异构计算系统和方法与流程
【技术领域】
本发明实施例关于异构计算,尤其是关于异构计算系统和方法。
背景技术:
根据丹那德微缩(dennardscaling),电压和电流应该与晶体管的线性尺寸成比例,且功耗(电压和电流的乘积)应该与晶体管的面积成比例。由于晶体管的大小持续缩减,可以放进芯片相同面积的晶体管的数目以指数方式增加。因此,预测每瓦计算性能还可以指数增加。然而,丹那德微缩似乎在近十年里被破坏了。即使晶体管的大小持续缩减,每瓦计算性能并没有以相同的速率改进。对于丹那德微缩的破坏有各种原因。一个原因就是很小的电流泄漏可导致芯片发热,这将增加能量成本以及热流失的风险。为了防止热流失,芯片上的部分硅在给定热设计功率(tdp)约束的标称操作电压下不能被打开(poweron)。此现象被称作“暗硅(darksilicon)”,在现代处理器中显著地约束每瓦计算性能。
丹那德微缩的破坏已经提示芯片制造商采取多核处理器设计。然而,即使多核处理器也遭遇相同的“暗硅”问题。依据处理器架构、冷却技术以及应用工作负担,暗硅的数量可超过50%。因此,在现代计算机系统中需要改进能量和计算效率。
技术实现要素:
有鉴于此,本发明提出一种异构计算系统和方法。
在一个实施例中,揭示一种异构计算系统。系统包含多个不同处理器类型的处理器,其中每个处理器包含内部存储器单元以储存其当前上下文;并行处理模块,包含多个执行单元;以及切换模块,耦合到处理器和并行处理模块,其中切换模块根据控制信号选择处理器的一个以使用并行处理模块,用于并行执行具有多个数据条目的指令。
在另一实施例中,揭示一种由异构计算系统执行的方法。包含根据控制信号,选择多个处理器的一个以连接异构计算系统中的并行处理模块,其中所述器包含不同处理器类型且每个处理器包含内部存储器单元以储存其上下文,以及其中并行处理模块包含多个执行单元;由并行处理模块从处理器的一个接收具有多个数据条目的指令;以及由执行单元并行对多个数据条目执行指令。
基于以上方案,本发明可以改进能量和计算效率。
【附图说明】
图1图示根据一个实施例的异构计算系统的架构。
图2图示根据一个实施例的异构计算系统中不同处理器类型的处理器。
图3图示根据一个实施例的统一解码器的示例。
图4是图示根据一个实施例的处理器切换过程的流程图。
图5图示根据一个实施例的上下文切换控制器的示例。
图6是图示根据一个实施例的由异构计算系统执行的方法的流程图。
【具体实施方式】
在以下的描述中,阐述许多具体细节。然而,要理解,本发明的实施例可在没有这些具体细节的情况下实践。在其它实例中,已知电路、结构和技术没有详细显示以防止模糊了对此描述的理解。然而,本领域的技术人员将意识到,本发明可在没有这样的具体细节下实践。本领域的普通技术人员利用所包含的描述,将能够在不需要过度实验的情况下实现适当的功能。
异构计算系统包含多于一个类型的处理器工作协力执行计算任务。例如,异构计算系统可包含处理器,例如,一个或多个中央处理单元(cpu)、一个或多个图形处理单元(gpu)、一个或多个数字信号处理器(dsp)、一个或多个专用指令组处理器(asip)、一个或多个专用集成电路(asic)等。在一些实施例中,处理器可都集成到芯片上系统(soc)平台。
作为示例,异构计算系统可包含cpu、gpu、dsp、asip和asic的组合。cpu执行通用计算任务。dsp和asip执行信号、图像和/或多媒体处理操作。dsp和asip都是可编程的。asip的示例是执行由系统支持的特定功能的专门的硬件加速器。asic是执行预定序列特定操作的固定功能处理器;例如,编码和解码。gpu执行图形处理任务;例如,创建3d场景的2d光栅表示。这些图形处理任务被称作3d图形管线或渲染管线。3d图形管线可以由用于加速计算的固定功能的硬件以及允许在图形渲染中的灵活性的通用可编程硬件的组合来实施。通用可编程硬件也被称作着色器硬件。除了渲染图形,着色器硬件还可执行通用计算任务。
异构计算系统中的处理器典型地包含并行执行硬件,用于执行单个指令多个数据(single-instruction-multiple-data,simd)操作。在现有技术系统这样的simd架构单独地实施于每个处理器中。因此,在这些系统中,simd架构被复制。由复制的simd架构占据的区域没有完全利用,因为不是所有处理器同时执行simd执行。
根据本发明的实施例,异构计算系统使用包含多个执行单元的共享的并行处理模块(例如,算术逻辑单元(alu))执行simd操作。执行单元的共享减少了硬件成本并增加了硬件利用。当simd执行从一个处理器到另一处理器的切换时,为了减少上下文切换开销,每个处理器保持单独的存储器控制。更具体地,每个处理器在其内部存储器单元(例如,寄存器和/或缓冲器)保持其上下文。每个处理器也具有其自己的存储器接口,用于从系统存储器(例如,动态随机存取存储器(dram))装置存取指令和数据。单独的存储器控制减少上下文切换的数目并因此增加能量和计算效率。
计算中的术语“上下文切换”通常指的是储存和恢复过程或线程的状态(也被称作“上下文”)以便可以在以后从相同的点继续执行的机制。上下文的示例包含,但不限于程序计数器、堆栈指针、寄存器内容等。根据本发明的实施例,共享执行单元的处理器在本地且单独地储存他们的相应上下文(例如,执行状态),以便当simd执行从第一处理器到第二处理器的切换时,没有或很少上下文切换开销用于储存第一处理器的上下文以及恢复第二处理器的上下文。即,不使用用于处理器间上下文切换的通常方法和共享的缓冲器,每个处理器在其内部存储器单元(例如,本地缓冲器)储存其自己的上下文。当simd执行从第一处理器到第二处理器的切换时,第一处理器的上下文保持在第一处理器中,并当后面需要时准备好使用。第二处理器的上下文在第二处理器中,并可由第二处理器立刻使用。单独的上下文管理避免当simd执行处理器之间的切换时上下文存储和恢复的时间和能量消耗。
此外,每个处理器具有其自己的存储器接口,用于从系统存储器存取指令、数据和其它信息。术语“存储器接口”指的是可以存取系统存储器的处理器中的硬件单元。存储器接口的示例包含,但不限于直接存储器存取(dma)单元、负载和储存单元等。具有单独的存储器接口使处理器能保持他们的具体数据流控制。
图1图示根据一个实施例的异构计算系统100的示例架构。系统100包含不同类型的多个处理器112,例如,gpu、dsp、asip、asic等(在图1中显示为p1,p2,…pn)。在一个实施例中,每个处理器112包含存储器接口118用于存取系统存储器160(例如,动态随机存取存储器(dram)或其它易失性或非易失性随机存取存储器)。一些处理器可包含处理器上缓存器和/或处理器上缓冲器。一些处理器112可包含不同于其它处理器112的特定功能的单元。一些(例如,至少两个)处理器112具有定义不同指令和/或指令格式的不同指令组架构(isa)。在一个实施例中,每个处理器112可以是执行由其isa定义的指令的可编程处理器。在另一实施例中,处理器112可包含固定功能的处理器或可编程处理器与固定功能的处理器的组合。
处理器112经由互连150连接到系统存储器160。处理器112也连接到切换模块120,其还连接到统一的解码器130和并行的处理模块140。切换模块120可以被控制以将任何一个处理器112连接到统一的解码器130和并行的处理模块140。并行的处理模块140包含多个执行单元(eu)142;例如,alu。每个执行单元142执行算术或逻辑操作,且并行的处理模块140,作为整体执行simd操作。即,并行的处理模块140可以并行方式在多个数据条目上执行单个指令。由执行单元142执行的指令具有根据定义用于并行的处理模块140的指令组架构(isa)的指令格式。由执行单元142执行的数据具有定义于一组统一的数据格式的统一的数据格式。例如,统一的数据格式可包含全精度、短整数、浮点、长整数等。在一个实施例中,并行的处理模块140可包含在数据阵列上执行向量操作的向量执行单元。
在一个实施例中,切换模块120由上下文切换控制器170控制,其可以是硬件单元或位于一个或多个cpu或其它控制硬件或由一个或多个cpu或其它控制硬件执行的软件方法。上下文切换控制器170确定simd执行应该切换到哪个处理器112,并生成选择处理器112连接到并行的处理模块140的控制信号。上下文切换控制器170的示例在图5中提供。在一个实施例中,处理器112可发送请求,如果有任何优先级信息,则和优先级信息一起发送到上下文切换控制器170(在图1中显示为单线箭头)以请求连接。选择的处理器112然后可经由切换模块120和统一的解码器130发送具有多个数据条目的指令(在图1中显示为具有填充图案的箭头)到并行的处理模块140用于执行。在一个实施例中,统一的解码器130可解码或翻译指令到统一的指令格式以及将伴随的源操作数解码或翻译为统一数据格式用于由并行处理模块140执行。即,统一解码器130可解码或翻译不同的isa指令为并行处理模块140的isa。在执行指令后,执行结果发送到系统存储器160或处理器上缓冲器。
在一个实施例中,异构计算系统100可以是移动计算和/或通信装置(例如,智能电话、平板电脑、膝上型计算机、游戏装置等)的一部分。在一个实施例中,异构计算系统100可以是台式计算系统、服务器计算系统或云计算系统的一部分。
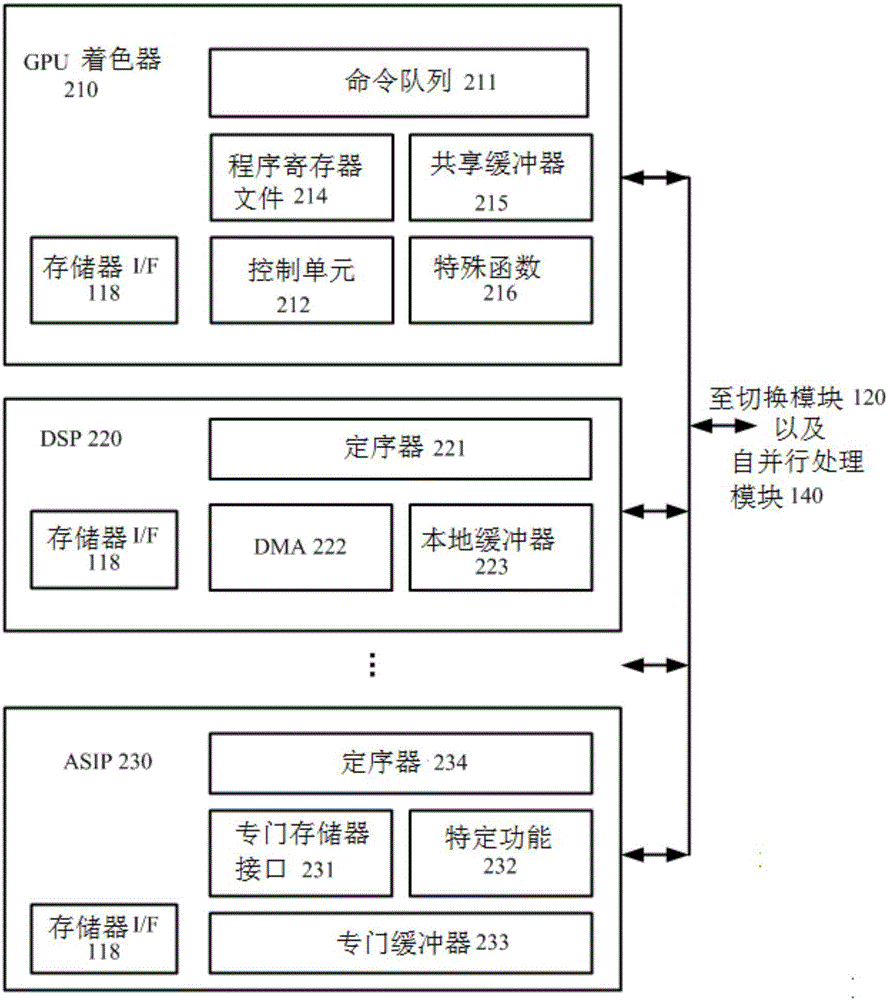
图2图示根据一个实施例的图1的处理器112的示例。例如,处理器112可包含gpu着色器210、dsp220以及asip230。尽管三个处理器类型显示于在此示例中,要理解,在备选实施例中存在更多或更少处理器类型,且每个处理器类型可具有任何数量的处理器。此外,也应理解所示gpu着色器210、dsp220以及asip230的功能的特征出于说明的目的已经被简化,在备选实施例中,这些处理器可包含更多、更少和/或不同于显示于图2中的部件。在图2的实施例中,所有三个处理器112具有不同的isa;在备选实施例中,处理器112可具有更多或更少(至少两个)不同的isa。此外,尽管未示出于图2的示例中,在上述备选实施例中,处理器112可包含固定功能的处理器,例如,asic用于执行指定操作的预定序列。每个处理器112可以选择以发送simd指令和数据到并行处理模块140用于simd操作,且可从并行处理器140接收执行结果(即中间数据)。
gpu着色器210是专门用于图形操作的可编程处理器。在一个实施例中,gpu着色器210包含命令队列211、控制单元212、程序寄存器文件214、共享缓冲器215、特殊函数216、存储器接口118以及其它单元。控制单元212的示例包含但不限于,分支预测符、命令获取单元等。dsp220是可编程处理器,其包含定序器221、直接存储器访问(dma)222、本地缓冲器223、存储器接口118以及其它单元。asip230也是可编程处理器,其包含专门存储器接口231、专门缓冲器233、特殊函数232、定序器234、存储器接口118以及其它单元。此外,gpu着色器210、dsp220以及asip230的一个或多个可包含,用于储存近来访问的和/或从系统存储器160获取的预获取的数据的缓存,以及用于储存在其它信息中由并行处理模块140生成的中间数据的缓冲器或其它类型的临时存储器。dsp220以及asip230是可编程处理器,用于执行特定功能。特定功能216和232的示例包含但不限于:特定数学功能的单元,例如,正弦、余弦和对数功能、图形处理、语音数据处理、视频处理以及图像处理。
在一个实施例中,每个处理器包含内置机制(例如,命令队列211、定序器221以及定序器234)用于确定接下来执行哪个指令,以及内部寄存器或缓冲器(即,处理器上寄存器或处理器上缓冲器)用于储存当前上下文,例如程序计数器、堆栈指针、寄存器内容等。当simd执行从第一处理器到第二处理器的切换时,第二处理器储存的上下文可以快速(例如,一个周期内)从其内部寄存器或缓冲器获取以开始该执行过程。第一处理器的上下文储存于其内部寄存器或缓冲器,用于当simd执行切换到第一处理器时快速获取。
尽管每个处理器包含内部寄存器或缓冲器,以储存其上下文,在一些场景中,上下文的数量可超过这些内部寄存器或缓冲器的容量。例如,当单个处理器执行多个任务,且一个或多个任务具有实时约束,处理器可在多个任务中切换上下文。为了储存这些多个任务的上下文,如果上下文的数量超过其内部上下文存储容量,处理器可使用外部缓冲器(即,处理器外缓冲器或芯片外缓冲器)以储存上下文。
图3是图示统一解码器130的一个实施例的示意图。在本实施例中,统一解码器130包含前端331和后端332,由切换模块120分开。前端331和后端332分别是来自切换模块120的上游和下游。前端331还包含数据获取(310a-d)和指令解码(320a-d)。使用处理器p1作为示例,由p1获取的指令由指令解码320a解码。指令解码320a根据处理器p1的isa解码指令。数据获取310a根据解码指令从处理器上存储器(例如,数据缓存)获取来源操作数。然后,当p1被选择用于连接并行处理模块140时,指令和获取的数据经由切换模块120被发送到后端332。
在一些实施例中,前端331可以是一个或多个处理器112的部分;即,处理器的本地解码和获取电路的部分。例如,如虚线所示,处理器p1可包含指令解码320a和数据获取310a为其本地解码和获取电路的部分。如果解码为非simd指令则指令由p1执行;如果解码为simd指令,指令被发送到并行处理模块140用于执行。在一些实施例中,一个或多个处理器112,例如,固定功能的处理器执行操作的预定序列,并因此不需要解码指令。这些固定功能的处理器不包含本地解码电路用于解码指令。在此情况下(例如,p4),当执行simd操作时,统一解码器130提供生成指示符的指令解码320d。指示符可指定待执行的simd操作以及simd操作的数据格式。当p4选择用于连接并行处理模块140时,由数据获取310d获取的指示符和来源操作数然后经由切换模块120发送到后端332。
在图3的实施例中,统一解码器130的后端332包含数据管线330和指令翻译340。指令翻译340可将来自不同处理器112(例如,不同isa)的指令翻译为由并行处理模块140执行的统一指令格式。此外,数据管330可修改来自处理器112的数据(例如,源操作数)为由并行处理模块140执行的统一数据格式。例如,如果源操作数是双精度格式,且双精度不由并行处理模块140支持,则数据管330可修改源操作数为浮点数据。由图3的部件执行的过程将参考图4在以下提供。
图4是图示根据一个实施例的处理器切换过程400的流程图。过程400可以由异构计算系统执行,例如,图1的系统100。当控制信号选择处理器(“目标处理器”)以使用并行处理模块140用于simd执行(步骤410),目标处理器根据其在本地储存的上下文获取指令以执行(步骤420)。目标处理器可从其指令缓存或储存在目标处理器中本地的命令队列获取指令。解码指令以及获取源操作数(步骤430),其然后经由切换模块120发送到统一解码器130(例如,图3的后端332)。统一解码器130解码或翻译指令为可执行格式用于由并行处理模块140执行的simd(步骤440)。在接收指令和来源操作数后,执行单元142并行对多个来源操作数执行相同指令(步骤450)。并行处理模块140返回执行结果到处理器112(simd指令从其发送)或系统存储器160(步骤460)。
当每次处理器选择用于simd执行时,过程400从步骤410重复。例如,当控制信号选择另一处理器(“下一处理器”)用于simd执行时,下一处理器可使用其在本地储存的上下文以获取指令用于执行而不重装载和恢复上下文到其本地存储器。此外,以前的处理器(即,目标处理器)的上下文可保留在本地在目标处理器中。目标处理器可使用其在本地储存的上下文继续执行非simd操作,或可等待其顺序以再次使用并行处理模块140用于simd执行。
图5是图示图1的上下文切换控制器170的实施例的示意图。在本实施例中,上下文切换控制器170包含第一硬件仲裁模块510和第二硬件仲裁模块520。在备选实施例中,上下文切换控制器170可包含更多、更少或不同于图5中所示的硬件模块。在备选实施例中,一些硬件模块可以至少部分地由运行于硬件处理器上的软件实施。
上下文切换控制器170可使用不同的硬件模块以为具有不同优先级的请求实现不同的排程策略。例如,在图5的实施例中,来自不指示优先级的处理器的请求可由第一硬件仲裁模块510处理,第一硬件仲裁模块510根据预定第一策略来排程请求;例如,循环策略。来自指示优先级或实时约束的处理器请求可由第二硬件仲裁模块520处理,第二硬件仲裁模块520根据预定第二策略来排程请求,例如,优先级排程。即,具有更高优先级设定或更紧实时约束的请求首先排程以便连接。例如,来自软件系统具有高优先级设定的请求可以是来自运行语音呼叫软件应用以处理语音呼叫dsp的请求。语音呼叫可以在来自过程(例如,背景过程)低优先级请求之前连接到并行处理模块140。作为另一示例,具有来自硬件系统的实时约束的请求可以是来自视频解码器的请求。视频解码器可要求满足实时约束以每秒解码特定数目的帧。具有实时约束的这样的请求被给出高的优先级。当请求被处理,上下文切换控制器170发出控制信号以经由切换模块120连接请求处理器到并行处理模块140。
图6是图示根据一个实施例的由异构计算系统,例如,图1的系统100,执行的方法600的流程图。参考图6,当系统根据控制信号选择多个处理器的一个连接到异构计算系统中的并行处理模块,方法600开始(步骤610)。处理器包含不同的处理器类型,且每个处理器包含内部存储器单元以储存其上下文。此外,并行处理模块包含多个执行单元。并行处理模块从选择的一个处理器接收指令和多个数据条目(步骤620)。然后,并行处理模块中的执行单元并行对多个数据条目执行指令(步骤630)。
每当控制信号选择不同的处理器用于simd时方法600可重复步骤610-630。处理器间的上下文切换出现很少或没有开销。在一个实施例中,并行处理模块用于在第一时钟内完成第一处理器的执行,并在第一时钟周期后的第二时钟周期内从第二处理器接收数据。
具有共享的计算单元和单独的存储器控制的异构计算系统已经描述。计算单元(例如,并行处理模块140)的共享减少硬件成本并增加硬件利用。每个处理器的单独的存储器控制使处理器能保持其上下文和数据流控制,并因此减少上下文开关开销。由此,可改善系统的整个能量和计算效率。
图4和6的流程图的操作已经参考图1、3和5的示范性实施例描述。然而,应该理解图4和6的流程图的操作可以由除了图1、3和5讨论之外的本发明实施例执行,且参考图1、3和5讨论的实施例可执行不同于参考流程图讨论的实施例的操作。尽管图4和6的流程图显示由本发明的某些实施例执行的操作的特定顺序,应该理解这样的顺序是示范性的(例如,备选实施例可以不同顺序、结合某些操作、重复某些操作等执行操作)。
尽管本发明已经在若干实施例方面描述,本领域技术人员将意识到本发明不限于所述实施例,且可以在所附权利要求的精神和范围内以修改和替代来实践。描述因此被看作是说明性的而不是限制性的。
- 还没有人留言评论。精彩留言会获得点赞!