数据优化的神经网络遍历的制作方法
本公开涉及神经网络。更具体地,本公开涉及神经网络的执行。
背景技术:
神经网络是指模仿生物大脑的计算架构。在神经网络内,被称为神经元的节点可互相连接并被共同地操作,以处理复杂的输入数据。不同类型的神经网络的示例包括卷积神经网络、递归神经网络、深度信念网络(Deep Belief Networks)、受限玻尔兹曼机(Restricted Boltzman Machines)等,但不限于此。在前馈神经网络中,神经网络的神经元链接到其他神经元。这些链接通过神经网络仅沿一个方向(即,前向)延伸。
神经网络可用于从复杂的输入数据提取“特征”。神经网络可包括多个层。每个层可接收输入数据并通过处理到该层的输入数据而产生输出数据。输出数据可以是神经网络通过利用卷积核对输入图像或特征映射(feature map)进行卷积而产生的输入数据的特征映射。神经网络的初始层(例如,卷积层)可被操作为从输入(诸如图像)提取低层特征(诸如边缘和/或梯度)。神经网络的初始层也被称为特征提取层。神经网络的后续层(被称为特征分类层)可提取或检测逐渐更复杂的特征(诸如眼睛、鼻子等)。特征分类层也被称为“全连接层”。
可使用外部存储器来存储在神经网络的执行期间所产生的大量的中间结果数据。外部存储器也可被用于存储在特征分类层中使用的大量权重。
技术实现要素:
实施例包括一种执行神经网络的方法。所述方法包括:通过处理到神经网络的第一层的输入图块产生第一层的输出图块;将第一层的输出图块存储在处理器的内部存储器中。所述方法还包括:使用处理器通过处理存储在内部存储器中的第一层的输出图块产生神经网络的第二层的输出图块。
另一实施例包括用于执行神经网络的设备。所述设备包括:在处理器内的内部存储器;在处理器内的第一计算单元,结合到内部存储器,并且被配置为将可执行的操作初始化。可执行的操作包括:通过处理到神经网络的第一层的输入图块产生第一层的输出图块;将第一层的输出图块存储在内部存储器中。可执行的操作还包括:通过处理存储在内部存储器中的第一层的输出图块产生神经网络的下一层的输出图块。
提供本发明内容部分仅为介绍一些构思,而不为识别所要求的主题的关键特征或本质特征。本发明的许多其他特征和实施例将通过附图和通过以下具体实施方式而清楚。
附图说明
附图示出一个或多个实施例;然而,附图不应被认为将本发明限制于仅仅示出的实施例。在综观以下具体实施方式并参考附图后,各种方面和优点将变得清楚。
图1是示出由神经网络的多个层进行处理的示例的示图;
图2是示出由示例神经网络引擎执行的处理的框图;
图3是示出利用重叠图块对神经网络进行的示例分割的框图;
图4-1和图4-2是示出对神经网络的进一步示例分割的框图;
图5是示出执行神经网络的示例方法的流程图;
图6是示出确定神经网络的锥台(frustum)的示例方法的流程图;
图7是示出用于执行神经网络的批处理的示例的示图;
图8是示出执行神经网络的示例方法的流程图;
图9是示例数据处理系统的示图。
具体实施方式
虽然本公开以限定新颖的特征的权利要求书作为总结,但是相信这里描述的各种特征将通过考虑结合附图的描述而被更好地理解。为了说明的目的而提供在本公开中描述的过程、机器、制造和它们的任何变化。所描述的任何具体结构和功能细节将不被解释为限制,而仅作为权利要求书的基础和用于教导本领域技术人员以多种形式采用在几乎任何适合的具体结构中所描述的特征的代表性基础。此外,本公开中使用的术语和短语不意在限制,而用于提供对描述的特征的可理解描述。
本公开涉及神经网络。更具体地,这里公开的示例实施例涉及减少存储器访问和神经网络在运行期间的网络内带宽消耗。根据这里公开的示例布置,提供用于运行神经网络的方法和系统。这里描述的示例实施例能促进内部存储器的有效使用并减少在神经网络的运行期间执行的对外部存储器或高级高速缓冲存储器的数据访问量。
例如,这里公开的示例实施例能在神经网络的前向运行期间减少、消除所有或消除几乎所有的用于中间结果的数据通信量和相关的存储。示例实施例涉及神经网络的一个或多个阶段的执行。例如,结合图1至图6描述特征提取层(例如,卷积层)的执行。另外或可选地,如结合图7和图8更详细地描述的,示例实施例能消除与神经网络的全连接层的执行有关的很多(例如,所有的或几乎所有的)从外部存储器读取的参数和写入外部存储器的参数。如在这里使用的,术语“全连接层”意思是神经网络的特征分类层。
减少用于执行神经网络的数据通信量,从而提高性能并减少确定相同计算结果(例如,无近似)所需的电力。通过减少从外部存储器读取或向外部存储器写入中间结果和/或特征分类层的权重,这里描述的示例实施例能促进提高执行速度、减少功耗和减小内存存储负载。
卷积神经网络可被部署用于很多应用,包括(但不限于)图像中的对象识别、图像重构、语义分割、场景识别等。对象识别是指检测或识别图像中的特定对象(诸如猫、汽车、椅子等)的图像处理。图像重构是指尝试校正图像的图像处理。图像重构的示例可包括锐化模糊图像。语义分割是指标注图像的部分的图像处理。场景识别是指确定在图像中表示的特定场景(诸如办公室、卧室、体育馆等)的图像处理。除了这些视觉的示例,还存在许多其中有效地应用类似的神经网络的其他应用领域。
虽然神经网络能实现卓越的精度(准确度),但是神经网络可以是计算密集型的。例如,神经网络通常对每个图像执行大量运算、需要大量权重来执行、以及产生大量中间结果通信量。举例说明,通常的神经网络可按每个图像十亿次运算的数量级执行运算、利用数以百计的数百万至数十亿的权重、以及产生数以百计的十亿字节的中间结果数据。在很多实施方式中,权重和中间结果数据通信量在能效方面具有高消耗。随着神经网络的计算效率提高,这些通信量构成执行神经网络所花费的电力的更大比例,从而限制神经网络在电力受限的移动装置和其他电力限制的应用和/或计算环境下的使用。因此,这里公开的示例实施例能有助于部署神经网络和移动电子装置上的基于神经网络的应用。
图1是示出由神经网络100的多个层进行处理的示例的示图。图1示出输入102和多个特征映射集104和106。例如,输入102可以是将通过神经网络100被处理的图像。如在这里使用的,术语“特征映射集”意思是一个或多个特征映射(例如,数据)。特征映射集作为输入被接收并被神经网络的层处理和/或被神经网络的层作为输出产生。在示例实施例中,特征映射集104和106由神经网络100的特征提取层或卷积层产生。
通常,神经网络100的层能定义输入到输出的映射。例如,在卷积神经网络的情况下,由层定义的映射被实现为将被应用于输入数据(诸如图像和/或特定特征映射)的一个或多个卷积核,以从所述层进一步产生特征映射作为输出。参照图1,层(未示出)在前向执行期间接收输入102并产生特征映射集104作为输出。下一层(未示出)在前向执行期间接收特征映射集104作为输入并产生特征映射集106作为输出。再下一层可在前向执行期间接收特征映射集106作为输入并产生进一步的特征映射集作为输出。因此,在前向执行期间,数据从输入102向上流至特征映射集104、流至特征映射集106。接收和/或产生特征映射集104和106的所有层或其中的一个或多个层可以是隐藏层(例如,隐藏卷积层)。除了应用卷积核来将输入特征映射映射到输出特征映射之外,还可执行其他处理操作。这些处理操作的示例可包括启动功能、池化(pooling)和重采样的应用,但不限于此。
在图1的示例中,特征映射集104包括四个特征映射104-1、104-2、104-3和104-4。特征映射集106包括六个特征映射106-1、106-2、106-3、106-4、106-5和106-6。应理解,在特征映射集104和106中的每个特征映射集中示出的特征映射的数量是为了说明的目的。在本公开中描述的示例布置不意在被神经网络100的任何特征映射集中的特征映射的特定数量和/或被神经网络100中的层的特定数量所限制。
术语“中间数据”是指由神经网络的隐藏卷积层(例如,层1至层N-1)产生的特征映射的数据。例如,神经网络引擎(NN引擎)在神经网络(诸如神经网络100)的执行期间产生中间数据。
通常,各个特征映射集104和106可由数十至数百的特征映射组成。在一个示例中,每个特征映射是表示在所有x、y位置的已知特征的强度的16位值的2D图像映射。为针对神经网络的层N+1产生每个特征映射,NN引擎读取由神经网络的层N输出的每个特征映射。例如,如果层N产生10个特征映射作为到层N+1(层N+1产生20个特征映射作为输出)的输入,则在运行层N+1的过程中必须读取层N中的每个特征映射20次。因此,NN引擎必须执行从层N读取的总共200次特征映射。
在一个布置中,NN引擎可使用并行化(parallelism)来重新整理计算,以使中间数据在产生之后很快被消耗。通过在产生之后很快消耗中间数据,在任一时刻仅存储少量的中间数据。可将所述少量的中间数据纳入附近的片上存储器(例如,内部存储器)中,而不是将中间数据存储在外部随机存取存储器(RAM)或其他远的高速缓冲存储器中。此外,在示例实施例中,少量中间数据(如果有的话)在NN引擎自身内部被移动任意显著的距离。产生中间数据的乘法累加(MAC)单元的相同的本地集可被用于在中间数据产生之后很快将其作为输入消耗。因为不需要NN引擎内的长的互连来传输中间数据,因此这进一步减少了电力。
在另一示例实施例中,NN引擎可被配置为重新整理计算以通过对神经网络的一个或多个或者可能所有的卷积层的产生进行交织(interleaving)来减少和/或消除中间数据并本地化中间数据。这与执行所有层以产生特征映射集104然后执行所有的下一层以产生特征映射集106等形成对照。相反,根据这里描述的示例布置,NN引擎可执行层的部分以产生特征映射集104的部分,然后执行下一层的部分以产生特征映射集106等。例如,NN引擎可产生被特征映射集106的相应图块112-1等跟随的特征映射集104中的图块110-1。NN引擎可随后产生被图块112-2等跟随的图块110-2。
为了说明的目的,图1的神经网络100可被可视化为层的金字塔。如所述的,执行可通过处理输入102以产生具有图块110的特征映射集104并且处理特征映射集104以产生具有图块112的特征映射集106,来从金字塔的底部开始执行。随着神经网络100被向上遍历,在每个下一更高的层的特征映射的数量可增加的同时,所述每个下一更高的层可在x-y维度方面收缩。例如,产生特征映射集106的层的x-y维度可小于产生特征映射集104的层的x-y维度。特征映射集106比特征映射集104具有更多的特征映射。在其他情况下,神经网络的下一更高的层中的特征映射的数量可保持不变。
根据另一示例实施例,神经网络100的3D体积可被概念地分解或分割为多个矩形锥台(rectangular frustums)。每个矩形锥台可具有矩形相交面,所述矩形相交面利用由神经网络100使用的输入和/或每个特征映射集限定图块。在这点上,图块是到神经网络的输入数据或者特征映射集的矩形部分。在图1的示例中,神经网络100被分为四个锥台,被称为锥台1、锥台2、锥台3和锥台4。通过输入102内的锥台的相交面来限定矩形图块,并通过特征映射集104和特征映射集106中的每个特征映射集内的锥台的相交面来限定矩形图块。因此,给出的特征映射集的各个图块包括该特征映射集的各个特征映射的一部分。例如,图块110-1包括特征映射104-1、104-2、104-3和104-4中的每个的左上部分。为了讨论的目的,特征映射集的每个图块的参考标号的延伸部分表示该图块所属的特定锥台。例如,锥台1可包括输入102的图块108-1、特征映射集104的图块110-1和特征映射集106的图块112-1。锥台2可包括输入102的图块108-2、特征映射集104的图块110-2和特征映射集106的图块112-2等。因为层使用卷积核定义输入到输出的映射,因此应理解,每个锥台也定义操作输入图块并产生输出图块的每个层中的卷积核中的特定的卷积核。结合图6来更详细地描述用于分割的示例方法。
如在这里使用的,(例如,通过使用诸如处理器、计算单元、NN引擎等)使用神经网络的层“执行层”和“处理数据”的示例包括“将神经网络的层的卷积核应用到被提供为到层的输入的数据以产生层的输出特征映射集”。数据可以是特征映射、特征映射集或另一输入(诸如一个或多个图像)。在这点上,应理解,神经网络的部分可被执行以处理图块。如在这里使用的,使用神经网络的层“处理图块”的示例包括“应用与被提供为到层的输入的图块所对应的神经网络的层的卷积核的子集来产生层的输出图块”。例如,定义被提供为输入的图块的锥台中的层的卷积核可被应用于输入图块以产生输出图块。
通常,每个锥台中的处理可被独立于各个其他锥台执行。在一个示例实施例中,可在相邻的锥台之间共享少量的数据。此外,针对层的给出的图块,可将产生下一层的相应图块所必需的所有特征映射部分存储在产生所述下一层中的相应图块的特定逻辑电路本地的缓冲器中。如本公开中所定义的,术语“相应图块”是指作为参考图块或主体图块的在神经网络的同一锥台中并且在相邻层中的图块。
例如,针对神经网络100的给出的层的图块,由NN引擎的处理器消耗和产生的特征映射的部分可被存储在处理器芯片上的内部存储器中。由处理器针对图块产生的特征映射的部分被用于产生被提供为到下一层的输入的输出图块。举例说明,处理器可消耗存储在内部存储器中的输入102的部分(例如,图块108-1)以产生特征映射集104的相应图块110-1。特征映射集104的图块110-1也可被存储在内部存储器中。然后,处理器可利用内部存储器中的特征映射集104的图块110-1来产生特征映射集106的图块112-1。图块112-1也可被存储在内部存储器中。在一个方面,内部存储器处理锥台所需的总存储是神经网络100的两个相邻层中的所述锥台的相应图块的最大占用空间(例如,存储使用)。例如,与图块112-1相应的数据可覆盖图块108-1的数据。应理解,图块的x和y维度(例如,锥台大小)可被减小为保证将中间结果纳入可用的内部存储器所需的大小。
针对神经网络100的每个锥台,NN引擎可从由层N的图块定义的特征映射的部分产生由层N+1的相应图块定义的特征映射的部分。在一个实施例中,NN引擎可在在内部存储器或缓冲器中保持所有需要的数据的同时以各种不同顺序中的任意顺序执行必要的处理。例如,NN引擎可通过对由层N的图块定义的所有输入特征映射进行读取和卷积并将结果相加来产生层N+1的相应图块的每个特征映射的部分。在产生层N+1的相应图块之后,不再需要用于产生层N+1的图块的层N的图块的数据。因此,NN引擎可回收、删除、释放或覆盖用于存储层N的图块的存储,以便存储层N+2的结果(例如,相应图块),以此类推。当如所述产生下一层的新产生的中间数据时,NN引擎可继续覆盖层的中间数据。结合图5更详细地描述示例方法。
通过将神经网络划分为可被彼此独立地处理的锥台,NN引擎可使用多个计算单元并行地处理锥台。例如,NN引擎的一个计算单元可处理图块108-1、110-1和112-1;而同时NN引擎的另一计算单元可处理图块108-2、110-2和112-2;而同时NN引擎的另一计算单元可处理图块108-3、110-3和112-3,同时NN引擎的另一计算单元可处理图块108-4、110-4和112-4。结合图4更详细地描述并行处理。
在一些情况下,一些数据(例如,极少数据)被同一特征映射集内的紧密相邻的图块所使用。因此,虽然锥台可被独立地处理,但是在被神经网络的层处理时,少部分中间数据可沿着同一特征映射集内的相邻图块的边界被共享。例如,针对特征映射集104的图块110-1产生的数据的少部分可被特征映射集104的图块110-2分享。因为在每个锥台内处理是一致的(执行相同数量的计算并且数据被内部保持),所以处理时间可以是可预测的。因此,图块之间的同步可被简单控制而没有任何明显的停滞。在示例实施例中,计算单元将与计算单元对紧邻的输入图块进行操作基本上同时地自然地完成输入图块的处理,而此时,数据在相邻图块的边缘处的可被交换。在另一示例实施例中,同步和数据交换可按照特征映射的基础在特征映射上以更精细粒度实现。神经网络遍历的基于锥台的方法使架构的有效换算简单且高效。
在另一示例实施例中,可通过限定图块在图块边界处彼此重叠来消除相邻图块之间的数据共享。在这种情况下,NN引擎可每个图块一次地产生图块(包括图块的边界区域)的数据。因此,在重叠图块的情况下,两个相邻图块的数据不需要被共享。结合图3更详细地描述重叠图块的示例。
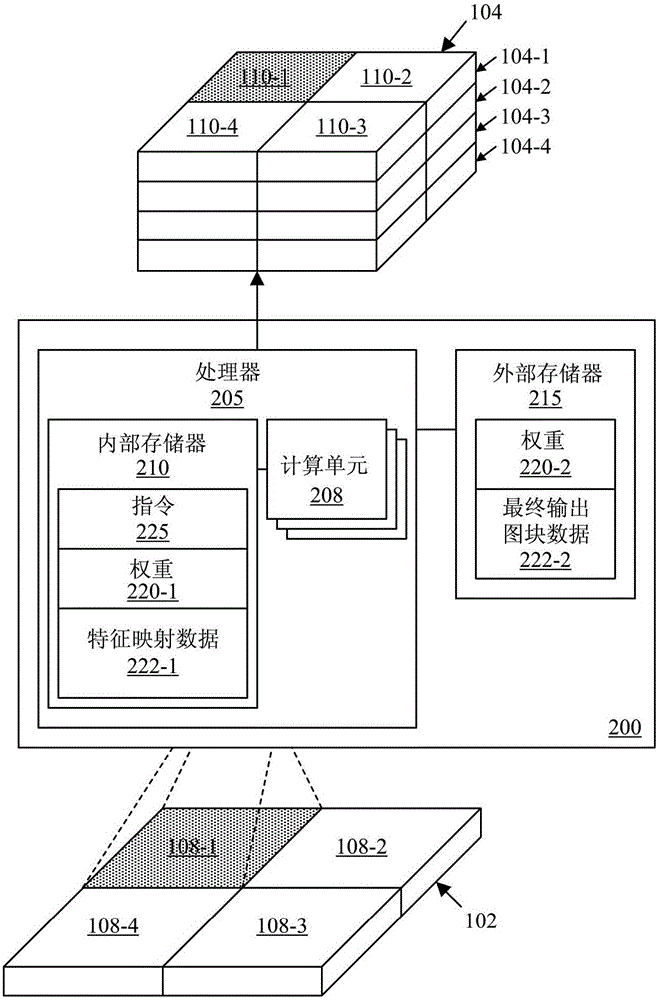
图2是示出由示例NN引擎200执行的处理的框图。如图,NN引擎200可包括处理器205和外部存储器215。处理器205可包括一个或多个计算单元208。在处理器205包括不止一个计算单元208的情况下,计算单元208可被配置为彼此并行或同时地操作。此外,计算单元208可彼此独立地操作。在一个示例中,每个计算单元208可被实现为可执行指令的核。
处理器205可被实现为一个或多个硬件电路。例如,处理器205可被实现为集成电路。在一个示例实施例中,处理器205可被配置为执行指令(诸如指令225)。指令225可被包含在程序代码中。处理器205的示例实施方式可包括(但不限于)中央处理器(CPU)、多核CPU、阵列处理器、向量处理器、数字信号处理器(DSP)、现场可编程门阵列(FPGA)、可编程逻辑阵列(PLA)、专用集成电路(ASIC)、可编程逻辑电路、控制器、图形处理器(GPU)等。可使用结合外部存储器215描述的各种不同的处理器中的任意处理器来实现NN引擎200。
处理器205可包括内部存储器210。内部存储器210可以是片上存储器。例如,内部存储器210可以是处理器205的高速缓冲存储器。内部存储器210可被实现为简单缓冲器、1级高速缓冲存储器、2级高速缓冲存储器或处理器205的其他类型的片上存储器。如图所示,计算单元208可连接到内部存储器210。在处理器205包括多个计算单元208的布置中,每个计算单元208可具有专用的内部存储器210。内部存储器210或视情况而定的各个内部存储器可将特征映射和/或它们的部分存储为特征映射数据222-1、权重220-1和指令225。
如图所示,处理器205可连接到外部存储器215。在一个示例中,外部存储器215可被实现为处理器205的一个或多个更高级别的高速缓冲存储器。然而,外部存储器215可不位于与处理器205的同一芯片上。在另一示例中,外部存储器215可被实现为RAM(例如,DRAM、SRAM)或其他存储器。在另一示例中,处理器205可通过存储器控制器(未示出)连接到外部存储器215。
在一个示例实施例中,外部存储器215针对神经网络的当前不使用的神经元存储权重220-2。外部存储器215还能存储最终输出图块数据222-2。因此,在存储器215存储权重220-2的同时,权重220-1可被存储在内部存储器210中。例如,权重220-1是处理到神经网络100的当前层的输入图块以产生将要被用作下一层的输入的神经网络100的当前层的输出图块所需要的那些权重。在图2的示例中,权重220-1是处理输入102的图块108-1以产生特征映射集104的图块110-1作为输出所需要的权重。权重220-2是当前不使用的或不是处理图块108-1所需的神经网络100的其他权重。在另一示例实施例中,处理器205可压缩权重220-1以存储在内部存储器210中。
在处理器205包括多个计算单元(每个计算单元具有自己的内部存储器)的另一示例实施例中,权重可被每层一次地装载。当处理相同的特征映射时,每个计算单元使用与其他计算单元相同的权重。每个计算单元的内部存储器可例如针对神经网络的当前正在被处理的层存储不同的权重。用于存储各个计算单元的权重的内部存储器的部分可与各个其他计算单元共享。每个计算单元的内部存储器可被其他计算单元访问以共享存储在其中的用于处理图块的权重。
图3是示出利用重叠图块对神经网络进行的示例分割的框图。更具体地,图3示出使用重叠的图块实现的神经网络100的特征映射集104。如图所示,图块110-1、110-2、110-3和110-4被限定为彼此交叠。重叠区域305以阴影显示。重叠区域305还在没有图块110-1、110-2、110-3和110-4的情况下单独示出。如所述的定义具有重叠的图块避免必须在相邻图块之间共享数据。
在更粗略级别上,可存在均处理具有多个锥台的整个神经网络的更广区域一些计算单元。例如,4单元的配置可将网络划分为4个象限,每个象限具有16个锥台。在这种情况下,每个计算单元可从左上角至右下角穿过被分配给该计算单元的象限。在另一示例中,神经网络可被分为棋盘格的锥台。
图4-1和图4-2是示出对神经网络的进一步示例分割的框图。在图4-1和图4-2的示例中,图块不重叠。参照图4-1,特征映射集402被分割为包括被示出为图块404-434的16个图块。处理特征映射集402的NN引擎可包括如所述的多个不同的计算单元或核。例如,NN引擎可包括4个计算单元A、B、C和D。因此,NN引擎可将工作分散给计算单元A、B、C和D以实现针对相邻图块之间的数据的交换具有最小(或至少更少)交叉通信量(cross traffic)的良好的换算(scaling,伸缩性)。
在图4-1的示例中,特征映射集402的部分440可包括图块404、406、408和410。NN引擎可将部分440的特征映射的图块处理为到神经网络的下一层的输入。计算单元A可处理图块404。计算单元B可处理图块406。计算单元C可处理图块408。计算单元D可处理图块410。计算单元A、B、C和D同时进行操作。
类似地,部分442包括图块412、414、416和418。NN引擎可将部分442的特征映射的图块处理为神经网络的下一层的输入。计算单元A可处理图块414。计算单元B可处理图块412。计算单元C可处理图块418。计算单元D可处理图块416。计算单元A、B、C和D同时进行操作。
部分444包括图块420、422、424和426。NN引擎可将部分444的特征映射的图块处理为到神经网络的下一层的输入。计算单元A可处理图块424。计算单元B可处理图块426。计算单元C可处理图块420。计算单元D可处理图块422。计算单元A、B、C和D同时进行操作。
部分446包括图块428、430、432和434。NN引擎可将部分446的特征映射的图块处理为到神经网络的下一层的输入。计算单元A可处理图块434。计算单元B可处理图块432。计算单元C可处理图块430。计算单元D可处理图块428。计算单元A、B、C和D同时进行操作。
在图4-1中的处理的描述过程中,NN引擎可处理一个部分,然后继续处理下一层的相应部分并继续上行处理神经网络的一个或多个其他特征提取层。在其他布置中,NN引擎可操作部分440,然后是部分442,然后在回到层402处理部分444和446之前视情况而定进行下一层或多层中的相应部分的处理。
应理解,提供图4-1仅用于说明的目的。在一个或多个其他实施例中,NN引擎能将神经网络划分为带(band),以行优先的顺序、Z顺序等进行遍历。存在能够使用的其他可能的粗略级别的子划分和遍历。一种考虑是减少锥台和/或计算单元之间的数据交换。例如,参照图4-1,计算单元B操作来自不同的部分的邻近的图块406和图块412并且操作来自不同的部分的邻近的图块426和图块432。对于计算单元C和邻近图块408和420以及邻近图块418和430,同样如此。计算单元D操作图块410、416、422和428的邻近图块组成。
图4-2示出特征映射集402的另一示例分割。在图4-2的示例中,特征映射集402被分割成图块1002-1008、1012-1018、1022-1028和1032-1038。图块1002-1008在行1010中。图块1012-1018在行1020中。图块1022-1028在行1030中。图块1032-1038在行1040中。图4-2中的每个图块也标注有操作该图块的NN引擎的特定核。如图所示,计算单元A操作行1010的每个图块。计算单元B操作行1020的每个图块。计算单元C操作行1030的每个图块。计算单元D操作行1040的每个图块。箭头表示每个计算单元被配置为从左至右遍历行中的图块。例如,参照行1010,计算单元A处理图块1002,然后处理图块1004,然后处理图块1006,然后处理图块1008。各个其他计算单元可以以相同的方式操作其他行中的图块。显然,如果期望的话可从右至左处理图块。
处理图块或遍历图块的顺序可按照带来确定。如这里定义的,术语“带”意思是在同一行或同一列中的两个或更多个邻近图块的集合。在一个示例实施例中,带是行或列的各个邻近图块。以行为基础从左至右对图块的遍历示出水平的(或基于行的)带的示例。在一个示例中,每行可能是一个带,其中,行1010对应于带1104;行1020对应于带1106;行1030对应于带1108;行1040对应于带1110。图4-2示出每个带按一行形成的示例实施方式。然而,在其他示例中,每个带可由2行、3行、4行或更多行形成。
在带中的图块的组织和遍历提供不重叠图块的情况下的多个优点。在一个方面,在从带的一个图块移动到同一个带中的下一相邻图块的过程中,不需要在这两个图块的边界处在计算单元之间交换数据。例如,计算单元A处理图块1002和图块1002之后的下个图块1004。如此,不需要与不同的计算单元交换数据以处理图块1002和图块1004之间共享的边界或边缘。
在另一方面,由于计算单元在近乎相同的时间完成对不同带的相邻图块(例如,如图4-2所示的同一列中的图块)的操作而促进计算单元A、B、C和D之间的数据交换。例如,带1104和带1106具有共享的边界区域1204。如果计算单元A处理带1104并且计算单元B处理带1106,则计算单元A和计算单元B共享数据以便处理共享边界区域1204。计算单元A处理图块1002与计算单元B处理图块1012同时。计算单元A和计算单元B在近乎相同的时间分别结束对图块1002和1012的处理,从而允许计算单元A和计算单元B更容易地共享共享边界区域1204(图块1002和1012之间的共享边缘)的那部分数据。计算单元A和计算单元B然后可分别继续转到图块1004和1014,同时处理图块1004和1014,共享数据,并且继续往下处理各自的带。
类似地,带1106和带1108具有共享边界区域1206。如果计算单元B处理带1106并且计算单元C处理带1108,则计算单元B和计算单元C共享数据以便处理共享边界区域1206。计算单元B处理图块1012与计算单元C处理图块1022同时。计算单元B和计算单元C在近乎相同的时间分别结束对图块1012和1022的处理,从而允许计算单元B和计算单元C更容易地共享共享边界区域1206(图块1012和1022之间的共享边缘)的那部分数据。计算单元B和计算单元C然后可分别移动到图块1014和1024,同时处理图块1014和1024,共享数据,并且继续往下处理各自的带。
最后,带1108和带1110具有共享边界区域1208。如果计算单元C处理带1108并且计算单元D处理带1110,则计算单元C和计算单元D共享数据以便处理共享边界区域1208。计算单元C处理图块1022与计算单元D处理图块1032同时。计算单元C和计算单元D在近乎相同的时间分别结束对图块1022和1032的处理,从而允许计算单元C和计算单元D更容易地共享共享边界区域1208(图块1022和1032之间的共享边缘)的那部分数据。计算单元C和计算单元D然后可分别继续转到图块1024和1034,同时处理图块1024和1034,共享数据,并且继续往下处理各自的带。
虽然大致描述图4-2具有由图块的一个或多个行形成的带,但是应理解,带可被形成为图块的一个或多个列。例如,第一带可由图块1002、1012、1022和1032形成,第二带由图块1004、1014、1024和1034形成,以此类推。在这种情况下,每个计算单元可从带的顶部(或底部)开始,并且从带的顶部(或底部)至底部(或顶部)移动地处理图块。每个带还可由2个列、3个列、4个列或更多列形成。
图5是示出执行神经网络的示例方法500的流程图。更具体地,方法500示出执行神经网络的特征提取层的示例方法。除了块505之外,方法500可由参考图2描述的NN引擎执行。
在块505,可将神经网络分割为多个锥台。这些锥台可以是矩形的。可将神经网络划分成从神经网络的更高层投影到更低层的矩形锥台。在一个实施例中,使用如由数据处理系统执行的离线处理将神经网络分割成锥台。可将分割的神经网络与所述分割存储在存储器中作为数据结构或数据结构的部分,以使NN引擎和/或另一系统可在执行神经网络时读取和/或确定所述分割。
例如,系统可根据神经网络的处理器的内部存储器的大小分割神经网络。系统可根据能够被处理器内部地用来存储权重的存储量来标定锥台的大小,其中,所述权重用来处理用于产生下一层的图块的一层的图块、相邻层中的特征映射的图块以及指令。结合图6描述实现块505的示例方法。
在块510,NN引擎可将神经网络的层选择作为当前层。例如,NN引擎可选择层N作为当前层。在块515,NN引擎可确定当前层是否是被指定为用于执行图5所示的执行方法的一个停止点。如果是,在一个方面,方法500可结束。在另一方面,可在神经网络的选择的层重新开始方法500。
例如,在块515,NN引擎可确定已经达到神经网络的特定层。作为响应,如果接下来的图块保持被处理为到起始层的输入(例如,神经网络的至少一个其他锥台需要处理),则NN引擎可从起始层开始处理,否则结束。如果未达到指定的层,则方法500可继续至块520。
在块520,NN引擎可将作为到当前层的输入的图块选择为当前图块。在块525,NN引擎可针对当前图块产生神经网络的下一层或相邻层的相应图块。例如,神经网络引擎将选择的图块作为输入图块处理以产生输出图块(例如,相应图块)。在块530,系统确定是否处理到当前层的输入对象(图像或特征映射集)的另一图块还是继续至神经网络中的下一层。响应于确定将处理输入对象的不同图块或下一图块,方法500循环回到块520以选择输入对象的下一图块。响应于确定将要处理神经网络的下一层中的相应图块,方法500循环回到块510,以选择神经网络的下一相邻层。例如,在块520的下一迭代中选择的图块可以是在块520的前一迭代中产生的输出图块。
在一个实施例中,根据分割、带、NN引擎中的计算单元的数量、内部存储器的大小等,NN引擎可处理当前层中的另一图块。例如,NN引擎可仅将图块的子集(例如,一个或多个,但少于所有的图块)处理为当前层的输入。NN引擎可在处理前一层中的所有图块之前,继续至神经网络的下一层。如讨论的,通过处理到当前层的输入图块而产生的中间数据可被存储在内部存储器中并被用于下一层(例如,作为用于产生下一层中的输出图块的输入图块)。
在另一实施例中,方法500可由NN引擎的第一计算单元执行,而NN引擎的一个或多个其他计算单元也与第一计算单元同时地实现图5的方法500。计算单元也可以以异步方式操作,因此在正由同时操作的计算单元处理的相同特征映射集中的邻近图块的边缘处的数据可被共享。可选地,可以以重叠方式限定图块,以避免计算单元之间的数据的共享。
在另一实施例中,可执行方法500以通过多个第一相邻层来处理神经网络的第一锥台。方法500可迭代,以通过所述多个第一相邻层来处理各个其他锥台。然后,可再次执行方法500,以处理具有与所述多个第一相邻层不同的分割的多个不同的第二相邻层的第一锥台。可重复方法500,以通过具有不同分割的所述多个第二相邻层来处理其余的锥台。
图6是示出确定神经网络的锥台的示例方法600的流程图。可执行方法600以将神经网络分割成锥台,锥台定义了神经网络的各个特征提取层的图块的大小。在一个方面,方法600可以是图5的块505的示例实施方式。在一个实施例中,方法600可由诸如计算机的数据处理系统(系统)执行。例如,方法600可被执行为离线处理,其中,可在神经网络的执行之前执行方法600。确定的分割可被存储为神经网络的部分,用于由NN引擎进行后续执行。
在块605,系统可选择神经网络的相邻特征提取层的组来共同处理,将中间数据保持在NN引擎的处理器的内部存储器中。例如,系统可选择两个相邻特征提取层。如讨论的,将中间数据保持在NN引擎的处理器的内部存储器中减少在执行神经网络的过程中产生的片外数据通信量。
在块610,系统可从确定的内部存储器大小减去用于存储所述组中压缩的权重所需的存储。针对神经网络的每一层存储压缩的权重所需的存储量可从在分割之前执行的训练过程来确定。在块615,系统可基于所述组的层N中的特征映射的数量所需的存储加上所述组的下一层(层N+1)的相应存储需求来确定图块的宽度和高度。层N+1所需的存储是换算的宽度和高度与层N+1中的特征映射的数量的乘积。宽度和高度被从层N换算并且针对卷积核宽度和高度而占有(account,考虑)图块边界处的另外的神经元。
针对块605中选择的层的组,系统可确定在任意给出的层的宽度和高度以使在从内部存储器的总共可用存储减去压缩的权重之后,两个相邻层的图块(例如,相应图块)的特征映射的部分被纳入剩余存储中。由于图块分辨率在每一层被换算,因此一个大小将导致不会换算超出可用存储。
图6仅为说明的目的而呈现,因此不意在作为对这里公开的发明布置的限制。图6示出基于NN引擎的内部存储器的大小将神经网络分割为锥台的示例处理。在一个布置中,可针对神经网络中的相邻特征提取层的不同组执行图6,以确定神经网络的不止一个分割。以这种方式,可使用第一分割来执行神经网络的具有多个相邻特征提取层的部分,而可使用第二(不同的)分割来执行神经网络的具有相邻特征提取层的第二(或第三或更多的)不同部分。
在另一方面,这里描述的示例实施例还可解决参数数据通信量的减少。例如,参数数据的读取可消耗神经网络的特征分类层中的存储器带宽的很大部分。如本说明书中定义的,术语“参数”意思是应用于从输入特征映射读取以在神经网络的后续层中产生输出特征映射的数据的权重。在这点上,术语“参数”可在本公开中与“权重”互换使用。通常,每个权重是8位或16位,但是本发明布置不意在被参数的特定位宽所限制。作为说明性示例,很多卷积神经网络包括数百万的权重,从而产生大量的网络内数据通信量。
在很多实施例中,大部分权重(例如,大约90%)是用于神经网络的最终特征分类层。例如,随着神经网络在将来演变为对更多的目标类别进行分类(或处理更复杂的任务),特征分类层中的参数的数量会增加,使得用于执行网络的参数通信量对功耗而言是更大的问题。为减少或几乎消除参数通信量的开销,可批量处理测试用例。例如,在一些应用中,可由网络共同处理数十或数百的图像。
在很多情况下,神经网络可从神经网络的输入层至输出侧变窄。例如,神经网络可具有特征提取层的集合,随后是全连接特征分类层。大部分权重属于特征分类层。神经网络的特征提取层的顶部所需的针对中间数据的存储量可以很小。
图7是示出用于执行神经网络的批处理的示例的示图。在图7的示例中,NN引擎(例如,图2的NN引擎)包括存储器系统700。存储器系统700包括与NN引擎的特定处理器、逻辑、计算单元等一起位于芯片上的内部存储器705。存储器系统700还包括外部(或片外)存储器710。外部存储器710可通过存储器控制器(未示出)连接到NN引擎。如图所示,神经网络包括多个特征提取层740和多个特征分类层745。
如图所示,NN引擎可通过如由特征映射715、720、725和最终特征映射730表示的神经网络的特征提取层740处理N个图像。在这个示例中,N是大于1的整数值。NN引擎将针对这N个图像中的每个图像的中间结果735保存在内部存储器705中。
进行至神经网络的特征分类层745,NN引擎读取第一全连接特征分类层755的权重750的部分或子集,并且通过层755处理这N个图像的每个中间结果。在对内部存储器705的批处理中,NN引擎保存全部N个图像的部分结果。在一些情况下,NN引擎可将针对这N个图像的层755的部分结果保存在外部存储器710中。
例如,如果在内部存储器705中针对层755存在1600万16位参数并且针对权重750存在32KB的存储,则NN引擎将权重750的子集(例如,16K的权重750)读入内部存储器705,将权重750的所述子集应用于所有N个图像,并将权重750的所述子集的贡献添加到存储在内部存储器705中的N个图像的中间结果。然后,NN引擎将权重750的下一子集(例如,下16K的权重750)读入内部存储器705,从而覆盖权重750的第一子集,以此类推。
在这个示例中,可重复这个过程1000次以处理层755的全部1600万个参数。以这种方式,将读取所述1600万权重的开销分摊到这N个图像,将相关的读取通信量减少至(1/N)×(16000000权重×2字节/权重)。如果N=16,则针对批处理的读取通信量是32MB,而不是256MB。然后,NN引擎针对权重760和层765执行描述的过程,并再对权重770和层775执行描述的过程。NN引擎针对层780执行最后的处理,以产生输出分类。例如,层780可被实现为软性最大层(softmax layer),软性最大层被配置为从全连接层输出找到具有最大可能性的分类。因此,NN引擎针对整批N个图像一次读取特征分类层745中的每一层的权重,而不是针对这N个图像中的每个图像进行一次读取。如这里参照特征分类层745的描述而处理的一批16个图像将具有针对特征分类层745读取的权重的数量的1/16(与逐一地处理每个图像相比)。如果特征分类层745构成神经网络的大约90%的权重,则本公开中描述的示例实施例节省用于执行神经网络的权重通信量的大约84%(15/16×9/10)。
图8是示出执行神经网络的示例方法800的流程图。更具体地,图8示出执行神经网络的特征分类层的示例方法800。方法800可在NN引擎已如这里描述的通过神经网络的特征提取层处理多个图像的状态下开始。可使用如所述的分割和图块来执行特征提取层。在一个示例中,可如参考图2描述的由NN引擎执行方法800。
在块805,NN引擎选择神经网络的层(即,特征分类层)作为用于处理的当前层。在块810,将当前层的权重的集装载到内部存储器中。被装载到内部存储器中的权重可以是当前层的权重的子集。此外,当前层的装载的权重的所述子集可以是允许NN引擎将N个图像中的每个图像的中间结果与这N个图像的中间结果存储在内部存储器中的很多权重。
在块815,NN引擎将在块810装载的权重的集应用于图像的集中的图像的中间结果。在块820,NN引擎将来自权重的集的贡献添加到内部存储器中的该图像的中间结果。
在块825,NN引擎确定是否还留有任何将针对当前层被处理的通过神经网络的特征分类层处理的一批图像中的不同图像的进一步的中间结果。如果留有,则方法800循环回块815来处理下一图像的中间结果。如果否(例如,已经使用在块810装载的权重的集处理这批图像中的所有图像),则方法800继续到块830。
在块830,NN引擎确定是否存在将应用于图像的当前层的另外的权重。如果是,则方法800循环回块810来装载当前层的权重的下一集合(例如,子集)。如果否,则方法800继续到块835。在块835,NN引擎确定是否存在将被执行的神经网络的任何其他的层(例如,特征分类层)。如果是,则方法800循环回块805来选择下一特征分类层并继续处理。如果否,则方法800结束。
图9是示出用于确定神经网络的锥台的示例数据处理系统(系统)900的示图。例如,系统900被用于实现如参考图6在这里描述的分割过程。在另一示例实施例中,系统900被用于执行神经网络。
如图,系统900包括通过系统总线915或其他合适的电路连接到存储器元件910的至少一个处理器(例如,中央处理器(CPU))905。系统900将计算机可读指令(也被称为“程序代码”)存储在存储器元件910中。存储器元件910可被看作计算机可读存储介质的示例。处理器905执行经由系统总线915从存储器元件910存取的程序代码。在一个示例中,处理器905可被实现为如关于图2所描述的。
存储器元件910包括一个或多个物理存储器(例如,诸如本地存储器920以及一个或多个大容量存储装置925)。本地存储器920是指在程序代码的实际执行期间通常使用的RAM或其他非持久性存储器装置。大容量存储装置925可被实现为硬盘驱动器(HDD)、固态驱动器(SSD)或其他持久性数据存储装置。系统900还可包括提供至少一些程序代码的暂时存储的一个或多个高速缓冲存储器(未示出),以便减少程序代码在执行期间必须从大容量存储装置925提取的次数。
输入/输出(I/O)装置(诸如键盘930、显示器装置935、指示装置940)和一个或多个网络适配器945可连接到系统900。I/O装置可直接或通过中间I/O控制器连接到系统900。在一些情况下,一个或多个I/O装置可被组合为触摸屏被用作显示器装置935的情况。在这种情况下,显示器装置935也可实现键盘930和指示装置940。网络适配器945可被用于通过中间的私有网络或公共网络将系统900连接至其他系统、计算机系统、远程打印机和/或远程存储装置。调制解调器、光缆调制解调器、以太网卡、无线收发器和/或无线广播是可与系统900一起使用的网络适配器945的不同类型的示例。根据系统900的特定实施方式,具体类型的网络适配器或视情况而定的网络适配器将变化。
如图9所示,存储器元件910可存储操作系统950以及一个或多个应用955。例如,应用955可以是神经网络实用工具,当被执行时,将神经网络分割和/或执行神经网络。例如,应用955可包括使处理器905执行方法500、600和/或800中的一个或多个方法的程序代码。以这种方式,处理器905是用于执行由一个或多个计算机程序定义的功能的专用处理器。
在一个方面,以可执行程序代码的形式实现的操作系统950和应用955被系统900执行,具体地,被处理器905执行。如此,操作系统950和应用955可被看作系统900的集成部分。操作系统950、应用955和由系统900使用、产生和/或操作的任何数据项是当被系统900利用时赋予功能的功能性数据结构。
在一个方面,系统900可以是适于存储和/或执行程序代码的计算机或其他装置。系统900可表示包括处理器和存储器的多种计算机系统和/或装置中的任何计算机系统和/或装置并且能够执行本公开中描述的操作。这种系统的示例可包括移动装置、智能电话和/或其他便携式计算和/或通信装置。在一些情况下,特定的计算机系统和/或装置可包括比所述更少或更多的组件。系统900可被实现为如所示的单个系统或被实现为多个网络化的或互连的系统,其中,每个系统具有与系统900相同或相似的架构。
在一个示例中,系统900可接收神经网络作为输入。系统900在执行操作系统950和应用955的过程中可分割神经网络并将分割的神经网络存储在存储器或计算机可读存储介质中,以待后续执行。
这里使用的术语仅是为描述特定实施例的目的,而不意在限制。尽管如此,现在仍将呈现贯穿本文所应用的一些定义。
如在这里定义的,除非另有明确指示,否则单数形式意在也包括复数形式。
如在这里定义的,术语“另一”意思是至少第二或更多。
如在这里定义的,除非明确地另有陈述,否则术语“至少一个”、“一个或多个”以及“和/或”是在操作中既是结合性的又是分离性的开放式表述。例如,“A、B和C中的至少一个”、“A、B或C中的至少一个”、“A、B和C中的一个或多个”、“A、B或C中的一个或多个”以及“A、B和/或C”中的每个表述意思是仅A、仅B、仅C、A和B一起、A和C一起、B和C一起或者A、B和C一起。
如在这里定义的,术语“自动地”意思是没有用户介入。
如在这里定义的,术语“计算机可读存储介质”意思是包含或存储由指令执行系统、设备或装置使用的或与指令执行系统、设备或装置有关的程序代码的存储介质。如在这里定义的,“计算机可读存储介质”本身不是暂时的传播的信号。计算机可读存储介质可以是(但不限于)电子存储装置、磁性存储装置、光学存储装置、电磁存储装置、半导体存储装置或上述任何合适的组合。如在这里描述的存储器元件是计算机可读存储介质的示例。计算机可读存储介质的更具体示例的非穷尽的列表可包括:便携式计算机软盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦写可编程只读存储器(EPROM或闪存)、静态随机存取存储器(SRAM)、便携式致密盘只读存储器(CD-ROM)、数字多功能盘(DVD)、记忆棒、软盘等。
如在这里定义的,除非另有指示,否则术语“连接”意思是没有任何中间元件的连接或是利用一个或多个中间元件非直接地连接。两个元件可通过通信信道、通路、网络或系统进行机械地、电地或通信链接地连接。
如在这里定义的,除非上下文另有指示,否则术语“可执行的操作”或“操作”是由数据处理系统或数据处理系统内的处理器执行的任务。可执行的操作的示例包括(但不限于)“处理”、“运算”、“计算”、“确定”、“显示”、“比较”等。在这点上,操作是指数据处理系统(例如,计算机系统或类似电子计算装置)的动作和/或处理,所述动作和/或处理将被表示为计算机系统的寄存器和/或存储器内的物理(电子)量的数据操控并转换成被类似表示为计算机系统存储器和/或寄存器或其他这种信息存储、传输或显示装置内的物理量的其他数据。
如在这里定义的,术语“包括”和/或“包含”指定存在陈述的特征、整体、步骤、操作、元件和/或组件,但是不排除存在或添加一个或多个其他特征、整体、步骤、操作、元件、组件和/或它们的组。
如在这里定义的,根据上下文,术语“如果”意思是“当……时”或“在……时”或“响应于”或“作为对……的回应”。因此,根据上下文,短语“如果确定”或“如果检测到[陈述的条件或事件]”可被解释为意味着“在确定……时”或“响应于确定……”或“在检测到[陈述的条件或事件]”或“响应于检测到[陈述的条件或事件]”或“作为对检测到[陈述的条件或事件]的回应”。
如在这里定义的,术语“一个实施例”、“实施例”或类似语言意思是在本公开中描述的至少一个实施例中包括了关于所述实施例描述的特定的特征、结构或特性。因此,贯穿本公开出现的短语“在一个实施例中”、“在实施例中”和类似语言可(但不必须)全部是指相同的实施例。术语“实施例”和“布置”在本公开中可互换使用。
如在这里定义的,术语“输出”意思是存储在物理存储器元件(例如,装置)中、写入显示器或其他外设输出装置、发送或传输至另一系统、出口等。
如在这里定义的,术语“多个”意思是两个或多于两个。
如在这里定义的,术语“处理器”意思是被配置为执行包含在程序代码中的指令的至少一个硬件电路。硬件电路可以是集成电路。处理器的示例包括(但不限于)中央处理器(CPU)、阵列处理器、向量处理器、数字信号处理器(DSP)、现场可编程门阵列(FPGA)、可编程逻辑阵列(PLA)、专用集成电路(ASIC)、可编程逻辑电路、图形处理器(GPU)、控制器等。
如在这里定义的,术语“实时”意思是用户或系统感受的作出的特定处理或确定是足够及时的或能使处理器跟上一些外部处理的处理响应性的程度。
如在这里定义的,术语“作为对……的回应”意思是对动作或事件快捷地响应或反应。因此,如果执行第二动作“作为对第一动作的回应”,则第一动作的出现和第二动作的出现存在因果关系。术语“作为对……的回应”表示所述因果关系。
如在这里定义的,术语“用户”意思是人。
术语“第一”、“第二”等可在这里使用以描述各种元件。除非另有陈述或上下文明确地另有指示,否则这些元件不应被这些术语限制,因为这些术语只是用来将一个元件与另一元件区分开。
计算机程序产品可包括计算机可读存储介质,在计算机可读存储介质上具有用于使处理器执行本发明的方面的计算机可读程序指令。在本公开中,术语“程序代码”与术语“计算机可读程序指令”可互换使用。这里描述的计算机可读程序指令可经由网络(例如,互联网、LAN、WAN和/或无线网络)从计算机可读存储介质被下载到各个计算/处理装置或被下载到外部计算机或外部存储装置。网络可包括铜传输电缆、光传输光纤、无线传输、路由、防火墙、交换机、网关计算机和/或包括边缘服务器的边缘装置。在每个计算/处理装置中的网络适配卡或网络接口从网络接收计算机可读程序指令并且将计算机可读程序指令转发,用于各个计算/处理装置中的计算机可读存储介质中的存储。
用于执行这里描述的发明布置的操作的计算机可读程序指令可以是汇编指令、指令集架构(ISA)指令、机器指令、依赖机器指令(machine dependent instruction)、微代码、固件指令或者写入一个或多个编程语言(包括面向对象语言和/或过程编程语言)的任意组合的源代码或目标代码。计算机可读程序指令可指定状态设置数据。计算机可读程序指令可完全在用户计算机上、部分地在用户计算机上、作为独立软件包、部分地在用户计算机上并且部分地在远程计算机上、或者完全在远程计算机或服务器上执行。在后面的情况下,远程计算机可通过任何类型的网络(包括LAN或WAN)连接到用户计算机,或者可对外部计算机做连接(例如,通过使用互联网服务提供商的互联网)。在一些情况下,包括例如可编程逻辑电路、FPGA或PLA的电子电路可通过利用计算机可读程序指令的状态信息将电子电路个性化来执行计算机可读程序指令,以便执行这里描述的发明布置的方面。
参考方法、设备(系统)和计算机程序产品的流程示图和/或块示图在这里描述了本发明布置的一些方面。将理解,流程示图和/或块示图中的每个块以及流程示图和/或块示图中的块的组合可由计算机可读程序指令(例如,程序代码)实现。
这些计算机可读程序指令可被提供给用于产生机器的专用计算机的处理器或其他可编程数据处理设备,使得通过计算机的处理器或其他可编程数据处理设备而执行的指令创建用于实现在流程图和/或块示图的块中指定的功能/动作的方法。这些计算机可读程序指令还可被存储在能指导计算机、可编程数据处理设备和/或其他装置以特定方式起作用的计算机可读存储介质中,使得其中存储有指令的计算机可读存储介质包括包含指令的制造产品,所述指令实现在流程图和/或块示图的块中指定的操作的方面。
计算机可读程序指令还可被装载到计算机、其他可编程数据处理设备、或其他装置上,以使一系列操作在计算机、其他可编程数据处理设备、或其他装置上被执行以产生计算机实现的处理,使得在计算机、其他可编程数据处理设备、或其他装置上执行的指令实现在流程图和/或块示图的块中指定的功能/动作。
附图中的流程图和块示图示出根据本发明布置的各个方面的系统、方法和计算机程序产品的可能实现的架构、功能和操作。在这点上,流程图或块示图中的每个块可表示包括用于实现指定的操作的一个或多个可执行指令的模块、区段或指令的部分。在一些可选实现中,在块中指出的操作可不以附图中指出的顺序发生。例如,根据涉及的功能,连续示出的两个块可基本上同时被执行,或者有时可以以相反的顺序被执行。还将注意,在块示图和/或流程示图中的每个块以及在块示图和/或流程示图中的块的组合可由执行专门功能或动作或者执行专用硬件和计算机指令的组合的专用的基于硬件的系统实现。
为了说明的简单和清晰的目的,在附图中示出的元件不必须按比例绘制。例如,为了清楚,一些元件的维度可相对于其他元件被夸大。此外,在认为合适的地方,参考标号在附图中被重复以表示相应的、类似的或相同的特征。
可在权利要求书中发现的所有方法或步骤以及功能元件的相应的结构、材料、动作和等同物意在包括如特别主张的用于执行结合其他主张的元件的功能的任何结构、材料或动作。
这里提供的本发明布置的描述是为了说明的目的而不意在穷尽或限于所公开的形式和示例。选择这里使用的术语以解释本发明布置、实际应用或在市场中发现的技术中的技术改良的原理,和/或使本领域的其他普通技术人员理解这里公开的实施例。在不脱离描述的发明布置的范围和精神的情况下,修改和变化对于本领域的那些普通技术人员而言是明显的。因此,在表示这些特征和实现的范围时应参考权利要求书而不是上述公开。
- 还没有人留言评论。精彩留言会获得点赞!