一种基于混沌灰狼优化的支持向量机方法与流程
本发明涉及一种基于混沌灰狼优化的支持向量机方法,属于计算机科学领域。
背景技术:
目前网格搜索和梯度下降是支持向量机(SVM)最常用的两种参数优化方法。网格搜索是一种穷举搜索方法,它一般是通过设置合理的区间上下限和间隔步长对指定参数空间进行划分,然后对每个网格节点代表的参数组合进行训练和预测,将这些预测结果中取值最高的一组参数作为最终SVM模型的最佳参数。这种穷举式搜索方法虽然在一定程度上能保证得到给定参数空间内最优的参数组合,然而随着参数空间增大,其搜索效率会大大降低,特别是设置合理的区间和间隔步长值往往非常困难,从而大大降低了其可行性,而且模型也非常容易陷入局部最优值。梯度下降方法的一个主要缺点是它对初始值非常敏感,当初始参数设置离最优解非常远的时候,模型很容易收敛到局部最优解。
近年来,基于元启发式的搜索算法凭借其独特的全局寻优能力而受到了学术和工业界的广泛关注,它们被普遍认为比传统寻优方法具有更大的机会找到全局最优解。目前已经提出多种基于元启发式算法的SVM训练算法来处理参数优化问题。
因为SVM在具体应用时,其性能主要受核函数及自由参数影响。SVM中常用的核函数一般包括线性核函数、多项式核函数、径向基(RBF)核函数和sigmoid核函数等。在实际应用中,一般情况下选择基于RBF核函数的SVM。RBF核SVM主要涉及两个重要的参数C和γ。C是惩罚因子,它用于控制对错分样本惩罚的程度,起到控制训练误差和模型复杂度之间平衡的作用;C值越小,则对数据中误判样本的惩罚也越小,使得训练误差变大,因此结构风险也变大。相反,C值越大,对错分样本的约束程度就越大,这样会导致模型虽然对训练数据的误判率很低,但整体的泛化能力却很差,容易出现“过拟合”现象。它的选取一般是由具体的问题而定,并取决于数据中噪声的数量,每个样本空间至少都存在一个合适的C值,使得SVM的泛化能力最强。第二个参数γ代表RBF核函数中的核宽,它决定了核函数的宽度,直接影响SVM的性能。因为核函数、映射函数和特征空间三者之间是一一对应的,确定了核函数也就意味着隐含地确定了映射函数和特征空间。核参数的改变隐含地改变了映射函数,进而样本特征空间分布的复杂程度也得到了改变。对于一个具体问题而言,如果γ取得不恰当,SVM很难获得预期的学习效果。γ值太小会导致过拟合,γ值太大会使SVM的判别函数过于平缓。所以惩罚因子C和核宽γ从不同的角度影响着SVM的分类超平面。在实际应用中,它们取值过大或过小都会使SVM的泛化性能变差。
相比于网格搜索方法,灰狼算法具有更好的全局搜索能力,其通过模拟自然界中狼群的社会等级和猎食行为获得问题的近似最优解,灰狼具有全局寻优能力强,寻优精度高的特点。但针对复杂问题时,它也有陷入局部极值的可能性,若结合混沌的初始值敏感、随机性、遍历性等特点,并加入混沌扰动机制,可有效降低其寻优过程中陷入局部最优的可能性,较其他优化算法在解的质量和收敛效率都有明显的提高。
技术实现要素:
为了解决上述技术问题,本申请提出一种融合混沌灰狼优化算法与支持向量机的分类、预测方法,该方法通过混沌灰狼算法优化支持向量机的两个关键参数,该申请的方法比现有方法具有更高的分类、预测精度,可以辅助对所研究领域的优化研究,例如该方法可应用于医疗筛选、工业制造、金融决策以及农业生产方面,借助该方法可以进行有效决策分析,具有重要的应用价值。具体举例来说,在农业领域内,可实现对棉花异性纤维的检测识别,棉花异性纤维是指在棉花的采摘、摊晒、收购、储存、运输、加工过程中混入棉花中对棉花及其制品的质量有严重影响的非棉纤维和色纤维,如毛发、麻、丝、纤维、染色丝和塑料膜等。虽然异性纤维即时含量少,但对于纺织品还是会产生一定质量影响,在最后的成品中显示出来会造成相应的经济损失,因此我们需要研究对应的检测机制来检测识别棉花中的异纤,从而提高纺织品的质量,这里是建立在对异性纤维的处理技术基础上对于棉花质量评定检验中异性纤维含量精确测量的一个研究,本文基于混沌灰狼优化算法的支持向量机的模型来进行棉花异性纤维的检测识别。
为实现上述目的,本发明采用的技术手段为:
一种基于混沌灰狼优化的支持向量机方法,包括如下步骤:
步骤1:收集待研究问题相关的数据;
步骤2:利用公式(1)进行对收集数据进行标准化;
式中,Si代表原始值,Si’代表标准化后的值,Smin代表极小值,Smax代表极大值;
步骤3:利用混沌灰狼算法优化支持向量机的惩罚系数C和核宽γ;
步骤4:基于步骤3获取的惩罚系数C和核宽γ值,构建下述公式(2)的识别模型f(x),其中的K(xi,xj)的具体形式如公式(3)所示,其中γ即为核宽,xj表示待测样本,xi(i=1…l)表示与支持向量对应的训练样本,yi(i=1…l)表示与上述训练样本对应的标签,b为阈值,αi是拉格朗日系数,sgn为符号函数;
K(xi,xj)=exp(-γ|xi-xj||2) (3)
步骤5:基于步骤4所构建的模型对待分类样本进行分类和预测。
根据本发明的一个方面,更为具体的,其中步骤3包括如下子步骤:
步骤3.1:参数初始化,包括对最大迭代次数T、灰狼群体中狼的头数n、C的搜索空间[Cmin,Cmax]和γ的搜索空间[γmin,γmax]进行初始化;
步骤3.2:灰狼位置混沌初始化:首先随机产生第一只灰狼的位置Xl=(xl1,xl2),然后从现存的混沌映射函数(公式(4))中选择一种合适的映射(Logistic映射)获得n-1只灰狼的位置,其中每只灰狼i的位置为Xi=(xi1,xi2);采用公式(5)将每一只灰狼的位置映射到设定的搜索范围内得到n只灰狼的位置X’i=(x’i1,x’i2)(i=1…n),其中x’i1表示灰狼i在当前位置时的C值,x’i2表示灰狼i在当前位置时的γ值;其中a1是小于b1的值,且Z′i∈[a1,b1];
计算每只灰狼i的适应度fi,该适应度基于灰狼i当前位置的C和γ值,以内部K折交叉验证策略计算支持向量机的准确度ACC,并将该值作为灰狼i的适应度fi的值,将适应度fi由大到小排序,接着将适应度排在前三的三只狼的适应度值保存为向量F_best(fa,fb,fc)且将其位置作为三只头狼的位置,保存为P_best(X’a,X’b,X’c)并参照公式(10)至公式(19)对灰狼的位置进行更新,获得n只灰狼的位置X”i=(x”i1,x”i2)(i=1…n),采用公式(5)将每一只灰狼的位置映射到设定的搜索范围内得到n只灰狼的初始位置Xi_Initialization=(xi1,xi2)(i=1…n),至此灰狼位置混沌初始化完成。其中a,b,c的范围在[1,n]之间,ACC是基于K折交叉验证获取的平均准确度,根据公式(6)计算获得,其中acck表示每一折数据上计算获得的准确度;
Z(i+1)=μ·Z(i)·(1-Z(i)) (4)
Z′i=a1+(b1-a1)·Zi (5)
步骤3.3:采取和步骤3.2中相同的C和γ编码方式后以内部K折交叉验证策略计算每一只灰狼的适应度;
步骤3.4:对狼群按步骤3.3所得的适应度值由高到低进行排序,如果此刻适应度最高值大于fa,并以此刻降序的排序前三的适应度值和对应位置更新F_best、P_best,且此刻具有最高适应度值的灰狼作为头狼α,适应度次高的灰狼作为灰狼β,适应度第三高的灰狼作为灰狼δ,执行3.5步;如果此刻适应度最高值经过若干迭代搜索后仍然保持不变,则引入混沌扰动机制,在当前最优位置即P_best中的三只头狼的领域内根据下面的公式进行搜索:
其中和为当前三只头狼在搜索范围内的混沌化后的变量,是[0,1]之间干扰系数,然后执行步骤3.5;
步骤3.5:灰狼位置更新:根据公式(10)(11)(12)分别计算头狼α、β和δ距猎物的距离其中和分别为步骤3.4所得的头狼α、β和δ的位置,和根据公式(13)计算,其中为[0,1]之间的随机数;根据公式(14)(15)(16)(17)对每只狼的位置进行更新其中,限据公式(18)计算,是随迭代次数由2到0之间的线性递减,并根据公式(19)计算,是[0,1]之间的随机数。
步骤3.6:判断是否达到最大迭代次数T,若已达到则转到步骤3.7,否则转到步骤3.3;
步骤3.7:输出头狼a的位置,即最优的惩罚系数C和核宽γ值。
本发明实现的关键创新点和效果在于:
1.融合混沌灰狼优化算法与支持向量机获取一种高效精准的智能分类、预测模型;
2.通过混沌灰狼算法优化支持向量机的关键参数即惩罚系数C和核宽γ;
3.将惩罚系数C和核宽γ编码为灰狼的位置进行优化;
4.由混沌初始化灰狼,在优化过程中提出了混沌干扰的概念,以防止陷入局部极值;
5.混沌灰狼优化惩罚系数C和核宽γ过程中采用K折交叉验证。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的类似附图。
图1为本发明的基于混沌灰狼与支持向量机分类、预测方法流程图;
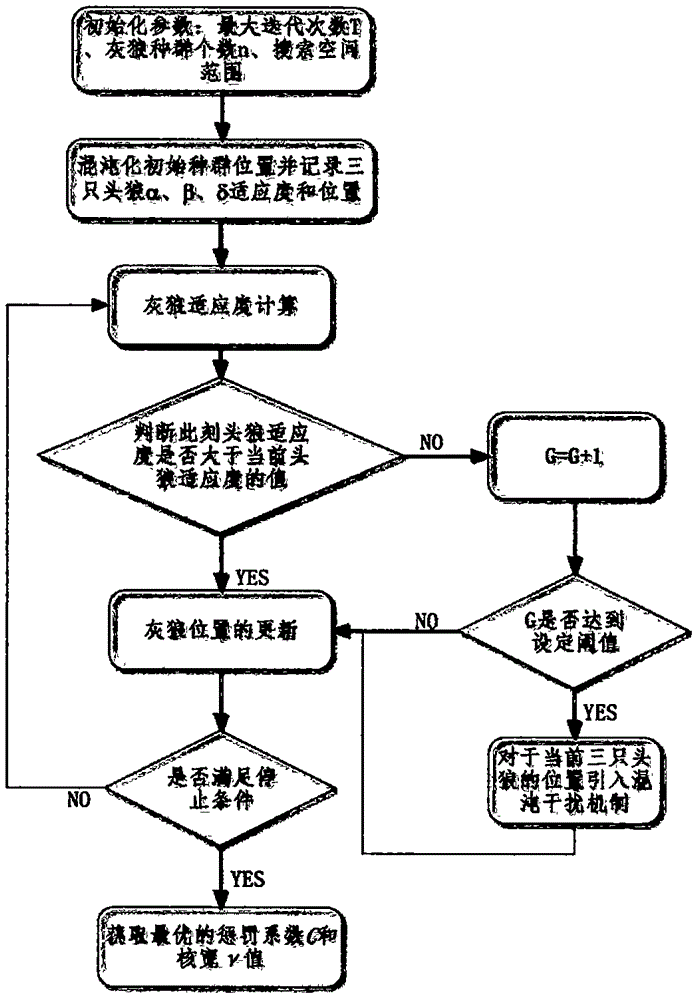
图2为本发明的惩罚系数C和核宽γ优化流程图;
图3为本发明的灰狼位置编码示意图;
图4为本发明的支持向量机模型。
具体实施方式
如图1所示,显示出本发明的基于混沌灰狼优化算法与支持向量机的智能分类和预测方法,该方法采用混沌化的灰狼算法优化支持向量机的关键参数包括惩罚系数C和核宽γ,基于获取的最优参数值构建最佳支持向量机模型,并实现对具体领域问题进行分类和预测。
如图1所示,方法包括如下具体步骤:
步骤1:收集待研究问题相关的数据;针对不同领域的待研究问题,其样本数据格式通常包括该领域内的属性指标和类别标签。具体举例来说,在研究棉花异性纤维识别时,其数据集的收集是从异性纤维的颜色特征、形状特征和纹理特征这三个角度来描述异性纤维的,且该数据集的异性纤维的类别标签包括6类:‘1’代表该异性纤维样本为颜料布类,‘2’代表该异性纤维样本为化纤布类,‘3’代表该该异性纤维样本为麻绳类,‘4’代表该该异性纤维样本为毛发类,‘5’代表该该异性纤维样本为丙纶丝类,‘6’代表该该异性纤维样本为羽毛类。
步骤2:利用公式(1)进行对收集数据进行标准化;
式中,Si代表原始值,Si’代表标准化后的值,Smin代表极小值,Smax代表极大值。
步骤3:利用混沌灰狼算法优化支持向量机的惩罚系数C和核宽γ;
步骤4:基于步骤3获取的惩罚系数C和核宽γ值,构建下述公式(2)(即构建好的模型)识别模型f(x),其中的K(xi,xj)的具体形式如公式(3)(即核函数)所示,其中γ即为核宽,xj表示待测样本,xi(i=1…l)表示与支持向量对应的训练样本,yi(i=1…l)表示与上述训练样本对应的标签,b为阈值,αi是拉格朗日系数,sgn为符号函数。
K(xi,xj)=exp(-γ|xi-xj||2) (3)
步骤5:基于步骤4所构建的模型(公式(2))对待分类样本进行分类和预测。
具体对于步骤3,其子步骤如下:
步骤3.1:参数初始化,包括对最大迭代次数T、灰狼群体中狼的头数n、C的搜索空间[Cmin,Cmax]和γ的搜索空间[γmin,γmax]进行初始化;
步骤3.2:灰狼位置混沌初始化:首先随机产生第一只灰狼的位置Xl=(xl1,xl2),然后从现存的混沌映射函数中(如Logisticmap公式(4),其中μ为控制参量,当μ=4时,Logistic映射处于完全混沌状态)选择一种合适的映射获得n-1只灰狼的位置,其中每只灰狼i的位置为Xi=(xi1,xi2);采用公式(5)(其中a1是小于b1的值,且Z’i∈[a1,b1])将每一只灰狼的位置映射到设定的搜索范围内得到n只灰狼的位置X’i=(x’i1,x’i2)(i=1…n),如图3所示编码,其中x’i1表示灰狼i在当前位置时的C值,x’i2表示灰狼i在当前位置时的γ值;
计算每只灰狼i的适应度fi,该适应度基于灰狼i当前位置的C和γ值,以内部K折交叉验证策略计算支持向量机的准确度ACC,并将该值作为灰狼i的适应度fi的值,将适应度fi由大到小排序,接着将适应度排在前三的三只狼的适应度值保存为向量F_best(fa,fb,fc)(a、b、c都是在[1,n]之间的值)且将其位置作为三只头狼的位置,保存为P_best(X’a,X’b,X’c)(a,b,c的范围在[1,n]之间)并参照公式(10)至公式(19)对灰狼的位置进行更新,获得n只灰狼的位置X”i=(x”i1,x”i2)(i=1…n),采用公式(5)将每一只灰狼的位置映射到设定的搜索范围内得到n只灰狼的初始位置Xi_Initialization=(xi1,xi2)(i=1…n),至此灰狼位置混沌初始化完成。其中ACC是基于K折交叉验证获取的平均准确度,根据公式(6)计算获得,其中acck表示每一折数据上计算获得的准确度;
Z(i+1)=μ·Z(i)·(1-Z(i)) (4)
Z’i=a1+(b1-a1)·Zi (5)
步骤3.3:采取和步骤3.2中相同的C和γ编码方式后以内部K折交叉验证策略计算每一只灰狼的适应度;
步骤3.4:对狼群按步骤3.3所得的适应度值由高到低进行排序,如果此刻适应度最高值大于fa,并以此刻降序的排序前三的适应度值和对应位置更新F_best、P_best,且此刻具有最高适应度值的灰狼作为头狼α,适应度次高的灰狼作为灰狼β,适应度第三高的灰狼作为灰狼δ,执行3.5步;如果此刻适应度最高值经过若干迭代搜索后仍然保持不变,则引入混沌扰动机制,在当前最优位置即P_best中的三只头狼的领域内根据下面的公式进行搜索:
其中和为当前三只头狼在搜索范围内的混沌化后的变量,是[0,1]之间干扰系数,然后执行步骤3.5;
步骤3.5:灰狼位置更新:根据公式(10)(11)(12)分别计算头狼α、β和δ距猎物的距离其中和分别为步骤3.4所得的头狼α、β和δ的位置,和根据公式(13)计算,其中为[0,1]之间的随机数;根据公式(14)(15)(16)(17)对每只狼的位置进行更新其中,限据公式(18)计算,是随迭代次数由2到0之间的线性递减,并根据公式(19)计算,是[0,1]之间的随机数。
步骤3.6:判断是否达到最大迭代次数T,若已达到则转到步骤3.7,否则转到步骤3.3;
步骤3.7:输出头狼α的位置,即最优的惩罚系数C和核宽γ值。
具体实施例应用
农业中对于棉花的采摘、摊晒、收购、储存、运输、加工过程中混入棉花中对棉花及其制品的质量有严重影响的非棉纤维和色纤维的检测分类,主要是一种对棉花异性纤维的检测识别方法,包括以下步骤:
步骤1.收集数据集:棉花异性纤维数据样本集合可以表示成如下形式:(xi,yi),i=1,2,3,4,……,其中每一个‘xi’表示75维的特征向量,其中包括了颜色特征、形状特征和纹理特征;颜色是区分棉花异性纤维的一种比较明显且重要的特征,针对棉花异性纤维在RGB、HIS彩色空间进行颜色提取,共产生了24个特征维,紧接着对棉花异性纤维的形态学特征进行整理,在针对异性纤维的长度、宽度、长宽比、面积、周长、圆度等进行特征提取;最后针对异性纤维的纹理特征反映的图像亮度空间变化从纹理的强度、密度、方向和粗糙度等来刻画异性纤维的纹理特征,从yi则代表值为1、2、3、4、5或6的样本标签,‘1’代表该样本为颜料布类,‘2’代表该样本为化纤布类,‘3’代表该样本为麻绳类,‘4’代表该样本为毛发类,‘5’代表该样本为丙纶丝类,‘6’代表该样本为羽毛类。
步骤2.对收集数据进行处理:
首先将待测试样本数据的各个特征属性值进行标准化(参照公式1),随后利用混沌灰狼算法优化支持向量机的惩罚系数C和核宽γ,且在内部采用K折交叉策略进行优化(即将导入模型的样本进行K折切割,每一次都以其中的K-1折作为训练数据,且在训练的同时采用混沌灰狼优化算法对于其中两个关键参数进行优化,期望获得最佳的智能棉花异性纤维识别模型,模型构建好后,再利用剩余的数据作为测试数据,对构建的智能识别模型进行评估),简而言之就是针对不同的智能分类决策问题,我们需要采用具有全局搜索能力的混沌灰狼优化算法去实现构造出针对此类问题最佳的分类决策模型,如之前论述:惩罚系数C和核宽γ对该模型的性能产生重要影响,也就是说,这两个参数取值的好坏将直接影响决策模型的性能,据此我们提出混沌灰狼优化算法实现上述两个参数的优化选择,当前主要的方法有:枚举法、网格法、遗传算法等,在此处我们提出将混沌理论引入灰狼算法(包括混沌初始化和混沌扰动机制),不仅改善了灰狼优化算法跳出局部极值点的概率,也在一定程度上提高了算法的收敛速度和解的质量。
步骤3.构建模型
初始化灰狼算法的相关参数:包括对最大迭代次数T、灰狼群体中狼的头数n、C的搜索空间[Cmin,Cmax]和γ的搜索空间[γmin,γmax]初始化;
紧接着对灰狼的位置进行混沌初始化:该过程参照步骤3.2;
对于灰狼的位置进行编码,其编码方式如图3,设置C和γ值;
输入棉花异性纤维数据训练样本xi,i=1,…,n,及其对应的输出yi∈{1,2,3,4,5,6};依据拉格朗日乘子理论,得到如下表达式:
然后对于以上的优化问题采用混沌灰狼优化算法对惩罚系数C和径向基核宽γ进行选择,期间每一次的计算获得的识别精度被称为适应度值,具体参数选择过程参照步骤3.4-3.7步,最终获取最佳的C和γ值,最后求解出拉格朗日乘子:
a=(a1,a2,…,al)T
和w,b:
那么最终的最优分类超平面函数便确定为其结果为1或2或3或4或5或6,分别表示不同类型的异性纤维。具体的支持向量机模型参见图4。
本申请由于将灰狼算法混沌化与支持向量机进行融合,通过具有优秀全局寻代能力的混沌灰狼算法优化支持向量机的两个关键参数即惩罚系数C和核宽γ,获取最优的核极限学习机参数值,从而使得本申请可以获得更准确的智能决策效果,有效地辅助决策机构进行科学合理的预测和决策,具有重要的应用价值。
- 还没有人留言评论。精彩留言会获得点赞!