一种基于LDA与退火算法组合的推荐技术的制作方法
本发明涉及商务网站的一种基于文档内容推荐的技术领域,特别涉及一种基lda模型与退火算法组合的推荐算法。
背景技术:
从互联网的诞生开始,各类信息技术迅猛发展,电子商务、网上服务等网络业务越来越普及,当然,这些网络业务积累的信息也越来越庞大,用户想从这海量的信息中快速准确地寻找到自己感兴趣的信息已经变得越来越困难。为了解决这个问题,百度、google等搜索引擎就应运而生了,客户可以方便地针对自己想要的快速搜索到相关信息。但是,在客户无法准确描述自己需求时,即不清楚自己所要信息的关键词时,搜索引擎就无能为力了。
且在实际上,用数学语言描述需求:我们的需求并不是绝对的只是有限的一个点,而往往是一个无边界的邻域,即对信息的需求往往没有明确界定边界。这是因为看似无关的信息间往往是存在藕断丝连关系的。简单来说,就是需求往往会衍生出需求。
如此,在这个信息时代中,便有商家悟到其中道理,从而根据客户的需求,向客户推荐出可能的需求。这便是推荐技术的中心思想。推荐技术使得客户在满足自己需求后发现自己一些潜在的需求,从而较全面的完成需求,而这同时也为商家带来一定利益,故而达到双赢。尽管现在的推荐算法多种多样,但是这个中心思想是不变的。
技术实现要素:
本发明针对商务网站提出的一种基于文档内容的推荐技术,从文档内容的角度出发,对文档内容进行分类,提出结合基于文档内容lda主题分析算法与退火算法,向用户推荐相似文档,供参考阅读。
本发明使用lda算法,本质上是一种文档聚类的算法,通过提取文档主题,对各文档文档的主题分布进行研究,将主题分布偏离度低的文档聚为一类。如此通过用户浏览过的历史文档主题分析,找到与其同属一类的其他文档,可根据偏离度最低的文档对用户进行推荐文档。
文档选择了退火算法代替相似度的计算,依据这样一个事实:在实际应用推荐系统中,商品(本发明主要指文档文档)类目过多,因此构建的文档—词矩阵是一个具有高度稀疏性的矩阵,在计算相似度过程中,时间和空间复制度都很高。
所述的基于lda与退火算法的组合推荐算法具体步骤如下:
1)采用gibbs抽样构建主题—文档矩阵和主题—词矩阵,得到历史浏览文档的多维主题分布φnew,从多维主题分布φnew中抽出k个具有高峰分布的主题作为这些文档的代表主题{zk}rep
2)采用一次退火算法在所有文档中筛选出在代表主题上的分布满足一定条件的历史文档作为备选文档
3)再采用第二次不同的退火算法从这些备选文档中筛选出来h篇与历史浏览文档在对应的代表主题上有较高相似度的文档作为最终推荐文档。
4)模型评价,本发明选择的lda算法与退火算法组合推荐模型与单独采用lda主题分析模型进行了对比分析。
本发明提出的基于lda算法与退火算法组合推荐模型,经验证(见后文算法),效果明显优于单独采用lda主题分析模型。本发明文档选择了退火算法代替相似度的计算。退火算法本身,是一个简单的寻找近似全局最优的算法,操作简单方便,运行快捷,用来寻找有限篇文档的推荐非常合适。并且本发明采用了两次退火算法,第一次是筛选,第二次才是真正的寻优,如此安排在后面实验中也表明,运行时效和结果准确率都有所提高。
附图说明
图1本发明实施步骤流程图;
图2步骤1历史浏览文档主题词汇频数分布图;
图3步骤1历史未浏览文档1的主题词汇频数分布图;
图4步骤1历史未浏览文档2的主题词汇频数分布图;
图5本发明算法与传统算法的平均相似度曲线比较图;
图6本发明算法与传统算法的困惑度曲线比较图。
具体实施方式
具体步骤如下:
步骤1:采用gibbs抽样构建主题—文档矩阵和主题—词矩阵,得到历史浏览文档的多维主题分布φnew,从多维主题分布φnew中抽出k个具有高峰分布的主题作为这些文档的代表主题{zk}rep
步骤2:采用一次退火算法在所有文档中筛选出在代表主题上的分布满足一定条件的历史文档作为备选文档
步骤3:再采用第二次不同的退火算法从这些备选文档中筛选出来h篇与历史浏览文档在对应的代表主题上有较高相似度的文档作为最终推荐文档。
步骤4:模型评价,本发明选择的lda算法与退火算法组合推荐模型与单独采用lda主题分析模型进行了对比分析。
本发明提出的基于lda算法与退火算法组合推荐模型,经验证(见后文算法),效果明显优于单独采用lda主题分析模型。本发明文档选择了退火算法代替相似度的计算。退火算法本身,是一个简单的寻找近似全局最优的算法,操作简单方便,运行快捷,用来寻找有限篇文档的推荐非常合适。并且本发明采用了两次退火算法,第一次是筛选,第二次才是真正的寻优,如此安排在后面实验中也表明,运行时效和结果准确率都有所提高
所述的步骤1具体说明如下:
抽取文档数据如下表所示:
对文档主题建模的方法便是将主题视为词汇的概率分布。假设有k个主题
若假设这k个主题形成m篇文档,共有w个词汇,则记
对主题变量
关于上述符号说明如下:
上述后验概率分布公式中i=(m,n)是一个二维下标,对应的是第m篇文档的第n个词,zi
就表示这个词对应的主题。而用/i表示去除下标为i的词,故:
而
gibbs抽样算法过程简述如下:
(1)初始化zi为1到k之间的某个随机整数k,i从(1,1)循环到(m,nm),m是文档的总篇数,nm是第m篇文档的词数(即是所有词汇的频数和)。
(2)根据(式3)按i从(1,1)循环到(m,nm)将下标为i的词汇
(3)对(2)迭代一定次数后,取i从(1,1)循环到(m,nm)的每个zi的当前值记录为样本。
由(3)得到的样本可以统计得到一个主题与词汇共现的频数分布矩阵,该矩阵就是lda模型,如下矩阵表1:
其中,n为单一性词汇数,n(k,n)表示为
同时也可以统计得到文档与主题共现的频数分布矩阵,如下表2:
其中,n(m,k)表示为
其中,
有了lda模型,我们可以再根据(式3)对历史浏览文档中的每一个词按照上述gibbs抽样过程对历史浏览文档进行主题分析,从而得到历史浏览文档的主题与词汇频数分布矩阵
所述的步骤2的子步骤具体说明如下:
本发明在得到文档主题分布后,先采用一次退火算法根据主题分布从所有未浏览文档中筛选出与历史浏览文档有相似主题高峰分布的文档,如此大大降低文档基数,以便第二次退火算法的运行。
退火算法过程如下:
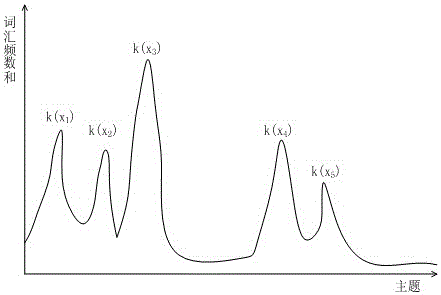
(1)采用带有记忆的退火算法确定历史浏览文档主题分布中的几个高峰的峰值主题:如图1,历史浏览文档有5个高峰分布区间,它们对应的峰值主题分别为:k(x1)、k(x2)、k(x3)、k(x4)、k(x5)。其中x1<x2<x3<x4<x5是主题编号1、2、…、k中的数。
该步骤是采用有记忆的退火算法,在寻找最优的过程保留每个局部最优,最后可得到峰值比较式:k(x3)>k(x1)>k(x4)>k(x2)>k(x5)。如图2所示
(2)确定历史浏览文档的代表主题:
先判断最大峰值n(k(x3))是否大于等于上界,若是,则进行以下(2.1)。若不,则进行以下(2.2)。
(2.1)判断最小峰值k(x5)是否大于等于上界,若小于则舍去该峰值k(x5),继续判断排序第四的峰值k(x2)是否大于等于上界,若小于则舍去,继续判断排序第三的峰值k(x4)是否大于等于上界,若小于则舍去,继续判断排序第二的峰值k(x1)是否大于等于上界,若小于则舍去。最后剩下排序第一的峰值k(x3),显然该峰值是大于等于上界的,且该峰值附近很大可能存在频数值大于上界的主题,故可在该峰值主题左右选出四个依次小于该峰值的频数值对应的主题k(y1)、k(y2)、k(y3)、k(y4),同样判断这些频数值是否大于上界,小于等于的则舍去,保留下来的主题加上第一峰值k(x3)共同作为该历史浏览文档的代表主题{z5}rep。
若最小峰值k(x5)大于等于上界,则这五个峰值主题共同作为历史浏览文档的代表主题{z5}rep;若排序第四的峰值k(x2)大于等于上界,则在第一峰值k(x3)左右取一个依次小于k(x3)的频数值对应的主题。如此类推下去。
说明:这里的上界即是箱形图里的上界。
(2.2)按照(2.1)将上界换成上四分位数进行。
假设得到历史浏览文档的代表主题就是k(x3)、k(x1)、k(x4)、k(x2)、k(x5)。
(3)从历史文档中筛选出相关文档:根据历史浏览文档的代表主题,对历史文档做如下筛选:依次判断历史文档的主题k(x3)、k(x1)、k(x4)、k(x2)、k(x5)的频数值是否大于该分档词汇频数值的上四分位数,只要其中一个满足,则将该历史文档筛选出来作为推荐的备选文档。
所述的步骤3的子步骤具体说明如下:
采用退火算法确定与历史浏览文档最相似的历史文档组合:假设备选文档有l篇,要从中选取h篇作为历史浏览文档的最相似推荐,其中1<h<l。则有c(l,h)种组合法。但采用退火算法则显然不用每种都尝试,下面是退火算法的应用过程:
(1)确定目标函数:设历史浏览文档与备选文档di对应的代表主题和非代表主题分别求余弦相似度
则退火算法的目的就是寻找推荐的h篇文档的相似程度和最大,故退火算法的目标函数为:
令
(2)初始化:
取初始解s0为备选文档中依次的前h篇
取初始状态t0=
(3)确定随机移动准则:
本发明采用metropolis准则,随机移动接受概率如下:
(4)新解产生方式:
随机从1到h中取两个数s和g,然后从当前解以外的所有文档中随机抽取两篇文档代替这两个随机数对应的文档构成新解,根据目标函数和随机移动准则对新解进行分析接受情况并对所得到的目标函数值对应新解记忆保留,循环直至接受概率趋近0时,取所有得到的目标函数值中最大的值对应的组合解作为最终解。
以下是两种与历史浏览文档相似度不同的文档图示,图2的文档doc(x)与历史浏览文档的相似性比图3的文档doc(y)高。
所述的步骤4具体说明如下:
如下表所示(按相似度降序排序):
下面便采用平均相似度分析两种不同算法推荐出的各文档与原文档的主题相似度,以及用困惑度分析推荐文档的混乱程度,以此评估两种算法模型的性能。混乱程度越小,说明文档符合推荐文档的概率越大,推荐算法模型的性能更优。
平均相似度公式如下所示:
其中,
(式8)中的
困惑度公式如下所示:
其中,
所求得的两种算法模型的平均相似度曲线如图5所示。本发明算法所求的平均相似度都明显高于普通算法所求的,这说明在针对有代表性的主要主题,本发明采用的算法是具有更高的准确性的
困惑度越小表明模型对文档的预测能力越强,泛化性能也越强。由图6可见,两种算法模型的困惑度在后面趋于平稳,而推荐篇数超过2后,本发明算法模型的困惑度明显小于普通算法,而且本发明算法模型的困惑度曲线整体较平稳,不像普通算法模型的困惑度曲线一样跨度大。这验证了本发明算法模型的推荐性能比普通算法的好。
综上所述,本发明提出的一种基于lda与退火算法的组合推荐算法在文档推荐上是较高效的。该算法针对文档,根据lda对历史文档的主题分析,得到历史浏览文档的多维主题分布φnew,从多维主题分布φnew中抽出具有高峰分布的主题作为该历史浏览文档的代表主题,然后采用一次退火算法在所有文档中筛选出在代表主题上的分布满足一定条件的历史文档作为备选文档,然后在采用第二次不同的退火算法从这些备选文档中筛选出来h篇与历史浏览文档在对应的代表主题上有较高相似度的文档作为最终推荐文档。经验证,本发明所提出的算法无论在性能上还是运行速度上都高于普通算法。
- 还没有人留言评论。精彩留言会获得点赞!