基于FPGA的深度卷积神经网络实现方法与流程
技术特征:
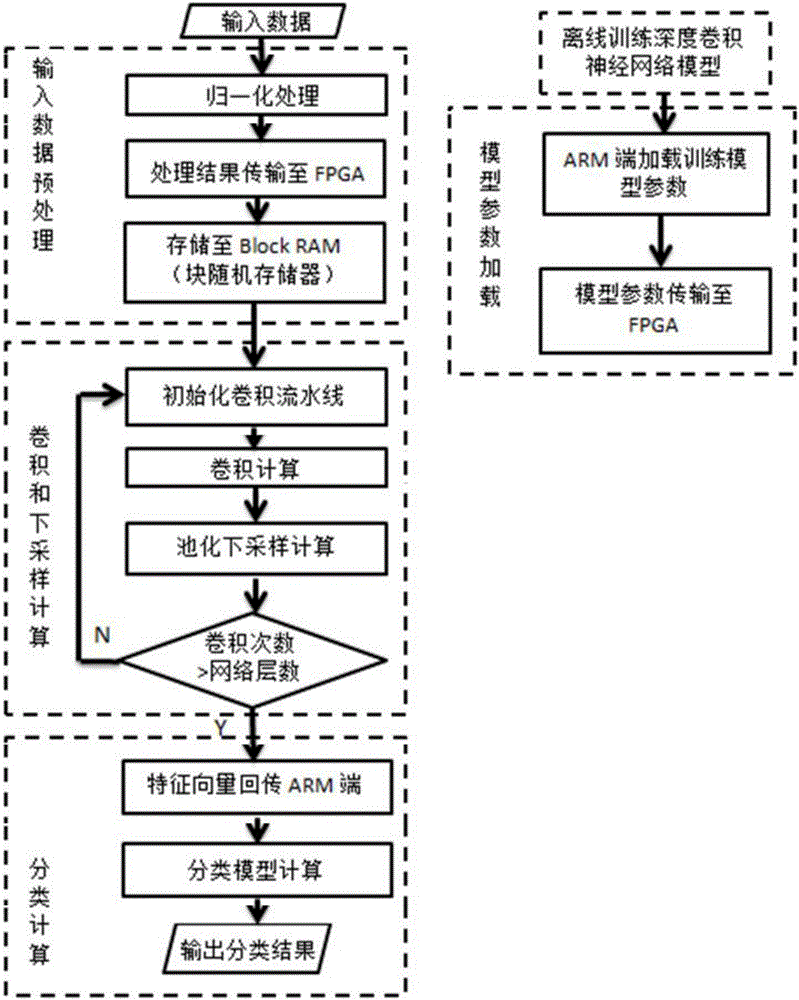
1. 一种基于FPGA的深度卷积神经网络实现方法,其特征在于具体步骤为:
步骤1、加载训练模型参数
(1)在ARM端加载离线训练的深度卷积神经网络模型参数;
(2)将训练模型参数传输至FPGA端;
(3)FPGA端经过FIFO缓存后存储在块随机存储器中;
步骤2、预处理深度卷积神经网络模型
(1)对输入数据进行归一化处理,使其满足模型卷积运算要求;
(2)利用APB总线将ARM端归一化数据传输至FPGA端;
(3)FPGA端将归一化数据经过FIFO缓存后存入块随机存储器;
步骤3、卷积和下采样计算
设网络模型有H个卷积层和池化层,第h个卷积层输入为T个m×m 32位浮点数矩阵,h=1,2,…,H;输出为S个(m-n+1)×(m-n+1)32位浮点数矩阵,卷积核为K个n×n 32位浮点数矩阵,n≤m,输入数据滑动窗尺度为n×n,横向滑动步长为1,纵向滑动步长为1;
(1)初始化卷积运算流水线
定义n+1个数据缓存寄存器P0,P1,…,Pn-1,Pn,每个寄存器存放m个数据,其中n个寄存器(P(i-1)%(n+1)+0,P(i-1)%(n+1)+1,…,P(i-1)%(n+1)+n-1)存放第t个输入数据矩阵的第i个子矩阵(n×m)数据,t=1,2,…,T,i=1,2,…,m-n+1;用%表示取余数,如果(i-1)%(n+1)+x>n,则(i-1)%(n+1)+x=0,(i-1)%(n+1)+x+1=1,…,其中x=0,1,…,n-1;如果n<m,P(i-1)%(n+1)+n寄存器存放输入数据矩阵中的第i+n行数据,在卷积计算过程中实现并行初始化,以减少FPGA空闲周期,提高计算效率;
定义1个卷积核矩阵缓存寄存器W,存放第k个n×n个卷积核矩阵权值数据,k=1,2,…,K;
(2)第h个卷积层计算
完成网络第h个卷积层第t个输入数据矩阵和第k个卷积核的卷积计算,通过Sigmoid函数实现计算结果的激活;
在进行每次卷积计算的同时,初始化第i+n个数据缓存寄存器P(i-1)%(n+1)+n,作为卷积中第i+1个子矩阵卷积计算的缓存输入数据,实现循环卷积;
在FPGA端通过浮点IP核构建Sigmoid函数,实现卷积计算结果的激活,Sigmoid函数的表达式为:;具体步骤为:
如前所述,输入数据为m×m浮点数矩阵,卷积核为n×n浮点数矩阵,滑动窗尺度为n×n,横向滑动步长为1,纵向滑动步长为1,则卷积结果为(m-n+1)×(m-n+1)的浮点数矩阵,矩阵的每个元素加上偏置量b11即离线训练模型参数,利用Sigmoid函数激活后,结果为(m-n+1)×(m-n+1)的浮点数矩阵,存入Block RAM;
完成1次卷积计算后,重新初始化卷积核矩阵缓存寄存器W,进行下一次卷积计算,往复循环卷积计算,计算结果为S个(m-n+1)×(m-n+1)浮点数矩阵,存入Block RAM;
(3)第h个池化层计算
实现第h个卷积层计算结果的池化计算,结果为S个[(m-n+1)/2]×[(m-n+1)/2]浮点数矩阵,存入Block RAM;具体步骤为:设卷积计算结果数据滑动窗尺度为2×2,步长为2,采用平均下采样法实现池化,即逐个2×2浮点数矩阵相加,计算结果取均值,获得S个[(m-n+1)/2]×[(m-n+1)/2]浮点数矩阵,作为第h+1个卷积层计算的输入矩阵;
步骤4、分类计算
将卷积计算和池化计算结果传回ARM端进行分类运算;具体步骤为:FPGA端将Block RAM中的卷积池化计算结果矩阵,通过FIFO缓存,APB总线传输至ARM端,ARM端利用Softmax运算完成数据分类计算,得到输入数据的分类结果并输出。
- 还没有人留言评论。精彩留言会获得点赞!