一种CNN‑SVM模型的构建及倾向性分类方法与流程
本发明涉及社交媒体信息处理领域,特别涉及一种cnn-svm模型的构建及倾向性分类方法。
背景技术:
在日常生活中,社交媒体(例如facebook、twitter、微博等)逐渐代替纸媒成为了人们了解新闻的新兴媒体,同时它也为提供了一个相对自由的发表个人言论,抒发情感的公共平台。由于社交媒体使用方便且信息更新及时,越来越多的人成为社交媒体的忠实使用者,且其言论自由度十分高,庞大的信息流揽括了众多的话题,这些信息看似琐碎不规则,事实上却蕴含着巨大的潜在价值。因此如何从社交媒体中获取用户的倾向,并服务于生活是一个很有价值的工作。现实生活中,人们希望通过分析社交媒体中一个事件的关注度和其倾向性来预测电影票房、股市情况等。当事件发生后,随着评论数与转发数的增加,事件的关注度增加,变成一个热门事件吸引更多的人关注,因此分析人们对于事件的倾向性以便采取舆论监督也是非常重要的。面对海量的数据,仅仅依靠人工浏览来获取用户倾向将是一件十分繁琐与困难的事情。
倾向性分类方法用来将文本分成不同倾向性的类别,一般分成两类(正向、负向)或者三类(正向、中性、负向)。传统的倾向性分析方法主要有机器学习和情感词典两类方法,一般机器学习的方法性优于情感词典的方法,但在社交网络中,单独的机器学习方法不能很好的考虑上下文的关系,其分类的结果虽然在正确率上比较高,但有时候不能反映社交媒体使用者的真实意图。而且在社交媒体的转发行为中,会出现倾向性反转的情况,即通过转发行为表达与被转发人不同或者相同的意见,从而对原事件发表看法,例如:我不同意//这个电影真难看,后者的转发是对转发者意见的否定,其倾向性是负向,但真实意图是对这个电影的表扬。因此,如果不考虑转发行为,会导致错误的倾向性分类。
技术实现要素:
本发明的目的在于克服目前倾向性分类方法存在的上述问题,提供了一种卷积神经网络和支持向量机结合的倾向性分类方法,该方法将卷积神经网络与支持向量机结合构造分类模型,该模型能够提高分类的正确率;同时构建转发树解决部分社交媒体中倾向性反转的情况。
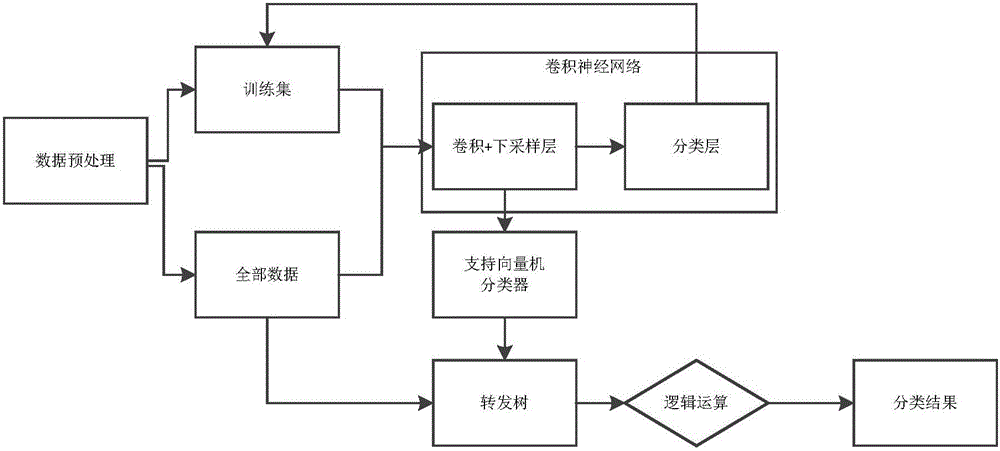
为了实现上述目的,本发明提供了一种cnn-svm模型的构建方法,所述方法包括:从社交媒体上抓取基于某一事件的所有评论和转发信息,构建训练样本集;建立包含卷积层、采样层和分类层的cnn模型,利用训练样本集训练cnn模型的各层参数;将训练好参数的cnn模型中的卷积层、采样层与svm分类器联合在一起,构成cnn-svm模型;将训练样本集输入cnn-svm模型,训练svm分类器的参数;所述cnn-svm模型构建完成。
上述技术方案中,所述方法具体包括:
步骤1)从社交媒体上抓取基于某一事件的所有评论和转发信息,对这些信息进行预处理,得到若干个句子;提取句子的word2vec的特征;将所有含有等量正负倾向性的句子形成训练样本集;所述预处理包括:去掉过短的句子、分词和停用词;
步骤2)建立cnn模型;所述cnn模型包括:卷积层、采样层和分类层;其中,卷积层和采样层的层数为1;分类层为一个soft-max的全连接层;
步骤3)利用训练样本集训练cnn模型的各层参数;
步骤4)将训练好参数的cnn模型中的卷积层、采样层与svm分类器联合在一起,构成cnn-svm模型;
步骤5)将训练样本集中的每个句子输入训练好的cnn模型的卷积层和采样层,将采样层输出的结果输入到svm分类器中,得到预测结果;计算预测结果和真实的标注结果的差值,根据差值调整svm分类器的参数,直到svm分类器所有参数训练完毕;
步骤6)cnn-svm模型构建完成。
上述技术方案中,所述步骤3)具体包括:
步骤3-1)将每个训练样本表示成矩阵s∈r(s×n),矩阵s由s个词语向量组成:[w1,…,wi,…,ws],每一个词语向量为n个已经用word2vec特征表示的向量:[v1,…,vi,…,vn];
步骤3-2)将矩阵s输入cnn模型的卷积层,输出特征图谱c;
卷积层包含t种类型的滤波器f∈r(m×n),m是滤波器的宽度,n和矩阵s的n相同,第i个卷积后的结果计算如下:
其中,s[i-m+1:i,:]表示宽度为m的矩阵块,
步骤3-3)将特征图谱矩阵c输入采样层,每一个特征图谱cnq都将返回一个最大值:
步骤3-4)将采样层的输出d输入分类层,使用下面的公式计算句子标签的概率:
其中wk和bk是分类层的第k个节点的权重和偏移向量,k是分类层的节点的总个数;b=(b1,b2,…bk),w=(w1,w2,…wk);
步骤3-5)将训练样本集中每个样本对应的矩阵s依次输入cnn模型的卷积层和采样层,得到高维度特征矩阵d,然后输入分类层,得到预测结果;计算预测结果和真实的标注结果的差值,根据差值调整cnn模型中的参数,直到所有参数训练完毕。
基于上述方法构建的cnn-svm模型实现,本发明还提供了一种倾向性分类方法,所述方法包括:
步骤s1)对待分类的评论进行预处理,得到若干个句子;提取句子的word2vec的特征;获取输入矩阵s0;
步骤s2)将输入矩阵s0输入训练好的cnn-svm模型,得到该评论的分类结果:情感标签。
上述技术方案中,如果待分类的评论含有转发的文本,所述方法还包括:
步骤s3)在转发过程中每个被转发的路径为转发树的一个节点,构建转发树;
步骤s4)将步骤s2)得到的情感标签根据转发路径中的转发节点进行逻辑运算,逻辑运算公式如下:
其中,nodei是转发树的第i个节点的倾向性,它的真实倾向性是将其前n个节点的真实情感结果相乘得到最终的分类结果ni,n0是使用cnn-svm模型输出的倾向性,倾向性取值为-1或1;其中,-1表示负向情感,1表示正向情感。
本发明的优点在于:
1、本发明的倾向性分类方法可以提高分类的正确率
2、本发明的方法构建了转发树,从数据的结构上进行逻辑运算,从而将评论的上下文联系起来。
附图说明
图1为本发明的cnn-svm模型的示意图;
图2为本发明的倾向类方法的示意图;
图3为本发明的转发树的示意图。
具体实施方式
下面结合附图和具体实施例对本发明做进一步详细的说明。
如图1所示,一种cnn-svm模型的构建方法,所述方法包括:
步骤1)从社交媒体上抓取基于某一事件的所有评论和转发信息,对这些信息进行预处理,得到若干个句子;提取句子的word2vec的特征;将所有含有等量正负倾向性的句子形成训练样本集;
所述预处理包括:去掉过短的句子、分词和停用词。
步骤2)建立cnn(卷积神经网络)模型;所述cnn模型包括:卷积层、采样层和分类层;其中,卷积层和采样层的层数为1;分类层为一个soft-max的全连接层;
步骤3)利用训练样本集训练cnn模型;具体包括:
步骤3-1)将每个训练样本表示成矩阵s∈r(s×n),矩阵s由s个词语向量组成:[w1,…,wi,…,ws],每一个词语向量为n个已经用word2vec特征表示的向量:[v1,…,vi,…,vn];
步骤3-2)将矩阵s输入cnn模型的卷积层,输出特征图谱c;
卷积层包含t种类型的滤波器f∈r(m×n),m是滤波器的宽度,n和矩阵s的n相同,第i个卷积后的结果计算如下:
其中,s[i-m+1:i,:]表示宽度为m的矩阵块,
步骤3-3)将特征图谱矩阵c输入采样层,每一个特征图谱cnq都将返回一个最大值:
步骤3-4)将采样层的输出d输入分类层,使用下面的公式计算句子标签的概率:
其中wk和bk是分类层的第k个节点的权重和偏移向量,k是分类层的节点的总个数;b=(b1,b2,…bk),w=(w1,w2,…wk);
步骤3-5)将训练样本集中的每个句子对应的矩阵s依次输入cnn模型的卷积层和采样层,得到高维度特征矩阵d,然后输入分类层,得到预测结果;计算预测结果和真实的标注结果的差值,根据差值调整cnn模型中的参数,直到所有参数训练完毕。
步骤4)将训练好参数的cnn模型中的卷积层、采样层与svm(支持向量机)分类器联合在一起,构成cnn-svm模型;
步骤5)将训练样本集中的每个句子对应的矩阵s依次输入训练好的cnn模型的卷积层和采样层,将采样层输出的高维度特征矩阵输入到svm分类器中,得到预测结果;计算预测结果和真实的标注结果的差值,根据差值调整svm分类器的参数,直到svm分类器所有参数训练完毕;
步骤6)cnn-svm模型构建完成。
如图2所示,基于上述方法构建的cnn-svm模型,本发明还提供了一种倾向性分类方法,所述方法包括:
步骤s1)对待分类的评论进行预处理,得到若干个句子;提取句子的word2vec的特征;获取输入矩阵s0;
步骤s2)将输入矩阵s0输入训练好的cnn-svm模型,得到该评论的分类结果:情感标签。
此外,如果待分类的评论含有转发的文本,所述方法还包括:
步骤s3)构建转发树,并且微博在转发过程中会保留其被转发的之前的所有路径;
例如:“@新浪四川:→_→//@成都微吧:→_→//@李伯伯:我们让你跌倒?”,这对于构建转发树是非常便利的。我们将所有如上的微博转发链条提取出来,把链条用//分开,若链条为s,则分开后该链条包括n个子句,s:[s1,s2,…,sn],每一个子句都包含发微博的账号和微博内容,将每一个子句与树中已有的节点相比较,若账号与内容都一直,我们认为该节点已在树中,否则为这个树添加节点。
在人们浏览微博时,转发行为是一种常见行为,例如“哈哈,同意//这个电影不好看,太失望了!”,在这个句子中,“哈哈,同意”从字面上的意思理解,该用户表达的是正向的情感,但结合其转发的微博看,他是对其转发的微博表示赞同,其实是对原事件表示一种负向的情感,对于这种情况,我们的模型cnn-svm就不能很好的进行情感分类。基于以上问题,我们对含有转发的文本构建转发树,
转发树结构如图3,在树中,圆圈越大表示其所处的层级越高,即其发微博的时间越早。圆圈中或圆圈外的数字是经过cnn-svm模型得到的情感标签。
步骤s4)将步骤s2)得到的情感标签根据转发路径中的转发节点进行逻辑运算,逻辑运算公式如下:
其中,nodei是转发树的第i个节点的倾向性,它的真实倾向性是将其前n个节点的真实情感结果相乘得到最终的分类结果ni,n0是使用cnn-svm模型输出的倾向性,倾向性取值为-1或1;其中,-1表示负向情感,1表示正向情感。
- 还没有人留言评论。精彩留言会获得点赞!