从句子生成高级别问题的制作方法
因特网是为全世界数十亿用户服务的全球数据通信系统。因特网向用户提供对大量在线信息资源和服务的访问,包括由万维网、基于内联网的企业等提供的在线信息资源和服务。万维网当前托管数十亿的网页,其共同托管了大量且不断增长的文本内容,文本内容涵盖用户可能感兴趣的任何主题。由于因特网、容易地并且成本高效地可获得的各种类型的网络启用的个人计算设备(诸如个人计算机、膝上型/笔记本计算机、智能电话、平板计算机和专用电子阅读器设备)、以及可以在这些设备上运行的各种类型的应用程序的普遍存在,跨全球的用户可以轻松地搜索、检索和阅读涵盖他们感兴趣的任何主题的任何类型的文本内容。
技术实现要素:
提供本发明内容以便以简化形式介绍将在以下具体实施方式中进一步描述的概念的选择。本发明内容不旨在标识所要求保护的主题的关键特征或必要特征,也不旨在用于帮助确定所要求保护的主题的范围。
本文中所描述的问题生成技术实现通常涉及生成关于文本的段落的问题,该文本的段落包括两个或更多个句子的序列。在一个示例性实现中,接收段落。然后生成关于段落的问题,其中问题涵盖段落中的多个句子的内容,并且包括段落的上下文部分以及与段落的上下文部分上下文相关的问题陈述。然后输出所生成的问题。下面提供这样的问题生成的示例。
附图说明
关于以下描述、所附权利要求和附图,将更好地理解本文中所描述的问题生成技术实现的具体的特征、方面和优点,在附图中:
图1是以简化形式示出用于生成关于文本的段落的问题的过程的一个实现的流程图。
图2是以简化形式示出用于生成关于文本的段落的问题的过程的一个实现的流程图,其中问题涵盖段落中的多个句子的内容,并且包括段落的上下文部分以及与该上下文部分上下文相关的问题陈述。
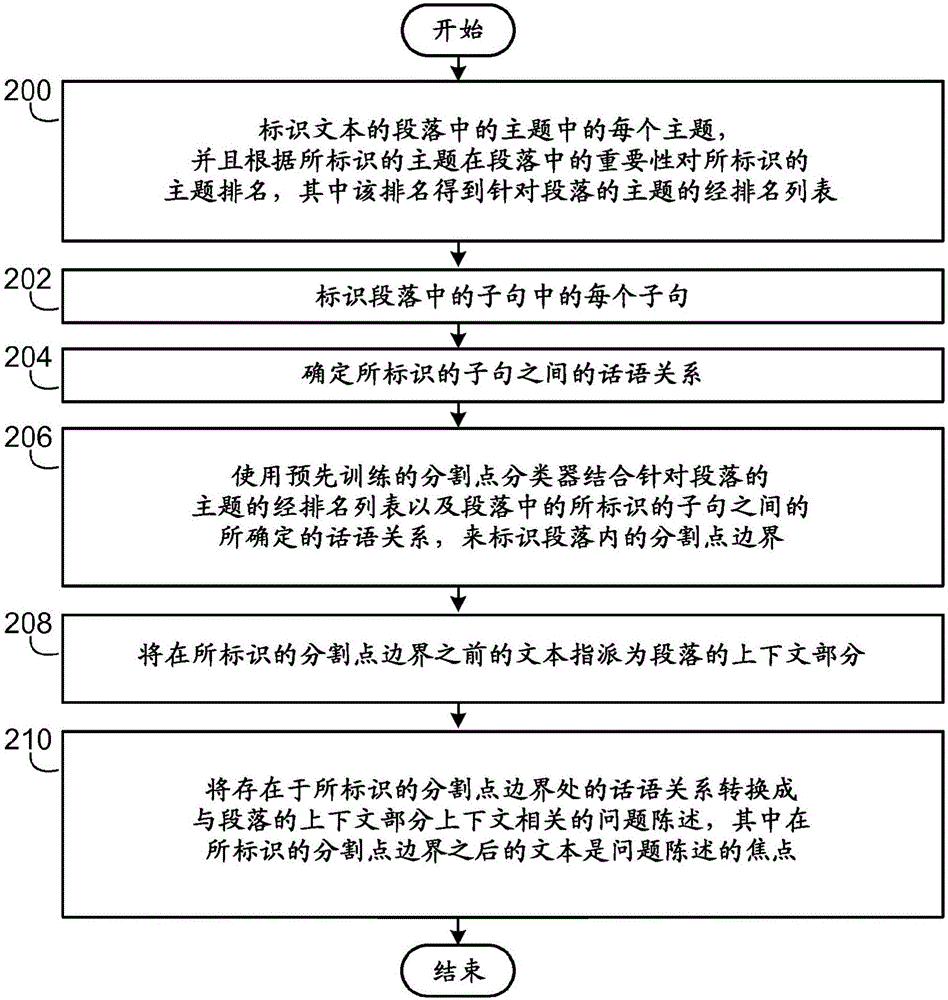
图3是以简化形式示出用于标识文本的段落中的主题中的每个主题,并且根据所标识的主题在段落中的重要性对所标识的主题排名的过程的一个实现的流程图。
图4是以简化形式示出用于标识文本的段落中的主题中的每个主题,并且根据所标识的主题在段落中的重要性对所标识的主题排名的过程的另一实现的流程图。
图5是以简化形式示出用于确定文本的段落中的所标识的子句之间的话语关系的过程的示例性实现的流程图。
图6是以简化形式示出用于将存在于文本的段落内的分割点边界处的话语关系转换成问题陈述的过程的示例性实现的流程图。
图7是以简化形式示出用于生成关于文本的段落的问题的过程的另一实现的流程图,其中问题涵盖段落中的多个句子的内容,并且包括段落的上下文部分以及与该上下文部分上下文相关的问题陈述。
图8是以简化形式示出用于生成关于文本的段落的问题的过程的另一实现的流程图,其中问题涵盖段落中的多个句子的内容,并且包括段落的上下文部分以及与该上下文部分上下文相关的问题陈述。
图9是以简化形式示出用于将存在于文本的段落内的所选择的话语标记处的话语关系转换成问题陈述的过程的示例性实现的流程图。
图10是以简化形式示出用于生成关于文本的段落的问题的过程的另一实现的流程图。
图11是以简化形式示出用于生成关于文本的段落的问题的过程的另一实现的流程图,其中问题涵盖段落中的多个句子的内容,并且包括段落的上下文部分以及与该上下文部分上下文相关的问题陈述。
图12是以简化形式示出用于使用预先训练的分割点分类器结合针对文本的段落的主题的经排名列表以及段落中的所标识的子句之间的所确定的话语关系,来标识段落内的分割点边界的过程的一个实现的流程图。
图13是以简化形式示出用于向用户提供关于他们正在阅读的文本的段落的问题的过程的示例性实现的流程图。
图14是以简化形式示出用于实现本文中所描述的问题生成技术实现的架构框架的示例性实现的图。
图15是示出可以实现本文中所描述的问题生成技术的各种实现和元素的通用计算机系统的简化示例的图。
具体实施方式
在问题生成技术实现的以下描述中,参考附图,附图形成以下描述的一部分,并且附图中通过说明示出了可以实践问题生成技术的具体实现。应当理解,在不脱离问题生成技术实现的范围的情况下,可以利用其他实现并且可以进行结构改变。
还应当注意,为了清楚起见,在描述本文中所描述的问题生成技术实现时将采用具体术语,并且并不旨在将这些实现限制于所选择的具体术语。此外,应当理解,每个具体术语包括以广义上相似的方式操作以实现相似目的的所有技术等同物。本文中对“一个实现”或“另一实现”或“示例性实现”或“替选实现”的引用表示结合该实现描述的特定特征、特定结构或特定特性可以被包括在问题生成技术的至少一个实现中。在说明书中的各个位置出现的短语“在一个实现中”、“在另一实现中”、“在示例性实现中”和“在替选实现中”不一定都指代相同的实现,也不一定是与其他实现相互排斥的单独的或替选的实现。此外,表示问题生成技术的一个或多个实现的处理流程的顺序不固有地指示任何特定顺序,也不暗示问题生成技术的任何限制。
1.0 Web上的文本内容
如上所述,存在在万维网(本文中有时简称为web)上当前可获得的大量并且不断增长的文本内容。跨全球的用户可以使用各种类型的网络启用的个人计算设备(除了其他以外,诸如在此之前描述的那些),来搜索、检索和读取涵盖他们感兴趣的任何主题的任何类型的文本内容。在给定用户读取给定文本的段落(例如,一段文本)之后,他们可能想要确定他们已经从段落中理解和记住了多少(例如,用户可能想要评估他们的阅读理解)。如在心理学领域中所理解的,存在被称为Dunning-Kruger效应的心理现象,由此读取给定文本的段落的用户通常会高估他们对该段落的认知/理解。从以下更详细的描述中可以理解,本文中所描述的问题生成技术实现的优点在于,它们可以用于各种各样的应用中,以自动地生成可以测量用户对文本的段落的理解的问题。例如,在用户正在专用电子阅读器设备上阅读给定电子书的情况下,问题生成技术实现可以用于自动地生成关于电子书的高级别问题,这些问题与电子书的不同部分上下文相关。在用户正在阅读网页上的文本的段落的情况下,问题生成技术实现可以用于自动地生成关于段落的高级别问题,这些问题与段落的不同部分上下文相关。下文中描述问题生成技术实现的附加优点。
如在因特网领域中所理解的,在web上可获得的很多文本内容本质上是教育性的。在网络上可获得的教育性文本内容的一部分是现有课程的一部分,并且被预先构造为使得阅读内容的用户(例如,学生)能够确定(例如,衡量)他们对内容的理解。这样的教育性文本内容的一个示例是教科书,其通常在每个章节的结尾处包括固定的预先创作的问题的集合,用户可以回答这些问题以便确定他们对内容的理解。在用户想要在稍后的日期重新确定他们对内容的理解的情况下,本文中所描述的问题生成技术实现可以用于自动地生成可以支持该重新确定的附加问题。在用户想要对他们对内容内的一个或多个具体主题的理解的更深入(例如,更集中的)评估的另一情况下,问题生成技术实现可以用于自动地生成关于这些具体主题的更多问题。在教师正在使用教科书教授课程的另一情况下,问题生成技术实现可以用于自动地生成要被包括在被给予学生的考试中的测试问题。虽然一些测试问题可能在教科书的教师版本中可获得,但是问题生成技术实现允许教师自动地生成年度不同的检查,并且自动地生成更深入地练习某些主题的更集中的测试问题。
网络上可获得的教育性文本内容的另一部分不是现有课程的一部分。例如,考虑第一次购房者正在阅读描述可获得的各种类型的贷款的文本内容的情况。在购房者完成他们的阅读之后,他们可能想知道他们在与他们的银行官员见面之前已经理解和记住了多少。还考虑另一种情况,其中患者被诊断为患有特定癌症,并且在获得URL(统一资源定位符,也称为“链接”)的集合之后,从他们的医生办公室被送回到家里,该URL的集合指向患者必须阅读以更多地了解关于他们的诊断和治疗选择的特定文本内容项目。在患者完成他们的阅读之后,他们可能想知道他们在与他们的医生再次见面之前已经理解和记住了多少。本文中所描述的问题生成技术实现可以用于自动地生成允许购房者和患者二者测量他们对他们阅读的文本内容的理解和记忆。问题生成技术实现还允许购房者和患者二者验证他们不仅仅具有对内容的粗略认知/理解,并且还允许他们随着时间推移刷新他们对内容的认知。
2.0 从句子生成高级别问题
给定包括两个或更多个句子的序列的文本的段落(本文中有时简称为段落),术语“句子级别问题”在本文中用于指代仅涵盖段落中的句子之一的内容的问题,使得该问题的答案仅被包含在该一个句子中(例如,问题的答案不能被包含在段落中的任何其他句子中)。相反,本文中使用术语“高级别问题”来指代涵盖段落中的多个句子的内容的问题,使得该问题的答案可以被包含在段落中的任何句子中,或者段落中的两个或更多个句子的组合中。因此,关于段落的高级别问题可以被认为是段落级别问题,因为高级别问题及其答案跨越段落中的多个句子。
给定包括两个或更多个句子的序列的文本的段落,本文中所描述的问题生成技术实现通常涉及自动地生成关于段落的高级别问题以及高级别问题中的每个高级别问题的答案。从下面更详细的描述中可以理解,不是单独地处理段落中的每个句子(例如,不是一次只处理段落中的一个句子,而不考虑段落中的其他句子),并且生成一个或多个句子级别问题,每个句子级别问题涵盖仅该一个句子的内容,问题生成技术实现将构成该段落的句子的整个序列作为一组来处理,并且可以生成高级别问题的集合,每个高级别问题涵盖段落中的多个句子的内容。因此,问题生成技术实现的优点在于,它们可以用于确定读者对段落中的更高级别内容的理解。问题生成技术实现还允许自动地生成高级别问题,这些高级别问题可以在上下文上探索段落的更深层面,诸如“为什么?”或“接下来发生了什么?”,而不是对段落中的单独的句子进行简单的语法修改,诸如“在哪里”或“何时”或“谁”。问题生成技术实现还确保自动地生成的高级别问题中的每个高级别问题在语法上是正确的。问题生成技术实现还确保高级别问题中的每个高级别问题的答案被包含在生成该高级别问题的文本的段落内。
如在自然语言理解和问题生成领域中所理解的,可以通过简单地在语法上修改句子来生成关于单个句子的句子级别问题。换言之,单个句子中的单词或单词短语可以被标识为期望答案,然后可以用适当的问题单词替换该标识的单词或单词短语,并且然后可以应用规则的集合来生成语法上正确的句子级别问题。例如,考虑原始句子“John married Jane in Seattle in 2012.”。可以通过将“in Seattle”替换为“where”来生成关于原始句子的一个句子级别问题,得到问题“Where did John marry Jane in 2012?”。可以通过将“in 2012”替换为“when”来生成关于原始句子的另一句子级别问题,得到问题“When did John marry Jane in Seattle?”。可以通过将“John”替换为“who”来生成关于原始句子的另一句子级别问题,得到问题“Who married Jane in Seattle in 2012?”。应当指出,这三个句子级别问题中的每个的答案都被包含在原始句子本身中。但是,如果原始句子在语法上被变换成问题“Why did John marry Jane?”或者问题“What happened after John married Jane?”,则这两个问题的答案显然不被包含在原始句子本身中。
2.1 高级别问题生成示例
这一部分呈现用于进一步描述本文中所描述的问题生成技术实现的样本文本的段落。这一部分还呈现了可以使用本文中所描述的问题生成技术实现自动地生成用于样本文本的段落的示例性的高级别问题的集合。样本文本的段落如下所示,并且包括三个句子的序列,即句子S1、紧接在句子S1之后的句子S2和紧接在句子S2之后的句子S3:
S1:Franklin saw the printing press as a device to instruct colonial Americans in moral virtue.
S2:He tried to influence American moral life through construction of a printing network based on a chain of partnerships from the Carolinas to New England.
S3:Franklin thereby invented the first newspaper chain.
上述文本的段落在下文中简称为段落S1-S3。
在接收并且处理段落S1-S3(下文将更详细地描述)之后,本文中所描述的生成技术的示例性实现可以针对段落S1-S3生成两个不同的高级别问题陈述和答案对,即高级别问题陈述和答案对Q1/A1和高级别问题陈述和答案对Q2/A2,如下所示:
Q1:What resulted from Franklin’s views on the role of the printing press?
A1:Because Franklin wanted to use printing press as a device to instruct colonial Americans in moral virtue,he constructed a chain of newspapers from the Carolinas to New England.
Q2:What precipitated Franklin’s invention of the first newspaper chain?
A2:Franklin invented the first newspaper chain because he tried to influence American moral life through the printing press and so constructed a printing network from the Carolinas to New England.
注意,高级别问题陈述Q1主要从句子S1来生成,但是Q1的答案A1被包含在句子S2和句子S3二者内。类似地,高级别问题陈述Q2主要从句子S3来生成,但是Q2的答案A2被包含在段落S1-S3中在句子S3之前的句子S1和句子S2二者内。
还应当注意,高级别问题陈述Q1的形式将单个句子S1的内容与Q1和其答案A1之间的期望关系(其在Q1的情况下是“结果”)组合。类似地,高级别问题陈述Q2的形式将单个句子S3的内容与Q2和其答案A2之间的期望关系(其在Q2的情况下是“在前”)组合。然而,从以下更详细的描述中将理解,本文中所描述的问题生成技术实现还可以生成关于段落S1-S3的高级别问题,该高级别问题针对问题与其答案之间的关系,但是使用段落S1-S3中的句子的内容来将问题置于上下文中。换言之,问题生成技术实现可以通过以下方式来生成关于段落S1-S3的高级别问题:首先标识段落S1-S3的部分以用作针对问题的上下文(下文中简称为段落的上下文部分),并且然后通过用问题陈述来扩充段落的上下文部分,来将段落的上下文部分变换成问题,该问题陈述包括特定于问题及其答案之间的期望关系的少量文本(例如,“为什么?”或“这是怎么发生的?”)。因此,段落的上下文部分用于将关于段落S1-S3的问题置于上下文中。
关于段落S1-S3的高级别问题(其针对问题与其答案之间的关系,但是使用段落S1-S3中的句子的内容来将问题置于上下文中)的一个示例如下:
S1:Franklin saw the printing press as a device to instruct colonial Americans in moral virtue.
Q3:What resulted?
注意,在上述示例中,句子S1是用于将高级别问题陈述Q3置于上下文中的段落S1-S3的上下文部分,得到Q3是由相对简单的文本组成的复杂问题陈述。
关于段落S1-S3的高级别问题(其针对问题与其答案之间的关系,但是使用段落S1-S3中的句子的内容来将问题置于上下文中)的另一示例如下:
S3:Franklin thereby invented the first newspaper chain.
Q4:What precipitated this?
注意,在上述示例中,句子S3是用于将高级别问题陈述Q4置于上下文中的段落S1-S3的上下文部分,得到Q4也是由相对简单的文本组成的复杂问题。
2.2 过程框架
图1以简化形式示出了用于生成关于文本的段落的问题的过程的一个实现,该文本的段落包括两个或更多个句子的序列。如图1中例示的,该过程开始于接收段落(动作100)。然后生成关于段落的问题,其中问题涵盖段落中的多个句子的内容,并且问题包括段落的上下文部分以及与段落的上下文部分上下文相关的问题陈述(动作102)。换言之,段落的上下文部分用作针对关于段落的问题的上下文。然后输出问题(动作104)。在本文中所描述的问题生成技术的示例性实现中,段落还包括一个或多个主题、多个子句以及一个或多个名词短语。段落也由单词n元语法的序列组成。术语“单词n元语法”在本文中用于指代给定文本的段落中的n个单词的序列。
图2以简化形式示出了用于生成关于文本的段落的问题的过程的一个实现。如图2中例示的,该过程开始于标识段落中的主题中的每个主题,并且根据所标识的主题在段落中的重要性对所标识的主题排名,其中该排名得到针对段落的主题的经排名列表(动作200);该主题标识和排名动作在下文中更详细地描述。然后标识段落中的子句中的每个子句(动作202)。一般来说,并且如在自然语言处理领域中所理解的,子句是完整想法的单元,并且可以作为语法句子独立存在。换言之,子句包括动词和主语,并且可以可选地包括其他论元(argument)和修饰语,诸如宾语、补语和/或状语。在本文中所描述的问题生成技术的示例性实现中,通过在句法上分析段落来标识段落中的子句中的每个子句,其中所标识的子句中的每个子句可以可选地被标记为主要子句或从属子句,从属子句取决于特定主要子句,并且可能对于段落的内容不太重要。注意,问题生成技术的替选实现也是可能的,其中可以使用各种其他方法来标识段落中的子句中的每个子句。
再次参考图2,在已经标识了文本的段落中的子句中的每个子句(动作202)之后,确定所标识的子句之间的话语关系(动作204);该话语关系确定动作在下文中更详细地描述。一般来说,并且如在自然语言处理领域中所理解的,话语关系(也被称为修辞关系)是对两个不同的文本的片段(例如,两个不同的子句)如何在逻辑上彼此连接的描述。在确定所标识的子句之间的话语关系(动作204)之后,然后使用预先训练的分割点分类器结合针对段落的主题的经排名列表以及段落中的所标识的子句之间的所确定的话语关系,来标识段落内的分割点边界(动作206);该分割点边界标识动作也在下文中更详细地描述。然后将在所标识的分割点边界之前的文本指派为上述段落的上下文部分(动作208)。然后将存在于所标识的分割点边界处的话语关系转换成问题陈述(动作210),其中在所标识的分割点边界之后的文本是问题陈述的焦点;该分割点边界话语关系转换动作也在下文中更详细地描述。下面还更详细地描述用于训练分割点分类器的示例性方法。
标识文本的段落中的主题中的每个主题,并且根据所标识的主题在段落中的重要性对所标识的主题排名的上述动作(图2中的动作200)可以以各种方式实现。在下文中更详细地描述用于标识文本的段落中的主题中的每个主题,并且对所标识的主题排名的示例性方法。注意,除了这些示例性方法之外,用于标识段落中的主题中的每个主题,并且对所标识的主题排名的各种其他方法也是可能的。
使用预先训练的分割点分类器结合针对文本的段落的主题的经排名列表以及段落中的所标识的子句之间的所确定的话语关系,来标识段落内的分割点边界的上述动作(图2中的动作206)也可以以各种方式实现。用于执行该分割点边界标识的示例性方法在下文中更详细地描述。注意,除了这些示例性方法之外,用于执行该分割点边界标识的各种其它方法也是可能的。
图12以简化形式示出了用于使用预先训练的分割点分类器结合针对文本的段落的主题的经排名列表以及段落中所标识的子句之间的所确定的话语关系,来标识段落内的分割点边界的过程的一个实现。如图12中例示的,该过程开始于使用分割点分类器结合针对段落的主题的经排名列表以及段落中的所标识的子句之间的所确定的话语关系,来标识段落内的候选分割点边界的集合(动作1200)。然后使用分割点分类器对候选分割点边界中的每个候选分割点边界评分(动作1202)。然后选择具有最高得分的候选分割点边界(动作1204)。然后将所选择的候选分割点边界指派为所标识的分割点边界(动作1206)。
图12中例示的过程的以下替选实现(未示出)也是可能的。不是如本文中所描述的选择具有最高得分的候选分割点边界(动作1204),并且然后使用该所选择的分割点边界来生成关于文本的段落的问题,而是可以选择具有高于规定得分阈值的得分的任何候选分割点边界。然后,可以使用这些所选择的候选分割点边界中的每个候选分割点边界用于生成关于段落的不同问题。
图3以简化形式示出了用于标识文本的段落中的主题中的每个主题,并且根据所标识的主题在段落中的重要性对所标识的主题排名的过程的一个实现。如图3中例示的,该过程开始于标识段落中的名词短语中的每个名词短语(动作300)。应当理解,可以使用各种不同的方法来执行该名词短语标识。作为示例而非限制,在本文中所描述的问题生成技术的示例性实现中,使用常规的成分(constituency)解析器来标识段落中的名词短语中的每个名词短语。然后计算段落中的回指和所标识的名词短语的共指(动作302)。该共指计算可以使用各种不同的方法来执行。作为示例而非限制,在问题生成技术的示例性实现中,使用用于解析代词引用的传统的Hobbs方法来计算段落中的回指和所标识的名词短语的共指。对上述段落S1-S3执行动作300和302的示例性结果如下所示,其中所标识的主题被加下划线:
S1:Franklin saw the printing press as a device to instruct colonialAmericans in moral virtue.
S2:He(=Franklin)tried to influence American moral life through construction of a printing network based on a chain of partnerships from the Carolinas to New England.
S3:Franklin thereby invented the first newspaper chain.
通过经由它们的中心名词(通常是每个名词短语的最后一个单词)对上述标识的主题分组,显而易见的是,在段落S1-S3中,主题“Franklin”出现三次,主题“chain”出现两次,并且所有其他标识的主题仅出现一次。这反映了我们作为人类读者的直觉——段落S1-S3的主旨是“Franklin”与“(newspaper)chain”之间的联系。
再次参考图3,在已经标识了文本的段落中的主题中的每个主题之后(动作300和302),然后如下对所标识的主题排名。针对所标识的名词短语中的每个名词短语,确定所标识的名词短语在所标识的名词短语出现在其中的段落的一个或多个句法单元中的句法角色(例如,所标识的名词短语所扮演的句法角色)(动作304)。然后确定所标识的名词短语中的每个名词短语和指代该名词短语的回指在该段落中的出现频率(动作306)。然后使用所标识的名词短语中的每个名词短语的句法角色以及所标识的名词短语中的每个名词短语和指代该名词短语的回指的出现频率对所标识的名词短语排名(动作308)。
再次参考图3,应当理解,刚才描述的用于对所标识的主题排名的过程(动作304、306和308)使用来自“中心理论(Centering Theory)”的领域的某些见解。更具体地,中心理论认为,与和谓语/动词不直接相关的主题相比,文本的段落中作为段落中的动词(或者主动词或者从属动词)的论元的主题通常对于段落的意义更重要。因此,在段落S1-S3中,“Franklin”有三次作为主语,“printing press”有一次作为宾语,“newspaper chain”有一次作为宾语,“American moral life”有一次作为宾语,并且“colonial Americans”有一次是从属子句中的动词的宾语。通过区分在论元角色中出现的主题与在论元角色中没有出现的主题,动作304、306和308的主题排名过程能够对否则在段落中出现相等次数的所标识的主题排名。动作304、306和308的主题排名过程因此将“printing press”和“American moral life”排在“partnerships”和“New England”之上。动作304、306和308的主题排名过程将基于具有较高凸显性的主题生成更好的问题这一假定,根据所标识的主题在段落中的凸显性来对所标识的主题排名。段落S1-S3中处于主语或宾语位置的所标识的主题在下面被粗体显示:
S1:Franklin saw the printing press as a device to instruct colonial Americans in moral virtue.
S2:He(=Franklin)tried to influence American moral life through construction of a printing network based on a chain of partnerships from the Carolinas to New England.
S3:Franklin thereby invented the first newspaper chain.
图4以简化形式示出了用于标识文本的段落中的主题中的每个主题,并且根据所标识的主题在段落中的重要性对所标识的主题排名的过程的另一实现。如图4中例示的,该过程开始于标识文本的段落中的单词n元语法中的每个单词n元语法(动作400)。然后确定所标识的单词n元语法中的每个单词n元语法的出现频率(动作402)。然后,对于所标识的单词n元语法中的每个单词n元语法,调节所标识的单词n元语法的出现频率以考虑其长度(动作404)。然后根据所标识的单词n元语法的经调节的出现频率,对所标识的单词n元语法排名(动作406)。
可以用各种方式实现确定所标识的子句之间的话语关系的上述动作(图2中的动作204)。下文中更详细地描述用于确定所标识的子句之间的话语关系的示例性方法。注意,除了该示例性方法之外,用于确定所标识的子句之间的话语关系的各种其他方法也是可能的。
图5以简化形式示出了用于确定所标识的子句之间的话语关系的过程的示例性实现。如图5中例示的,该过程涉及使用预先学习的话语关系预测模型,来标识文本的段落中彼此相邻的每对所标识的子句之间的最可能的话语关系(动作500)。在本文中所描述的问题生成技术的示例性实现中,该预测模型包括如下操作的预先配置的(例如,预先学习的)关系模板(例如,关系查找表)和预先训练的关系类型分类器。每当段落中彼此相邻的一对所标识的子句被明确地连接时,使用关系模板来标识该对之间的话语关系(动作502)。每当段落中彼此相邻的一对所标识的子句没有被明确地连接时,使用关系类型分类器来标识该对之间的话语关系(动作504)。
对段落S1-S3执行刚才描述的用于确定所标识的子句之间的话语关系的过程的示例性结果如下所示,其中在段落S1-S3中彼此相邻的每对子句之间标识的话语关系被大写:
S1:Franklin saw the printing press as a device PURPOSE to instruct colonial Americans in moral virtue.CONSEQUENCE
S2:He tried to influence American moral life MANNER through construction of a printing network based on a chain of partnerships from the Carolinas to New England.RESULT
S3:Franklin thereby invented the first newspaper chain.
在上述结果中,相邻的句子S2和S3通过单词“thereby”被明确地连接,“thereby”表示由关系模板标识的RESULT话语关系。相邻的句子S1和S2没有被明确地连接,因此关系类型分类器用于标识CONSEQUENCE话语关系。
在本文中所描述的问题生成技术的示例性实现中,从话语关系的固定集合和大量文本中学习话语关系预测模型,该大量文本已经用来自该固定集合(例如,宾州话语树库(Penn Discourse Treebank))的话语关系被注释。话语关系的固定集合包括规定数目的不同话语关系,并且除了其他以外,包括诸如原因、结果、规范、后果、概括、时间之前、时间之后、目的、方式和条件等话语关系。应当理解,该规定数目可以从相对小的数目(例如25)到相对大的数目(例如,超过100)。更具体地,使用该被注释的大量文本来配置关系模板。也使用该被注释的大量文本来训练关系类型分类器。关系类型分类器的模型由各种特征组成,诸如句子的句法结构、句子连接词、时态、句子顺序、词性、词汇表示(例如,词簇)和其它相关特征。
在本文中所描述的问题生成技术的示例性实现中,用下面的方式来训练上述预先训练的分割点分类器。给定包括不同文本的段落的训练语料库,如上所述生成针对训练语料库中的段落中的每个段落的主题的经排名列表;也如上所述确定训练语料库中的段落中的每个段落中的话语关系。然后,要求一组个人(可以被认为是判断者)手动检查训练语料库中的段落中的每个段落,并且使用针对段落的主题的经排名列表以及被确定为在段落中的话语关系,来标识段落内的分割点边界,其中在所标识的分割点边界之前的文本是所提出的问题上下文,并且在所标识的分割点边界之后的文本是与所提出的问题上下文相关联的问题焦点。然后注释训练语料库以标识由该组个人标识的分割点边界中的每个分割点边界。然后使用该注释的训练语料库来训练分割点分类器。分割点分类器的模型由广泛的特征组成,除了其他以外,包括但不限于与关系类型分类器相关联的上述特征、以及文本的段落的各种上下文特征,诸如高排名主题在所提出的问题上下文中的第一次出现、高排名主题在与所提出的问题上下文相关联的问题焦点中的第一次出现、高排名主题在所提出的问题上下文中的存在、高排名主题在与所提出的问题上下文相关联的问题焦点中的存在、给定文本的段落中的句子的顺序、段落中的句子中的每个句子的长度、所提出的问题上下文的词性、以及与所提出的问题上下文相关联的问题焦点的词性。
图6以简化形式示出了用于将存在于所标识的分割点边界处的话语关系转换成与文本的段落的上下文部分上下文相关的上述问题陈述的过程的示例性实现。如图6中例示的,该过程开始于使用所标识的子句之间的所确定的话语关系,来计算存在于所标识的分割点边界处的话语关系(动作600)。然后选择与所计算的话语关系相对应的问题碎片(动作602)。从本文中所提供的各种问题生成技术实现的描述将理解的,给定的问题碎片可以是与给定的话语关系相对应的单个单词、或者与话语关系相对应的两个或更多个单词的短语。除了其他以外,可以选择的示例性问题碎片包括“为什么?”、“如何?”、“在哪里?”、“接下来是什么?”、“这之后接下来是什么?”、“结果是什么?”、“这样的结果是什么?”。因此,问题碎片可以被认为是与给定的话语关系相对应的短的问题的规定的规范形式。
再次参考图6,在已经选择了与存在于所标识的分割点边界处的话语关系相对应的问题碎片(动作602)之后,将所选择的问题碎片随后指派为问题陈述(动作604)。然后,使用在所标识的分割点边界之后的文本来建立问题的答案(如本文中所描述的其包括文本的段落的上下文部分和问题陈述)(动作606)。然后可以可选地通过从问题的答案中省略(例如,从答案范围中移除)不依赖于存在于所标识的分割点边界处的话语关系,并且不包括段落的上下文部分中的任何主题的任何文本片段,来提炼问题的答案(动作608),以得到仅包括依赖于存在于所标识的分割点边界处的话语关系,并且包括段落的上下文部分中的主题中的一个或多个主题的文本片段的经提炼的答案。不依赖于存在于所标识的分割点边界处的话语关系,并且不包括段落的上下文部分中的任何主题的这样的文本片段的一个示例是当文本片段出现在所标识的分割点边界之后时,其与在所标识的分割点边界之前的文本无关的新想法相关联。
可以使用各种不同的方法来执行刚才描述的问题碎片选择。作为示例而非限制,在本文中所描述的问题生成技术的一个实现中,可以使用预先配置的(例如,预先学习的)问题模板(例如,问题查找表)来选择与存在于所标识的分割点边界处的话语关系相对应的问题碎片,预先配置的问题模板将每个可能的话语关系映射到与其对应的特定问题碎片。换言之,该问题模板指定与每个可能的话语关系相对应的所规定的公式化问题碎片。在问题生成技术的另一实现中,可以使用考虑文本的段落的上下文特征的预先训练的问题类型分类器,来选择与存在于所标识的分割点边界处的话语关系相对应的问题碎片。在多个不同的问题碎片可以对应于给定的话语关系的情况下,问题类型分类器是有用的。更具体地,在这种情况下,问题类型分类器可以使用段落的上下文特征,来选择这些不同问题碎片中最佳地表示存在于所标识的分割点边界处的话语关系的一个问题碎片。
在本文中所描述的问题生成技术的另一实现中,不是如刚才描述的使用存在于所标识的分割点边界处的话语关系来选择问题碎片,问题类型分类器可以分析文本的段落的上下文特征,并且从该分析来预测与在所标识的分割点边界之前和之后的文本最佳匹配的问题碎片。
对段落S1-S3执行图6所示的动作的示例性结果如下示出:
高级别问题1:
S1:Franklin saw the printing press as a device to instruct colonial Americans in moral virtue.
Q5:What followed from this?
高级别问题1的答案:
S2:He tried to influence American moral life through construction of a printing network based on a chain of partnerships from the Carolinas to New England.
S3:Franklin thereby invented the first newspaper chain.
在上述结果中,假定段落S1-S3内的分割点边界被标识为在句子S1的结尾与句子S2的开始之间。因此,所生成的被置于上下文中的问题陈述Q5与存在于该分割点边界处的上述CONSEQUENCE话语关系相对应。
2.3 仅使用子句之间的话语关系的替选实现
图7以简化形式示出了用于生成关于文本的段落的问题的过程的另一实现。如图7中例示的,该过程开始于标识段落中的子句中的每个子句(动作700),如上所述。然后确定所标识的子句之间的话语关系(动作702),如上所述。然后,使用上述预先训练的分割点分类器结合段落中的所标识的子句之间的所确定的话语关系,来标识段落内的分割点边界(动作704)。然后将在所标识的分割点边界之前的文本指派为段落的上下文部分(动作706)。然后将存在于所标识的分割点边界处的话语关系转换成与段落的上下文部分上下文相关的上述问题陈述(动作708),如上所述,其中在所标识的分割点边界之后的文本是问题陈述的焦点。
应当理解,对段落S1-S3执行刚才描述的用于生成关于文本的段落的问题的过程还可以产生由句子S1和问题陈述Q5组成的上述高级别问题1。
2.4 使用主题和显式话语标记的替选实现
图8以简化形式示出了用于生成关于文本的段落的问题的过程的另一实现。如从以下更详细的描述将理解的,每当段落包括一个或多个显式话语标记时,可以使用该特定实现。一般来说并且如在自然语言处理领域中所理解的,话语标记(有时也被称为语用标记、或链接词/短语、或句子连接符)是单词或单词短语,其在大多数情况下句法上独立,使得从给定的句子中移除给定的话语标记仍然使得句子结构完整。话语标记通常用于定向或重定向段落中的“会话”流,而不对该段落增加任何显著的可解释的含义。换言之,话语标记具有某种“空的含义”,并且经常被用作段落中的填充词或虚词。因此,话语标记通常来自单词类,诸如副词或介词短语。
图8中例示的过程开始于标识文本的段落中的主题中的每个主题,并且根据所标识的主题在段落中的重要性对所标识的主题排名,其中该排名得到针对段落的主题的经排名列表(动作800);该主题标识和排名动作如上所述地实现。然后标识段落中的话语标记中的每个话语标记(动作802)。在本文中所描述的问题生成技术的示例性实现中,使用规定的话语标记列表来标识段落中的话语标记中的每个话语标记,规定的话语标记列表包括已知用作话语标记的有限集合的单词和单词短语。所标识的话语标记中的每个话语标记可以可选地被标记为出现在主要子句或者从属子句中,从属子句依赖于特定主要子句并且对于段落的内容可能不太重要。然后选择结合主题的经排名列表中具有最高排名的主题出现的所标识的话语标记(动作804)。然后将在所选择的话语标记之前的文本指派为段落的上下文部分(动作806)。然后将存在于所选择的话语标记处的话语关系转换成与段落的上下文部分上下文相关的上述问题陈述,其中在所选择的话语标记之后的文本是问题陈述的焦点(动作808)。
图9以简化形式示出了用于将存在于所选择的话语标记处的话语关系转换成问题陈述的过程的示例性实现。如图9中例示的,该过程开始于选择与存在于所选择的话语标记处的话语关系相对应的问题碎片(动作900)。然后将所选择的问题碎片指派为问题陈述(动作902)。然后,使用在所选择的话语标记之后的文本来建立问题的答案(如本文中所描述的其包括文本的段落的上下文部分和问题陈述)(动作904)。然后可以可选地通过从问题的答案中省略不依赖于存在于所选择的话语标记处的话语关系,并且不包括段落的上下文部分中的任何主题的任何文本片段,来提炼问题的答案(动作906),以得到仅包括依赖于存在于所选择的话语标记处的话语关系,并且包括段落的上下文部分中的主题中的一个或多个主题的文本片段的经提炼的答案。
可以使用各种不同的方法来执行刚才描述的问题碎片选择。作为示例而非限制,在本文中所描述的问题生成技术的一个实现中,可以使用上述预先配置的问题模板来选择与存在于所选择的话语标记处的话语关系相对应的问题碎片。在问题生成技术的另一实现中,可以使用上述预先训练的问题类型分类器来选择与存在于所选择的话语标记处的话语关系相对应的问题碎片。
对段落S1-S3执行刚才描述的用于生成关于文本的段落的问题的过程的示例性结果如下所示:
高级别问题2:
S1:Franklin saw the printing press as a device to instruct colonial Americans in moral virtue.
S2:He tried to influence American moral life
Q6:How did he do this?
高级别问题2的答案:
S2:through construction of a printing network based on a chain of partnerships from the Carolinas to New England.
S3:Franklin thereby invented the first newspaper chain.
在上述结果中,假定“Franklin”是段落S1-S3中排名最高的(例如,最重要的)主题。还假定“through construction”是段落S1-S3中与“Franklin”结合出现的显式话语标记。
2.5 仅使用显式话语标记的替选实现
图10以简化形式示出了用于生成关于文本的段落的问题的过程的另一实现,该文本的段落包括两个或更多个句子的序列,其中段落还包括一个或多个显式话语标记。如从以下更详细的描述可以理解的,该特定实现不依赖于标识段落中的主题,并且也不依赖于标识段落中的子句。相反,该特定实现仅仅从存在于段落中的显式话语标记来生成关于段落的问题。
图10中例示的过程开始于接收文本的段落(动作1000)。然后标识段落中的第一话语标记(动作1002)。在本文中所描述的问题生成技术的示例性实现中,使用上述规定的话语标记列表来标识段落中的第一话语标记。然后将在所标识的第一话语标记之前的文本指派为段落的上下文部分(动作1004)。然后生成关于段落的问题,其中问题涵盖段落中的多个句子的内容,问题包括段落的上下文部分以及与段落的上下文部分上下文相关的问题陈述,并且在所标识的第一话语标记之后的文本是问题陈述的焦点(动作1006)。然后输出问题(动作1008)。
图11以简化形式示出了刚才描述的用于生成关于文本的段落的问题的动作(图10中的动作1006)的过程的示例性实现。如图11中例示的,该过程开始于选择与存在于所标识的第一话语标记处的话语关系相对应的问题碎片(动作1100)。然后将所选择的问题碎片指派为与段落的上下文部分上下文相关的上述问题陈述(动作1102)。然后,使用在所标识的第一话语标记之后的文本来建立问题的答案(如本文中所描述的其包括段落的上下文部分和问题陈述)(动作1104)。然后可以可选地通过从问题的答案中省略不依赖于存在于所标识的第一话语标记处的话语关系,并且不包括段落的上下文部分中的任何主题的任何文本片段,来提炼问题的答案(动作1106),以得到仅包括依赖于存在于所标识的第一话语标记处的话语关系,并且包括段落的上下文部分中的主题中的一个或多个主题的文本片段的经提炼的答案。
可以使用各种不同的方法来执行刚才描述的问题碎片选择。作为示例而非限制,在本文中所描述的问题生成技术的一个实现中,可以使用上述预先配置的问题模板来选择与存在于所标识的第一话语标记处的话语关系相对应的问题碎片。在问题生成技术的另一实现中,可以使用上述预先训练的问题类型分类器来选择与存在于所标识的第一话语标记处的话语关系相对应的问题碎片。
对段落S1-S3执行刚才描述的用于生成关于文本的段落的问题的过程的示例性结果如下所示:
高级别问题:
S1:Franklin saw the printing press as a device to instruct colonial Americans in moral virtue.
S2:He tried to influence American moral life through construction of a printing network based on a chain of partnerships from the Carolinas to New England.
Q7:What did this result in?
高级别问题的答案:
S3:Franklin thereby invented the first newspaper chain.
在上述结果中,假定“thereby”是段落S1-S3中的第一话语标记。因此,所生成的被置于上下文中的问题陈述Q7与存在于话语标记“thereby”处的上述RESULT话语关系相对应。
2.6 用户界面
图13以简化形式示出了用于向用户提供关于他们正在阅读的文本的段落的问题的过程的示例性实现,其中段落包括两个或更多个句子的序列。如图13中例示的,该过程开始于接收关于段落的问题,其中问题涵盖段落中的多个句子的内容,并且问题包括段落的上下文部分以及与段落的上下文部分上下文相关的问题陈述(动作1300)。然后将问题呈现给用户(动作1302),其中该问题呈现包括显示上述段落的上下文部分(动作1304)并且显示问题陈述(动作1306)。然后接收问题的答案,其中该答案驻留在位于段落的上下文部分外部的段落的部分中的单个句子内,或者驻留在位于段落的上下文部分外部的段落的部分中的多个句子内(动作1308)。每当用户不正确地回答问题(动作1310,否)时,向用户呈现问题的答案(动作1312)。该答案呈现(动作1312)包括显示位于段落的上下文部分外部的段落的部分(动作1314)。答案呈现(动作1312)还可以可选地包括突出显示段落的所显示的上下文部分的部位以及位于段落的上下文部分外部的段落的所显示的部分的、与问题的答案相关的部位(动作1316)。
再次参考图13,应当注意,刚才描述的答案呈现动作1312、1314和1316的优点在于,其实现了用户能够在其中检查他们的工作的自分级上下文。还应当注意,动作1314和1316的组合的优点在于,其允许用户结合查看问题与其上下文相关的段落的部分(例如,段落的问题区域)来查看在其中寻到问题的答案的段落的部分(例如,段落的答案区域)。
2.7 架构框架
图14以简化形式示出了用于实现本文中所描述的问题生成技术实现的架构框架的示例性实现。如图14中例示的,架构框架1400包括在用于生成关于文本的段落1404的问题的上述过程中采用的问题生成模块1406。更具体地,问题生成模块1406接收段落1404并且生成关于段落的问题1422,问题1422涵盖段落中的多个句子的内容,并且包括段落的上下文部分以及与该上下文部分上下文相关的问题陈述。问题生成模块1406包括主题标识和排名模块1408、子句标识模块1410、话语标记标识模块1412、话语关系确定模块1414、分割点边界标识模块1416、问题陈述创建模块1418和答案确定模块1420。
再次参考图14,主题标识和排名模块1408标识文本的段落1404中的主题中的每个主题,并且根据所标识的主题在段落1404中的重要性对所标识的主题排名,其中该排名得到针对段落的主题的经排名列表。子句标识模块1410标识段落1404中的子句中的每个子句。话语关系确定模块1414使用上述预先学习的话语关系预测模型1432来确定所标识的子句之间的话语关系,其中话语关系预测模型1432包括预先配置的关系模板1434和预先训练的关系类型分类器1436,如上所述。分割点边界标识模块1416使用上述预先训练的分割点分类器1426结合主题的经排名列表和所标识的子句之间的所确定的话语关系,来标识段落1404内的分割点边界。问题陈述创建模块1418使用上述预先配置的问题模板1428或上述预先训练的问题类型分类器1430,来将存在于所标识的分割点边界处的话语关系转换成与段落1404的上下文部分上下文相关的问题陈述。答案确定模块1420使用在所标识的分割点边界之后的文本来建立问题的答案1424,并且如上所述可选地提炼该答案。
再次参考图14,在文本的段落1404包括一个或多个显式话语标记的情况下,话语标记标识模块1412可以标识段落1404中的话语标记中的每个话语标记,并且然后选择所标识的话语标记中结合段落中排名最高的主题出现的一个话语标记。问题陈述创建模块1418然后可以使用预先配置的问题模板1428或预先训练的问题类型分类器1430将存在于所选择的话语标记处的话语关系转换成与段落1404的上下文部分上下文相关的问题陈述。答案确定模块1420然后可以使用在所选择的话语标记之后的文本来建立问题的答案1424,并且如上所述可选地提炼该答案。
再次参考图14,在文本的段落1404包括一个或多个显式话语标记的情况下,话语标记标识模块1412还可以标识段落1404中的第一话语标记。问题陈述创建模块1418然后可以使用预先配置的问题模板1428或预先训练的问题类型分类器1430,来将存在于所标识的第一话语标记处的话语关系转换成与段落1404的上下文部分上下文相关的问题陈述。然后,答案确定模块1420可以使用在所标识的第一话语标记之后的文本来建立问题的答案1424,并且如上所述可选地提炼该答案。
再次参考图14,架构框架1400还包括问题呈现模块1438,其在上述过程中被采用用于向用户1402提供关于他们正在阅读的文本的段落1404的问题。更具体地,问题呈现模块1438接收关于段落1404的问题1422,问题1422涵盖段落中的多个句子的内容,并且包括段落的上下文部分以及与该上下文部分上下文相关的问题陈述。问题呈现模块1438还接收问题的答案1424。然后,问题呈现模块1438向用户1402呈现关于段落1404的问题1422,如上所述。每当用户1402不正确地回答问题1422时,问题呈现模块1438然后向用户呈现问题的答案1424,如上所述。
3.0 另外的实现
虽然已经通过具体参考问题生成技术的实现描述了问题生成技术,但是应当理解,在不脱离问题生成技术的真实精神和范围的情况下,可以对其做出变化和修改。例如,本文中所描述的问题生成技术实现可以以问题生成系统的形式实现,该问题生成系统可以由教师和其他类型的教育者使用,以从教科书或者用于教授给定课程的任何其他类型的教育性文本内容,自动地生成测试问题的集合。另外,问题生成技术的替选实现是可能的,其中正在阅读给定文本的段落的用户可以指定他们感兴趣的特定类型的话语关系(例如,用户可以指定他们想要仅被呈现CONSEQUENCE问题,或仅被呈现RESULTS问题),并且该指定的特定类型的话语关系可以用于过滤被呈现给用户的关于段落的问题。更具体地,在使用预先训练的分割点分类器结合针对段落的主题的经排名列表以及段落中的所标识的子句之间的所确定的话语关系,来标识段落内的候选分割点边界的集合之后,分割点分类器可以过滤候选分割点边界的集合,使得集合中没有与用户感兴趣的特定类型的话语关系相对应的任何候选分割点边界从集合中被省略,得到候选分割点边界的过滤后的集合,其仅包括与用户感兴趣的特定类型的话语关系相对应的候选分割点边界。
此外,应当理解,在给定的文本的段落中的给定的一对子句之间可以存在多于一个话语关系。例如,在一对子句之间可以存在多于一个显式话语关系,或者在一对子句之间可以存在混合的显式/隐式话语关系,或者在一对子句之间可以存在多于一个隐式话语关系。在给定的一对子句之间存在多个显式话语关系的情况下,可以使用上述预先训练的关系类型分类器用于消除这些关系的歧义。
还应当注意,可以以期望的任何组合来使用任何或所有上述实现以形成另外的混合实现。尽管已经以特定于结构特征和/或方法动作的语言描述了问题生成技术实现,但是应当理解,所附权利要求中定义的主题不一定限于上文中描述的具体特征或动作。相反,上文中描述的具体特征和动作被公开作为实现权利要求的示例形式。
4.0 示例操作环境
本文中所描述的问题生成技术实现在多种类型的通用或专用计算系统环境或配置中操作。图15示出了可以在其上实现本文中所描述的问题生成技术的各种实现和元素的通用计算机系统的简化示例。注意,在图15所示的简化的计算设备10中由折线(broken line)或虚线表示的任何框表示简化的计算设备的替选实现。如下所述,这些替选实现中的任一个或全部可以与贯穿本文档描述的其它替选实现结合使用。简化的计算设备10通常在具有至少某种最小计算能力的设备中被找到,诸如个人计算机(PC)、服务器计算机、手持计算设备、膝上型或移动计算机、诸如蜂窝电话和个人数字助理(PDA)的通信设备、多处理器系统、基于微处理器的系统、机顶盒、可编程消费电子产品、网络PC、小型计算机、大型计算机、以及音频或视频媒体播放器。
为了允许设备实现本文中所描述的问题生成技术实现,设备应当具有足够的计算能力和系统存储器以实现基本的计算操作。具体地,图15中所示的简化的计算设备10的计算能力一般由一个或多个处理单元12示出,并且还可以包括与系统存储器16通信的一个或多个图形处理单元(GPU)14。注意,简化的计算设备10的一个或多个处理单元12可以是专用微处理器(诸如数字信号处理器(DSP)、超长指令字(VLIW)处理器、现场可编程门阵列(FPGA)或其他微控制器),或者可以是具有一个或多个处理核心的传统的中央处理单元(CPU)。
另外,图15中所示的简化的计算设备10还可以包括其他部件,诸如通信接口18。简化的计算设备10还可以包括一个或多个传统的计算机输入设备20(例如,指点设备、键盘、音频(例如,语音)输入设备、视频输入设备、触觉输入设备、手势识别设备、用于接收有线或无线数据传输的设备等)。简化的计算设备10还可以包括其它可选部件,诸如一个或多个传统的计算机输出设备22(例如,一个或多个显示设备24、音频输出设备、视频输出设备、用于传输有线或无线数据传输的设备等)。注意,用于通用计算机的典型的通信接口18、输入设备20、输出设备22和存储设备26是本领域技术人员公知的,并且在此不再详细描述。
图15中所示的简化的计算设备10还可以包括各种计算机可读介质。计算机可读介质可以是可以由计算机10经由存储设备26访问的任何可用介质,并且可以包括易失性介质和作为可移除存储装置28和/或不可移除存储装置30的非易失性介质,用于存储信息,诸如计算机可读或计算机可执行指令、数据结构、程序模块或其它数据。计算机可读介质包括计算机存储介质和通信介质。计算机存储介质是指有形的计算机可读或机器可读介质或存储设备,诸如数字多功能盘(DVD)、光盘(CD)、软盘、磁带驱动器、硬盘驱动器、光驱动器、固态存储器设备、随机存取存储器(RAM)、只读存储器(ROM)、电可擦除可编程只读存储器(EEPROM)、闪存或其它存储器技术、磁带盒、磁带、磁盘存储装置或其它磁存储设备。
诸如计算机可读或计算机可执行指令、数据结构、程序模块等信息的保留也可以通过使用各种上述通信介质中的任一个(与计算机存储介质相反)编码一个或多个调制的数据信号或载波、或者其他传输机制或通信协议来实现,并且可以包括任何有线或无线信息传递机制。注意,术语“调制的数据信号”或“载波”通常是指以使得在信号中编码信息的方式设置或改变其特性中的一个或多个特性的信号。例如,通信介质可以包括用于传送和/或接收一个或多个调制的数据信号或载波的有线介质(诸如携带一个或多个调制的数据信号的有线网络或直接有线连接)以及无线介质(诸如声学、射频(RF)、红外线、激光和其他无线介质)。
此外,实施本文中所描述的各种问题生成技术实现中的一些或全部的软件、程序和/或计算机程序产品或其部分可以从计算机可读或机器可读介质或存储设备以及以计算机可执行指令或其他数据结构形式的通信介质的任何期望组合中存储、接收、传送或读取。
最后,可以在由计算设备执行的计算机可执行指令(诸如程序模块)的一般上下文中进一步描述本文中所描述的问题生成技术实现。通常,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、部件、数据结构等。问题生成技术实现也可以在分布式计算环境中实践,其中任务由一个或多个远程处理设备执行,或者在通过一个或多个通信网络链接的一个或多个设备的云内执行。在分布式计算环境中,程序模块可以位于包括媒体存储设备的本地和远程计算机存储介质中。另外,上述指令可以部分或全部实现为硬件逻辑电路,其可以包括或可以不包括处理器。
- 还没有人留言评论。精彩留言会获得点赞!