在大型非结构化数据字段中的技术和语义信号处理的制作方法
对相关申请的交叉引用
本申请基于并要求于2014年12月10日提交的临时美国申请no.62/090,178的优先权的权益,临时美国申请的全部内容通过引用并入本文。
本文公开的实施例一般而言涉及用于分析和解释来自非结构化数据的信号以识别和推理仅能通过所述概念的类比和代理间接访问的底层概念的分析算法、方法和过程。
背景技术:
本文提供的背景描述是出于一般地呈现本公开的上下文的目的。当前提名的发明人的工作,就该工作在这个背景部分中被描述的程度而言,以及在提交时没有以其它方式被限定为现有技术的本描述的各方面,既不是明确地承认也不是暗示地承认作为针对本公开的现有技术。
商业信息处理应用程序取决于具有挖掘非结构化数据存储的技术理解和能力。这些商业信息处理应用可以包括技术、市场趋势、竞争性产品、技术系统和功能以及新的和即将来临的市场的评估。非结构化数据的格式、技术形式或结构都不是同质的,其存储和检索的方法也不是同质的。根据定义,非结构化数据不以标准化的机器可读的跨计算机硬件和软件平台的方式被存储、策展(curate)、格式化或使其可访问。
已经由投资组合分析师使用任何一种技术(例如,技术功能和措施)分析和基础(例如,语义数据、信息和本体)分析完成关于非结构化数据字段(field)中隐藏的信息及其对风险、威胁和机会的识别的影响的最新评估。但是,尚未实现将技术分析和基础分析全面整合以包括这样的能力:出于识别和表征某些结果发生的“前提(pre-requisite)”条件(例如,风险代理、类比和类比的类比)的目的,识别和使用来自非结构化数据的信息信号(起始是隐含和明确的)。
自然语言处理(nlp)面临的一个重大挑战是,非结构化数据的几何增长会创造带来不断变化的意义的不断变化的文本流。对于及时提供分析结果,当代非结构化数据不适合“事后”处理或专家系统相关过滤、筛选、排序和计算。相反,仅需要一个能够在非结构化数据内容上进行实时过滤、筛选、排序和计算并且当数据的底层含义改变时在输出中适应的系统。关注单词单元、句子单元、段落单元、文档单元和文件单元的语法和语义处理的传统做法不足以应对挑战,因为它们不能解决识别向基于纯粹符号的(即,词典)语义解释增加风险的隐藏或隐含概念的存在。具体而言,传统的自然语言处理(nlp)和计算语言学(如由lsi/lsa(2)、语义搜索的概率和统计数据驱动模型(3)、专家模型和系统(4)、概念图(5)、语义图(6)、元标记(7)的学科以及相关领域所表示的)不能解决用于类比发现的非结构化数据的实时处理技术要求。
对于大的数据集,通常以包含集合中数据之间的所有成对关系的对称矩阵的形式描述相似性。遗憾的是,成对相似矩阵不适用于数值处理和视觉检查。对这个问题的常见解决方案是以尽可能忠实地保持原始的成对接近性的方式将对象嵌入到低维欧几里德空间中:例如,lsa、pca和其它此类向量方法。
称为多维缩放(mds)或非线性映射(nlm)的一种做法将数据点转换成实值向量集,该向量集随后可以被用于各种模式识别和分类任务。多维缩放(mds)是一种统计技术,其试图以最小的误差和失真保留模式的原始(语义上成对的)相互关系的方式将通过相异性矩阵描述的模式集嵌入低维平面。但是,目前的mds算法非常慢,并且其使用仅限于小的数据集。
技术实现要素:
本发明可以应用于使用从非结构化数据提取的信号导出的类比的所有形式的风险量化,并且这些类比代理用于可以是隐藏或隐含的而不是明确的在关于任何感兴趣的主题的数据中的风险识别和量化。
本发明定义了一种方法,该方法使得计算机系统能够系统地和灵活地挖掘非结构化数据内容并且以对关于系统、产品、市场、趋势或其它感兴趣事项的现状和预计未来状况的时间关键的分析发现必要的风险类比或风险代理的形式向用户提供对异质文件中隐藏意义和内容的访问。
本发明公开了一种用于根据具有计算数据结构的具体表示的非结构化文本字段的语义信号处理的方法以及所述方法与用于异常或惊喜的分析的本体框架的使用,所述具体表示用于作为得自数据的信号的可区分性和不可区分性的函数表示数据内的无知。如本文所述的信号处理是非结构化数据流中通过基于收敛代理的符号信号处理。技术信号由非结构化信息生成,该信号包括由令牌、对象、字母、符号、单词、文档标识符或文件中的其它原子(atom)的计算机编码而生成的信号。在本发明中语义信号由非结构化信息生成,并由三种语义边界指数表示:基于不可区分性对数据进行分类的指数;基于可区分性对数据进行分类的指数;以及基于无知对数据进行分类的指数。这些分类特定于本发明,并且用于导出指示间隙或空洞或隐含或间接概念实体的存在的其它信号。本发明定义了可以被聚合以形成充当信号的解释的类比或代理的唯一语义边界指数。
附图说明
当结合附图考虑时,通过参考以下详细描述提供对本公开的更完整的理解,其中:
图1示出根据一个实现的用于语义信号处理方法的流程图;
图2示出根据一个实现的用于生成技术信号流的装置的示意图;
图3示出根据一个实现的动态划分过程的流程图;
图4示出根据一个实现的语义边界指数过程的流程图;
图5示出根据一个实现的信息表示过程的流程图;
图6示出根据一个实现的执行类比发现的过程的流程图;
图7示出根据一个实现的检测惊喜和异常的过程的流程图;
图8示出根据一个实现的确定维度压力(stress)指数的过程的流程图;以及
图9示出根据一个实现的计算设备的框图。
具体实施方式
本文描述的方法提供用于分析和解释来自非结构化数据的信号以识别和推理仅能通过所述概念的类比和代理间接访问的底层概念的分析算法、方法和过程。本公开生成显式语义概念及其隐含的相关或相关联概念(包括类比,如类比或代理)的定性和定量表示。本文描述的方法使用称为语义边界指数(sbi)的数据结构和处理方法,该语义边界指数被用于以表征、存储、测量、监视、启用隐含和明确信息或证据的事务更新或分析的方式实时处理非结构化数据字段或流,以识别明确和隐含或隐藏的语义概念,包括类比。
sbi是通过使用基于符号语言的信号处理的动态划分产生的。这种处理通过基于代理的动态感测、表征、存储、监视、推理以及将非结构化数据划分为核心语义元素来进行。划分是根据sbi值的阈值及sbi值相关联的含义(如由归因于分析者的核心价值所指派的)以及机器提供的结果反馈来定义的。sbi是用于机器生成的完全集成的语句的数字代理,该语句关于技术和语义信号及该技术和语义信号在基于其中包含的底层内容发生在任何非结构化数据集内的语义和语法划分方面的含义。
sbi的语义边界可以根据对分析者具有最大解释或描述价值的边界类型进行调整。sbi是域无关的,可以实时改变并且使用本文所述的方法不断地进行评定、测量、处理和评估,以定义和表征下游核心语义元素,包括基于信号的类比类型、概念图、本体、信息差(informationgap)、趋势的表征、技术功能和度量的实例及其表征、域评定的发展水平,以及其它语义因素。
因此,本文所述的方法可以有利地提供非结构化数据的完全自动化评估,用于发现在惊喜或异常识别和预测中用于类比形成的定性和定量类比,以及用于从使用用于预报或预测假设情景识别的sbi创建的类比和代理快速检索隐含或明确的证据。
本文描述的方法的进一步的优点包括:
(1)在应用产生三类信号的本实施例之后,通过类比和代理的表示使得非结构化数据中的之前是不显然的隐含概念的网络变得明确,其中三类信号是:通过不可区分性关系表示数据的信号、通过关系区别表示数据的信号以及经由通过可区分性和不可区分性之间的交互得出的无知的测量来表示数据的信号。
(2)在常规数据处理范例中,类比的识别是困难的,并且在一些情况下,在没有大量的人的努力的情况下是不可能的,本文描述的方法利用从数据的信号提取来产生底层概念的类比或代理,该类比或代理可以与类比推理引擎一起使用用于识别相关概念。
(3)信号和导出的类比表征并且标注语义边界层之间的维度压力,从而揭示被示出以表示非结构化数据集的数据信号字段内的潜在断裂和压力点。
(4)非结构化数据字段中的信号处理使得能够进行独立于域的信息处理,并且适用于非结构化数据是知识存储的任何领域。这包括但不限于技术和科学领域(例如,物理学、生物学、化学、材料科学、工程和跨学科领域,诸如生物物理学、生物工程、遗传工程等);一般商业领域(例如,金融、营销、管理、运营、供应链管理等);大学和非政府组织领域(例如,行政管理、知识管理、资助和拨款管理、图书馆科学等);政府领域(例如,行政管理、公共政策、税收、法律、国家安全、研发投资组合管理等);以及非结构化数据是相关信息的存储库的任何其它领域。
(5)类比表示过程是快速、健壮的,并且提供从嘈杂或失真的数据进行学习。
(6)通过信号类型之间的类比的综合学习对于利用表示和方法和过程来实现是微不足道的;
(7)过程和方法适用于非口头或非语言处理
(8)通过应用与引用文献或开源数据源或用户(即,人或其它计算代理)的交互,方法和过程足以自举(bootstrap)以从零词汇开始学习语言;
(9)类比学习过程从样本中呈现出公共结构(拒绝相信的“噪音”),并且具有足够的证据和期望的标准,使得当证据匹配期望时发出肯定的信号。因此,本发明可以通过数据交互来“搜集”隐含的负面证据,并且本发明的底层系统从这些观察到的信号之间的交互“学习”。
(10)学习意味着交互传播通过代理的群体,所述代理朝着手边的主体调节代理的交互和观点。这解释了语义变化(在定义和使用方面的语言演化)的许多突出特征,而不是关于(人类)大脑的固有特征或者语言或者固定词汇或硬编码解决方案的规定方面。
另外,本文描述的方法可以应用于使用得自从非结构化数据提取的信号的类比的所有形式的风险量化,并且这些类比代理用于可以在关于任何感兴趣的主题的数据中隐藏或隐含的不明确的风险的识别和量化。
sbi可以被用于基于类比的推理和信号处理。类比和代理是在逻辑或时间上对应于数据模式的信号向量的特殊模式。一旦被训练,类比的已学习(已构建的)网络可以以前馈(feed-forward)的方式用来投射剩余的群体成员。因此,可以有利地以最小的失真来辨别和提取新的/未看见的数据模式和/或信息。
因此,本文描述的方法有利地将低级中介(agent)与类比或代理的数据表示和计算方法相结合,所述类比或代理是测量不能被直接观察但可以通过其它因素(即,类似于因素)被观察的任何事物的手段。因此,我们引入了语义边界指数的概念,它是一个软件对象,它提供关于类比的主动定量数据信号测量,该类比扮演不是可直接观察或可直接测量的数据的指示项或解释项的角色。
本发明的类比发现过程和方法形成清晰的快速知识形成和发现组成部分;这种做法的独特优点是它捕获显式功能中的非线性映射关系,并且在不需要每次重建信号向量的整个映射的情况下,在附加信息可能变得可用时允许该附加信息的缩放。
从信号的模式实时推断类比(如同它们由编码单词、句子、段落、文档和文件的计算机代码的多个特点生成)的能力是基于非参数、非统计的图式(schemata),该图式使用用于基于相似性计算以及表示间接或隐含概念的类比或代理的指数结构(即,这些是签名)的信号模式目录的相关分析的公式导出。
本文描述的方法提供通过使用基于来自美国哲学家和逻辑学家charlessanderspeirce的符号学(semiotic)理论的软件代理表示的符号过程(semiosis)的扩展和独特实施例。
peirce在符号过程的框架中制定“记号(sign)”的模型,其中记号产生记号和记号的分类法。peirce描述由以下组成的三元模型:代表项(representamen):记号采用的形式(不一定是物质);对象:记号所指的,并且最终是必须在观察者的脑海中发生的交互,该交互的结果产生解释项;解释项(interpretant):不是解释者(interpreter)而是由记号组成的意义。代表项形式的记号是在某个方面或能力上向某人坚持某物的事物。符号代表某物,它的对象。它不是在所有方面代表那个对象,而是关于一种想法,有时被称为代表项的范围(ground)。代表项与对象以及观看者(beholder)的眼睛之间的交互创造了解释项,并被peirce称为符号过程的过程。在peirce的记号模型中,用于“停止”的交通灯符号将包括:交叉路口面对交通的红灯(代表项);车辆停住(对象)以及在观看者(即,驾驶员)脑海中形成的红灯指示车辆必须停止的想法(解释项)。
peirce的记号模型包括对象或指示项。代表项与指向对象的指针在意义上相似。但是,解释项具有与所指(signified)的特质不同的特质:它本身就是解释者脑海中的记号。umbertoeco使用短语“无限制的符号过程”来指其中这可以导致(如peirce很好地意识到的)(可能地)无限的一系列连续的解释项从而形成符号过程的过程的方式。
为了实现percean框架,需要两个特殊组成部分:(i)能够进行观察和解释的自主软件过程;和(ii)形成可以被观察和解释的记号的感知系统。
这两个组成部分分别由以下提供:用于观察和解释的代理技术;其次,用于创建作为其它记号的函数的记号的专用感知系统,其被实现为某个底层数据集上的时间序列信号窗口,无论该底层数据集静态还是动态变化。
dinahgoldin和peterwegner已经通过交互描述计算的本质,虽然wegner和goldin并没有将这个模型与peirce的符号学相关或连接,但是由“交互主义”的计算(产生连续的记号状态)来总计解释用于对象和代表项的记号的代理之间的交互,其中wegner和goldin证明“交互主义”等同于可以超过传统计算算法模型的能力和限制的超级图灵(super-turing)机。
现在参考附图,其中在若干视图中相同的标号表示完全相同或对应的部分,图1示出类比发现方法和过程的流程图。
方法100的过程110执行动态划分方法。
方法100的过程120执行定义sbi的语义边界指数方法。
方法100的过程130执行信息表示方法。
方法100的过程140执行加权表示方法。在方法100中,过程130和140被示为并行发生。这指示过程130和140之间没有依赖关系,使得不存在过程130和140被执行的预定顺序。
方法100的过程150执行信号互换方法。
方法100的过程160执行类比发现方法。
方法100的过程170执行第一惊喜和异常检测方法。
方法100的处理180执行第二惊喜和异常检测方法。
方法100的过程190执行维度压力发现方法。
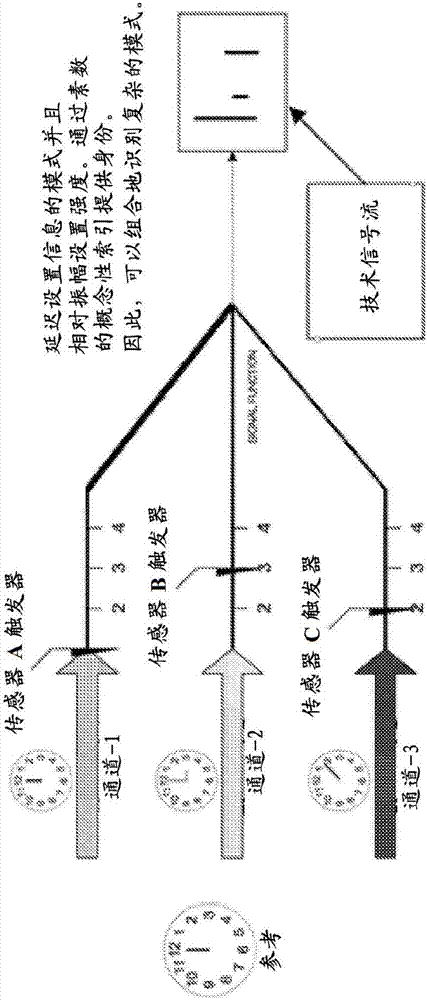
图2示出信号获取装置的示例,其中三个通道具有单独的时钟,并且在每一个通道上设置不同的延迟使得当信号被组合以产生技术信号流时导致一系列偏移尖峰。延迟设置信息的模式并且相对振幅设置强度。通过素数的概念性索引提供身份。因此,可以组合地识别复杂的模式。
图3示出执行动态划分方法的过程110的实现。
过程110的过程310确定与信号之间的区别对应的第一通道。
过程110的过程350确定与信号之间的无区别对应的第二通道。
过程110的过程380确定与信号之间的无知对应的第一通道。
因此,由过程110执行的动态划分算法是将数据元素划分成被称为可区分、不可区分和无知的类别的算法。
动态划分过程110分配代理以基于它们的观察来生成信号测量,并且根据代理的私有知识基于可区分性,将信号划分成语义组成部分,或者使用代理的私有知识作为逆向约束,沿着“不可区分”线分割数据,要注意的是,一些数据可能属于既不是可区分又不是不可区分的第三类,在这种情况下,数据被标记为“无知”。基于不可区分性的划分与“粗糙集(roughset)”技术有关。此外,基于区别的划分与数据聚类的方法相关。但是,区别数据和无区别数据之间的交互产生可被用来开发类比或代理的“无知”数据。动态划分使用在机器处理层处的基本单位,其中所有信号的观察、存在的证明、意义、指示项、编码、分类和检索机制被一致地、系统地且完整地完成。这是以本公开为基础的基于符号学的信号处理的核心属性。正是用于区别和无区别的模型之间的间隙产生可以被迭代以识别类比或代理的以数据形式利用的信号。下面进一步讨论这个过程。
确定区别信号的过程310由算法1的步骤定义:
i)使用测量量规(rubric)获得原始观察为某类。例如,可以使用股票市场技术指标或基于现有本体或数据库的语义距离测量(诸如,resnik测量);
ii)从集合中提取训练模式的随机集合p;
iii)使用几何非线性映射函数p→y将模式映射到
iv)通过聚类来确定模式的本体o,例如使用k-均值(k-means)聚类或其它基于距离测量的方法;
v)基于已知的数据解释创建一些参考模式r;
vi)使用例如pearson相关系数依据o确定p和r之间的相似性函数:sim(p,r),并且将相似性集称为s。
vii)例如使用shepard插值函数确定函数集s(fi),以映射si→yi;以及
viii)收集s(fi)的所有函数,并将它们导出为到知识映射ik的信息。这个集合被称为技术信号集。
此外,可以通过算法2的步骤来为新模式更新区别信号通道:
i)确定任何新模式与每一个参考模式的相似性;
ii)确定函数s(gi),以映射si→yi;以及
iii)用gi更新包含s(fi)的信号。
确定无区别信号的过程350由以下步骤定义:
i)基于未能由过程310区分,将原始观察提取到一些类集合中;
ii)从集合中提取训练模式的随机集合p;
iii)使用几何非线性映射函数p→y将模式映射到
iv)确定模式的本体o;
v)创建一些参考模式r;
vi)确定o之下的p和r之间的相似性函数:sim(p,r),并将不相似性集称为s;
vii)确定函数集s(fi),以在o之下映射si→yi;
viii)使用概念距离度量和基(basis)c将对象yi链接或聚类,并创建通过其相对于所选基参考(basisreference)的不可区分性来聚类的聚类集{yci};
ix)对于yi的c中的每一个不相交的聚类ci,基于ri→yi到聚类原型ci之间的距离,确定“最接近的”训练参考集;
x)寻找独立于|ci|的函数,其确定函数s(fi)到c中的每一个ci的无区别成员资格(即,粗糙集),称这个集合为s(hi);
xi)对于每一个s(hi),确定到s(fi)的映射并称这个映射为mi;以及
xii)mi是无区别技术信号。
因此,用于生成用来创建类比的技术信号的算法被描述为使用区别来生成信号的算法与基于无区别来生成数据的划分的第二算法之间的交互。为了方便起见,用于区别、无区别和无知的三种信号分别被标记为1型通道(又称为通道-1)数据、通道-2数据和通道-3数据。
确定无知信号的过程380将不在第一通道或第二通道中的那些信号识别为处于第三通道中(即,无知信号)。参考上面的算法1和算法2:识别相对于给定边界窗口(即,采样尺寸)内的数据的信号集的直方图的并集(union)的补集(complement),并将这个集称为“无知信号”集。这个集表示产生异常的数据或经由不能由所提供的方法直接可观察的隐含关系相关的数据。
现在参考图4,过程120执行语义边界指数算法。语义边界指数算法是一种将三个区别封装在基于单个流的软件数据表示对象中的方法,该对象适于计算不可直接测量的底层数据的各种其它属性。
在过程120的步骤410中,每一个代理可以创建通道,或者单个代理可以创建全部三个通道。
在过程120的步骤420中,每一个通道具有其自己的相对于主机的时基或时钟参考,其中时钟可以是逻辑lamport时钟(logicallamportclock)。
在过程120的步骤430中,每一个通道分别基于类型(区别、无区别和无知)生成数据流。以相对于时钟的速率并对于特定的样本数对数据流进行采样。采样窗口的尺寸和采样率被称为“边界”。
在过程120的步骤440中,将信号乘以对数函数并相对于时间进行微分,以在窗口中每一个规则的间隔产生关于时钟的有界采样窗口尺寸内的编码的尖峰列。
在过程120的步骤450中,尖峰列的模式与底层数据或概念的类型对应,并且用唯一生成的md5(消息摘要)标识符标记原始数据。
在过程120的步骤460中,在步骤(4)中生成的有界尖峰列信号被转换为二进制位码,使得位码在每一个位位置处包含时钟。因此,对于64个时钟的周期(tick),将会有64位二进制位码。
在过程120的步骤470中,步骤460的输出被附有消息摘要标识符。
在过程120的步骤480中,语义边界指数(sbi)被返回为消息标识符、数据和位码。
现在参考图5,过程130执行信息表示算法。
在过程130的步骤510中,根据已知的参考数据样本或本体标记流学习图式(schemata)。参考数据将具有被指派的元数据标签,并且这个标签将被用来标记从过程120导出的sbi。
在过程130的步骤520中,使用距离的测量(诸如,dice测量、jaccard测量或任何其它测量)根据流来划分未知数据。
在过程130的步骤530中,未知信号匹配到信号组成部分,该信号组成部分的sbi充当模式类比或代理,用于基于相对于所选择的测量系统选择的阈值对未知模式进行分类。
在过程130的步骤540中,sbi的输出作为采样窗口内的时间序列信号返回,该采样窗口的采样尺寸对应于底层sbi本身的演变,并且这个过程可以递归到任何用户选择的深度。
在过程130的步骤550中,得到的sbi加窗的(windowed)时间序列用用于窗口序列的时间偏移量以0到1的范围归一化,并且每一个窗口被delta编码(即,差分编码)并作为分层语义边界指数(hsbi)返回。例如,对于周期性模式,hsbi将在一定数量的样本内重复并形成固定点。
在过程130的步骤560中,hsbi被返回或存储在数据存储装置中。
函数的选择(数据通过该函数被转换到通道中)影响所产生的信号测量的质量。函数的数据点的选择可以基于最大熵(或多样性),并且相对于随机选择具有有益效果,因为其消除了输入数据的表示中的冗余。但是,如果表示了可区分性、不可区分性和无知,那么其它方法也可以用来生成sbi。
与语义边界指数的算法和方法相反,向量空间方法和算法具有以下问题。
1)使用了欧几里德归一化,这对于实际的神经硬件不是微不足道的计算。
2)输入组成部分ik的尺寸及其重要性是混淆的。如果弱的组成部分具有特别的重要性,或者强的组成部分是不可靠的,那么不存在表示这一点的方式。单个w测量只能够描述目标组成部分的一个语义维度。
3)如果问题要通过将输入分成若干部分、独立地解决、并将这些结果馈送给更高级别的处理器进行最终确认而被分解成层次,那么不存在自然的组合。通过类比视觉可以最好地看出这一点。如果人在一幅图中在一个范围上识别祖母的鼻子、在另一个范围上识别她的嘴,并在第三个范围上识别她的右眼,那么肯定不是祖母。单独的归一化对于创建层次是困难的(它使所有语义变得平坦)。
4)大量的输入可能丢失或给出严重错误的信息。“点积与阈值(dot-product-and-threshold)”解决方案无法应对这一问题,因为语义差异已经丧失。
当使用动态划分对信息进行编码和计算以生成对数据的信号测量时,上述所有四个识别的问题都被去除。信号表示的三个数据馈送通道通过相对于参考时间的时间签名t(可能是逻辑时钟)的信号的位置发生。通道中t与“尖峰”的时间之间的间隔被对数地缩放,所以我们可以说尖峰的时间是j并具有输入通道i,因此由logij定义。另外,可以根据其它信息(例如,使用dempster-shafer理论的统计或信念或概率或证据)来加权信号。
因此,可以基于行为模式的与技术信号测量窗口的“相对”组成部分来识别行为模式。范围信息保留在识别单元被驱动的时间内。系统明显“组合”,并且困难(3)被克服。不需要归一化消除了困难(1)。每一个通道具有描述它的三个参数,延迟(其包含关于要识别的模式的信息)、信号强度(其描述在识别单元处的权重)以及形状(其表示正在被计算的概念)。
因此,范围和重要性(权重或信心测量)是分开表示的,而在传统的系统中,它们被扁平化。核心的计算主题(motif)是使用技术信号测量及其相关联的语义组成部分,因为这些捕获数据和信息之间的相对性:关联性和隐含的相关性,并且简而言之,相对定时表示信息并且时间延迟表示信息动态模式(关于数据本身嵌入的信息内的时间的进化或行为)。
用于动态划分的本方法可以容忍由于在常规方法(例如,使用传统神经网络模型或lsa/lsi)的时域信息映射内的丢失或严重不准确的信息计算的错误。原因是,当学习阈值设置为高时,两种方案都识别相同的信息(即,高阈值意味着所接收的信息中的清晰度高,并且不含糊)。
在高噪声或竞争性信号的情况下,降低时域方案中的识别阈值导致确定任何两个组成部分是否处于正确的比率,与第三组成部分的尺寸无关。范围与重要性的解耦允许可以用常规方法来辨别这一点。这种类型的阈值降低意味着(传入信息的)几乎任何向量都将被(错误地)识别,因为范围与相对的重要性混合。
每一个通道可能经历不同程度的失真、噪声和相对时间变形,只要它在不完全破坏传感器数据之间的相对定时的情况下存在,就将向信息变换提供用于准确、抗噪声的数据的模型。
关于hsbi中的语义边界层,当信号在信号的聚合组合被减少到形成新的分层语义边界指数(hsbi)输出的三元组(triple)集(即,输入是对象和代表项并且输出是解释项)的层次中进行处理时。边界层对应于层次之间的层,并且在这些层内,聚合的聚类以及描绘与新的解释项对应的聚合的边界条件的采样窗口的选择。
关于sbi,语义边界指数对应于连续解释项之间的差异测量。
关于维度压力测量,维度压力对应于解释项的失真、扩张和收缩。
语义边界指数算法及其递归分层语义边界指数产生一个指数结构,该指数结构在变化的环境因素下的贡献将相对于该指数结构对类比表示的贡献改变:换句话说,为了利用本发明,sbi被用元数据标签标记,并且具有不同的非匹配标签的sbi的相似性或聚类被解释为意味着标签是彼此的类比。sbi的聚类之间的边界形成可以在重叠聚类之间共享的层,因此类比可以共享直接的相似性,或者,利用各种加权,边界可以扩大或缩小。在极端情况下,来自一个sbi的边界层可以消耗(consume)相邻的sbi。在这种极端情况下,在一个类比包含(subsume)另一个类比的意义上,消耗者(consumer)变成那个数据及其底层sbi的新分类器(classifier)。以这种方式,包含或包围sbi的顺序层次可以被构造为权重的图像。这种变化通过使用为本发明提供的算法的加权方案来量化。
过程140将这些权重应用于sbi。可以由主题专家信心测量通过统计或可能性或经验性方法得出权重,并且也可以通过训练过程分配权重,在该训练过程中权重被调整,直到类比与人类验证的判断一致。
过程150执行信号互换算法。信号互换算法提供将一个表示从一个通道转换到另一个通道的手段,并允许使用sbi的代理进行互操作。例如,可以在三种信号类型之间进行互换,使得信号a封装信号b和c。信号互换的另一个示例可以是信号a被合并到信号d。
现在参考图6,过程160执行类比发现算法。测量集合及其与底层数据驱动特征的关联产生一种表示,该表示可以被用来由通过其sbi的相关来将作为类比的具体数据结构彼此相关。过程160将类比引擎(诸如,vivomind类比引擎(vae))的使用应用于如本文定义的应用过程中的非明显未来(future)的预示和预测,并使用sbi来识别可以被用来向类比引擎提供足够的部分以合成整个完整类比的预期类比。
在过程160的步骤610中,探索在感兴趣的域(例如,财务流)中的类比引擎当代知识,并将这个域指定为“目标”域。
在过程160的步骤620中,使用从目标域提取的感兴趣的行为来识别另一个系统(例如,生物过程),并将其称为“源”域。
在过程160的步骤630中,域内的概念支架(scaffolding)被识别为其特征、行为、属性、功能或能力的原始本体(proto-ontology)。
在方法160的步骤640中,(iv)在源域支架和目标域支架之间产生结构化关系,以便构建类比支架。
在过程160的步骤650中,(v)使用类比支架,通过使用源域和目标域之间的新发现的类比,生成未来指示符(例如,生成要提出的正确问题)。
在过程160的步骤660中,在源系统和目标系统之间识别一致类比的对,以产生源系统和目标系统的动态相似性的视图。
在过程160的步骤670中,根据这些动态相似性,生成假设并预测目标系统的未来演化。
对于源域存在许多潜在的系统。本文列出了一些模型,但是源域的潜在模型的该列表并不限于此。用于类比的模型可以包括:
1.来自科技期刊的信息模型;
2.来自生物学、政治学、股票市场和其它源的信号数据模型;
3.来自信息学期刊或源的测量模型(适用于信号数据);
4.来自商业过程的处理模型(信号数据模型的计算机仪表)或工厂车间调度模型;
5.如在商业智能、科学或技术智能实践方面所出现的分析模型;
6.定性评定模型:诸如层次分析过程(ahp)的输出;
7.定量评估模型:诸如来自ahp的加权输出;
8.如在科学、技术或社会需求工程中所理解的间隙分析模型;
9.“发展水平”模型,诸如nasa技术就绪评定等级模型;
10.类比推理模型:诸如veale等人或falkenheimer等人的类比本体论;
11.前提映射模型:诸如用于设计的triz方法映射模型;
12.根据本发明的惊喜模型;
13.根据投资组合和股票市场分析模型的投射模型;
14.类比模型的类比:诸如隐喻、寓言、比喻和其它类似于本发明的训练集的话语结构;和
15.其它基于本体论的模型,如可能偶尔使用或识别的。
本公开中包含的类比发现过程的显著优点是,它使得能够快速重新利用过去的经验,以在新颖或不可预见的情况下实现操作创新。通过信号处理范式进行的类比推理允许发现在域中和域之间暗含的隐藏知识。类比发现过程允许用户将显然不相称和不同的域相关为结构化关系,并且通过这样做来构思(craft)结果并构思一起产生对大型非结构化数据字段的含义的新视图和理解。
过程170执行第一惊喜和异常检测过程。移动平均(movingaverage)以及动量和周期性检测过程的使用(诸如,在传统投资组合分析中所使用的)被组合,以产生其中可能发生主要变化的维度压力的临界点的指示。这些高度不稳定的区域形成用于惊喜结果或异常的联系,并且特点具有与在可以产生惊喜和异常的混沌系统中发现的演化结构过程的类型的相似性。
除了上面讨论的移动平均、动量和周期性检测过程,传统的投资组合分析还使用许多其它技术指标。在这里,从stevenb.achelis,technicalanalysisfromatoz,mcgraw-hill,(2000)(其全部内容通过引用并入本文)中列出若干技术指标。这些指标包括:
1.绝对幅度指标
2.累积派发
3.累积摆动指标
4.上涨/下跌线
5.上涨/下跌比率
6.上涨-下跌值
7.阿姆氏指标
8.阿隆指标
9.平均真实区域
10.布林带
11.宽度突破
12.牛/熊比率
13.蔡金货币流量
14.蔡金摆动指标
15.钱德动量摆动指标
16.商品通道指标
17.商品选择指标
18.相关性
19.累计成交量指标
20.双重指数移动平均和三重指数移动平均
21.非趋势价格摆动指标
22.动向指标
23.动态动量指标
24.轻松移动指标
25.轨道(envelope)
26.预测摆动指标
27.惯性指标
28.日内动量指标
29.克林格摆动指标
30.大宗交易比率
31.线性回归指标
32.线性回归趋势线
33.线性回归斜率
34.macd
35.市场便利指标
36.质量指标
37.迈克勒兰摆动指标
38.迈克勒兰和
39.中间价格
40.会员卖空比率
41.动量
42.货币流量指标
43.移动平均-指数
44.移动平均-简单
45.移动平均-时间序列
46.移动平均-三角
47.移动平均-变量
48.移动平均–成交量调整的
49.移动平均-加权
50.负容积指标
51.新高-新低累积指标
52.新高-新低指标
53.新高/新低比率
54.零股平衡指标
55.零股卖空比率
56.平衡交易量
57.公开-10交易(open-10trin)
58.超买/超卖指标
59.抛物线状的止损与反转
60.表现指标
61.正量指标
62.价格通道
63.价格摆动指标
64.价格的变动率
65.价量趋势
66.投射带
67.投射摆动指标
68.公众卖空比率
69.看跌/看涨比率
70.q棒指标
71.r平方指标
72.拉弗回归通道
73.区域指标
74.相对动量指标
75.比较相对强弱指标
76.相对强弱指标
77.相对波动性指标&惯性指标
78.标准离差
79.标准离差通道
80.标准误差
81.标准误差带
82.标准误差通道
83.stix
84.随机动量指标
85.随机摆动指标
86.摆动指标
87.三重指数移动平均
88.时间系列预测
89.总卖空比率
90.trix
91.典型价格
92.终极摆动指标
93.上涨/下跌量比
94.上涨-下跌量指标
95.垂直水平过滤指标
96.蔡金波动性指标
97.成交量摆动指标
98.成交量变动率
99.加权收盘价
100.威尔德平滑
101.威廉姆斯累积/派发指标
102.威廉姆斯%r
类比依赖于来自低级数据过滤器的数据流,该数据过滤器在元数据标签上产生投票,其中元数据标签充当表示操作系统环境中存在风险的信号的符号观察。
ema是当前支持标签的投票频率的百分比与昨天的移动平均值的百分比的比较。指数移动平均对支持标签的最近投票置以更多权重。指数移动平均(ema)指标所具有的超过简单移动平均的优点是最近的投票支配先前的投票。这使得ema对短期趋势高度响应,从而使短期趋势(诸如,短期初始应用行为)的异常可以揭示威胁代理(threat-agent)的可能性。长度参数k控制ema如何响应于最近趋势。在时间i,k乘ema,其中ρt是时间t处的值,并且emat-1是尺寸(长度)κ的之前时间的ema。
代理可以比较对于给定的投票集(关于由低级数据过滤器产生的观察的标记投票)短期ema何时跨越超过长期ema。这种交叉指示增加的信心,即,指数正在识别将由活跃代理群体的剩余部分投票的具体标签的具体强度(标志或者“压力”或者“放松”)。
为了比较来自不同质量维度的sbi,我们最初将在[-1,1]的间隔内对所有sbi进行归一化,并且我们使用加权算法来偏置质量维度的重要性。通过适应来自当代投资组合理论的交易领域的类似规则,将为其它指标设计每一个推理规则,诸如ema交叉规则。
现在参考图7,过程180执行第二惊喜和异常检测方法。列出了用于在制定代表性过程中使用的特定的和优选的公式,并且给出了向本发明的结果提供特异性的变量(variant)。
简单的移动平均通过在特定数量的窗口上计算sbi的平均值来形成:这本身产生层次的sbi。通过计算sbi的偏度(skewness)、峰度(kurtosis)、偏差和其它高阶因子来表征动态范围以及尤其是动态范围相对于sbi的动态范围的范数(norm)的变化来一般化“惊喜和异常”模式的训练集。
在过程180的步骤710中,使用来自相关源(诸如,作为一个源的科幻文学和作为另一个源的专利文献)的惊喜的训练集来构建每一个源的sbi。
在过程180的步骤720中,使用距离矩阵或者k-均值聚类或其它算法来计算sbi之间的相似性。
在过程180的步骤730中,对于每一个标记的数据,使用表示交易量、周期、动量和变化率的适当选择的股票市场技术指标来计算sbi的图像。
在过程180的步骤740中,计算偏度、峰度、偏差和指数移动平均值。
在过程180的步骤750中,将标记为“惊喜”的数据与其他方式标记的数据进行比较,并使用结果的步骤740之间的差值的50%来计算“阈值”。
在过程180的步骤760中,将该方法应用于新数据,并且对于任何超过阈值的数据,将数据标记为“惊喜”。
在过程180的步骤770中,返回“惊喜”数据结构sbi。
现在参考图8,过程190执行维度压力方法。关键因素包括调制语义边界指数的数据和信息元素的多维集。这些元素包括维度压力源、松弛源、阻滞源和加速源。与本公开中信息模型集成的定性和定量评定模型被部署以分析大型非结构化数据中的内容。这种分析模型包括但不限于间隙分析模型、智能交易模型、域模型、技术就绪水平模型、制造就绪水平模型、类比推理模型、投射和预测模型、威胁矩阵模型、swot模型和其它分析方法。
在过程180的步骤810中,从惊喜的训练集形成相关源的对。例如,可以使用科幻文学作为一个源以及专利文献作为源对以及来自新报告和政治事件的对来形成相关源的对,为每一对构建用于异常和惊喜的算法。
在过程180的步骤820中,在对中的差异之间计算偏度、峰度、偏差和指数移动平均;
在过程180的步骤830中,对差异进行加权,直到其导致用于异常和惊喜的算法的阈值的50%偏移。这是维度压力指数。
在过程180的步骤840中,相对于采样窗口边界,将方法应用于新数据。并且对于:
1.增加阈值的任何数据,将其标记为压力源;
2.降低阈值的任何数据,将其标记为松弛源;
3.扩大阈值的位置的任何数据,将其标记为阻滞源;以及
4.收缩阈值的位置的任何数据,将其标记为加速源。
在过程180的步骤810中,过程180返回维度压力指数。
与某些语义边界层相关联的某些信号模式由本公开与称为“维度压力”的核心语义元素相关联。维度压力是一种信息或模型的语义类别,该维度压力描述伴随由于引入新的数据或知识或者由于从数据字段中移除数据或知识而导致的包含在大型非结构化数据中的信息的意义中的快速移动、意想不到的变化而发生的前提。维度压力是一种语义测量,通过它提前生成关于非结构化数据字段的情况的意识,该情况启示某些类型的语义边界层的存在或出现。这些语义边界层又通过本公开被评定以与语义边界指数得分密切地相关联,该语义边界指数得分与维度压力和维度压力源相关联,从而允许分析者构建关于何时稳定的、不稳定的、不变的或快速变化的语义元素可能会出现或者可能开始出现的结构化知识库。这个知识库产生关于大型非结构化数据字段中惊喜的元素的未来意识。维度压力是与发现大规模、连续更新的非结构化数据字段中的内容的意义的潜在、快速、意想不到的变化相关联的核心语义属性,包括用于发现类比的核心语义属性。
通过关于语义边界层和语义边界交互指数的信号的实时测量和处理生成维度压力指数。当在与域中的关键驱动器相关联的特殊语义边界层内部和之间存在高的变化(随时间不稳定)时,出现高维度压力。当在与域中的关键驱动器相关联的特殊语义边界层内部和之间存在低的变化(随时间的稳定性)时,出现低维度压力。作为量化信号数据模型的结果产生这两种情况中的维度压力指数,该模型被调整成检测随时间的变化、语义边界内部和之间的稳定性和不稳定性。
惊喜模型基于相对于来自作为给定域的输入的相关文献集合的类比对的量化的sbi时间序列测量之间的交互。文献集合的域可以包括某些优选实施例对,诸如:
1.政治新闻和政治事件(例如,国家元首的言论和选民所投的投票)
2.科学技术期刊与专利文献
3.专利文献与科幻文学
4.经济新闻与自然事件(例如,股票价格和海啸)
5.军事活动和社会新闻(例如,精神疾病的移动和速率或者示威游行的速度和规模)
惊喜模型是“模型的模型”,因为它们是根据sbi及其来自模型对的相应类比之间的交互之间的具体上下文中的分析工作生成的:边界上的信号处理结果以及使用本方法和算法产生类比、类比的类比,非结构化数据字段的差距模型,维度压力和维度压力源的模型,语义边界层模型和核心语义元素的其它模型。惊喜模型是类比推理的中心结果。
返回的“惊喜”sbi被用来识别类比,并且类比与类比发现过程一起使用以识别不可预见的惊喜或异常。
可以使用某种形式的计算机处理器或处理电路系统来实现本发明的上述算法和过程以及特征中的每一个,例如,使用特别编程的处理电路系统。电路系统可以被特别设计或编程以实现上述功能和特征,这些功能和特征提高了电路系统的处理,并且允许数据以不可能由人或甚至缺乏本实施例的特征的通用计算机的方式处理。如本领域普通技术人员将认识到的,计算机处理器可以被实现为离散的逻辑门,如专用集成电路(asic)、现场可编程门阵列(fpga)或其它复杂可编程逻辑器件(cpld)。fpga或cpld实现可以以vhdl、verilog或任何其它硬件描述语言进行编码,并且代码可以直接存储在fpga或cpld内的或者作为单独的电子存储器的电子存储器中。此外,电子存储器可以是非易失性的,诸如rom、eprom、eeprom或flash存储器。电子存储器也可以是易失性的,诸如静态ram或动态ram,并且可以提供处理器(诸如,微控制器或微处理器)来管理电子存储器以及fpga或cpld与电子存储器之间的交互。
可替代的,计算机处理器可以执行包括执行本文描述的功能的一组计算机可读指令的计算机程序,该程序被存储在上述非瞬态电子存储器和/或硬盘驱动器cd、dvd、闪存驱动器或任何其它已知的存储介质中的任何一种中。此外,计算机可读指令可以作为结合处理器(诸如,来自美国intel的xenon处理器或来自美国amd的opteron处理器)和操作系统(诸如,microsoftvista、unix、solaris、linux、apple、mac-osx以及本领域技术人员已知的其它操作系统)执行的实用应用、后台守护程序、或操作系统的组件或其组合提供。
此外,可以使用基于计算机的系统901来实现本发明。可以由一个或多个处理电路来实现上述实施例的功能中的每一个功能。处理电路包括被编程的处理器(例如,图9中的处理器903),因为处理器包括电路系统。处理电路还包括诸如专用集成电路(asic)和被布置成执行所述功能的常规电路部件的设备。
上述讨论的各种特征可以由计算设备(诸如,计算机系统(或可编程逻辑))来实现。图9图示这种计算机系统901。图9的计算机系统901可以是特定的专用机器。在一种实施例中,当处理器903被编程为计算向量缩并时,计算机系统901是特定的、专用机器。
计算机系统901包括耦合到总线902以控制用于存储信息和指令的一个或多个存储设备的盘控制器906,该一个或多个存储设备诸如磁硬盘907和可移除介质驱动器908(例如,软盘驱动器、只读紧凑型盘驱动器、读/写紧凑型盘驱动器、紧凑型盘自动点唱机(jukebox)、带驱动器和可移除磁光驱动器)。可以使用适当的设备接口(例如,小型计算机系统接口(scsi)、集成设备电子器件(ide)、增强型ide(e-ide)、直接存储器访问(dma)或超-dma)将存储设备添加到计算机系统801。
计算机系统901还可以包括专用逻辑器件(例如,专用集成电路(asic))或可配置逻辑器件(例如,简单可编程逻辑器件(spld)、复杂可编程逻辑器件(cpld)和现场可编程门阵列(fpga))。
计算机系统901还可以包括耦合到总线902以控制用于向计算机用户显示信息的显示器910的显示控制器909。计算机系统包括输入设备(诸如,键盘911和定点设备912),用于与计算机用户交互并向处理器903提供信息。定点设备912例如可以是鼠标、轨迹球、用于触摸屏传感器的手指、或用于向处理器903传达方向信息和命令选择以及用于控制在显示器910上的光标移动的定点杆。
处理器903执行包含在存储器(诸如,主存储器904)中的一条或多条指令的一个或多个序列。这些指令可以从另一个计算机可读介质(诸如,硬盘907或可移除介质驱动器908)读入到主存储器904中。也可以利用多处理布置中的一个或多个处理器执行包含在主存储器904中的指令序列。在替代实施例中,可以使用硬连线电路系统代替软件指令或硬连线电路系统可以与软件指令组合使用。因此,实施例不限于硬件电路系统和软件的任何特定组合。
如上所述,计算机系统901包括至少一个计算机可读介质或存储器,所述至少一个计算机可读介质或存储器用于保存根据本公开的任何教导编程的指令和用于包含本文所述的数据结构、表、记录或其它数据。计算机可读介质的示例是紧凑型盘、硬盘、软盘、带、磁光盘、prom(eprom、eeprom、闪存eprom)、dram、sram、sdram或任何其它磁介质、紧凑型盘(例如,cd-rom)或任何其它光学介质、穿孔卡、纸带或具有孔模式的其它物理介质。
存储在计算机可读介质中的任何一个上或其组合上,本公开包括用于控制计算机系统901、用于驱动用于实现本发明的一个或多个设备、以及用于使得计算机系统901能够与人类用户交互的软件。这样的软件可以包括但不限于设备驱动程序、操作系统和应用软件。这样的计算机可读介质还包括用于执行在实现本发明的任何部分中执行的处理的全部或部分(如果处理是分布式)的本公开的计算机程序产品。
本实施例的计算机代码设备可以是任何可解释或可执行的代码机制,包括但不限于脚本、可解释程序、动态链接库(dll)、java类和完整的可执行程序。此外,为了更好的性能、可靠性和/或成本,本实施例的处理的部分可以是分布式的。
本文所使用的术语“计算机可读介质”是指参与向处理器903提供指令用于执行的任何非瞬态介质。计算机可读介质可以采取许多形式,包括但不限于,非易失性介质或易失性介质。非易失性介质包括例如光盘、磁盘和磁光盘,诸如硬盘907或可移除介质驱动器908。易失性介质包括动态存储器,诸如主存储器904。相反,传输介质包括同轴电缆、铜线和光纤,包括构成总线902的电线。传输介质也可以采取声波或光波(诸如,在无线电波和红外数据通信期间所生成的那些波)的形式。
将一条或多条指令的一个或多个序列携带出到处理器903中用于执行可以涉及各种形式的计算机可读介质。例如,指令最初可以被携带在远程计算机的磁盘上。远程计算机可以将用于实现本公开的全部或部分的指令加载到动态存储器中,并使用调制解调器通过电话线发送指令。计算机系统901本地的调制解调器可以接收电话线上的数据并将数据放置在总线902上。总线902将数据携带到主存储器904,处理器903从中检索并执行指令。由主存储器904接收到的指令可以可选地在由处理器903执行之前或之后存储在存储设备907或908上。
计算机系统901还包括耦合到总线902的通信接口913。通信接口913提供耦合到网络链路914的双向数据通信,该网络链路914连接到例如局域网(lan)915或者连接到另一个通信网络916,诸如互联网。例如,通信接口913可以是附接到任何分组交换lan的网络接口卡。作为另一个示例,通信接口913可以是综合业务数字网(isdn)卡。也可以实现无线链路。在任何这样的实现中,通信接口913发送和接收携带表示各种类型的信息的数字数据流的电信号、电磁信号或光信号。
网络链路914通常通过一个或多个网络向其它数据设备提供数据通信。例如,网络链路914可以通过本地网络915(例如,lan)或通过由服务提供商操作的装备来提供与另一个计算机的连接,服务提供商通过通信网络916提供通信服务。本地网络914和通信网络916使用例如携带数字数据流的电信号、电磁信号或光信号以及相关联的物理层(例如,cat5电缆、同轴电缆、光纤等)。可以在基带信号或基于载波的信号中实现通过各种网络的信号以及在网络链路914上并且通过通信接口913的信号,所述信号携带去往和来自计算机系统901的数字数据。
基带信号将数字数据作为描述数字数据位流的未调制电脉冲运送,其中术语“位”要被广义地解释为意味着符号,其中每一个符号运送至少一个或多个信息位。数字数据还可以用于调制载波,诸如在传导介质上传播或者通过传播介质作为电磁波传输的幅度、相位和/或频移键控信号。因此,数字数据可以通过“有线”通信信道作为未调制的基带数据发送和/或通过调制载波在与基带不同的预定频带内发送。计算机系统901可以通过(一个或多个)网络915和916、网络链路914和通信接口913传输和接收包括程序代码的数据。此外,网络链路914可以通过lan915向移动设备917(诸如,个人数字助理(pda)、膝上型计算机或蜂窝电话)提供连接。
本实施例具有许多应用,包括但不限于搜索和识别数据中的模式。
虽然已经描述某些实现,但是这些实现仅仅是作为示例给出,并且不旨在限制本公开的教导。实际上,可以用各种其它形式体现本文描述的新颖方法、装置和系统;此外,在不脱离本公开的精神的情况下,可以对本文描述的方法、装置和系统的形式做出各种省略、替换和改变。
权利要求书(按照条约第19条的修改)
1.一种使用自动化代理电路系统的技术信号和/或语义信号解释的方法,所述方法包括:
从原始数据流中获得原始数据;
根据测量量规对所述原始数据操作以生成测量结果;
基于可区分性度量确定第一信号指示符集,所述可区分性度量表示所述原始数据的所生成的测量结果之间的可区分性;
基于不可区分性度量确定第二信号指示符集,所述不可区分性度量表示所述原始数据的所生成的测量结果之间的不可区分性;
基于无知度量确定第三信号指示符集,所述无知度量表示对所述原始数据的所生成的测量结果的可区分性和不可区分性的无知;
通过向所述原始数据流应用所述第一信号指示符集来辨别所述原始数据流中的可区分性指示符以生成一个或多个可区分性数据流;
通过向所述原始数据流应用所述第二信号指示符集来辨别所述原始数据流中的不可区分性指示符以生成一个或多个不可区分性数据流;
通过向所述原始数据流应用所述第三信号指示符集来辨别所述原始数据流中的无知指示符以生成一个或多个无知数据流;
将所述一个或多个可区分性数据流、所述一个或多个不可区分性数据流以及所述一个或多个无知数据流进行结合以生成一个或多个语义边界指数;以及
使用所述一个或多个语义边界指数输出所述原始数据流的一个或多个技术解释和/或语义解释或者输出所述原始数据流的一个或多个技术确定和/或语义确定。
2.如权利要求1所述的方法,其中根据所述测量量规对所述原始数据操作还包括,所述测量量规是以下中的一个:金融或商品证券的技术指标、语义距离测量以及resnik测量。
3.如权利要求1所述的方法,其中确定所述第一信号指示符集通过以下方式执行:
根据所述测量结果确定模式集以生成训练数据,
将所述训练数据从原始数据空间映射到目标空间,并且所述目标空间是多维向量空间,
使用聚类确定所述训练数据的本体,所述训练数据对应于根据所述测量结果的所述模式集,
基于所述原始数据的解释接收参考模式,
确定所述训练数据的所述模式集与所述参考模式之间的相似性测量,
估计从所述原始数据空间到所述目标空间的第一映射集,第一相似性映射集的每一个映射基于所确定的相似性测量的对应的相似性测量,并且所述第一映射集包括所述第一符号指示符集。
4.如权利要求3所述的方法,其中使用几何非线性映射函数执行将所述训练数据从原始数据空间映射到目标空间,其中所述几何非线性映射函数是服从迭代限制的迭代函数系统。
5.如权利要求3所述的方法,其中使用所述聚类执行确定所述训练数据的本体,所述聚类是以下中的一个或多个:k-均值聚类方法以及基于距离测量的聚类方法。
6.如权利要求3所述的方法,其中使用pearson相关系数执行所述相似性测量的确定。
7.如权利要求3所述的方法,其中使用shepard插值函数执行基于所确定的相似性测量的从所述原始数据空间到所述目标空间的相似性映射的估计。
8.如权利要求3所述的方法,其中确定所述第二信号指示符集通过以下方式执行:
使用概念距离度量链接和/或聚类已映射的训练数据以生成所述目标空间中的多个聚类,每一个聚类分别根据相对于相应聚类的对应的基的不可区分性被链接和/或聚类,
对于所述目标空间中的每一个不相交的聚类,确定相应的参考模式的参考模式到所述目标空间的最接近映射,
对于所述多个聚类的每一个聚类,确定从所述原始数据空间到所述目标空间的第二映射集的映射,所述第二映射集的每一个映射对应于相对于所述多个聚类的相应聚类的所述第一映射集的无区别成员资格,以及
确定所述第二信号指示符集是从所述第一映射集到所述第二映射集的相应的映射。
9.如权利要求1所述的方法,其中通过获得所述第一信号指示符集与所述第二信号指示符集之间的并集的补集来执行确定所述第三信号指示符集。
10.如权利要求1所述的方法,所述方法还包括:
将所述第一信号指示符集、所述第二信号指示符集和所述第三信号指示符集形成组以生成对应于接收到的参考模式的通道,所述通道包括:
使用所述第一信号指示符集生成的第一数据流,
使用所述第二信号指示符集生成的第二数据流,以及
使用所述第三信号指示符集生成的第三数据流;
将所述第一数据流乘以对数函数以生成第一乘积,并且相对于时间微分所述第一乘积以生成第一尖峰列;
将所述第二数据流乘以对数函数以生成第二乘积,并且相对于时间微分所述第二乘积以生成第二尖峰列;以及
将所述第三数据流乘以对数函数以生成第三乘积,并且相对于时间微分所述第三乘积以生成第三尖峰列。
11.如权利要求10所述的方法,所述方法还包括:
通过相应的二进制值近似在第一时钟的每一个循环处的所述第一尖峰列的值;
通过相应的二进制值近似在第二时钟的每一个循环处的所述第二尖峰列;
通过相应的二进制值近似在第三时钟的每一个循环处的所述第三尖峰列;以及
将所述第一尖峰列、所述第二尖峰列和所述第三尖峰列的二进制值划分成时间加窗的二进制位码,所述时间加窗的二进制位码的每一个时间序列对应于所述一个或多个语义边界指数中的一个。
12.如权利要求11所述的方法,所述方法还包括:
确定相应的素数标识符以唯一地识别所述时间加窗的二进制位码,其中
所述相应的素数标识符与相应的时间加窗的二进制位码一起的组合包括所述一个或多个语义边界指数。
13.如权利要求11所述的方法,其中所述第一时钟、所述第二时钟和所述第三时钟分别是lamport时钟。
14.如权利要求1所述的方法,其中所述一个或多个语义边界指数包括用于生成另外的一个或多个语义边界指数的另外的原始数据流的原始数据。
15.如权利要求1所述的方法,其中所述一个或多个语义边界指数是使用来自是另外的一个或多个语义边界指数的原始数据流的原始数据生成的,所述另外的一个或多个语义边界指数是使用来自另外的原始数据流的原始数据生成的。
16.如权利要求1所述方法,其中来自用于生成所述一个或多个语义边界指数的原始数据流的原始数据包括所述一个或多个语义边界指数。
17.如权利要求1所述的方法,所述方法还包括:
获得另外的原始数据流;
基于另外的一个或多个可区分性数据流、另外的一个或多个不可区分性数据流和另外的一个或多个无知数据流生成另外的一个或多个语义边界指数,其中所述另外的原始数据流的所述另外的一个或多个可区分性数据流、另外的一个或多个不可区分性数据流和另外的一个或多个无知数据流是分别通过向所述另外的原始数据流应用另外的第一信号指示符集、另外的第二信号指示符集和另外的第三信号指示符集生成的;
使用所述另外的一个或多个语义边界指数和所述一个或多个语义边界指数之间的相似性来识别所述原始数据流和所述另外的原始数据流之间的预期类比;以及
使用类比推理引擎,根据所述原始数据流和所述另外的原始数据流之间的所述预期类比来确定所述原始数据流和所述另外的原始数据流之间的类比。
18.如权利要求1所述的方法,所述方法还包括:
获得另外的原始数据流;
基于另外的一个或多个可区分性数据流、另外的一个或多个不可区分性数据流和另外的一个或多个无知数据流生成另外的一个或多个语义边界指数,其中所述另外的原始数据流的所述另外的一个或多个可区分性数据流、另外的一个或多个不可区分性数据流和另外的一个或多个无知数据流是分别通过向所述另外的原始数据流应用另外的第一信号指示符集、另外的第二信号指示符集和另外的第三信号指示符集生成的;
生成所述原始数据流与所述另外的原始数据流之间的结构化关系以生成类比支架;以及
生成基于所述原始数据流预测事件的指示符,所述指示符是基于类比支架并且基于使用所述另外的原始数据预测其它事件的其它指示符生成的,其中所述其它指示符是先前获得的。
19.如权利要求1所述的方法,所述方法还包括:
使用所述一个或多个语义边界指数作为金融技术指标的输入来计算所述金融技术指标;以及
对所述一个或多个语义边界指数的所述金融技术指标执行金融投资组合分析,以预测由所述原始数据流标志的转变点和/或交叉点。
20.如权利要求1所述的方法,所述方法还包括:
获得另外的原始数据流;
基于另外的一个或多个可区分性数据流、另外的一个或多个不可区分性数据流和另外的一个或多个无知数据流生成另外的一个或多个语义边界指数,其中所述另外的原始数据流的所述另外的一个或多个可区分性数据流、另外的一个或多个不可区分性数据流和另外的一个或多个无知数据流是分别通过向所述另外的原始数据流应用另外的第一信号指示符集、另外的第二信号指示符集和另外的第三信号指示符集生成的;
通过确定以下中的一个或多个来使用所述另外的一个或多个语义边界指数和所述一个或多个语义边界指数之间的相似性来识别所述原始数据流和所述另外的原始数据流之间的预期类比:所述另外的一个或多个语义边界指数和所述一个或多个语义边界指数之间的相关性、所述另外的一个或多个语义边界指数和所述一个或多个语义边界指数的相应的指数之间的距离测量以及k-均值聚类方法。
21.如权利要求1所述的方法,所述方法还包括:
识别对应于所述原始数据流中的惊喜和/或异常事件的第一时间集;
识别对应于所述原始数据流中无惊喜和/或无异常事件的第二时间集;
基于所述一个或多个语义边界指数计算技术指标的移动平均;
执行所述移动平均的统计分析以识别相比于所述第二时间集期间所述第一时间集期间的所述移动平均的差异;以及
将所述移动平均的相应的惊喜阈值确定为所述第一时间集处的所述移动平均和所述第二时间集处的所述移动平均之间的对应的差异的预定部分;以及
将对应于超过所述惊喜阈值的所述原始数据流的移动平均的事件标志为是预期的惊喜和/或异常事件。
22.如权利要求21所述的方法,其中对所述移动平均执行的所述统计分析包括计算各种一个或多个语义边界指数的所述移动平均的偏度、所述移动平均的峰度、所述移动平均的偏差以及指数移动平均。
23.如权利要求1所述的方法,其中所述原始数据流是以下中的一个或多个:非结构化数据流、文本数据流、数值数据流、金融证券数据流以及物理测量的时间序列。
24.一种执行技术信号和/或语义信号解释的装置,所述装置包括:
自动化代理电路系统,被配置成:
从原始数据流中获得原始数据;
根据测量量规对所述原始数据操作以生成测量结果;
基于可区分性度量确定第一信号指示符集,所述可区分性度量表示所述原始数据的所生成的测量结果之间的可区分性;
基于不可区分性度量确定第二信号指示符集,所述不可区分性度量表示所述原始数据的所生成的测量结果之间的不可区分性;
基于无知度量确定第三信号指示符集,所述无知度量表示对所述原始数据的所生成的测量结果的可区分性和不可区分性的无知;
通过向所述原始数据流应用所述第一信号指示符集来检测所述原始数据流中的可区分性指示符以生成一个或多个可区分性数据流;
通过向所述原始数据流应用所述第二信号指示符集来检测所述原始数据流中的不可区分性指示符以生成一个或多个不可区分性数据流;
通过向所述原始数据流应用所述第三信号指示符集来检测所述原始数据流中的无知指示符以生成一个或多个无知数据流;
将所述一个或多个可区分性数据流、所述一个或多个不可区分性数据流以及所述一个或多个无知数据流进行结合以生成一个或多个语义边界指数;以及
使用所述一个或多个语义边界指数输出所述原始数据流的一个或多个技术解释和/或语义解释或者输出所述原始数据流的一个或多个技术确定和/或语义确定。
25.如权利要求24所述的装置,其中所述电路系统还被配置成根据所述测量量规对所述原始数据操作,使得所述测量量规是以下中的一个:金融或商品证券的技术指标、语义距离测量以及resnik测量。
26.如权利要求24所述的装置,其中所述电路系统还被配置成:
根据所述测量结果确定模式集以生成训练数据,
将所述训练数据从原始数据空间映射到目标空间,并且所述目标空间是多维向量空间,
使用聚类确定所述训练数据的本体,所述训练数据对应于根据所述测量结果的所述模式集,
基于所述原始数据的解释接收参考模式,
确定所述训练数据的所述模式集与所述参考模式之间的相似性测量,
估计从所述原始数据空间到所述目标空间的第一映射集,第一相似性映射集的每一个映射基于所确定的相似性测量的对应的相似性测量,并且所述第一映射集包括所述第一符号指示符集。
27.如权利要求26所述的装置,其中所述电路系统还被配置成使用几何非线性映射函数执行将所述训练数据从原始数据空间映射到目标空间,其中所述几何非线性映射函数是服从迭代限制的迭代函数系统。
28.如权利要求26所述的装置,其中所述电路系统还被配置成使用所述聚类执行确定所述训练数据的本体,所述聚类是以下中的一个或多个:k-均值聚类方法以及基于距离测量的聚类方法。
29.如权利要求26所述的装置,其中所述电路系统还被配置成使用pearson相关系数执行所述相似性测量的确定。
30.如权利要求26所述的装置,其中所述电路系统还被配置成通过以下方式执行所述第二信号指示符集的确定:
使用概念距离度量链接和/或聚类已映射的训练数据以生成所述目标空间中的多个聚类,每一个聚类分别根据相对于相应聚类的对应的基的不可区分性被链接和/或聚类,
对于所述目标空间中的每一个不相交的聚类,确定相应的参考模式的参考模式到所述目标空间的最接近映射,
对于所述多个聚类的每一个聚类,确定从所述原始数据空间到所述目标空间的第二映射集的映射,所述第二映射集的每一个映射对应于相对于所述多个聚类的相应聚类的所述第一映射集的无区别成员资格,以及
确定所述第二信号指示符集是从所述第一映射集到所述第二映射集的相应的映射。
31.如权利要求24所述的装置,其中所述电路系统还被配置成通过获得所述第一信号指示符集与所述第二信号指示符集之间的并集的补集来执行确定所述第三信号指示符集。
32.如权利要求24所述的装置,其中所述电路系统还被配置成:
将所述第一信号指示符集、所述第二信号指示符集和所述第三信号指示符集形成组以生成对应于接收到的参考模式的通道,所述通道包括:
使用所述第一信号指示符集生成的第一数据流,
使用所述第二信号指示符集生成的第二数据流,以及
使用所述第三信号指示符集生成的第三数据流;
将所述第一数据流乘以对数函数以生成第一乘积,并且相对于时间微分所述第一乘积以生成第一尖峰列;
将所述第二数据流乘以对数函数以生成第二乘积,并且相对于时间微分所述第二乘积以生成第二尖峰列;以及
将所述第三数据流乘以对数函数以生成第三乘积,并且相对于时间微分所述第三乘积以生成第三尖峰列。
33.如权利要求32所述的装置,其中所述电路系统还被配置成:
通过相应的二进制值近似在第一时钟的每一个循环处的所述第一尖峰列的值;
通过相应的二进制值近似在第二时钟的每一个循环处的所述第二尖峰列;
通过相应的二进制值近似在第三时钟的每一个循环处的所述第三尖峰列;以及
将所述第一尖峰列、所述第二尖峰列和所述第三尖峰列的二进制值划分成时间加窗的二进制位码,时间加窗的二进制位码的每一个时间序列对应于所述一个或多个语义边界指数中的一个。
34.如权利要求33所述的装置,其中所述电路系统还被配置成:
确定相应的素数标识符以唯一地识别所述时间加窗的二进制位码,其中
所述相应的素数标识符与相应的时间加窗的二进制位码一起的组合包括所述一个或多个语义边界指数。
35.如权利要求33所述的装置,其中所述电路系统还被配置成使用相应的lamport时钟作为所述第一时钟、所述第二时钟和所述第三时钟来执行所述第一时钟、所述第二时钟和所述第三时钟的近似。
36.如权利要求24所述的装置,其中所述一个或多个语义边界指数包括用于生成另外的一个或多个语义边界指数的另外的原始数据流的原始数据。
37.如权利要求24所述的装置,其中所述一个或多个语义边界指数是使用来自是另外的一个或多个语义边界指数的原始数据流的原始数据生成的,所述另外的一个或多个语义边界指数是使用来自另外的原始数据流的原始数据生成的。
38.如权利要求24所述的装置,其中来自用于生成所述一个或多个语义边界指数的原始数据流的原始数据包括所述一个或多个语义边界指数。
39.如权利要求24所述的装置,其中所述电路系统还被配置成:
获得另外的原始数据流;
基于另外的一个或多个可区分性数据流、另外的一个或多个不可区分性数据流和另外的一个或多个无知数据流生成另外的一个或多个语义边界指数,其中所述另外的原始数据流的所述另外的一个或多个可区分性数据流、另外的一个或多个不可区分性数据流和另外的一个或多个无知数据流是分别通过向所述另外的原始数据流应用另外的第一信号指示符集、另外的第二信号指示符集和另外的第三信号指示符集生成的;
使用所述另外的一个或多个语义边界指数和所述一个或多个语义边界指数之间的相似性来识别所述原始数据流和所述另外的原始数据流之间的预期类比;以及
使用类比推理引擎,根据所述原始数据流和所述另外的原始数据流之间的所述预期类比来确定所述原始数据流和所述另外的原始数据流之间的类比。
40.如权利要求24所述的装置,其中所述电路系统还被配置成:
获得另外的原始数据流;
基于另外的一个或多个可区分性数据流、另外的一个或多个不可区分性数据流和另外的一个或多个无知数据流生成另外的一个或多个语义边界指数,其中所述另外的原始数据流的所述另外的一个或多个可区分性数据流、另外的一个或多个不可区分性数据流和另外的一个或多个无知数据流是分别通过向所述另外的原始数据流应用另外的第一信号指示符集、另外的第二信号指示符集和另外的第三信号指示符集生成的;
生成所述原始数据流与所述另外的原始数据流之间的结构化关系以生成类比支架;以及
生成基于所述原始数据流预测事件的指示符,所述指示符是基于类比支架并且基于使用另外的原始数据预测其它事件的其它指示符生成的,其中所述其它指示符是先前获得的。
41.如权利要求24所述的装置,其中所述电路系统还被配置成:
使用所述一个或多个语义边界指数作为金融技术指标的输入来计算所述金融技术指标;以及
对所述一个或多个语义边界指数的所述金融技术指标执行金融投资组合分析,以预测由所述原始数据流标志的转变点和/或交叉点。
42.一种包括可执行指令的非瞬态计算机可读存储介质,其中当所述指令被电路系统执行时,使得所述电路系统执行以下步骤:
从原始数据流中获得原始数据;
根据测量量规对所述原始数据操作以生成测量结果;
基于可区分性度量确定第一信号指示符集,所述可区分性度量表示所述原始数据的所生成的测量之间的可区分性;
基于不可区分性度量确定第二信号指示符集,所述不可区分性度量表示所述原始数据的所生成的测量结果之间的不可区分性;
基于无知度量确定第三信号指示符集,所述无知度量表示对所述原始数据的所生成的测量结果的可区分性和不可区分性的无知;
通过向所述原始数据流应用所述第一信号指示符集来辨别所述原始数据流中的可区分性指示符以生成一个或多个可区分性数据流;
通过向所述原始数据流应用所述第二信号指示符集来辨别所述原始数据流中的不可区分性指示符以生成一个或多个不可区分性数据流;
通过向所述原始数据流应用所述第三信号指示符集来辨别所述原始数据流中的无知指示符以生成一个或多个无知数据流;
将所述一个或多个可区分性数据流、所述一个或多个不可区分性数据流以及所述一个或多个无知数据流进行结合以生成一个或多个语义边界指数;以及
使用所述一个或多个语义边界指数输出所述原始数据流的一个或多个技术解释和/或语义解释或者输出所述原始数据流的一个或多个技术确定和/或语义确定。
43.如权利要求1所述的方法,其中从所述原始数据流获得的所述原始数据是非结构化数据。
- 还没有人留言评论。精彩留言会获得点赞!