果否,进行步骤30,如果是,进行步骤31。
步骤30:该第一电子装置11的处理模块112使n=n+1,并回到步骤24。
步骤31:该第一电子装置11的处理模块112停止辨识编程。
根据前述,本发明只需要输入包含目标物件511的图像51,就可以在任意的动态影像4中找出相符且需求的物件41,借此,本发明并不需要机器学习的时间,及不需要建立资料库。举例来说,若本发明应用在交通系统,只需要输入一个车牌号码的影像,就可以利用监视器将即时影像传送给该第一电子装置11,进而快速的找出拥有该车牌的车辆,及该车辆的所在地点。又或者,只需要输入一个人的头像,就可以利用监视器将即时影像传送给该第一电子装置11,进而快速的找出符合头像的人员,及该人员的所在地点。
参阅图2,及图6、图7、图8、图9,是本发明自动截取目标图像的互动式影片建立方法的一个第二实施例,同样以该辨识系统1为工具。在本实施例中,该辨识系统1还包含通过网络与该第一电子装置11相互通讯的一个第二电子装置14。该第一电子装置11在本实施例为一个伺服主机。该第二电子装置14可以是电脑、或手持式第二电子装置如:笔记本电脑、平板电脑、触控电脑、或行动通讯装置如:智能手机、或个人数码助理装置,且通过一个应用编程传送至少一个指令,使该第一电子装置11根据前述指令接续步骤31执行互动式影 片建立编程。
以下再针对使用动态影像的物件辨识方法自动截取目标图像的互动式影片建立方法结合商务应用的实施例步骤说明如下:
步骤32:该第一电子装置11的处理模块112开始互动式影片建立编程。
步骤33:该第一电子装置11的处理模块112呈现所有的目标图像52。
步骤34:该第一电子装置11的处理模块112根据来自于该第二电子装置14点选任一个目标图像52的一个触发讯息,呈现预载有该动态影像4、该目标图像52的一个设定版面7。
步骤35:该第一电子装置11的处理模块112根据该第二电子装置14通过该设定版面7输入的条件,设定相关于该目标图像52的内容属性,前述内容属性至少包括连接网址、名称、或价格等。
步骤36:该第一电子装置11的处理模块112媒合并合并前述动态影像4与被选择的目标图像52为一个互动式影片。
步骤37:该第一电子装置11的处理模块112通过该通讯模块111发布一个线上影音播放介面8,而通过网络将该线上影音播放介面8嵌入一个网页,或嵌入一个应用编程。
该线上影音播放介面8包括浏览前述动态影像4的一个第一框架81,及浏览前述目标图像52的一个第二框架82。前述目标图像52随该第一框架81内的动态影像4的时间轴为顺序显示、同步显示其中一种显示方式显现在该第二框架82内。
步骤38:该第一电子装置11的处理模块112停止互动式影片建立编程。
值得说明的是,前述互动式影片的技术已公开在本案发明人先前所申请的中国第CN103678448A号「互动式影片商务的发布方法及其发布系统」发明专利公开案中。惟,本实用新型能够进一步改善中国第CN103678448A号专利必须手动设定物件出现的时间点,及图像的不便。
经由以上的说明,可将前述实施例的优点归纳如下:
1、以第一实施例为例,本发明可以彻底有别于现有做法,在不 需要机器学习时间以及不需要建置资料库的情形下,可以针对任何无法预期的动态影像4,立即辨识出需求的物件41,不但能够打破先前技术只能针对2D图像51进行辨识的限制,且辨识速度快(辨识速度可以是动态影像4播放时间的1/3~1/4)、精准,而能够广泛运用在日常生活、商务等领域。
2、以第二实施例为例,本发明能够针对需要目标图像52与动态影像4建立互动式影片,自动搜索该动态影像4中所有符合该图像51的目标图像52,及对应的时间点,借此,使用者不需要完整浏览动态影像4,也不需要记忆或手动输入目标图像52的时间点,而能够大幅缩短建立互动影片的时间,及提升方便性。
以上所述者,仅为本发明的实施例而已,当不能以此限定本发明实施的范围,即凡依本发明权利要求书及说明书内容所作的简单的等效变化与修饰,皆仍属本发明的范围。
- 还没有人留言评论。精彩留言会获得点赞!