一种分散式大数据管理与检索的方法与流程
本发明涉及大数据管理技术领域,特别是涉及一种分散式大数据管理与检索的方法,尤其是大量北斗船位时空数据的分散式存储管理,以及快速查询、统计。
背景技术:
海量业务数据应用系统在运行过程中,需要查询大量的相关数据,因此业务数据的存放与查询成为应用系统的重要组成部分。由于数据量比较庞大,为了维护和管理便利,应用系统的业务数据通常被存放在数据库中,应用系统在运行时通过使用SQL语句访问数据库的方式查询。这种方式虽然实现简便,但是由于数据库本身的性能以及网络数据传输的消耗等因素,会影响应用处理查询数据的速度,从而降低应用系统的性能表现,因此通过直接访问数据库的方式比较适合于数据量不是很大、对应用系统的处理速度要求不高的系统。并且DB2、0racle、SQL Server等数据库系统会绕开文件系统,自己管理磁盘块,提高了数据库的性能,但数据库的管理也变得比较复杂了,这些商业数据库成本都较高。
技术实现要素:
本发明所要解决的技术问题是提供一种分散式大数据管理与检索的方法,能够准确、直观的渔船的时空分布统计查询。
本发明解决其技术问题所采用的技术方案是:提供一种分散式大数据管理与检索的方法,应用程序服务器处理北斗空间数据,处理后的数据由管理服务器根据配置分散存储到文件服务器,并记录存放的位置,Web服务器为外部网络访问提供服务,把外部访问请求发给应用程序服务器,应用程序服务器通过管理服务器获取分散的文件数据,对这些数据根据访问请求处理后返回给Web服务器;所述数据分为两部分,一部分是基础数据,另一部分是业务数据;系统运行后,系统将数据读入内存中,利用内存的缓冲区直接操作数据文件。
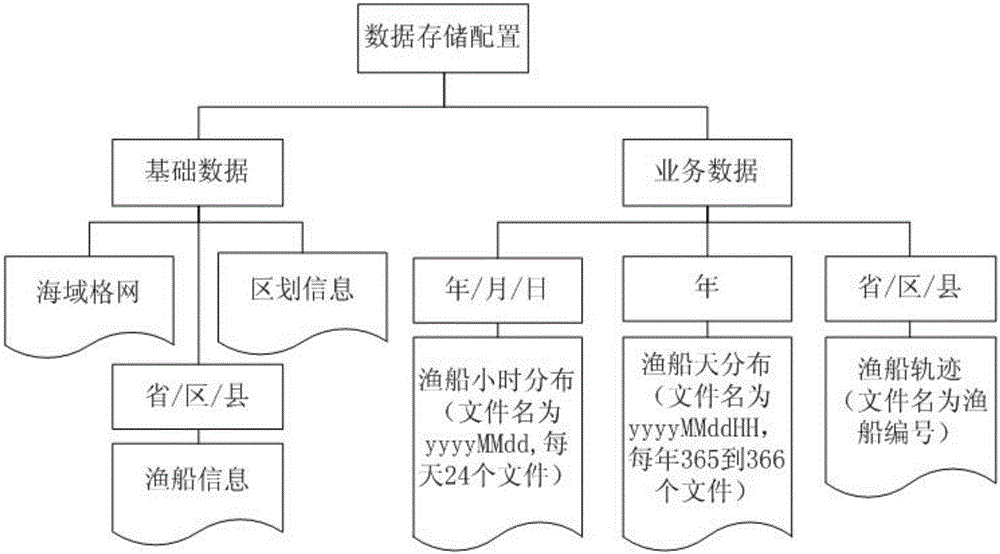
所述基础数据包括海域数据、区划数据和渔船数据;所述业务数据包括渔船小时分布、渔船天分布和渔船轨迹数据。
所述区划数据与渔船数据通过区划编号关联;所述渔船轨迹数据通过渔船编号与渔船数据相关联;所述渔船小时分布表通过小渔区编号与海域数据关联;所述渔船天分布表通过小渔区编号与海域数据关联。
所述海域数据的内存结构所表达的海域层次关系为海区、渔场、渔区、小渔区由上向下成包含的层次关系。
所述区划数据的内存结构所表达的区域层次关系为省级行政区划、地区级行政区划、县级行政区划由上向下成包含的层次关系。
所述渔船数据的内存结构为省级行政区划编号、地区级行政区划编号同区划数据的内存结构,每个县级行政区划中存储起止的渔船编号,每个渔船编号中存储渔船基本信息。
通过区划数据的内存结构和海域数据的内存结构,查询分散的北斗船位空间分布数据文件,统计某段时间,某区划渔船去各海域作业的数量或统计某段时间,某海域渔船来源于各区划的数量。
有益效果
由于采用了上述的技术方案,本发明与现有技术相比,具有以下的优点和积极效果:本发明把现有技术中存储在数据库中的数据存储在由文件系统管理的分散的数据文件中,其提高了数据读取效率,增加了数据管理灵活性,减少了商业数据库软件的成本。本发明采用一种分散式数据管理,用内存表层次模型来解决数据快速统计查询的问题。内存的速度是除了CPU CACHE外最快的存储设备,内存速度可达6G/S以上,与硬盘速度相差30倍以上。分散式存储还支持自定义的socket协议,构建分布式系统,遇到高并发,高流量的任务时可以进行拓展提高数据共享效率。
附图说明
图1为数据关系图;
图2为数据结构图;
图3为数据存储管理图;
图4为海域数据内存结构图;
图5为海域层次关系图;
图6为区划数据内存结构图;
图7为区划数据层次关系图;
图8为渔船信息数据内存结构图;
图9为海域统计图;
图10为区划统计图;
图11为渔场渔船追溯展示图;
图12为全国区划渔船海上分布图。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
本发明的实施方式涉及一种分散式大数据管理与检索的方法,下面以北斗数据存储与检索为例进一步说明本发明。
1.数据内容
1.1海域划分
我国沿海从北到南分渤海、黄海、东海和南海海区。渤海、黄海分界线是辽东半岛南端老铁山角与山东半岛北岸蓬莱角的连线;黄海、东海分界线是长江口北岸的启东角与韩国济州岛西南角的连线;东海、南海分界线是广东南澳岛与台湾岛南端的鹅銮鼻连线。山东半岛以北称渤海,山东半岛与长江口之间称黄海,长江口与台湾岛之间的海域是东海,台湾岛以南、以西的部分则是南海。习惯上根据水域位置、捕捞对象和作业方式等划分渔场,近海划分了53个传统渔场。我国制定有渤、黄、东海渔区编码和南海渔区编码。近海区编码以30′×30′经纬度范围大小为一个渔区单元,每渔区又按每10′×10′经纬度细分为9个小渔区,每个渔区单元按照从西至东、从北向南的顺序进行编号。渔区编码从最北部的辽东湾开始,初始编码为1,沿经度方向向东最远扩展到129.5°E,从北往南依次编码,最南端为4°N附近的曾母暗沙海域。海域信息保存在文本文件中(表1),每个海域的信息占一条记录,海域的属性用逗号隔开,各海域记录间用回车符分开。海域存储按照海区、渔场、渔区、小渔区排序,然后对排序的海域由1开始逐渐增加作为海域的编号。
表1
1.2行政区划
《中国海洋统计年鉴》中沿海地区定义是指有海岸线(大陆岸线和岛屿岸线)的地区,目前我国有8个沿海省、1个自治区、2个直辖市;53个沿海城市、242个沿海区县。行政区划保存在文本文件中(表2),每个区划信息占一条记录,区划的属性用逗号隔开,各区划记录间用回车符分开。区划存储按照省、地区、县排序,然后对排序的区划由1开始逐渐增加作为区划的编号。
表2
1.3渔船信息
渔船信息包括渔船名称、捕捞类型、船长、功率捕捞类型等,根据《渔业捕捞许可管理规定》作业类型有刺网、围网、拖网、张网、钓具、耙刺、陷阱、笼壶和杂渔具(含地拉网、敷网、抄网、掩罩及其他杂渔具)共9种。渔船命名按照“省简称+县简称+船号”形式命名,渔船信息保存在文本文件中(表3),每艘船的信息占一条记录,船的属性用逗号隔开,各渔船记录间用回车符分开。渔船存储按照省、地区、县排序,船号由小到大,然后对排序的渔船由1开始逐渐增加作为渔船的编号。
表3
1.4渔船分布数据
渔船分布数据分为渔船小时分布数据和渔船天分布数据。渔船小时分布数据指的是渔船每小时各小渔区格网中的渔船(表4),渔船天分布数据指的是渔船每天各小渔区格网中的渔船(表5),数据记录包括系统生成的唯一编号小渔区编号和渔船编号,渔船分布信息保存在在文本文件中,以每天或每小时为一条记录,以小渔区编号为主键,渔船编号用逗号隔开,每个渔区的记录用回车符分开。
表4
表5
1.5渔船轨迹数据
渔船轨迹数据包括时间、经度、纬度、航速、航向、渔船编号等。每一条渔船轨迹记录为单艘渔船的轨迹(表6),以船位数据发出的时间为主键,船的轨迹信息用逗号隔开,包括经度、纬度、航速(单位m/s)航向、渔船编号,每个时间点的船位记录用回车符分开。
表6
1.6数据间的关系
数据主要包含6张表,互相联系(图1)。行政区划表与渔船信息表通过区划编号关联。渔船轨迹通过渔船编号与渔船信息相关联,可获取渔船的轨信息。渔船小时分布表通过小渔区编号与海域格网表关联,通过渔船编号与渔船信息表关联,构成渔船小时分布的完整信息。渔船天分布表通过小渔区编号与海域格网表关联,通过渔船编号与渔船信息表关联,构成渔船天分布的完整信息。
2.数据存储管理
2.1渔船数据存储
完善的统计分析功能需要大量的数据结构支持,按照3min的时间分辨率来接收船位数据,5万艘船每天接收到的位置数据可达2000万余条。“结构化管理”包括结构化文件夹和数据文件。数据分为两部分(图2),一部分是数据比较固定,变化小的基础数据,如海域、区划、渔船数据;一部分是数据量不断增加的业务数据,如渔船小时分布、天分布、轨迹数据。
2.2数据管理
整个网络区分为三个部分(图3)WAN(局域网,分布于一个相对较小的区域内的用以连接各种类型服务器的计算机网络)、LAN(广域网,能在很宽的地理区域内为用户服务的数据通信网络)、DMZ(隔离区,为解决安装防火墙后外部网络的访问用户不能访问内部网络服务器的问题),在这个数据存储方案中,使用防火墙为关键服务器提供隔离区,防火墙抵挡外部网络的攻击,并管理所有内部网络的访问。为了解决安装防火墙后外部网络不能访问内部网络服务器的问题,设立了一个非安全系统与安全系统之间的隔离区DMZ。通过DMZ区域有效地保护了内部网络。DMZ防火墙方案为要保护的内部网络增加了一道安全防线,并且提供了一个区域放置公共服务器,能有效地避免一些互联应用需要公开与内部安全策略相矛盾的情况发生。应用程序服务器处理北斗空间数据,处理后的数据由管理服务器根据配置分散存储到文件服务器,并记录存放的位置,Web服务器为外部网络访问提供服务,把外部访问请求发给应用程序服务器,它通过管理服务器获取分散的文件数据,对这些数据根据访问请求处理后返回给Web服务器。
3.数据内存管理
系统运行后,系统将数据读入内存中,利用内存的缓冲区直接操作的数据文件,以便快速地查询和访问数据内容,减少对磁盘IO的访问,提升查询性能。
3.1渔区内存表
海域数据内存结构如图4所示,海区编号、渔场编号、渔区编号中都存储着下一层次的起始与终止的编号,如海区编号是1~4的4个海区,每个海区存储该海区的渔场起止编号,每个渔场保存该渔场的渔区起止编号,每个渔区保存该区域的小渔区起止编号,小渔区中存储着小渔区基本单元信息。
海域数据内存结构所表达的海域层次关系如图5所示,海区、渔场、渔区、小渔区由上向下成包含的层次关系。
3.2区划内存表
区划数据内存结构如图6所示,省级行政区划编号、地区级行政区划编号、县级行政区划编号中都存储着下一层次的起始与终止的编号,每个省级行政区划中存储地区级行级政区划的起止编号,每个地区级行级政区划中存县级行政区划起止编号,每个县级行政区划中存储县级行政区划基本单元信息。
区划数据内存结构所表达的区域层次关系图如图7所示,省级行政区划、地区级行政区划、县级行政区划由上向下成包含的层次关系。
3.3渔船内存表
渔船信息数据内存结构如图8所示,省级行政区划编号、地区级行政区划编号同区划数据内存结构,每个县级行政区划中存储起止的渔船编号,每个渔船编号中存储渔船基本信息。
4.数据检索
北斗数据挖掘获取的捕捞努力量、网次、累计捕捞时间等信息,可以根据行政区划统计各级区划渔船一段时间的捕捞情况,海上空间分布情况,根据海域格网追溯渔船来源各级区划的数量等。
4.1区划渔船去向检索
用户选择一个区划,统计这个区划渔船去各海域作业的数量,一般数据库中查询语句是“select海域,count(*)where时间in时间段and渔船in区划group by海域”,本专利分散的北斗船位据统计渔船去向,流程如图9。
(1)系统运行时把海域、区划、渔船信息先读取到内存,构建海域数据内存结构、区划数据内存结构、渔船信息数据内存结构;
(2)选定某个区划时,根据区划数据内存结构判断该海域包含的选定渔船;
(3)根据时间读入分散的北斗船位空间分布数据文件,筛选包含在选定的渔船,实现查询语句的“where时间in时间段and渔船in区划”;
(4)根据选定海域级别(海区、渔场、渔区、小渔区),利用海域数据内存结构确定该海域的包含小渔区;
(5)把“小渔区+渔船编号”作为关键字,添加渔船编号是为了实现渔船在某个渔区不重复统计,通过“小渔区+渔船编号”筛选出各小渔区中的渔船,在以选中的“海域”级别为关键字统计各海域渔船的数量,实现查询语句中的group by海域。
4.2追溯渔船海域数据来源检索
用户选择一个海域,追溯这个海域渔船来源于各区划的数量,一般数据库中查询语句是“select区划,count(*)where时间in时间段and渔船in海域group by区划”,本专利渔船追溯渔船数据的流程如图10。
(1)系统运行时把海域、区划、渔船信息先读取到内存,构建海域数据内存结构、区划数据内存结构、渔船信息数据内存结构;
(2)选定某个海域时,根据海域数据内存结构判断该海域包含的选定小渔区;
(3)根据时间读入分散的北斗船位空间分布数据文件,筛选包含在选定小渔区的渔船实现查询语句的“where时间in时间段and渔船in海域”;
(4)根据选定区划级别(省级行政区划、地区级行政区划、县级行政区划),利用渔船信息数据内存结构确定该区划的包含渔船;
(5)把“区划+渔船编号”作为关键字,添加渔船编号是为了实现渔船在某个区划不重复统计,通过“区划+渔船编号”筛选出选定区划中各区中渔船,在以选中的“区划”为关键字统计各区划渔船的数量,实现查询语句中的group by区划。
5.数据展示
5.1某个渔场渔船来源
以渔场渔船来源的地区及行政区划为例说明海域渔船追溯的展示方法,如图11,选择需要查询的日期与时间,点击任意渔场,1秒内完成数据查询统计与地图刷新显示,展示出由渔场指向各地区级区划的箭头,并标注该渔场来源各地区的船只数量。
5.2某区划渔船去向
以各级区划渔船在渔场中的分布数量为例说明区划渔船的去向,如图12,选择需要查询的日期与时间,点击任意级别区划,1秒内完成数据查询统计与地图刷新显示,可以统计出选中区划所属渔船在各个渔场中分布的数量,并用对应颜色表示。
5.3渔船轨迹查询展示
某海域渔船来源可以调出来源的各区划中渔船列表,某区划渔船去向可以调出去向的各海域中渔船列表,选择某个渔船,确定具体时间,就可以在分散式北斗数据文件中获取该渔船的轨迹并展示。
- 还没有人留言评论。精彩留言会获得点赞!