基于三维非局部均值滤波的高光谱图像分类方法与流程
本发明属于遥感图像处理
技术领域:
,涉及一种高光谱图像分类方法,可用于对高光谱图像的地物分类。
背景技术:
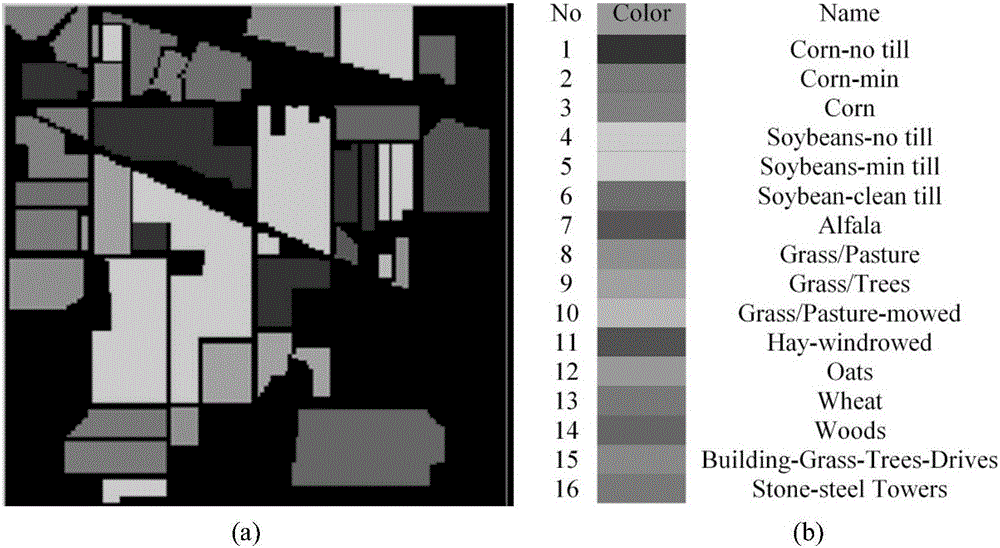
:近几年,高光谱图像分类已经成为高光谱遥感领域的研究热点。高光谱图像分类的目的是为每一点像素分配特定的类别。研究发现相同类别的像素的光谱特征和空间特征具有一致性,不同类别的像素的光谱特性和空间特征具有明显的差异,因此可以利用这个特性来进行高光谱图像分类。高光谱图像数据具有维度高、样本少的特点,是一种典型的三维图像数据,每个像素点包含了上百个光谱波段,所以在处理过程中可以将每点像素表示成光谱向量的形式。为了解决高光谱数据维度高、样本少的现象,传统的方法是利用特征选择、特征降维以及特征联合等方法解决,将空域信息和光谱信息进行分开处理,分别提取空间特征和光谱特征后再进行分类。但是这种方法忽略了高光谱图像数据中光谱信息和空域信息之间的联系,空域信息是通过光谱波段和邻域来联合体现的,所以将空域信息和光谱信息进行分开处理容易产生误差,会影响分来精度,而且分开提取特征也会增加处理数据的时间,增加复杂度。传统的非局部均值滤波主要针对二维图像提出的,由于高光谱图像数据除了具有空间维之外还增加了光谱维,也就是说高光谱图像数据是一种典型的三维数据,所以不能直接将非局部均值滤波应用到高光谱数据上;除此之外,非局部均值滤波中,利用欧式距离来计算领域内两个像素点的相似性,并将其作为权值进行滤波,由于高光谱图像数据中的特征主要通过第三维的光谱通道体现,即高光谱图像中的像素点是用矢量来表示的,此时欧式距离并不能完全体现出两个像素点的相似性,从而导致高光谱图像数据的分类精度降低。技术实现要素:本发明的目的在于针对上述现有技术的不足,提出一种基于三维非局部均值滤波的高光谱图像分类方法。以在提取空-谱域特征的同时较好的将空域信息和光谱域信息进行结合,在降低处理数据所用开销的同时提高分类精度。为实现上述目的,本发明的技术方案包括如下:(1)输入包含k个类别的待分类三维高光谱图像数据及其类别标签,图像大小为m×n×d,将该高光谱图像的像素集表示为X=[x1,x2,...,xs,...,xN],其中,d的取值为高光谱图像的光谱波段总数,xs=[xs1,xs2,……xsd]表示第s点的像素,1≤s≤N,N=m×n表示像素总数;(2)设置邻域的大小ω,则邻域内像素的个数为M=ω×ω,邻域中心的像素为xi,对应的邻域内的像素表示为xj,1≤i≤N,1≤j≤M;(3)对输入的高光谱图像数据X进行三维非局部均值滤波,得到空-谱域特征向量集C:(3a)计算邻域中心的像素xi与邻域内像素xj之间的皮尔逊相关系数rij:rij=cov(xi,xj)std(xi)std(xj)=Σk=1d(xik-x‾i)(xjk-x‾j)Σk=1d(xik-x‾i)2Σk=1d(xjk-x‾j)2]]>其中,xik和xjk分别表示邻域中心的像素xi和邻域内像素xj的第k个光谱波段对应的光谱值,和分别为邻域中心的像素xi和邻域内像素xj的光谱均值,1≤i≤N,1≤j≤M;(3b)计算三维非局部均值的滤波权值:w(i,j)=1W(i)e-(1σ+rij)]]>其中w(i,j)表示以像素xi为中心的邻域内像素xj处对应的滤波权值,σ是限定系数,范围:1<σ<2,用于限定分母不为零,W(i)是归一化系数,由下式得出:W(i)=Σj=1Me-(1σ+rij)]]>(3c)根据三维非局部均值滤波器的滤波权值,得到高光谱图像的空-谱域特征集:C=[c1,c2,...,ci,...,cN],其中ci=[ci1,ci2,…,cik,…,cid]表示像素xi滤波后的空-谱域特征向量,1≤i≤N,由下式得出:ci=Σj=1Mw(i,j)xj]]>(4)对滤波后的特征向量集C进行归一化,得到归一化后的特征向量集C';(5)确定训练样本集和测试样本集,即随机的从特征向量集C'中提取10%作为训练样本集,将剩下的样本作为测试样本集;(6)利用步骤(5)中的测试样本集及其对应的类别标签,对支持向量机SVM分类器进行训练,使其能对高光谱图像数据进行正确的分类;(7)利用训练好的支持向量机SVM分类器对步骤(5)中的测试样本集进行分类,并给出最后的分类结果。本发明与现有的技术相比具有以下优点:第一:本发明采用皮尔逊相关系数来度量像素间的相似程度,并用此相似程度来构造非局部滤波器的滤波权值,克服了传统的非局部均值器中由于使用欧式距离而不能体现向量之间相似性的缺点,可以更好地表示高光谱图像中邻域内像素点之间的相似性,提高了同质区域的分类精度。第二:本发明对三维的高光谱图像数据直接处理,将传统的非局部均值滤波器扩展到了三维高光谱图像数据中,从而可以实现了对空域特征和光谱域特征进行同时提取,即将空间信息和光谱信息进行了有效的结合,克服了传统的特征提取过程中将两者分开提取而不能体现两者之间内在关系的缺点,这不仅简化了特征提取的过程,而且提高了分类精度。附图说明图1是本发明的流程图;图2是本发明仿真采用的IndianPine图像;图3是用本发明与现有方法对图像分类的效果对比图。具体实施方式下面结合附图对本发明做进一步的描述。参照图1,本发明的实现步骤如下:步骤1,输入有类别标签的三维高光谱图像数据。1.1)输入待分类的三维高光谱图像数据及其类别标签,该高光谱图像共包含k种类别,每种类别包含若干个像素,输入的高光谱图像的大小为m×n×d,其中,d表示高光谱图像的光谱波段总数,m和n分别表示二维空间中的行数和列数,N=m×n表示像素总数;1.2)将该高光谱图像的像素集表示为X=[x1,x2,...,xs,...,xN],其中xs表示高光谱图像数据中按二维空间列排列后的第s点的像素;1.3)由于高光谱图像数据是一种三维数据结构,所以图像中每点像素可以表示成向量的形式,即xs=[xs1,xs2,……xsd],1≤s≤N。步骤2,设置邻域的大小ω。本实施例中,邻域的大小设为7,即ω=7,邻域内像素的总数为M=49,对于输入的高光谱图像数据,每一点像素都存在大小为ω的邻域,将邻域中心的像素表示为xi,邻域内的像素表示为xj,1≤i≤N,1≤j≤M。步骤3,对输入的高光谱图像数据X进行三维非局部均值滤波,得到空-谱域特征集C。3.1)对于输入的高光谱图像数据,分别计算邻域中心像素xi的光谱均值和邻域内像素xj的光谱均值x‾i=xi1+xi2+...,+xik...+xidd,]]>x‾j=xj1+xj2+...+xjk...+xjdd,]]>其中,xik表示邻域中心像素xi的第k个光谱波段对应的光谱值,xjk表示邻域内像素xj的第k个光谱波段对应的光谱值,1≤i≤N,1≤j≤M,1≤k≤d;3.2)对于输入的高光谱图像数据,根据步骤3.1)的结果计算邻域中心的像素xi和邻域内像素xj之间的相关系数rij:rij=cov(xi,xj)std(xi)std(xj)=Σk=1d(xik-x‾i)(xjk-x‾j)Σk=1d(xik-x‾i)2Σk=1d(xjk-x‾j)2]]>其中xik和xjk分别表示邻域中心的像素xi和邻域内像素xj的第k个光谱波段对应的光谱值,∑是求和操作,是开方操作;相关系数rij的范围是-1到1,即|rij|≤1,根据相关系数的性质,|rxy|越接近1,则说明像素xi和像素xj的相关程度越高,此时两个像素可能属于同一类,而|rxy|越接近零,则说明像素xi和像素xj的相关程度越低,此时两个像素越可能属于不同类;3.3)根据步骤3.2)中描述的相关系数rij,构造三维非局部均值滤波器的滤波权值w(i,j):w(i,j)=1W(i)e-(1σ+rij)]]>其中,w(i,j)表示以像素xi为中心的邻域内像素xj处对应的滤波权值,σ是限定系数,取值范围:1<σ<2,用于限定分母不为零,W(i)是归一化系数,用于对权值w(i,j)进行归一化,该滤波权值w(i,j)可实现随着相关程度的增大而增大;3.4)根据步骤3.3)中构造的滤波权值,将三维非局部均值滤波器的输出ci表示为:ci=Σj=1Mw(i,j)xj]]>其中,xj表示以像素xi为中心的邻域内的像素,1≤j≤M,ci表示邻域中心像素xi处的空-谱域特征向量,1≤i≤N;3.5)将高光谱图像数据X=[x1,x2,...,xs,...,xN]作为非局部均值滤波器的输入,重复步骤3.1)到步骤3.5),得到高光谱图像的空-谱域特征向量集C=[c1,c2,...,ci,...,cN]。步骤4,对步骤3得到的空-谱域特征向量集C进行归一化,得到归一化后的空-谱域特征向量集C'。4.1)对步骤3得到的空-谱域特征向量集C=[c1,c2,...,ci,...,cN]中的空-谱域特征向量ci进行归一化,得到归一化后的特征向量其中表示特征向量中第k个特征值,可由下式得到:cik*=cik-cmincmax-cmin]]>其中,cik表示表示空-谱域特征向量ci中第k个特征值,1≤k≤d,1≤i≤N,cmin和cmax分别表示空-谱域特征向量集C中的最小值和最大值;4.2)对整个空-谱域特征向量集C=[c1,c2,...,ci,...,cN]重复步骤4.1),得到归一化后的空-谱域特征向量集步骤5,确定训练样本集和测试样本集。5.1)对于步骤4得到的空-谱域特征向量集C',随机的从中提取10%作为训练样本集;5.2)提取完训练样本集后,将剩下的空-谱域特征向量集作为测试样本集。步骤6,利用测试样本集及其对应的类别标签对支持向量机SVM分类器进行训练。利用步骤5.1)选出的训练样本集对支持向量机SVM分类器进行训练,即将选出的10%特征向量集输入到支持向量机SVM分类器中实现对支持向量机SVM分类器的训练,使其能对该高光谱图像数据进行正确的分类。步骤7,利用训练好的支持向量机SVM分类器对测试样本集进行分类。7.1)将步骤5.2)选出测试样本集输入到训练好的支持向量机SVM分类器中进行分类;7.2)给出整幅高光谱图像的分类结果。本发明的效果可通过以下仿真进一步说明。1、仿真实验条件:本发明的硬件测试平台是:处理器为InterCore2CPUE8200,主频为2.67GHz,内存2GB,软件平台为:Windows7家庭普通版64位操作系统和MatlabR2014a。本发明的输入数据为高光谱图像印第安松树IndianPine图像数据及其类别标签,如图2所示,该IndianPine图像数据的大小为145×145×220,即光谱波段数为220,移除被水域吸收的20个波段剩余200个波段,即此时图像的大小为145×145×200,该图像共包括16类地物,IndianPines图像的真实地物类别示意图如图2(a)所示,每种颜色所代表的类别如图2(b)所示。实验所用方法为本发明方法和现有3种方法,其中:现有方法1:Melgani等人在“Classificationofhyperspectralremotesensingimageswithsupportvectormachines,”IEEETrans.Geosci.RemoteSens.,vol.42,no.8,pp.1778–1790,Aug.2004.中提出的分类方法,简称支持向量机SVM分类方法;现有方法2:JonAtliBenediktsson等人在“Classificationofhyperspectraldatafromurbanareasbasedonextendedmorphologicalprofiles,”IEEETrans.Geosci.RemoteSens.,vol.43,no.3,pp.480–491,Mar.2005.中提出的基于扩展的形态学分类方法,简称EMP分类方法;现有方法3:JunLi等人在“HyperspectralimagesegmentationusinganewBayesianapproachwithactivelearning,”IEEETrans.Geosci.RemoteSens.,vol.49,no.10,pp.3947–3960,Oct.2011.中提出的基于多逻辑回归和多层次逻辑的分类方法,简称L-MLL分类方法。2、仿真实验内容仿真实验1,用本发明方法与上述的3中现有方法分别对印第安松树IndianPines图像数据进行分类,结果如图3,其中:图3(a)为采用支持向量机SVM分类器对高光谱图像印第安松树IndianPines原数据直接进行分类的结果图;图3(b)为采用基于扩展的形态学EMP分类方法对高光谱图像印第安松树IndianPines数据进行分类的结果图;图3(c)为采用基于多逻辑回归和多层次逻辑的L-MLL分类方法对高光谱图像印第安松树IndianPines数据进行分类的结果图;图3(d)为本发明方法对高光谱图像印第安松树IndianPines数据进行分类的结果图。由图3(a)可见,支持向量机SVM直接对原图像数据进行分类的结果比较差,主要原因是它只利用了高光谱图像的光谱信息,忽略了空域信息和邻域信息,使得分类结果在同质区域的分类精度很差;由图3(b)和图3(c)可见,对于EMP和L-MLL方法,虽然这两种方法在分类过程中将空域信息考虑在内,但是他们都是将光谱特征和空域特征进行分开处理,忽略了两者之间的联系,所以导致分类结果也不理想;由图3(d)可见,对于本发明的方法,利用像素间的相关系数来构造三维非局部均值滤波的权值,充分体现了高光谱图像中邻域内的像素可能属于不同类的特点,并且在三维滤波过程中,同时提取空域特征和光谱域特征,避免了现有技术中分开提取的缺点,提高了同质区域和边缘的分类精度,与此同时,对于小区域的像素集,本发明的方法同样可以进行很好的分类。仿真实验2,利用客观评价指标,分别对本发明方法和上述3种方法的分类结果给出定量分析。在仿真实验中,采用以下三个常用的指标来评价分类性能:第一个评价指标是总精度OA,表示正确分类的样本占所有样本的比例,值越大,说明分类效果越好。第二个评价指标是平均精度AA,表示每一类分类精度的平均值,值越大,说明分类效果越好。第三个评价指标是Kappa系数,表示混淆矩阵中不同的权值,值越大,说明分类效果越好。用上述客观评价指标对图3中各方法的分类进行评价的结果如表1。表1.各方法分类结果的定量分析方法总精度(OA)平均精度(AA)Kappa系数本发明95.11%87.86%94.42%SVM79.36%73.59%76.49%EMP91.31%89.47%89.99%L-MLL92.06%93.44%90.91%由表1可见,本发明方法存在明显的优势,对于总分类精度OA,本发明方法由SVM的79.36%提高到了95.11%,增加了25%左右;对于平均精度AA,本发明方法由SVM的73.59%提高到了87.86%,增加了14%左右;对于Kappa系数,本发明方法由SVM的76.49%提高到了94.42%,增加了18%左右;对于ELM和L-MLL方法,本发明方法仍然具有很大的提高。以上仿真实验表明:本发明方法可以充分的利用高光谱图像的光谱信息和空域信息,并且能很好的保留光谱信息和空间信息之间的内在关系,从而在高光谱图像边缘和同质区域都能取得很好的分类结果。本发明方法能够解决现有技术中存在的忽略高光谱图像的邻域信息,以及分类精度低、提取特征时操作复杂等问题,是一种非常实用且简单有效的高光谱图像分类方法。本实施例没有详细叙述的计算方法属本行业的公知技术和常用方法,这里不一一叙述。以上描述仅仅是对本发明的举例说明,并不构成对本发明的保护范围限制,凡是与本发明相同或相似的设计均属于本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1