一种信息匹配方法及装置与流程
本申请涉及计算机技术领域,尤其涉及一种信息匹配方法及装置。
背景技术:
随着信息技术的不断发展,越来越多的应用场景需要进行信息匹配,例如:搜索引擎的检索词匹配、论文的相似度匹配、拼写检查等。
目前,信息匹配技术通常为利用java语言的index of函数实现关键字匹配,即,建立预先写有若干关键字的文件,将用户在客户端输入的内容与该文件中所含的每个关键字进行匹配。假设预先建立的文件中包括100个关键字,那么,则需要进行100次的全文扫描才能完成对用户输入内容的信息匹配。在这个信息爆炸的时代,采用上述匹配方式进行匹配的效率非常低,无法适应信息量较大的场景。
现有技术不足在于:
现有的信息匹配方式效率低下,不能适应信息量较大的场景。
技术实现要素:
本申请实施例提出了一种信息匹配方法及装置,以解决现有技术中信息匹配方式效率低下,不能适应信息量较大的场景的技术问题。
本申请实施例提供了一种信息匹配方法,包括如下步骤:
按照待匹配信息的字符顺序接收所述待匹配信息;
将待匹配信息在预先构建的有穷状态机DFA中进行匹配,所述DFA由预 设的关键字构成,所述DFA中每个状态的输出列表包含所述状态的子孙失败状态的输出列表,所述状态的子孙失败状态与所述状态的字符相同;
在匹配过程中,如果当前状态没有与所述待匹配信息的字符相匹配的下一状态,跳转到所述当前状态的失败状态继续匹配。
本申请实施例提供了一种信息匹配装置,包括:
接收模块,用于按照待匹配信息的字符顺序接收所述待匹配信息;
匹配模块,用于将待匹配信息在预先构建的有穷状态机DFA中进行匹配,所述DFA由预设的关键字构成,所述DFA中每个状态的输出列表包含所述状态的子孙失败状态的输出列表,所述状态的子孙失败状态与所述状态的字符相同;在匹配过程中,如果当前状态没有与所述待匹配信息的字符相匹配的下一状态,跳转到所述当前状态的失败状态继续匹配。
有益效果如下:
本申请实施例所提供的信息匹配方法及装置,预先构建由预设关键字构成的有穷状态机DFA,将待匹配信息在所述DFA中进行匹配,由此关键字的匹配即变成了状态机的跳转;由于本申请实施例中所述DFA每个状态的输出列表包含所述状态的子孙失败状态的输出列表,在匹配过程中,如果当前状态没有与所述待匹配信息的字符相匹配的下一状态,则跳转到所述当前状态的失败状态继续匹配,所述待匹配信息的匹配过程只需要随着所述DFA状态一步一步地往下一状态跳转,无需返回上一状态以匹配其他关键字,从而可以确保所述待匹配信息只需要扫描一遍即可完成匹配,极大地提高了匹配效率。
附图说明
下面将参照附图描述本申请的具体实施例,其中:
图1示出了本申请实施例中信息匹配方法实施的流程示意图;
图2示出了本申请实施例中DFA结构示意图;
图3示出了本申请实施例中DFA初始化时的示意图;
图4示出了本申请实施例中DFA构建完成后的结构示意图;
图5示出了本申请实施例中群组聊天限制的DFA示意图;
图6示出了本申请实施例中信息匹配装置的结构示意图。
具体实施方式
为了使本申请的技术方案及优点更加清楚明白,以下结合附图对本申请的示例性实施例进行进一步详细的说明,显然,所描述的实施例仅是本申请的一部分实施例,而不是所有实施例的穷举。并且在不冲突的情况下,本说明中的实施例及实施例中的特征可以互相结合。
针对现有技术的不足,本申请实施例提出了一种信息匹配方法及装置,下面进行说明。
图1示出了本申请实施例中信息匹配方法实施的流程示意图,如图所示,所述信息匹配方法可以包括如下步骤:
步骤101、按照待匹配信息的字符顺序接收所述待匹配信息;
步骤102、将待匹配信息在预先构建的有穷状态机(DFA,Deterministic Finite Automata)中进行匹配,所述DFA由预设的关键字构成,所述DFA中每个状态的输出列表包含所述状态的子孙失败状态的输出列表,所述状态的子孙失败状态与所述状态的字符相同;
步骤103、在匹配过程中,如果当前状态没有与所述待匹配信息的字符相匹配的下一状态,跳转到所述当前状态的失败状态继续匹配。
具体实施中,所述待匹配信息可以为网络博客中的一篇文章,也可以为word文档中的某段文字。根据实际场景的及时性需要,所述待匹配信息可以为既有信息,也可以在用户实时输入的信息,例如:所述待匹配信息可以为已公开博文的标题,也可以为用户在搜索引擎中实时输入的检索词语。
除此之外,本申请实施例中所述待匹配信息还可以为语音,即,可以接收用户输入的语音信息,将所述语音(或转换成对应的文本)在预先构建的DFA 中进行匹配,从而实现所述用户言语内容的检测。
本申请实施例中所述预先构建的DFA,可以由预设的若干关键字组成,每个关键字所包含的字符均可以为所述DFA中的状态节点。所述DFA中与某个状态的字符相同的状态,可以作为所述状态的子孙失败状态,每个状态的子孙失败状态可以在DFA构建初始化时预先设定。
在具体匹配过程中,可以从所述DFA的初始状态开始匹配,如果当前状态的关键字集合包含所述待匹配信息中某个字符,则根据跳转路径跳转到下一状态,以开始所述待匹配信息中下一字符的读入;如果当前状态没有与所述待匹配信息的字符相匹配的下一状态,则立即跳转到所述当前状态的失败状态继续匹配;如果当前状态的输出列表不为空,则说明已经匹配到有相应的关键字,所述当前状态的输出列表即为本次新增的匹配到的所有关键字集合。
本申请实施例所提供的信息匹配方法,可以将待匹配信息在预先构建的DFA中进行匹配,所述DFA中每个状态的输出列表包含所述状态的子孙失败状态的输出列表,在匹配过程中,如果当前状态没有与所述待匹配信息的字符相匹配的下一状态,跳转到所述当前状态的失败状态继续匹配,所述待匹配信息的匹配过程只需要随着所述DFA中各个状态的跳转条件一步一步地向下一状态跳转,无需返回上一状态以匹配其他关键字,从而可以确保所述待匹配信息只需要扫描一遍即可完成匹配,极大地提高了匹配效率。
实施中,所述方法可以进一步包括:
输出与所述待匹配信息匹配的关键字集合。
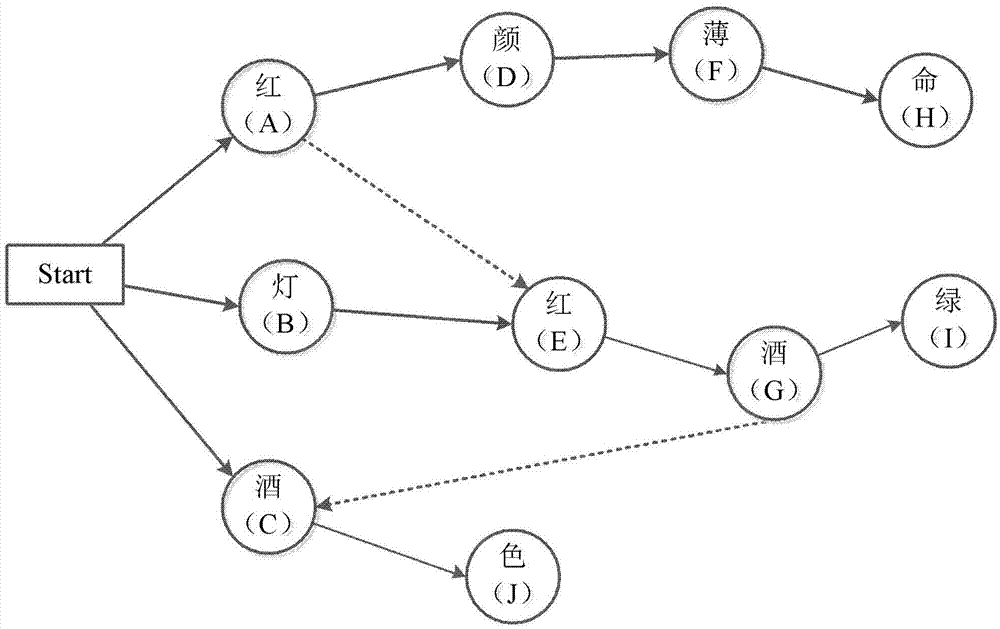
例如,预设的关键字可以为“红颜薄命”、“灯红酒绿”、“酒色”等,生成的DFA可以如图2所示,其中,虚线代表某个状态与其失败状态的关联关系。
DFA初始化时,只有叶子节点默认获得输出列表,其他非叶子节点的输出列表为空,即:
H的outputlist为{“红颜薄命”};
I的outputlist为{“灯红酒绿”};
J的outputlist为{“酒色”};
在DFA初始化完毕时,可以立即构建各状态与其子孙失败状态的关联关系,A状态的子孙失败状态为E,G状态的子孙失败状态为C,并分别获得其子孙失败状态的输出列表。
本申请实施例中虽然A、G存在子孙失败状态,但由于它们的子孙失败状态的输出列表也为空,故A、G的输出列表依旧为空。
假设待匹配信息为“察看红酒色泽为品酒方法之一”,从start开始,匹配“红”,跳转到A状态节点后,没有与下一字符相匹配的状态,所以立即跳转到E状态,从E开始继续匹配,下一字符与“酒”匹配,故跳转到G状态节点;在跳转到G状态节点后,没有与下一字符相匹配的状态,所以立即跳转到C状态,从C开始继续匹配,存在与“色”匹配的下一状态节点,故跳转到J节点,得到输出列表为J的输出列表,即输出与所述待匹配信息匹配的关键字集合为“酒色”。
本申请实施例中在匹配结束后输出与所述待匹配信息匹配的关键字集合,可以为后续的统计、分析等操作提供数据支持。
实施中,所述方法可以进一步包括:
确定匹配的关键字在所述待匹配信息中的位置;
根据关键字所在位置、预设关键字权重和关键字的匹配次数计算所述待匹配信息的重要度。
具体实施中,在匹配时可以记录每个匹配的关键字在所述待匹配信息中的位置,假设所述待匹配信息为一篇包括标题和正文的文章,每当匹配到一个关键字时,则可以记录所述关键字是在所述文章的标题部分还是在所述文章的正文部分;在匹配结束后,统计每个关键字的匹配次数,例如:假设标题出现“酒色”1次,正文出现“酒色”12次,计算所述文章的重要度。
具体的,计算所述待匹配信息的重要度,可以结合预先设定的关键字等级/打分来实现,例如:预先设定关键字“酒色”在标题出现时分值为0.8、正文 出现时分值为0.2,那么,所述文章的重要度可以为0.8*1+0.2*12=3.2。
本申请实施例可以在匹配时确定匹配的关键字在所述待匹配信息中的位置、关键字的匹配次数,结合预设关键字权重,来得到所述待匹配信息的重要度。
实施中,在所述按照待匹配信息的字符顺序接收所述待匹配信息之后,将待匹配信息在有穷状态机DFA中进行匹配之前,所述方法可以进一步包括:
对所述待匹配信息进行预处理操作。
本申请实施例中,当接收到所述待匹配信息时,可以首先对所述待匹配信息进行一些预处理操作,以便于后续所述待匹配信息在有穷状态机中的匹配,提高匹配效率或精度。
实施中,所述预处理操作可以包括以下至少一种:中英文转换、拼音汉字转换、繁简体转换、全角半角转换、数字大小写转换、去除干扰字符。
其中,干扰字符可以为标签符号、html标签等字符。
具体实施时,由于同一个词语可以通过不同形式标示出来,为了提高防变种能力,本申请实施例可以将所述待匹配信息中的某个或全部字符进行中英文转换、拼音汉字转换、繁简体转换、全角半角转换、数字大小写转换等。例如:预设关键字包括“酒色”,但待匹配信息中为“酒se”,此时,本申请实施例可以将“se”转换为“色”之后进行匹配。
本申请实施例中,在接收所述待匹配信息之后,可以对所述待匹配信息进行中英文转换、拼音汉字转换、繁简体转换、全角半角转换、数字大小写转换、去除干扰字符等预处理操作,从而防止关键字由于变种而导致匹配失败的情况出现,在一定程度上提高匹配的成功率,增强所述DFA防变种能力。
实施中,在所述按照待匹配信息的字符顺序接收所述待匹配信息之前,所述方法可以进一步包括:
根据预先设置的关键字构建有穷状态机DFA,所述DFA初始化时所有叶子节点分别获得各自的输出列表;
建立所述DFA中各状态与其子孙失败状态的关联关系,每个状态获得所述状态的子孙失败状态的输出列表。
本申请实施例中可以预先构建有穷状态机,然后再将接收到的待匹配信息在所述有穷状态机中进行匹配。
本申请实施例中,有穷状态机的数据结构可以包括:匹配成功时所有跳转状态(gotoMap)、匹配失败时下一个跳转状态(failureState)和关键字列表(outputlist)。
具体实施时,failurestate构建过程可以如下:
首先,可以创建一个链表LinkedList;
在所述DFA中自顶向下进行搜索,搜索与其中的每个状态包含相似信息的节点。
如果经搜索,找到了与某个状态包含相似信息的节点,则可以将该节点作为所述状态的子孙failureState加入到所述链表中,将DFA中每个状态State的failureState对应的输出列表outputlist加入到所述状态自己的outputlist中。
如果经搜索,没有找到与某个状态包含相似信息的节点,那么,可以默认设置该状态的failureState为startState,重新开始匹配状态。
在搜索过程中,可以设置当所述failureState为开始状态时跳出循环,从而避免搜索陷入死循环。
经过上述过程后,每个状态的整个子孙failureState均已加入到所述链表中,其中,链表指针越靠近头结点其对应的状态所包含的信息越和头结点接近。
failureState可以在DFA初始化时基于敏感词之间本身的关联性而设定,可以通过广度优先搜索策略完成DFA的重建。
本申请实施例通过在匹配无法继续的情况下跳转到failurestate继续匹配,来保证整个文本扫描一遍即可完成匹配,只需要向前走、无需返回。
本申请实施例中的匹配过程可以如下:
首先,在开始匹配时进行初始化操作,可以将当前状态curState设置为初 始状态startState,设置变量i初始值为0;
从变量i=0开始进行匹配过程,如果DFA构建存在循环则执行跳出匹配操作;如果DFA构建不存在循环,则可以从初始状态开始匹配,直至变量i=文本长度text.length。
在匹配过程中,如果当前状态关键字集合包含文本中某一字符,那么,则根据跳转路径跳转到下一状态,以开始文本中下一字符的读入。
如果当前状态的输出列表不为空,则说明本次匹配过程已经匹配到有相应的关键字,其中的输出列表outputlist正是本轮匹配新增的匹配到的所有关键字集合,记录本轮新增的关键字匹配信息,其中可以包括关键字本身和匹配位置。
本申请实施例在匹配时,可以从初始状态startstate进行匹配,如果当前状态关键字集合中包含待匹配信息中某一字符,则根据跳转路径跳转到下一状态,开始所述待匹配信息的下一字符的读入,如果初始状态一直指向所述初始状态的失败状态,则提示“DFA构建存在循环”警告。
按照上述跳转方式继续匹配,如果到达某个状态(读入到所述待匹配信息中某个字符)时,该状态的输出列表不为空,则说明已经匹配到相应关键字,该状态的输出列表即为本轮匹配过程得到的所有关键字集合,本轮匹配结束。记录本轮匹配得到的关键字以及关键字的所在位置。
具体实施中,可以从所述待匹配信息的当前字符的下一字符开始,重新在DFA中startstate开始匹配。
本申请实施例所提供的信息匹配方法,可以首先根据预先设置的关键字构建有穷状态机,所述有穷状态机中每个状态均获得其子孙失败状态的输出列表;然后接收待匹配信息,对待匹配信息进行预处理操作后将所述待匹配信息从所述有穷状态机的初始状态开始匹配;在某个状态匹配失败时直接跳转到所述状态的子孙失败状态继续匹配,无需返回所述状态的之前状态,直至获得存在输出列表的状态,输出所述输出列表中包含的关键字集合,本轮匹配结束;如果此时所述待匹配信息的当前字符之后还存在未匹配字符,则将所述待匹配 信息中当前字符之后的字符从状态机的初始状态开始重新开启新一轮的匹配。
为了便于本申请的实施,下面以实例进行说明。
实施例一、
以过滤文本中敏感词这一应用场景为例,进行说明如下:
敏感词,一般是指带有敏感政治倾向(反执政党倾向)、暴力倾向、不健康色彩或不文明的词语,也可以指一些企业根据自身实际情况,自行设定的适用于企业内部的特殊违禁词语。
假设敏感词为:很邪恶的、很邪门、邪恶、恶、邪性;
图3示出了本申请实施例中这5个敏感词作为关键词构成的DFA初始化时的示意图,如图所示,所述DFA初始化时所有的叶子节点都可以默认获得outputlist,其他节点的outputlist均为空。
各叶子节点的outputlist如下所示:
C状态的outputList为{“恶”};
E的outputList为{“邪恶”};
G的outputList为{“很邪门”};
H的outputList为{“很邪恶的”};
I的outputList为{“邪性”}。
在DFA初始化完毕时,可以立即构建各状态的failurestate,每个状态都可以获取它子孙failurestate的outputlist。
图4示出了本申请实施例中DFA构建完成后的结构示意图,图4中以虚线表示状态与其failurestate的关系,如图所示,D状态的子孙failurestate为B,F状态的子孙failurestate为E、C。
由于C状态的outputList为{“恶”},C为E的子孙failurestate,因此,E的outputlist变为{“邪恶”,“恶”};
由于E的outputlist变为{“邪恶”,“恶”},E为F的子孙failurestate,因此,F的outputList变为{“邪恶”,“恶”}。
虽然B为D的子孙failurestate,但由于B状态为非叶子节点、outputlist为空,所以,D的outputList依然为空。
假设待匹配的文本为:
1)这玩意真的很邪恶呼?
2)这玩意真的很邪性呼?
当对整个文本“这玩意真的很邪恶呼?”匹配时,字符“很”与A状态匹配,A状态的下一级存在与“邪”匹配的状态(即D状态),故跳转到D;D状态的下一级存在与“恶”匹配的状态(即F状态),故跳转到F状态;走到F状态,由于F状态的下一级没有与“呼”匹配的状态,匹配不下去,立即跳转到E,直接获取到E的outputList{“邪恶”,“恶”}。输出匹配得到的关键字为邪恶、恶。
当对整个文本“这玩意真的很邪性呼?”匹配时,字符“很”与A状态匹配,A状态的下一级存在与“邪”匹配的状态(即D状态),故跳转到D;走到D状态,由于D状态的下一级没有与“性”匹配的状态,匹配不下去,立即跳转到B,从B开始继续跳转。B状态的下一级存在与“性”匹配的状态(即I状态),故跳转到I,获得I的outputList{“邪性”}。输出匹配得到的关键字集合为{“邪性”}。
具体应用时,可以预先设定“邪性”这一关键字位于文档的标题、正文的分值,或者预先设定“邪性”这一关键字位于文档的正文首段、正文中段、正文结尾的不同等级,从而可以确定出该文档的重要度。
还可以进一步将所有待匹配信息按照计算得到的重要度进行排序,设定过滤阈值,如果超过所述预设阈值,则将该文档进行屏蔽。
综上可以看出,采用本申请实施例所提供的信息匹配方法,对于待匹配的文本而言,匹配过程始终是往前走、不需要返回,全文扫描一次即可完成匹配。
采用本申请实施例所提供的信息匹配方法,测试样本为几千字的博客文本、敏感词字库有上千个时,测试的平均匹配性能可以达到O(ms)级别,效率 远远高于现有的匹配算法。
实施例二、
以网络聊天文明用语这一应用场景为例,进行说明如下:
实际使用时,为了确保群组成员的用语文明,群管理员可以预先将限制词语作为关键字,由系统自动生成如本申请实施例中所提供的DFA,当有成员输入带有预设关键字的言语时进行屏蔽。
图5示出了本申请实施例中群组聊天限制的DFA示意图,如图所示,假设预设的限制成员使用的词语为:二货、缺心少肺、心眼、滚,其中F的failurestate为C。
假设群组内成员A输入“2货,你是不是缺心眼?”,系统按照A输入的顺序接收所述待匹配信息(即“2货,你是不是缺心眼?”),然后对这句话进行预处理操作,将这句话中的标点符号去掉,得到所述待匹配信息为“2货你是不是缺心眼”,然后进一步将其中的小写数字“2”转换为大写数字“二”,从状态机的start开始进行匹配。
A状态节点与待匹配信息的第一个字符(即“二”)匹配,从start跳转到A,然后E状态节点与待匹配信息的第二个字符(即“货”)匹配,从A跳转到E;待匹配信息的第三个字符是“你”,由于E没有与“你”匹配的下一个状态节点,也没有failurestate,故输出E的outputlist(即“二货”关键字),默认E的failurestate为start,重新开始新一轮的匹配。
从start开始,“你”、“是”、“不”、“是”均没有匹配的字符,所述待匹配信息中第7个字符“缺”与B状态节点匹配,故从start跳转到B;所述待匹配信息中第8个字符“心”与F状态节点匹配,故从B跳转到F;待跳转到F之后,由于F没有与第9个字符“眼”匹配的下一状态,但F有failurestate(即C),因此,直接从F跳转到C继续匹配;C的下一状态I与所述待匹配信息的第9个字符“眼”匹配,故输出I的outputlist(即“心眼”关键字)。
至此,待匹配信息完成匹配过程,最终输出关键字集合为{“二货”,“心 眼”}。
由于群组成员A输入的语言包括了上述两个关键字,为了确保组员之间的和谐,可以限制成员A的上述言论或进一步发出警告。
本申请实施例所提供的方案,在每一轮匹配过程中只需要从start节点逐步向下一节点跳转,中途无需向前节点跳转返回匹配,从而可以提高匹配效率,满足聊天及时性检测的需求;另外,还可以对待匹配信息进行预处理,以提高匹配的成功率,防止由于关键字变种导致匹配失败的情况发生。
基于同一发明构思,本申请实施例中还提供了一种信息匹配装置,由于这些设备解决问题的原理与一种信息匹配方法相似,因此这些设备的实施可以参见方法的实施,重复之处不再赘述。
图6示出了本申请实施例中信息匹配装置的结构示意图,如图所示,所述信息匹配装置可以包括:
接收模块601,用于按照待匹配信息的字符顺序接收所述待匹配信息;
匹配模块602,用于将待匹配信息在预先构建的有穷状态机DFA中进行匹配,所述DFA由预设的关键字构成,所述DFA中每个状态的输出列表包含所述状态的子孙失败状态的输出列表,所述状态的子孙失败状态与所述状态的字符相同;在匹配过程中,如果当前状态没有与所述待匹配信息的字符相匹配的下一状态,跳转到所述当前状态的失败状态继续匹配。
实施中,所述装置可以进一步包括:
输出模块603,用于输出与所述待匹配信息匹配的关键字集合。
实施中,所述装置可以进一步包括:
确定模块604,用于确定匹配的关键字在所述待匹配信息中的位置;
计算模块605,用于根据关键字所在位置、预设关键字权重和关键字的匹配次数计算所述待匹配信息的重要度。
实施中,所述装置可以进一步包括:
预处理模块606,用于在所述按照待匹配信息的字符顺序接收所述待匹配 信息之后,将待匹配信息在有穷状态机DFA中进行匹配之前,对所述待匹配信息进行预处理操作。
实施中,所述预处理模块606具体可以用于在所述按照待匹配信息的字符顺序接收所述待匹配信息之后,将待匹配信息在有穷状态机DFA中进行匹配之前,对所述待匹配信息进行以下至少一种操作:中英文转换、拼音汉字转换、繁简体转换、全角半角转换、数字大小写转换、去除干扰字符。
实施中,所述装置可以进一步包括:
状态机构建模块607,用于在所述按照待匹配信息的字符顺序接收所述待匹配信息之前,根据预先设置的关键字构建有穷状态机DFA,所述DFA初始化时所有叶子节点分别获得各自的输出列表;建立所述DFA中各状态与其子孙失败状态的关联关系,每个状态获得所述状态的子孙失败状态的输出列表。
为了描述的方便,以上所述装置的各部分以功能分为各种模块或单元分别描述。当然,在实施本申请时可以把各模块或单元的功能在同一个或多个软件或硬件中实现。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本申请的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本申请范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!