一种网页表格信息抽取方法与流程
本发明涉及网页信息抽取领域,具体涉及一种网页表格信息抽取方法。
背景技术:
随着web技术日新月异的进步,网页能够容纳海量数据,但是,有许多用户不关心的信息充斥在网页中,如广告图像和推广链接等,这些信息甚至与网页中的正文内容混淆,使用户难以迅速地从网页中获取重要信息。此外,如果用户想要让目标信息挪作他用,只能先手动摘取信息,同时还要去掉HTML标签或其它噪声信息,然后再重新整理,最后才能按照自己的意愿展现这些目标信息,这样做不仅准确率低,而且费时费工,效率低下。
表格(Table)因其能够简洁而有效地表达关系信息的特点,在各领域的网页中被广泛使用,对于大部分Table标签而言,它们用来向用户展示关系数据,例如火车时刻表、网上购物、网上银行和管理信息系统等。而现在web信息抽取技术在表格中的应用有限,多数都是首先通过DOM(Document Object Model,文档对象模型)树对网页进行处理之后进行数据抽取,这种处理方式在进行的时候首先会将网页的全部信息加载进内存,倘若处理的页面较多,则会很耗内存;此外,在对表格数据的处理过程中多数应用也仅仅限于将表格中的数据抽取出来,并未对其可能会进行的一些公有操作进行抽取,做出进一步的加工处理,往往影响了对数据进行二次处理的效率。
有鉴于此,急需提供一种网页表格信息抽取的新方法,解决现有的网页表格信息抽取技术对系统资源的消耗较大、对网页数据进行二次处理的效率较低的问题。
技术实现要素:
本发明所要解决的技术问题是解决现有的网页表格信息抽取技术对系统资源的消耗较大、对网页数据进行二次处理的效率较低的问题。
为了解决上述技术问题,本发明所采用的技术方案是提供一种网页表格信息抽取方法,包括以下步骤:
用户预先对操作文件进行配置;
用户输入所要抓取网页的URL地址,并由java系统对该网页进行抓取;
java系统对抓取到的网页进行预处理;
java系统根据用户手动输入的信息对网页进行解析和定位,同时,生成抽取规则并存入规则库进行维护;
java系统根据抽取规则在页面抽取所需数据,并将抽取到的数据存入MySQL数据库;
java系统根据操作文件的配置,利用JSP页面将抽取到的数据以动态页面的形式展示给用户,供用户操作。
在上述技术方案中,用户根据预先定义好的格式在所述操作文件中添加所要进行的操作,包括对网页表格数据的确认、修改和删除操作。
在上述技术方案中,所述预先定义好的格式与所述java系统对所述操作文件进行解析时所用格式一致。
在上述技术方案中,所述java系统对抓取到的网页进行预处理包括去除网页中不相干的图片、视频、音乐、大段文字、导航栏和将HTML文件格式化。
在上述技术方案中,当所述网页内容较多时,对所述网页进行去噪处理。
在上述技术方案中,所述操作文件为manipulate.conf。
在上述技术方案中,所述抽取规则包括所需数据位于所述页面第几个表和第几列的信息。
在上述技术方案中,所述java系统采用java开源工具包Jsoup对所述网页进行解析和定位。
本发明减少了网页表格信息抽取过程中对系统资源的消耗,加快了网页表格信息抽取的速度,方便了用户对抽取出的网页表格数据进行二次处理,提高了用户对网页表格数据进行二次处理的效率。
附图说明
图1为本发明实施例提供的一种网页表格信息抽取方法流程图;
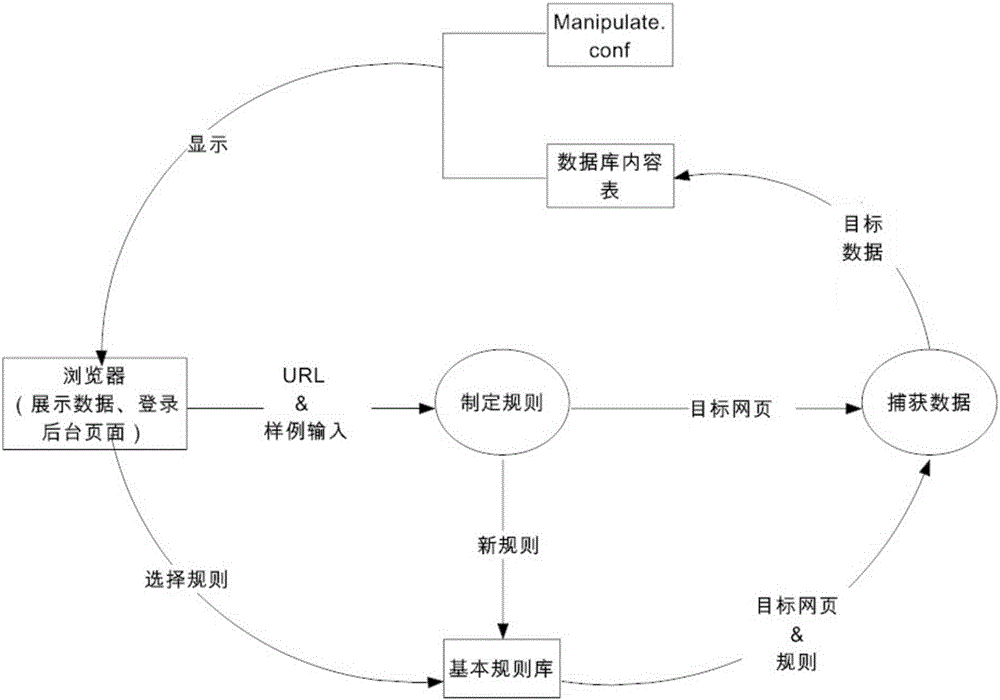
图2为本发明实施例提供的对抽取到的网页表格数据进行再处理的数据流程图。
具体实施方式
本发明涉及操作文件manipulate.conf配置、网页抓取、网页预处理、Jsoup解析、基于表格样本行的表格定位、规则知识库维护、数据抽取、数据规范化和数据持久化、数据及操作展示几个方面的内容,通过用户的示例输入定位网页的目标表格,并且将目标表格的数据存储到数据库,再根据用户的意愿展示出来,让目标数据得以重新利用。从而减少了网页表格信息抽取过程中对系统资源的消耗,加快了网页表格信息抽取的速度,方便了用户对抽取出的网页表格数据进行二次处理,提高了用户对网页表格数据进行二次处理的效率。
下面结合说明书附图和具体实施方式对本发明做出详细的说明。
本发明实施例提供了一种网页表格信息抽取方法,如图1所示,包括以下步骤:
S1、用户根据需求预先对操作文件manipulate.conf进行配置。
用户根据自己最终要对抽取的网页表格数据进行的操作,预先对操作文件manipulate.conf进行配置,根据预先定义好的格式在操作文件manipulate.conf中添加自己所要进行的操作,包括对网页表格数据的确认、修改和删除等操作,上述预先定义的格式,只需与java系统对该操作文件manipulate.conf进行解析时所用格式一致即可。
S2、用户输入所要抓取网页的URL(Uniform Resource Locators,统一资源定位器)地址,并由所写的java系统对该网页进行抓取。
为提高java系统稳定性,要求用户输入的URL地址符合URL标准,否则,当输入的URL地址不符合URL标准时,提交时将弹出相应的提示窗口。
S3、java系统对抓取到的网页进行预处理。
为优化后续对网页的抽取,本发明对抓取到的网页进行预处理,包括去除网页中不相干的图片、视频、音乐、大段文字、导航栏和将HTML文件格式化(即对HTML页面XML序列化)。同时,若网页内容较多可对网页进行去噪处理。
S4、java系统根据用户手动输入的信息,采用java开源工具包Jsoup对网页进行解析和定位,同时,生成抽取规则并存入规则库进行维护。
用户手动输入感兴趣的某一行内容,例如可以是火车售票网的一行车票数据,包括航次、售价、始发点、终点和剩余票数等,方便java系统快速定位用户所需数据。
抽取规则包括所需数据位于页面第几个表、第几列等信息,存入规则库方便以后在此网页类似页面下直接抽取信息以节约时间。
S5、java系统根据抽取规则在页面抽取所需数据,并将抽取到的数据存入MySQL数据库,方便以后对数据进行二次处理。
如图2所示,为本发明实施例提供的对抽取到的网页表格数据进行再处理的数据流程图。
S6、java系统根据操作文件manipulate.conf的配置,利用JSP页面(Java Server Pages,java服务器页面)将抽取到的数据以动态页面的形式展示给用户,供用户操作。
实施例1。
首先定义操作文件manipulate.conf的配置格式如下:
1:转储浏览,0,无;
2:单人签到,2,签到,操作;
3:双人签到,4,员工操作,员工签到,主管操作,主管签到。
假设某公司某部门经理需要其团队的每个人对团队报账单进行签到确认,但是,由于企业级应用结构复杂,涉及的外部资源众多,员工无法获得这些数据的接口,只能手动将表格信息抄录下来再发布出去,同时,签到确认也无法实现自动化,这样不仅大大地浪费了人力和时间,而且还不能保障数据准确可用。按照本发明设计的方案,部门经理可首先配置操作文件manipulate.conf;输入包含团队账目网页的URL地址,将网页抓取下来;对抓取到的网页进行XML序列化处理,同时,若网页杂音较多,可进行去噪处理;由部门经理输入其中某一个人账单的全部数据,据此生成抽取规则,同时将抽取规则加入规则库进行维护;根据抽取规则对该网页进行处理,抽取所需数据;将抽取到的数据存入数据库中;最后,将最终抽取到的数据及在操作文件manipulate.conf中配置的操作展示给部门经理,在该网页中该部门经理所在的部门可以对这些数据进行操作,而部门经理也可以看到本部门同事的签到与否。
上述方法具体包括以下步骤:
S10、部门经理根据定义好的格式在操作文件manipulate.conf中添加如下语句:单人签到,2,签到,操作。
S11、部门经理登录服务网页,在该网页中输入所要抓取网页的URL地址。
S12、若本次抓取到的网页大于4MB,由于本次所要抽取的是账单数据,可以将网页中的音频和图片等信息全部去除,以加快表格定位和识别。
S13、部门经理根据原网页的数据格式输入一行报账数据。
S14、java系统根据部门经理输入的账单数据,采用java开源工具包Jsoup对网页进行解析和定位,最后将此次得到的抽取规则,例如位于第几个表、第几列等信息存入规则库,方便以后在此网站类似页面下直接抽取信息以节约时间。
S15、java系统将根据部门经理输入的账单数据抽取到的数据存入MySQL数据库,方便以后对数据进行二次处理。
S16、java系统根据操作文件manipulate.conf的配置和MySQL数据库中存储的内容,利用JSP页面将抽取到的数据通过浏览器展示给部门经理,在该页面中,部门经理所在部门的员工可以进行签到确认,而该部门经理也可以看到某个员工是否签到确认。
本发明不局限于上述最佳实施方式,任何人在本发明的启示下作出的结构变化,凡是与本发明具有相同或相近的技术方案,均落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!