VLIW型指令束结构和适用于处理该指令束的处理器的制作方法
本发明涉及超长指令字(VLIW)处理器,并且特别地涉及可变长度指令束(instructionbundle)处理器。
背景技术:
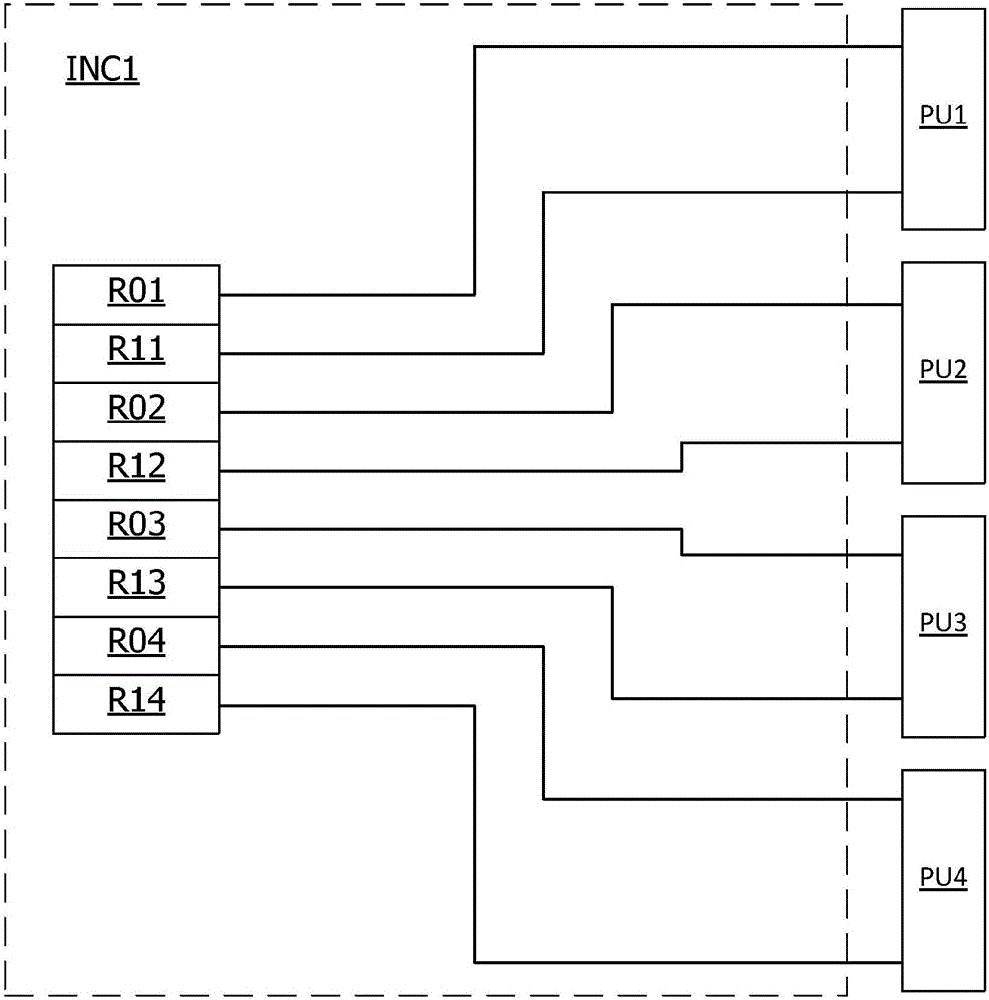
:该处理器包括具有用于并行执行多个指令的多个处理单元的CPU。VLIW指令束可以包括以CPU的不同处理单元为目标的多个基本指令。因此,用于该处理器的指令束可以达到典型地在64和128位之间的长度,或者甚至达到256位或更多。在一些VLIW处理器中,通常以相同顺序执行对指令束的基本指令在CPU处理单元之间的分配。图1示出了这种处理器的处理单元PU1、PU2、PU3、PU4的输入电路INC1。电路INC1包括被设计为接收指令束的基本指令的寄存器R01-R04和R11-R14。寄存器R0j、R1j被连接到处理单元PUj,其中j=1、2、3和4。然后,VLIW指令束被分成多个道(lane),每个道被指定到处理单元PUj。编译器然后被配置为向它生成的每个指令束中的特定道指定仅可由对应于该道的处理单元处理的基本指令。由编译器生成的指令束然后系统地呈现以下结构:P1-P2-P3-P4,Pj是可由处理单元PUj(j=1、2、3或4)唯一地执行的基本指令。如果要由处理器执行的程序包括需要相同处理单元的连续基本指令,则可能需要将这些基本指令分配给不同的VLIW指令束。如果这些束的其它道不能接收要求其它处理单元的基本指令,则这些道通常接收不触发任何处理的基本NOP指令。此外,在可变尺寸的基本指令的情况下,编译器采用一个或多个基本NOP指令来完成接收小于最大尺寸的基本指令的道。术语“字节(syllable)”指示组成可变尺寸的基本指令的固定尺寸的字。在图1的示例中,基本指令包括相同尺寸的一个或两个字节。因此,寄存器R01-R04被配置为接收指令束的基本指令的第一字节,并且寄存器R11-R14被配置为接收可能的基本指令的第二字节。对于没有第二字节的每个基本指令,与接收基本指令的第一字节的寄存器R0j配对的寄存器R1j采用单个字节NOP指令填充。因此,包含程序的存储器的实质部分可能被NOP指令占用。因此同样地,处理器指令总线上的数据流的实质部分包含该指令束。这些缺点导致CPU处理资源的不良使用以及功率损耗。也因此,程序存储器的显著部分不必要地被NOP指令占用。一些处理器被设计为不限制VLIW束指令到处理单元的分配。通过这种配置,不需要在指令束中插入NOP指令。为此,每个处理单元的每个指令输入包括复用器,复用器的输入被连接到接收VLIW束的基本指令的输入寄存器。图2示出了在VLIW指令束中的基本指令具有多达两个字节的情况下,处理单元PU1-PU4的输入电路INC2。输入电路INC2包括寄存器R01-R04和R11-R14,以及用于每个处理单元PU1-PU4的两个复用器MX01-MX04和MX11-MX14。由这种处理器的编译器生成的VLIW束包括至多四个基本指令,每个具有相同尺寸的一个或两个字节。每个第一复用器MX01-04向其所连接的处理单元PU1-PU4提供基本指令的第一字节,并且每个第二复用器MX11-MX14向其所连接的处理单元PU1-PU4提供基本指令的第二字节。由于寄存器R01不能接收第二基本指令字节,所以它只连接到第一复用器MX01-MX04。因此,对于四个处理单元PU1-PU4,每个第一复用器MX01-MX04具有八个输入,并且每个第二复用器MX11-MX14具有七个输入。因此,复用器MX01-MX04和MX11-MX14可以由三位控制字控制。这导致寄存器R01-R04和R11-R14与复用器MX01-MX04和MX14-M11之间的互连电路,以及具有相对高复杂度(60个复用器输入)的复用器控制电路。此外,信号在复用器中的传播时间随着复用器的输入数量而增加。特别地,复用器MX01至MX04的存在可能需要将指令束的处理延迟一个时钟周期。通过根据被指定给处理单元的级(rank)对VLIW指令束中的基本指令进行排序,以及通过使用NOP指令完成较短的基本指令(短于最大字节数),可以显著减少复用器输入的数量,使得最后完成的指令束中的所有基本指令具有相同的长度,即相同数量的字节。因此,图3示出了处理单元PU1-PU4的输入电路INC3。输入电路INC3包括寄存器R01-R04和R11-R14,以及复用器MX22-MX24和MX32-MX34。寄存器R01和R11被直接连接到处理单元PU1的第一和第二输入。复用器MX22通过其输入被连接到寄存器R01和R02,并且通过其输出被连接到处理单元PU2的第一输入。复用器MX32通过其输入被连接到寄存器R11和R12,并且通过其输出被连接到处理单元PU2的第二输入。复用器MX23通过其输入被连接到寄存器R01、R02和R03,并且通过其输出被连接到处理单元PU3的第一输入。复用器MX33通过其输入被连接到寄存器R11、R12和R13,并且通过其输出被连接到处理单元PU3的第二输入。复用器MX24通过其输入被连接到寄存器R01-R04,并且通过其输出被连接到处理单元PU4的第一输入。复用器MX34通过其输入被连接到寄存器R11-R14,并且通过其输出被连接到处理单元PU4的第二输入。该解决方案将复用器MX22-MX24、MX32-MX34的输入数量限制为18。然而,因为NOP指令仍被添加到不具有最大数量的字节的基本指令的指令束中,所以该解决方案仅部分地有助于改进处理器资源的使用和程序存储器的使用。通过维持指令束中基本指令的顺序对应于被指定给处理单元的顺序,可以避免对在VLIW指令束中插入NOP指令的需要。因此,图4示出了处理单元PU1-PU4的输入电路INC4。输入电路INC4包括寄存器R01-R04和R11-R14,以及复用器MX42-MX44和MX52-MX54。寄存器R01和R11被直接连接到处理单元PU1的第一和第二输入。复用器MX42通过其输入被连接到寄存器R02、R11和R02,并且通过其输出被连接到处理单元PU2的第一输入。复用器MX52通过其输入被连接到寄存器R11、R02和R12,并且通过其输出被连接到处理单元PU2的第二输入。复用器MX43通过其输入被连接到寄存器R01、R11、R02、R12和R03,并且通过其输出被连接到处理单元PU3的第一输入。复用器MX53通过其输入被连接到寄存器R11、R02、R12、R03和R13,并且通过其输出被连接到处理单元PU3的第二输入。复用器MX44通过其输入被连接到寄存器R01-R04和R11-R13,并且通过其输出被连接到处理单元PU4的第一输入。复用器MX54通过其输入被连接到寄存器R02-R04和R11-R14,并且通过其输出被连接到处理单元PU4的第二输入。该解决方案将复用器MX42-MX44、MX52-MX54的输入数量限制为30,而无需在VLIW指令束中插入NOP指令。然而,该解决方案还需要具有大量输入的复用器。特别地,复用器MX44可能需要将指令束的处理延迟一个时钟周期。期望简化VLIW处理器的处理单元的输入电路,而不会损害CPU处理资源的使用和程序存储器的使用,并且不增加功率消耗。还期望改进该输入电路的用于将指令束的基本指令传输到各种处理单元的效率。技术实现要素:实施例涉及一种用于具有能够执行具有若干基本指令的指令束的多个处理单元的处理器的程序的编译方法,方法包括以下步骤:在指令束中收集多个基本指令,每个基本指令以处理器的相应处理单元为目标,每个基本指令包括一个或多个字节,每个字节具有在基本指令中的级;以及根据相同级的字节的组分配在指令束中基本指令的字节,将指令束的所有基本指令的第一级的字节的组在指令束中插入到指令束的所有基本指令的第二级的字节的组之前,每个组中的字节根据每个字节的目标处理单元来排序。在实施例中,相同级的字节在指令束中排序,使得高优先级处理单元首先接收其相应的基本指令字节。在实施例中,每个指令束的每个字节包括指示字节是否是指令束中的最后一个的结束码。在实施例中,每个指令束的每个字节包括指示字节将被传输到的处理单元的处理单元代码。在实施例中,每个指令束的每个字节包括指示字节的级的代码。在实施例中,每个指令束包括比处理单元的数量乘以每基本指令的最大字节数量更少的字节。在实施例中,所有基本指令的字节具有相同的长度。实施例还涉及一种处理器,处理器包括:用于并行处理多个基本指令的多个处理单元,基本指令包括一个或多个字节,每个字节具有在基本指令中的级;以及输入电路,输入电路被配置为接收包括多个基本指令的指令束,以及向处理单元传输指令束的基本指令的第一级的所有字节比向处理单元传输指令束的基本指令的第二级的字节更快,相同级的字节根据每个字节的目标处理单元来排序。在实施例中,指令束的字节在相同级的字节组中进行分配,第一级的字节的组被放置在指令束的开始,其中每个组中的字节以被指定给处理单元的顺序来排序。在实施例中,输入电路被配置为相对于被指定给处理单元的顺序向处理单元传输指令束的每个组的字节。在实施例中,输入电路包括被配置为接收指令束的每个相应字节的寄存器,寄存器的数量至多等于处理器的处理单元的数量乘以每基本指令的字节的最大数量。在实施例中,寄存器的数量小于处理器的处理单元的数量乘以每基本指令的字节的最大数量。在实施例中,每个指令束的每个字节包括指示字节是否是指令束中的最后一个的结束码。在实施例中,每个指令束的每个字节包括指示字节将被传输到的处理单元的处理单元代码。在实施例中,每个指令束的每个字节包括指示字节的级的代码。附图说明通过仅出于示例性目的而提供的并且在附图中表示的本发明的具体实施例的以下描述,其它优点和特征将变得更加显而易见,在附图中:图1-4示意性地示出了根据现有技术的各种解决方案的VLIW处理器的处理单元以及其输入电路;图5示意性地示出了根据实施例的VLIW处理器的处理单元以及其输入电路;图6示意性地示出了根据实施例的指令束;图7和8示出了根据实施例的基本指令结构;图9示意性地示出了根据另一实施例的VLIW处理器的处理单元以及其输入电路。具体实施方式根据实施例,编译器通过从基本指令的第一字节开始对每个VLIW指令束中的基本指令进行排序来产生VLIW指令束,每个VLIW指令束包括一个或多个基本指令,每个基本指令由一个或多个字节形成。因此,每个VLIW指令束包括该束的所有基本指令的第一级的字节,然后是可能的第二级的字节等等。每个级的字节根据被指定给处理单元的顺序来排序。因此,仅字节的顺序被置于VLIW指令束中,而不是字节在束中的确切位置。图5示出了处理器PRC的处理单元PU1-PU4和用于处理单元PU1-PU4的输入电路INC,其适于处理该指令束。输入电路INC包括指令寄存器R21至R28,以及将输入寄存器连接到处理单元的复用器MX62-MX64和MX71-MX74。每个寄存器R21-R28接收VLIW指令束的基本指令的相应字节。图5示出了具有四个处理单元并因此能够处理多达四个基本指令的VLIW指令束的处理器的情况。寄存器R01被直接连接到处理单元PU1的第一输入。复用器MX71通过其输入被连接到寄存器R22-R25,并且通过其输出被连接到处理单元PU1的第二输入。复用器MX62通过其输入被连接到寄存器R21和R22,并且通过其输出被连接到处理单元PU2的第一输入。复用器MX72通过其输入被连接到寄存器R22-R26,并且通过其输出被连接到处理单元PU2的第二输入。复用器MX63通过其输入被连接到寄存器R21-R23,并且通过其输出被连接到处理单元PU3的第一输入。复用器MX73通过其输入被连接到寄存器R22-R27,并且通过其输出被连接到处理单元PU3的第二输入。复用器MX64通过其输入被连接到寄存器R21-R24,并且通过其输出连接到处理单元PU4的第一输入。复用器MX74通过其输入被连接到寄存器R22-R28,并且通过其输出被连接到处理单元PU4的第二输入。因此,复用器MX62-MX64、MX71-MX74的输入数量被限制为32,并且不必在VLIW指令束中插入NOP指令。此外,接收指令束的第一字节的复用器MX62-MX64包括数量被减少的输入,并且处理单元PU1的第一字节输入被直接连接到寄存器R01。因此,处理单元PU1-PU4接收在第二字节之前的第一字节。由于第二字节不需要解码第一字节,输入电路INC具有启动指令束的基本指令的处理的特征,并且因此在传送到可以存在于寄存器R22-R28中的基本指令的可能后续字节的处理单元之前激活涉及的所有处理单元PU1-PU4。图6示出了指令束IW。根据实施例,指令束包括基本指令Pj的第一级Pj[1]的字节组G1,可能地基本指令Pj的第二级Pj[2]的字节组G2,以及可能地当基本指令具有多于两个字节时基本指令Pj的一个或多个低级字节组。这里,j对应于处理器的处理单元号,并且可以是图5的示例中的1、2、3或4。因此,指令束IW可以具有以下最小和最大内容,其分别为:最小:Pj[1],其中j=1、2、3或4最大:P1[1]-P2[1]-P3[1]-P4[1]-P1[2]-P2[2]-P3[2]-P4[2]其中Pj[1]表示可由处理单元PUj(j=1、2、3或4)执行的基本指令Pj的第一字节(或级1的字节),并且Pj[2]表示基本指令Pj的第二字节(级2的字节)。假设指令束在没有对应的第一字节Pj[1]时无法具有第二字节Pj[2],通过从最大内容中移除一个或多个字节,保持最大内容的字节的顺序,可以获得指令束的所有可能的内容。寄存器R21-R28的可能内容如下表1所示:表1R21P1[1]P2[1]P3[1]P4[1]R22P2[1]P3[1]P4[1]P1[2]P2[2]P3[2]P4[2]R23P3[1]P4[1]P1[2]P2[2]P3[2]P4[2]R24P4[1]P1[2]P2[2]P3[2]P4[2]R25P1[2]P2[2]P3[2]P4[2]R26P2[2]P3[2]P4[2]R27P3[2]P4[2]R28P4[2]MUX-MX62MX63MX64MX71MX72MX73MX74表1的从左上到右下的对角线是指令束IW的最大内容。表1的每列表示在表的最后一行MUX中指示的复用器MX62-MX64和MX71-MX74中的一个。表1的每列通过其非空框限定在对应的复用器MX62-MX64和MX71-MX74的输入处的寄存器R21-R28。根据实施例,被指定给处理单元的顺序根据其时间关键性来定义。例如,分支控制单元BCU可被视为在时间上是最关键的,因为它需要尽快知道要执行的指令和相关联的操作数,以便快速执行分支并从而最小化用于执行分支操作的必要时间。根据实施例,每个字节包括指定它应当由哪个处理单元处理的处理单元代码。图7示出了基本指令Pj的第一和第二级Pj[1]、Pj[2]的字节。字节Pj[1]包括指令字段IT0、处理单元代码字段PUC0和指示该字节是否是VLIW指令束的最后一个字节的字段EW。如果处理器具有被配置为执行相同操作的多个处理单元,则可以被设计为处理单元代码PUC0不区分处理单元以便减少代码长度。基本指令Pj的字节Pj[2]包括指令字段IT1、指示该字节是否是VLIW指令束的最后一个的字段EW、被设定为0的处理单元代码字段PUC0以及用于第二字节的处理单元代码字段PUC1。处理单元代码字段PUC0、PUC1可被用于控制复用器MX62-MX64和MX71-MX74。当然,在字节Pj[i]中可以提供其它字段。因此,图8表示级i的字节Pj[i]。字节Pj[i]包括指令字段IT、处理单元代码字段PUC、EW字段、以及指示字节(当基本指令包括多达两个字节时在一位上被编码的)的级i的字段RNG。所有基本指令从寄存器R21-R28到处理单元PU1-PU4的传送通过在一个寄存器中写入指令束的最后一个字节(存在指示该束的最后一个字节的EW字段)来触发。处理单元中字节的到达时间取决于复用器MX62-MX64、MW71-MX74的尺寸。因此,单元PU1-PU4可以首先按照PU1、PU2、PU3、PU4的顺序接收第一字节。由于复用器MX71和MX64具有相同数量的输入,它们可以同时接收存在于寄存器R21-R28中的指令束的字节。然后,处理单元PU2至PU4可以连续地接收字节。根据实施例,处理器包括一个或多个分支控制单元BCU、一个或多个算术和逻辑单元ALU、一个或多个加载和存储单元LSU、以及一个或多个固定或浮点乘法和累加单元MAU。图9示出了包括五个处理单元的示例性处理器PRC',即BCU、两个ALU(被称为ALU0和ALU1)、MAU和LSU。BCU仅处理单字节基本指令,而其它处理单元ALU0、ALU1、MAU和LSU可以处理具有一个或两个字节的基本指令。处理单元可以按照BCU、ALU、MAU和LSU的顺序排序。因此,指令束最多可以具有以下九个字节内容:BC[1]-A0[1]-A1[1]-MA[1]-LS[1]-A0[2]-A1[2]-MA[2]其中BC[1]、A0[1]、A1[1]、MA[1]和LS[1]是分别以单元BCU、ALU0、ALU1、MAU和LSU为目标的基本指令的第一级字节,A0[2]、A1[2]、MA[2]和LS[2]是分别以单元ALU0、ALU1、MAU和LSU为目标的第二级字节。图9示出了包括处理单元BCU、ALU0、ALU1、MAU和LSU以及输入电路INC'的处理器PRC'。输入电路INC'包括指令寄存器R31至R39、以及将输入寄存器连接到处理单元的复用器MX82-MX85和MX92-MX94。每个寄存器R31-R39接收指令束IW的基本指令的相应字节。图9因此示出了具有五个处理单元的处理器的情况,其能够处理具有一个或两个字节的五个基本指令的指令束IW。寄存器R31至R39的可能内容如下表2所示:表2R31BC[1]A0[1]A1[1]MA[1]LS[1]R32A0[1]A1[1]MA[1]LS[1]A0[2]A1[2]MA[2]LS[2]R33A1[1]MA[1]LS[1]]A0[2]A1[2]MA[2]LS[2]R34MA[1]LS[1]A0[2]A1[2]MA[2]LS[2]R35LS[1]]A0[2]A1[2]MA[2]LS[2]R36A0[2]A1[2]MA[2]LS[2]R37A1[2]MA[2]LS[2]R38MA[2]LS[2]R39LS[2]MUX-MX82MX83MX84MX85MX92MX93MX94MX95表2的每列由非空单元限定如在表的最后一行MUX中识别的复用器MX82-MX85和MX92-MX95中的一个的输入处的寄存器R31至R39。寄存器R31被直接连接到处理单元BCU的单个输入。复用器MX82通过其输入被连接到寄存器R31和R32,并且通过其输出被连接到处理单元ALU0的第一输入。复用器MX92通过其输入被连接到寄存器R32-R36,并且通过其输出被连接到处理单元ALU0的第二输入。复用器MX83通过其输入被连接到寄存器R31-R33,并且通过其输出被连接到处理单元ALU1的第一输入。复用器MX93通过其输入被连接到寄存器R32-R37,并且通过其输出被连接到处理单元ALU1的第二输入。复用器MX84通过其输入被连接到寄存器R31-R34,并且通过其输出被连接到处理单元MAU的第一输入。复用器MX94通过其输入被连接到寄存器R32-R38,并且通过其输出被连接到处理单元MAU的第二输入。复用器MX85通过其输入被连接到寄存器R31-R35,并且通过其输出被连接到处理单元LSU的第一输入。复用器MX95通过其输入被连接到寄存器R32-R39,并且通过其输出被连接到处理单元LSU的第二输入。复用器MX82-MX85和MX92-MX95共有40个入口(entry)。由于BCU单元的输入被直接连接到寄存器R31,因此可以首先开始分支指令的处理。由于它们所连接的复用器输入的数量,处理单元ALU0、ALU1、MAU和LSU然后可以连续地接收第一字节。ALU0单元可以接收第二字节,而LSU接收第一字节。然后,单元ALU1、MAU和LSU可以连续地接收第二字节。根据实施例,编译器生成最多具有八个字节的指令束IW。结果,可以省略寄存器R39,并且复用器MX95仅具有七个输入而不是八个。因此,输入电路INC'的复用器最多具有3个控制位。这种布置还减少了第二字节到LSU处理单元的传播时间。输入电路INC'的这种简化具有可忽略的副作用,因为编译器产生具有九个字节的指令束IW的概率低。因为处理器具有两个类似的处理单元ALU0、ALU1,所以PUC0字段不需要区分这两个处理单元,由此该字段对于四种类型的处理单元可以仅用2位编码。如果指令束包括用于ALU单元之一的基本指令,则它将被转发到单元ALU0。仅当指令束IW包括要由ALU处理的两个基本指令时,单元ALU1才将被激活。由于BCU单元不接收第二字节,所以只有四个处理单元ALU0、ALU1、MAU、LSU可能接收第二字节。PUC1字段因此也可以仅包括2位。在字节包含PUC和RNG字段的情况下,仅需要4位来编码处理单元号(3位用于5个处理单元)和字节的级(1位用于一个或两个字节的基本指令)。对本领域技术人员显而易见的是,本发明容许各种替代和应用。特别地,本发明不限于其中字节根据级分组并根据被指定给处理单元的级来排序的指令束。充分的是,从字节的第一级开始执行将字节传送到处理单元。将第一级的字节放置在指令束的开始处仅允许首先将位于输入寄存器中的第一级的字节传输到处理单元。此外,每个指令束的每个字节不必包括指示该字节是否是指令束中的最后一个的结束码。实际上,可以设计每个指令束包括例如指定指令束中的字节的数量的头部或尾部字段。指定要向其传输字节的处理单元和每个字节的级RNG的字段PUC0、PUC1,或每个字节要传输到的处理单元的输入号码,也可以插入到指令束的该头部或尾部字段中。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1