一种科技项目查重对比的方法与流程
本发明一种科技项目查重对比的方法涉及信息内容相似度的查重的方法,尤其是涉及利用科技立项过程中确定申请的文件材料是否重复的查重的方法。
背景技术:
为了避免在科技项目和科技成果的重复申报而导致的科研经费浪费现象,在科技项目和科技成果的申报审核过程中,主要依靠人工审查方式和通过将项目申报书关键词集与项目数据库做简单比对这两种查重方式,将重复申报的项目从大量上报的项目中筛选出来。这两种筛选方式虽然也能够在一定程度上减少科研项目的重复申报,但是仍然存在效率低下和容易出现错判、漏判的缺点。特别是简单比对项目申报书关键词集的查重方式,一旦申报者更换标题或将项目申报书的内容稍加改变,则能够轻易避开查重系统。针对这一问题,国内部分科技项目管理系统尝试将历年申报的项目数据库中的数据与新上报的项目数据做进行简单分析比较,但是可靠性较差。
技术实现要素:
本发明所要解决的技术问题是提供一种项目查重比对系统及方法,提高科技项目查重比对的效率,解决现有技术中难以对重复申报的科技项目做出有效检测的技术问题。
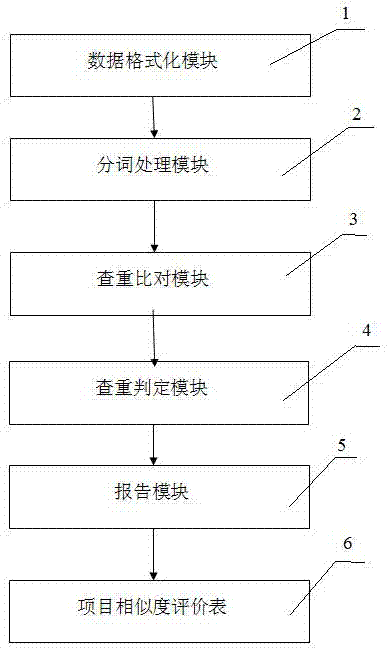
具体的技术方案为:一种科技项目查重对比的方法,其特殊之处在于,是通过下述步骤实现的:将待比对的项目和已知的项目这两个项目输入数据格式化模块,并依次通过分词处理模块、查重比对模块、查重判定模块、报告模块,最终获得项目相似度评价表;
A,数据格式化模块:将两个项目中各个字段信息使用UTF-8编码进行格式化编码;
B,文本判定模块:计算数据格式化模块格式化后文本的大小,当大于150字节,则标记为长文本,否则标记短文本;
C,分词处理模块:对格式化后的项目各个字段信息分词,并将分词后的字段特征文本以字段名为标签存入项目比对文件(XML格式) 形成特征词集合,且分词处理模块中还分为长文本分词模块和短文本分词模块;长文本分词模块:对长文本进行分词,分词采用Simhash算法,得到特征词对,其中包括特征词和权重,权重通过计算每个特征词在文本中的出现次数得出;短文本分词模块:对短文本进行分词,分词采用Shingle算法,对于段文本长度为L,每隔N个字符切一个特征词,如此切下去一共可以得到L-N+1个特征词(根据科技项目的特点,一般取N=10);
D,查重比对模块:依次取出两个项目比对文件中相同字段名标签下的特征词文本,为两个项目的逐项比对做好准备;长文本比对模块:先取两个项目相同字段名标签下的特征词对集合,分别采用64位Simhash方法处理这两个集合,分别生成指纹签名集,比较这两个指纹签名集的海明距离来判定项目的相似度;短文本比对模块:先取两个项目相同字段名标签下Shingle特征词集合A和B的交集,然后除以两个集合A和B的并集,计算出jaccard系数,将J与0.3比较, 若J大于0.3则判断两项目该字段内容相似(相似度值为1);
E,查重判定模块:根据项目各个字段的相似度值和比对数据库中项目权重评价表与之对应的项目各个字段的权重(各字段权重之和等于1),使用模糊综合评价法对两个项目进行相似度比较,当两个项目的相似度大于0.7,则判断两个项目相似;
F,报告模块:将两个项目的查重判定结果生成报告页返回给用户,若两个项目相似,则报告页面将逐条显示两个项目的相似内容;
G,项目相似度评价表:记录在比对数据库中,记录项目各比对字段的相似度值和最终查重结果,当两个项目相似,记为1,否则记为0。
为了能够更好的实现本发明的目的,提供更加准确的查重结果,可以将上述的技术方案,进一步的改进:
其改进点在于,在所述的数据格式化模块之前设置有比对检索模块,所述的比对检索模块是根据项目编号在对比数据库中查询,若项目以前比对过,则从库中直接取出该项目的分词信息,生成项目比对文件,不再进行分词处理。在所述的查重判定模块和报告模块之间设置比对存储模块,所述的比对存储模块将两个项目比对文件中的字段标签下的特征词文本和查重判定结果存储到比对数据库中备查。
本发明与现有技术相比具有如下的优点:
本发明的科技项目查重比对方法根据项目字段的大小分别利用两种分词比对方法对科技项目关键字段进行查重比对,并通过模糊综合评价法综合计算项目中关键项目字段的相似度信息从而判定出两个项目的是否重复,与传统的科技项目人工比对方式以及通过将项目申报书关键词集与项目数据库做简单比对等方式相比提高了项目查重准确率,减少了科技项目查重过程中容易出现的误判、漏判现象,本发明对于科技项目查重判定具有量化和统一的评价体系和标准,对项目相似度比较能够做出科学规范的判断。
附图说明
图1为本发明一种科技项目查重对比的方法的实施例1的结构示意图。
图2为本发明一种科技项目查重对比的方法的实施例2的结构示意图。
具体实施方式
下面结合附图,对本发明的技术方案加以解释:
一种科技项目查重对比的方法(图1),是通过下述步骤实现的:将待比对的项目和已知的项目输入数据格式化模块1,并依此通过分词处理模块2、查重比对模块3、查重判定模块4、报告模块5,最终获得项目相似度评价表6;
A,数据格式化模块:将项目中各个字段信息使用UTF-8编码进行格式化编码;
B,文本判定模块:计算数据格式化模块格式化后文本的大小,若大于150字节,则标记为长文本,否则标记短文本;
C,分词处理模块:对格式化后的项目各个字段信息分词,并将分词后的字段特征文本以字段名为标签存入项目比对文件(XML格式) 形成特征词集合,且分词处理模块中还分为长文本分词模块和短文本分词模块;长文本分词模块:对长文本进行分词,分词采用Simhash算法,得到特征词对,其中包括特征词和权重,权重通过计算每个特征词在文本中的出现次数得出;短文本分词模块:对短文本进行分词,分词采用Shingle算法,对于段文本长度为L,每隔N个字符切一个特征词,如此切下去一共可以得到L-N+1个特征词(根据科技项目的特点,一般取N=10);
D,查重比对模块:依次取出两个项目比对文件中相同字段名标签下的特征词文本,为两个项目的逐项比对做好准备;长文本比对模块:先取两个项目相同字段名标签下的特征词对集合,分别采用64位Simhash方法处理这两个集合,分别生成指纹签名集,比较这两个指纹签名集的海明距离来判定项目的相似度;短文本比对模块:先取两个项目相同字段名标签下Shingle特征词集合(分别标记为A和B)的交集,然后除以两个集合A和B的并集,计算出jaccard系数,将J与0.3比较, 若J大于0.3则判断两项目该字段内容相似(相似度值为1);
E,查重判定模块:根据项目各个字段的相似度值和比对数据库中项目权重评价表与之对应的项目各个字段的权重(各字段权重之和等于1),使用模糊综合评价法对两个项目进行相似度比较,当两个项目的相似度大于0.7,则判断两个项目相似;模糊综合评价法基于模糊数学,能够对受到多种因素制约的事物或对象做出一个总体的评价。它具有结果清晰,系统性强的特点,能较好地解决模糊的、难以量化的问题,适合各种非确定性问题的解决。在科技项目查重对比中运用模糊综合评价法,可以在评判两个项目单个影响因素如项目名称、项目主要内容、主要研究内容、主要创新点先进性、研究方法和技术路线等的相似度的基础上,据此进一步做出针对两个项目的整体相似度评判。解决了以往科技项目查重对比过程中仅注重单个因素的评判,不能做整体相似性评判的问题,提高了科技项目查重对比的准确率。
F,报告模块:将两个项目的查重判定结果生成报告页返回给用户,若两个项目相似,则报告页面将逐条显示两个项目的相似内容;
G,项目相似度评价表:记录在比对数据库中,记录项目各比对字段的相似度值和最终查重结果,如果两个项目相似,记为1,否则记为0。
实施例2
为了能够更好的实现本发明的目的,避免以前做过比对的项目重复做分词处理,提高查重效率,可以将实施1所述的技术方案,进一步的改进(参见图2):在所述的数据格式化模块1之前设置有比对检索模块7,所述的比对检索模块是根据项目编号在对比数据库中查询,若项目以前比对过,则从库中直接取出该项目的分词信息,生成项目比对文件,不再进行分词处理。在所述的查重判定模块4和报告模块5之间设置比对存储模块8,所述的比对存储模块将两个项目比对文件中的字段标签下的特征词文本和查重判定结果存储到比对数据库中备查。
- 还没有人留言评论。精彩留言会获得点赞!