一种深度估计方法、系统及电子设备与流程
本发明涉及深度估计领域,尤其涉及一种深度估计方法、系统及电子设备。
背景技术:
3DRS(3-Dimension Recursive Search,三维递归搜索)算法是一种运动估计算法,由Gerard de Haan在1993年于《True-Motion Estimation with 3-D Recursive Search Block Matching》一文中提出。原文中的3DRS首先以块(block)为单位计算图像与参考图像之间的差异,然后通过块腐蚀(Block Erosion)方法将块网格(block grid)下的运动场(Motion Field)或差异场(Displacement Field)扩展为像素网格(Pixel grid)下的最终结果。最初3DRS所指的递归是图像空间上,最初并无迭代的做法,其收敛方向由其估计器(Estimator)及搜索方向决定。
3DRS提出之后的改进保留了其基本思想。通过改进原算法中的ACS(asynchronous cyclic search)表《Sub-pixel motion estimation with 3D Recursive block matching》,与金字塔表达(Pyramidal Representation)的结合《Optimization of Hierarchical 3DRS Motion Estimators for Picture Rate Conversion》等方法,形成了具有亚像素精度的多层3DRS算法(Hierarchical 3DRS)。
深度估计问题是实现3D自动转换的核心问题。3D自动转换,指将传统3D左右图格式,转换成可用于多角度(Multi-view)3D图像生成的2D+Z(深度)格式。深度估计的主要方法之一是基于视差(Disparity)与深度之间联系,通过检测左右图间的差异(Displacement),得到所需要的深度信息(Depth Map)。像素递归算法,如3DRS(3Dimension recursive search),具有运算量小、易于并行处理与硬件实现等特点,较能满足深度估计应用中对实时性的需求。
深度估计算法以像素递归算法(3DRS)为核心,由于其估计依赖于块内的特征,3DRS在均匀性图像区域,即缺少特征区域(以下称为均匀区域),存在容易发生估计错误的特点。且由于3DRS在空间上收敛的特性,3DRS存在将均匀性区域错误估计向外扩散的特点。如何在深度估计时达到减少3DRS在均匀区域的误差,是业界亟需解决的问题。
技术实现要素:
本发明提供了具有噪声填充预处理的深度估计方法及系统,用于解决的3DRS存在将均匀性区域发生估计错误而向外扩散的问题。
本发明实施例采用以下技术方案:
第一方面,本发明提供了一种深度估计方法,该方法包括:
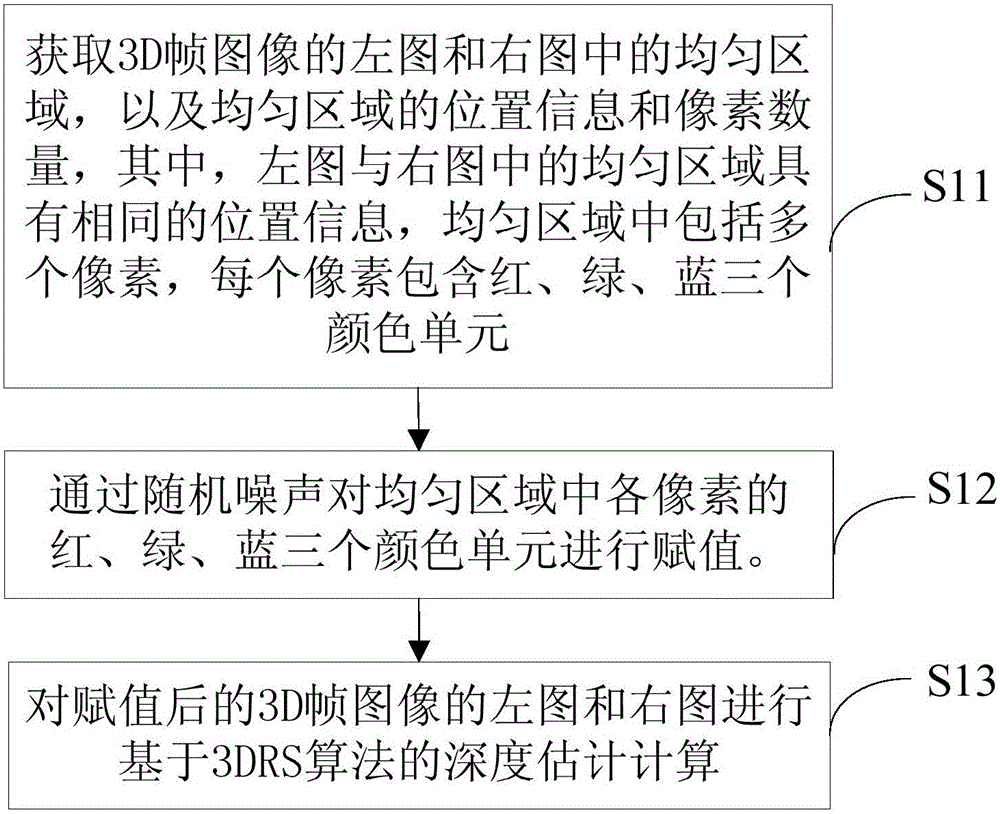
获取3D帧图像的左图和右图中的均匀区域,以及均匀区域的位置信息和像素数量,其中,所述左图与右图中的均匀区域具有相同的位置信息,所述均匀区域中包括多个像素,每个所述像素包含红、绿、蓝三个颜色单元;
通过随机噪声对所述均匀区域中各像素的红、绿、蓝三个颜色单元进行赋值;
对赋值后的3D帧图像的左图和右图进行基于3DRS算法的深度估计计算。
优选的,所述通过随机噪声对所述均匀区域中各像素的红、绿、蓝三个颜色单元进行赋值,包括:
形成红、绿、蓝三个颜色通道,分别生成红、绿、蓝三个颜色通道的随机噪声信号和随机相位信号;
分别从所述红、绿、蓝三个颜色通道的随机相位信号中读取随机相位信号值作为起始相位,在对应颜色通道的随机噪声信号中从所述起始相位开始逐个读取噪声信号值,根据所述均匀区域的位置信息和像素数量,将读取到的噪声信号值赋给到所述3D帧图像的左图和右图的均匀区域中各像素的对应颜色单元。
优选的,所述随机噪声信号长度为L,所述随机相位信号长度为M,L和M的取值满足:L,M∈{x|x=2n-1,n∈N}。
优选的,所述分别生成红、绿、蓝三个颜色通道的随机噪声信号和随机相位信号,具体为:通过均匀分布函数分别生成红、绿、蓝三个颜色通道的随机噪声信号和随机相位信号。
优选的,所述从所述红、绿、蓝三个颜色通道的随机相位信号中读取随机相位信号值作为起始相位,具体为:
从所述红、绿、蓝三个颜色通道的随机相位信号中顺序循环读取相位信号值作为起始相位;
所述在对应颜色通道的随机噪声信号中从所述起始相位开始逐个读取噪声信号值,根据所述均匀区域的位置信息和像素数量,将读取到的噪声信号值赋给到所述3D帧图像的左图和右图的均匀区域中各像素的对应颜色单元,具体为:
分别确定红、绿、蓝三个颜色通道的当前起始相位,在对应颜色通道的随机噪声信号中从所述当前初始相位开始逐个读取所有噪声信号值,根据所述均匀区域的位置信息将读取到的噪声信号值赋给所述3D帧图像的左图和右图的均匀区域中各像素的对应颜色单元;每个像素被赋值后均判断赋值的噪声信号值的数量是否等于所述像素数量,若否,且有剩余噪声信号值,则继续赋值;若否,且所有噪声信号值均已赋值,则将下一相位值更新为当前起始相位,返回执行赋值操作;若是,则停止赋值。
优选的,所述对赋值后的所述3D帧图像的左图和右图进行基于3DRS算法的深度估计计算,具体为:
根据赋值后的3D帧图像的左图和右图分别搭建预设层数的图像金字塔,根据所述图像金字塔生成预设块尺寸的块网格差异场金字塔;
根据预设的估计器逐层使用预设搜索路径对各层块网格差异场金字塔完成预设迭代次数的多层3DRS块估计迭代计算,得到块网格差异场金字塔中最底层的各块差异估计值;
根据所述块网格差异场金字塔中最底层的各块差异估计值生成深度图。
第二方面,本发明还提供了一种深度估计系统,该系统包括:
区域信息获取单元,用于获取3D帧图像的左图和右图中的均匀区域,以及均匀区域的位置信息和像素数量,其中,所述左图与右图中的均匀区域具有相同的位置信息,所述均匀区域中包括多个像素,每个所述像素包含红、绿、蓝三个颜色单元;
赋值单元,用于通过随机噪声对所述均匀区域中各像素的红、绿、蓝三个颜色单元进行赋值;
深度估计单元,用于对赋值后的3D帧图像的左图和右图进行基于3DRS算法的深度估计计算。
优选的,赋值单元包括:
信号生成模块,用于形成红、绿、蓝三个颜色通道,分别生成红、绿、蓝三个颜色通道的随机噪声信号和随机相位信号;
赋值模块,用于分别从所述红、绿、蓝三个颜色通道的随机相位信号中读取随机相位信号值作为起始相位,在对应颜色通道的随机噪声信号中从所述起始相位开始逐个读取噪声信号值,根据所述均匀区域的位置信息和像素数量,将读取到的噪声信号值赋给到所述3D帧图像的左图和右图的均匀区域中各像素的对应颜色单元。
优选的,所述随机噪声信号长度为L,所述随机噪声信号长度为M,L和M的取值满足:L,M∈{x|x=2n-1,n∈N}。
优选的,所述信号生成模块,用于,具体用于:通过均匀分布函数分别生成红、绿、蓝三个颜色通道的随机噪声信号和随机相位信号。
优选的,所述赋值模块,用于:从所述红、绿、蓝三个颜色通道的随机相位信号中顺序循环读取相位信号值作为起始相位;
分别确定红、绿、蓝三个颜色通道的当前起始相位,在对应颜色通道的随机噪声信号中从所述当前初始相位开始逐个读取所有噪声信号值,根据所述均匀区域的位置信息将读取到的噪声信号值赋给所述3D帧图像的左图和右图的均匀区域中各像素的对应颜色单元;每个像素被赋值后均判断赋值的噪声信号值的数量是否等于所述像素数量,若否,且有剩余噪声信号值,则继续赋值;若否,且所有噪声信号值均已赋值,则将下一相位值更新为当前起始相位,返回执行赋值操作;若是,则停止赋值。
优选的,所述深度估计单元包括金字塔生成模块、迭代计算模块和深度图生成模块;
所述金字塔生成模块,用于:根据赋值后的3D帧图像的左图和右图分别搭建预设层数的图像金字塔,根据所述图像金字塔生成预设块尺寸的块网格差异场金字塔;
所述迭代计算模块,用于:根据预设的估计器逐层使用预设搜索路径对各层块网格差异场金字塔完成预设迭代次数的多层3DRS块估计迭代计算,得到块网格差异场金字塔中最底层的各块差异估计值;
所述深度图生成模块,用于:根据所述块网格差异场金字塔中最底层的各块差异估计值生成深度图。
第三方面,本发明还提供了一种电子设备,包括上述第二方面所述的一种深度估计系统。
与现有技术相比,本发明提供的一种深度估计方法、系统及电子设备,具有以下有益效果:
本发明通过在均匀区域中赋值噪音后在进行3DRS深度估计计算,通过扩大均匀区域中像素间的差异,减少因3DRS算法造成的估计错误。
附图说明
图1是本发明提供的一种深度估计方法的第一个实施例的方法流程图。
图2是本发明提供的一种深度估计方法的第二个实施例的方法流程图一。
图3是本发明提供的一种深度估计方法的第二个实施例的方法流程图二。
图4是本发明提供的一种深度估计系统的第一个实施例的结构框图。
图5是本发明提供的一种深度估计系统的第二个实施例的结构框图。
图6是本发明提供的一种深度估计方法及系统实例的噪声信道提取数据图一。
图7是本发明提供的一种深度估计方法及系统实例的噪声信道提取数据图二。
具体实施方式
为使本发明解决的技术问题、采用的技术方案和达到的技术效果更加清楚,下面将结合附图对本发明实施例的技术方案作进一步的详细描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1示出根据本发明提供的一种深度估计方法第一个实施例的方法流程图。本实施例的一种深度估计方法主要适用于通过3DRS算法进行深度估计的情况,该方法由一种深度估计系统来执行,该系统主要由电子设备硬件和软件配合执行。其中,电子设备可以为个人电脑、笔记本电脑、手机、平板电脑等,且电子设备中带有处理器,该方法包括以下步骤:
S11:获取3D帧图像的左图和右图中的均匀区域,以及均匀区域的位置信息和像素数量,其中,左图与右图中的均匀区域具有相同的位置信息,均匀区域中包括多个像素,每个像素包含红、绿、蓝三个颜色单元。
其中,均匀区域可以为用户设置的,或者也可以为系统自动判断识别得到的。均匀区域是指3D帧图像的左图和右图中各像素之间没有差异的区域,例如,电影帧图片中上下两行黑色填充条,就是均匀区域。3D帧图像的左图中均匀区域与3D帧图像的右图中均匀区域的位置相同。
例如,在3D电影视频文件的3D帧图像的左图和右图中,影片图片上下均有一条黑色的区域A,黑色的区域A由于像素之间没有差异,则为均匀区域,该均匀区域的位置坐标为位置信息,通过预先设定的方式获取这黑色的区域A的位置坐标(四个顶点坐标)作为该3D电影视频文件的3D帧图像的左图和右图中均匀区域的位置信息,根据区域A的位置坐标得到区域A内部的像素数量作为均匀区域的像素数量。
S12:通过随机噪声对均匀区域中各像素的红、绿、蓝三个颜色单元进行赋值。
其中,随机噪声中的随机噪声信号值在各颜色单元的取值范围内。如果帧图像是8bit的图片,则各颜色通道的随机噪声信号中的随机噪声信号值的取值范围均为[0,255]。通过对均匀区域赋值的方式,可以增加均匀区域中的差异,减少因3DRS算法造成的估计错误。
S13:对赋值后的3D帧图像的左图和右图进行基于3DRS算法的深度估计计算。
通过进行的多层3DRS算法得到差异估计值可以得到较好的深度估计结果。再通过块腐蚀、差异深度转化等方式得到深度图,块腐蚀、差异深度转化等均为现有技术,在此不再阐述。
图2和图3示出根据本发明提供的一种深度估计方法第二个实施例的方法流程图。本实施例的一种深度估计方法主要适用于通过3DRS算法进行深度估计的情况,该系统主要由电子设备硬件和软件配合执行。其中,电子设备可以为个人电脑、笔记本电脑、手机、平板电脑等,且电子设备中带有处理器,该方法相比于一种深度估计方法第一个实施例,进一步优化了噪声的赋值过程,加入了噪声的生成步骤,包括以下步骤:
S21:获取3D帧图像的左图和右图中的均匀区域,以及均匀区域的位置信息和像素数量,其中,左图与右图中的均匀区域具有相同的位置信息,均匀区域中包括多个像素,每个像素包含红、绿、蓝三个颜色单元。
S22:形成红、绿、蓝三个颜色通道,分别生成红、绿、蓝三个颜色通道的随机噪声信号和随机相位信号。
S23:分别从红、绿、蓝三个颜色通道的随机相位信号中读取随机相位信号值作为起始相位,在对应颜色通道的随机噪声信号中从起始相位开始逐个读取噪声信号值,根据均匀区域的位置信息和像素数量,将读取到的噪声信号值赋给到3D帧图像的左图和右图的均匀区域中各像素的对应颜色单元,左图右图均匀区域中相同位置赋值相同,不同通道赋值不同。
具体的,从各颜色通道的随机相位信号中均读取至少一个随机相位信号值作为该颜色通道的起始相位。在各颜色通道的随机噪声信号中,从该颜色通道的相位值的位置开始逐个读取噪声信号值,根据均匀区域的位置信息将噪声信号值赋值到均匀区域的像素中,使均匀区域所有像素被赋值,得到加噪后的3D帧图像的左图和右图。
例如,在R、G、B通道(红、绿、蓝三个颜色通道)的随机相位信号中读取到两组相位值,一组为a1、b1、c1,另一组为a2、b2、c2。在R、G、B通道的随机相位信号中获取到的一组相位信号值作为初始相位均为a1、b1、c1,在R通道随机相位信号中获取的初始相位为a1,则在R通道的随机噪声信号中,从相位值的位置为a1的噪声信号值开始逐个读取并依次填充到3D帧图像的左图和右图中均匀区域的像素中,使均匀区域被赋值。将所有噪声信号值读取完毕后(当读取到最后一个随机噪声信号后,再从第一个随机噪声信号值开始)从相位值的位置为a2的噪声信号值开始逐个读取并依次赋值到均匀区域的像素中,使均匀区域被填满。均匀区域的R通道被赋值的过程中,均匀区域的G通道、B通道也采用同样的方式进行赋值。
还可以采用以下方式填充:
从起始相位开始逐个读取噪声信号值,生成与均匀区域具有相同像素数量的噪声图案;根据均匀区域的位置信息将噪声图案填充到3D帧图像的左图和右图的均匀区域内。
通过生成各颜色通道的随机噪声信号和随机相位信号,根据随机相位信号中的随机相位值作为读取随机噪声信号的起始相位,可以通过加随机噪声的方式扩大空间差异,减少3DRS算法在均匀区域的误差,深度估计更准确。
优选的,S23包括S231和S232。
S231:从红、绿、蓝三个颜色通道的随机相位信号中顺序循环读取相位信号值作为起始相位。
优选的,为了循环过程中不出现重复噪声,随机噪声信号长度为L,所述随机相位信号长度为M,且L和M的取值满足:L,M∈{x|x=2n-1,n∈N},所述随机相位信号的各信号值取值范围为区间[0,L]中的整数。
S232:分别确定红、绿、蓝三个颜色通道的当前起始相位,在对应颜色通道的随机噪声信号中从当前初始相位开始逐个读取所有噪声信号值,根据均匀区域的位置信息将读取到的噪声信号值赋给3D帧图像的左图和右图的均匀区域中各像素的对应颜色单元;每个像素被赋值后均判断赋值的噪声信号值的数量是否等于像素数量,若否,且有剩余噪声信号值,则继续赋值;若否,且所有每个像素被赋值,则将下一相位值更新为当前起始相位,返回执行赋值操作;若是,则停止赋值。
例如:保存三组长度为L,范围为[0,255](8 bits)的随机信号作为红、绿、蓝三个颜色通道的随机噪声信号,L=1023,保存三组长度为M=1023,范围为[1,L]的随机信号作为红、绿、蓝三个颜色通道的随机相位信号。设定计数器C,计数长度为L,初始值为0。循环读取噪声信号中各点值输出,用于赋值给均匀区域中像素,红、绿、蓝三个颜色单元,由于采用了3组不同的随机信号,同点红、绿、蓝三个颜色通道对应值可能不同。每输出一点噪声信号值,C=C+1。
每个像素被赋值后均判断赋值的噪声信号值的数量是否等于像素数量(此步骤也是通过计数器实现的),若否,且有剩余噪声信号值没输出,即C<L,则继续赋值;若否,且所有噪声信号值均已赋值,即C=L时,重置计数器C=0,则将下一相位值更新为当前起始相位(若随机相位信号中读到最后一个相位值则重新读取第一个相位值),返回执行赋值操作,令读取得到的红、绿、蓝三个颜色通道初始相位为A、B、C,则重置计数器时输出像素点与噪声信号关系,如图6和图7所示,且每个像素被赋值后均执行上述判断步骤。
本实施例中,1920*1080像素图中的均匀区域为1920*200,考虑实际处理图像尺寸区间(960*540像素~3840*2160像素),可取L=1023,M=1023,存储空间小,大周期变小。实现时所需存储空间为3*(L+M)=3*(1023+1023)≈6Bytes,即6KBytes大小。同时由于方法具有了余存噪声的特点,省去了噪声发生器等较复杂的逻辑部分。
通过循环获取初始相位和噪声信号的方式,生成的随机噪声信号和随机相位信号不需要占用很多存储空间,便能赋值很大的均匀区域。
优选的,通过均匀分布函数分别生成红、绿、蓝三个颜色通道的随机噪声信号和随机相位信号。
S241:根据赋值后的3D帧图像的左图和右图分别搭建预设层数的图像金字塔,根据图像金字塔生成预设块尺寸的块网格差异场金字塔。
例如:基于输入的赋值后的3D帧图像的左图和右图,采用加权平均的方法,生成左右图的多层(3~4层)金字塔结构。高一层金字塔的尺寸是第一层金字塔的1/4(即长宽均为其1/2);举例而言,对于1080*960(长*宽)像素的图像,将生成1080*960/540*480/270*240像素三层的金字塔;相应的,初始化块网格下对应的差异场金字塔。基于以上例子,块大小采用8*8像素时,块网格下差异场大小为135*120/67*60/33*30块。差异场生成时丢弃了不足8像素的部分,如540像素/8=67.5~67块。
S242:根据预设的估计器逐层使用预设搜索路径对各层块网格差异场金字塔完成预设迭代次数的多层3DRS块估计迭代计算,得到块网格差异场金字塔中最底层的各块差异估计值。
例如:由最高一层金字塔开始,逐层向下计算其对应块网格下差异场。上一层计算结果保留,经扩展,根据估计器中分层预测块位置读取,作为相应的分层候选向量(Hierarchy Candidate)。常规搜索路径为:由左至右方向,由左上角点开始,至右下角点停止逐行计算(或逐列)。当按以上路径完成首次迭代后,以结束点(右下角点)起始,至上一轮起始点(左上角点),按反方向完成新一轮计算,直至迭代到达要求的迭代次数(如4次)。迭代计算结果保存,根据估计器中时间预测块位置读取,作为相应的时间候选向量(Temporal Candidate)。首次迭代时,根据时间预测块位置,读取上一帧计算对应位置结果作为时间候选向量,最终得到块网格差异场金字塔中最底层的各块差异估计值。其中,估计器,即空间候选块(S:Spatial Prediction Block)、时间候选块(T:Temporal Prediction Block)、分层候选块(H:Hierarchy Prediction Block)与计算块的相对位置,有不同选择,如Y估计器(Y estimator),或其变形的斜置Y估计器(Oblique Y estimator)等。
S243:根据块网格差异场金字塔中最底层的各块差异估计值生成深度图。
根据亚像素精度插值、块腐蚀、差异深度转化等最终生成将差异图量化至0~255区间内的深度图,完成整个深度估计过程。
综上,本实施例通过生成各颜色通道的随机噪声信号和随机相位信号,根据随机相位信号中的随机相位值作为读取随机噪声信号的起始相位,可以通过加随机噪声的方式扩大空间差异,减少3DRS算法在均匀区域的误差,深度估计更准确。
图4示出根据本发明提供的一种深度估计系统第一个实施例的结构框图。该系统主要由电子设备硬件和软件配合执行。其中,电子设备可以为个人电脑、笔记本电脑、手机、平板电脑等,且电子设备中带有处理器,该系统包括:区域信息获取单元31、赋值单元32、深度估计单元33。
区域信息获取单元31,用于获取3D帧图像的左图和右图中的均匀区域,以及均匀区域的位置信息和像素数量,其中,左图与右图中的均匀区域具有相同的位置信息,均匀区域中包括多个像素,每个像素包含红、绿、蓝三个颜色单元。
其中,均匀区域可以为用户设置的,或者也可以为系统自动判断识别得到的。均匀区域是指3D帧图像的左图和右图中各像素之间没有差异的区域,例如,电影帧图片中上下两行黑色填充条,就是均匀区域。3D帧图像的左图中均匀区域与3D帧图像的右图中均匀区域的位置相同。
例如,在3D电影视频文件的3D帧图像的左图和右图中,影片图片上下均有一条黑色的区域A,黑色的区域A由于像素之间没有差异,则为均匀区域,该均匀区域的位置坐标为位置信息,通过预先设定的方式获取这黑色的区域A的位置坐标(四个顶点坐标)作为该3D电影视频文件的3D帧图像的左图和右图中均匀区域的位置信息,根据区域A的位置坐标得到区域A内部的像素数量作为均匀区域的像素数量。
赋值单元32,用于通过随机噪声对均匀区域中各像素的红、绿、蓝三个颜色单元进行赋值。
其中,随机噪声中的随机噪声信号值在各颜色单元的取值范围内。如果帧图像是8bit的图片,则各颜色通道的随机噪声信号中的随机噪声信号值的取值范围均为[0,255]。通过对均匀区域赋值的方式,可以增加均匀区域中的差异,减少因3DRS算法造成的估计错误。
深度估计单元33,用于对赋值后的3D帧图像的左图和右图进行基于3DRS算法的深度估计计算。
通过进行的多层3DRS算法得到差异估计值可以得到较好的深度估计结果。再通过块腐蚀、差异深度转化等方式得到深度图,块腐蚀、差异深度转化等均为现有技术,在此不再阐述。
图5示出根据本发明提供的一种深度估计系统第一个实施例的结构框图。该系统主要由电子设备硬件和软件配合执行。其中,电子设备可以为个人电脑、笔记本电脑、手机、平板电脑等,且电子设备中带有处理器,该系统包括:区域信息获取单元41、赋值单元42、深度估计单元43。
区域信息获取单元41,用于获取3D帧图像的左图和右图中的均匀区域,以及均匀区域的位置信息和像素数量,其中,左图与右图中的均匀区域具有相同的位置信息,均匀区域中包括多个像素,每个像素包含红、绿、蓝三个颜色单元。
赋值单元42中包括信号生成模块421和赋值模块422。
信号生成模块421,用于形成红、绿、蓝三个颜色通道,分别生成红、绿、蓝三个颜色通道的随机噪声信号和随机相位信号。
优选的,为了循环过程中不出现重复噪声,随机噪声信号长度为L,所述随机相位信号长度为M,且L和M的取值满足:L,M∈{x|x=2n-1,n∈N},所述随机相位信号的各信号值取值范围为区间[0,L]中的整数。
赋值模块422,用于分别从红、绿、蓝三个颜色通道的随机相位信号中读取随机相位信号值作为起始相位,在对应颜色通道的随机噪声信号中从起始相位开始逐个读取噪声信号值,根据均匀区域的位置信息和像素数量,将读取到的噪声信号值赋给到3D帧图像的左图和右图的均匀区域中各像素的对应颜色单元。
具体的,从各颜色通道的随机相位信号中均读取至少一个随机相位信号值作为该颜色通道的起始相位。在各颜色通道的随机噪声信号中,从该颜色通道的相位值的位置开始逐个读取噪声信号值,根据均匀区域的位置信息将噪声信号值赋值到均匀区域的像素中,使均匀区域所有像素被赋值,得到加噪后的3D帧图像的左图和右图。
例如,在R、G、B通道(红、绿、蓝三个颜色通道)的随机相位信号中读取到两组相位值,一组为a1、b1、c1,另一组为a2、b2、c2。在R、G、B通道的随机相位信号中获取到的一组相位信号值作为初始相位均为a1、b1、c1,在R通道随机相位信号中获取的初始相位为a1,则在R通道的随机噪声信号中,从相位值的位置为a1的噪声信号值开始逐个读取并依次填充到3D帧图像的左图和右图中均匀区域的像素中,使均匀区域被赋值。将所有噪声信号值读取完毕后(当读取到最后一个随机噪声信号后,再从第一个随机噪声信号值开始从相位值的位置为a2的噪声信号值开始逐个读取并依次赋值到均匀区域的像素中,使均匀区域被填满。均匀区域的R通道被赋值的过程中,均匀区域的G通道、B通道也采用同样的方式进行赋值。
还可以采用以下方式填充:
从起始相位开始逐个读取噪声信号值,生成与均匀区域具有相同像素数量的噪声图案;根据均匀区域的位置信息将噪声图案填充到3D帧图像的左图和右图的均匀区域内。
优选的,赋值模块422具体用于:从红、绿、蓝三个颜色通道的随机相位信号中顺序循环读取相位信号值作为起始相位,分别确定红、绿、蓝三个颜色通道的当前起始相位,在对应颜色通道的随机噪声信号中从当前初始相位开始逐个读取所有噪声信号值,根据均匀区域的位置信息将读取到的噪声信号值赋给3D帧图像的左图和右图的均匀区域中各像素的对应颜色单元;每个像素被赋值后均判断赋值的噪声信号值的数量是否等于像素数量,若否,且有剩余噪声信号值,则继续赋值;若否,且所有每个像素被赋值,则将下一相位值更新为当前起始相位,返回执行赋值操作;若是,则停止赋值。
优选的,为了循环过程中不出现重复噪声,随机噪声信号长度为L,所述随机相位信号长度为M,且L和M的取值满足:L,M∈{x|x=2n-1,n∈N}。
例如:保存三组长度为L,范围为[0,255](8bits)的随机信号作为红、绿、蓝三个颜色通道的随机噪声信号,L=1023,保存三组长度为M=1023,范围为[0,L]的随机信号作为红、绿、蓝三个颜色通道的随机相位信号。设定计数器C,计数长度为L,初始值为0。循环读取噪声信号中各点值输出,用于赋值给均匀区域中像素,红、绿、蓝三个颜色单元,由于采用了3组不同的随机信号,同点红、绿、蓝三个颜色通道对应值可能不同。每输出一点噪声信号值,C=C+1。
每个像素被赋值后均判断赋值的噪声信号值的数量是否等于像素数量(此步骤也是通过计数器实现的),若否,且有剩余噪声信号值没输出,即C<L,则继续赋值;若否,且所有噪声信号值均已赋值,即C=L+1时,重置计数器C=0,则将下一相位值更新为当前起始相位(若随机相位信号中读到最后一个相位值则重新读取第一个相位值),返回执行赋值操作,令读取得到的红、绿、蓝三个颜色通道初始相位为A、B、C,则重置计数器时输出像素点与噪声信号关系,如图6和图7所示,且每个像素被赋值后均执行上述判断步骤。
本实施例中,1920*1080像素图中的均匀区域为1920*200,考虑实际处理图像尺寸区间(960*540像素~3840*2160像素),可取L=1023,M=1023,存储空间小,大周期变小。实现时所需存储空间为3*(L+M)=3*(1023+1023)≈6Bytes,即6KBytes大小。同时由于方法具有了余存噪声的特点,省去了噪声发生器等较复杂的逻辑部分。
通过循环获取初始相位和噪声信号的方式,生成的随机噪声信号和随机相位信号不需要占用很多存储空间,便能赋值很大的均匀区域。
优选的,通过均匀分布函数分别生成红、绿、蓝三个颜色通道的随机噪声信号和随机相位信号。
深度估计单元43包括金字塔生成模块431、迭代计算模块432、深度图生成模块433。
金字塔生成模块431,用于:根据赋值后的3D帧图像的左图和右图分别搭建预设层数的图像金字塔,根据图像金字塔生成预设块尺寸的块网格差异场金字塔。
例如:基于输入的赋值后的3D帧图像的左图和右图,采用加权平均的方法,生成左右图的多层(3~4层)金字塔结构。高一层金字塔的尺寸是第一层金字塔的1/4(即长宽均为其1/2);举例而言,对于1080*960(长*宽)像素的图像,将生成1080*960/540*480/270*240像素三层的金字塔;相应的,初始化块网格下对应的差异场金字塔。基于以上例子,块大小采用8*8像素时,块网格下差异场大小为135*120/67*60/33*30块。差异场生成时丢弃了不足8像素的部分,如540像素/8=67.5~67块。
迭代计算模块432,用于:根据预设的估计器逐层使用预设搜索路径对各层块网格差异场金字塔完成预设迭代次数的多层3DRS块估计迭代计算,得到块网格差异场金字塔中最底层的各块差异估计值。
例如:由最高一层金字塔开始,逐层向下计算其对应块网格下差异场。上一层计算结果保留,经扩展,根据估计器中分层预测块位置读取,作为相应的分层候选向量(Hierarchy Candidate)。常规搜索路径为:由左至右方向,由左上角点开始,至右下角点停止逐行计算(或逐列)。当按以上路径完成首次迭代后,以结束点(右下角点)起始,至上一轮起始点(左上角点),按反方向完成新一轮计算,直至迭代到达要求的迭代次数(如4次)。迭代计算结果保存,根据估计器中时间预测块位置读取,作为相应的时间候选向量(Temporal Candidate)。首次迭代时,根据时间预测块位置,读取上一帧计算对应位置结果作为时间候选向量,最终得到块网格差异场金字塔中最底层的各块差异估计值。其中,估计器,即空间候选块(S:Spatial Prediction Block)、时间候选块(T:Temporal Prediction Block)、分层候选块(H:Hierarchy Prediction Block)与计算块的相对位置,有不同选择,如Y估计器(Y estimator),或其变形的斜置Y估计器(Oblique Y estimator)等。
深度图生成模块433,用于:根据块网格差异场金字塔中最底层的各块差异估计值生成深度图。
根据亚像素精度插值、块腐蚀、差异深度转化等最终生成将差异图量化至0~255区间内的深度图,完成整个深度估计过程。
综上,本实施例通过生成各颜色通道的随机噪声信号和随机相位信号,根据随机相位信号中的随机相位值作为读取随机噪声信号的起始相位,可以通过加随机噪声的方式扩大空间差异,减少3DRS算法在均匀区域的误差,深度估计更准确。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!