一种图像推理重建的方法与流程
本发明涉及图像处理技术,尤其是指对图像中物体数量,形状,位置进行推理重建。
背景技术:
人对视觉景象知觉是高度结构化的。利用解释概率模型来对图像进行推理,有着悠久的历史,但在实践中的应用比较困难,因为很难定义模型,需要模型有足够的表现力来处理自然场景的复杂性,以及推论必须易处理易控制。
本发明基于图像推理重建的方法,使用递归神经网络进行概率推理。对场景元素进行一次性处理。关键地,模型自己选择合适的推理次数。这样的模型学习识别多个对象,场景元素的数量,定位和分类,不需要人工监管。举例来说,用单次神经网络分解不同数量的对象的三维图像。和有监督的情况对比,本专利所用网络产生推论非常准确。该模型的推理非常高效,结构化的图像模型,实现了对场景的解释。关键地,我们的模型可以处理复杂场景的推理。
技术实现要素:
针对实践中很难定义模型等问题,本发明的目的在于提供一种图像推理重建的方法,可以对图像中物体数量,形状,位置进行推理重建。
为解决上述问题,本发明提供一种图像推理重建的方法,其主要内容包括:
(一)数据集的导入;
(二)模型识别;
(三)图像推理;
(四)图像学习;
(五)图像重建;
其中,所述的一种图像推理重建的方法,其特征在于,整个过程不需要人为监督,模型自己选择合适的推理次数。
其中,所述的数据集的导入,包括一个多重数据集,每个图像包含零个、一个或两个非重叠的物体。
其中,所述的模型识别,在生成模型中处理任务的推理,步骤如下:
1)给出一个图像x和一个模型通过θ参数化,通过计算后面的为底层的场景描述
2)捕捉我们的基本场景,是场景描述渲染如何来形成图像的模式,许多现实世界的场景自然分解成相应的对象;因此,我们的建模假设的场景描述被构造成一组变量子zi,其中每个组描述的场景中的一个对象的属性,例如,它的类型,外观和姿势;由于对象的数量在每个场景中不同,我们假设以下形式的模型
3)z=(z1,z2,…,zn)是从场景模型采样,最后,我们根据表达图片,由于对象的索引是任意的,是可交换的,排列不变
4)每个物体i假定两种变量,分别为和它们的意义(在像素空间中的位置和尺度与三维空间中的位置和方向),和它们的数据类型(连续与离散)都是不同的,我们假设zi和之前的是独立的,则
其中,所述的图像推理,包括采用变分近似,通过学习分布,通过参数化,最大限度地减少分歧网络运行的n步,在每个步骤中解释在场景中一个对象,简化对象的数量的顺序推理步骤如下:
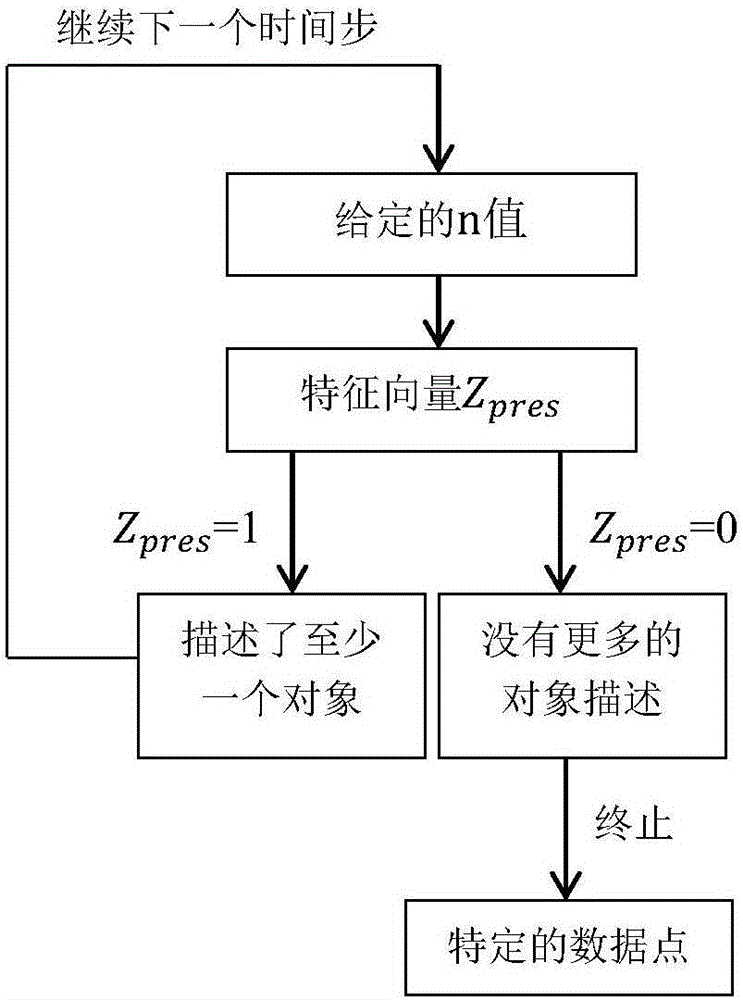
1)使参数n为一个可变长度的特征向量Zpres对于给定的n值,Zpres是由n一个接一个为0形成的矢量,这两个表示等量
2)采取以下形式
其中,作为一个神经网络实现,在每一个步骤中,输出的参数的抽样分布的潜变量,例如,连续变量的高斯分布的平均值和标准偏差
3)Zpres可以理解为一个中断变量,在每一个时间步长,如果网络输出Zpres=1,它描述了至少一个更多的对象,并继续到下一个时间步,如果网络输出Zpres=0,没有更多的对象描述,推理终止,注意调节zi|x,z1:i-1是捕捉潜在变量zi之间的依赖关系的关键。
其中,所述的图像学习,包括共同优化推理网络模型的参数θ和通过最大限度地降低模型边缘
其中被称为负自由能。
其中,所述的图像重建,随着模型注意窗口的可视化,第一,第二和第三个时间步分别显示为不同颜色方框;没有看到第三种颜色的边框,说明在这个数据没有超过两个时间步,主要作用有:
1)模型正确的识别物体的个数,这是由每个图像中的注意窗口的数量表示的,我们还计算了在训练过程中的计数推断的准确性
2)它准确地定位物体
3)回归网络学习一个合适的扫描方法,以确保不同的物体占不同的时间步
4)当图像只包含一个物体时,网络学习不使用第二个时间步。
进一步的,所述的图像推理的模型θ参数,其特征在于,包括的计算,从近似给定一个样本;计算提供的p是可微的。
进一步的,所述的图像推理的推理网络参数,其特征在于,步骤包括:
1)RNN实现产生现场变量z和变量的抽样分布参数
2)对于时间步长i,ω表示变量的抽样分布的参数,变量的抽样分布的所有参数用ωi表示
3)根据z1:i-1分布和x确定参数,使用递归函数实现神经网络
4)通过链式法则获得全梯度
其中,的计算方法如下:
1)函数定义为让zi作为向量的任意元素,根据zi是连续还是分离进行计算
2)假设zi是连续变量。对于许多连续变量(实际上没有一般性的损失),zi可以作为h(ξ,ωi)采样。H是确定性转换函数,ξ是一个固定的噪点分布p(ξ)的随机变量,获得梯度估计
3)离散变量(如),我们使用的似然比估计,给定一个后验样本可以得到一个估计的梯度如下
附图说明
图1是本发明一种图像推理重建的方法的系统流程图。
图2是本发明一种图像推理重建的方法的图像推理示意图。
图3是本发明一种图像推理重建的方法的图像重建示意图。
图4是立方体和圆柱体的三维生成模型。
图5是桌面场景陶器的三维生成模型。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
图1是本发明一种图像推理重建的方法的系统流程图。如图1所示,本发明中提出的一种图像推理重建的方法的系统流程图,其主要内容包括:
1、数据集的导入,包括一个多重数据集,每个图像包含零个、一个或两个非重叠的物体。
2、模型识别,在生成模型中处理任务的推理,步骤如下:
(一)给出一个图像x和一个模型通过θ参数化,通过计算后面的z为底层的场景描述
(二)捕捉我们的基本场景是场景描述渲染如何来形成图像的模式,许多现实世界的场景自然分解成相应的对象;因此,我们的建模假设的场景描述被构造成一组变量子zi,其中每个组描述的场景中的一个对象的属性,例如,它的类型,外观和姿势;由于对象的数量在每个场景中不同,我们假设以下形式的模型
(三)z=(z1,z2,…,zn)是从场景模型采样,最后,我们根据表达图片,由于对象的索引是任意的,是可交换的
(四)每个物体i假定两种变量,分别为和它们的意义(在像素空间中的位置和尺度与三维空间中的位置和方向),和它们的数据类型(连续与离散)都是不同的,我们假设zi和之前的是独立的,则
3、图像推理,采用变分近似,通过学习分布,通过参数化,最大限度地减少分歧网络运行的n步,在每个步骤中解释在场景中一个对象;
其中,推理网络参数,步骤包括:
(一)RNN实现产生现场变量Z和存在的变量的抽样分布参数
(二)对于时间步长i,ω表示变量的抽样分布的参数,变量的抽样分布的所有参数用ωi表示
(三)根据z1:i-1分布和x确定参数,使用递归函数实现神经网络
(四)通过链式法则获得全梯度
其中,的计算方法如下:
1)函数定义为让zi作为向量的任意元素,根据zi是连续还是分离进行计算
2)假设zi是连续变量,对于许多连续变量(实际上没有一般性的损失),zi可以作为h(ξ,ωi)采样;H是确定性转换函数,ξ是一个固定的噪点分布p(ξ)的随机变量,获得梯度估计
3)离散变量(如),我们使用的似然比估计,给定一个后验样本可以得到一个估计的梯度如下
4、图像学习,包括共同优化推理网络模型的参数θ和通过最大限度地降低模型边缘
其中被称为负自由能。
5、图像重建,随着模型注意窗口的可视化,第一,第二和第三个时间步分别显示为不同颜色方框;没有看到第三种颜色的边框,说明在这个数据没有超过两个时间步主要作用有:
(一)模型正确的识别物体的个数,这是由每个图像中的注意窗口的数量表示的,我们还计算了在训练过程中的计数推断的准确性
(二)它准确地定位物体
(三)回归网络学习一个合适的扫描方法,以确保不同的物体占不同的时间步
(四)当图像只包含一个物体时,网络学习不使用第二个时间步。
图2是本发明一种图像推理重建的方法的图像推理示意图,简化对象的数量的顺序推理步骤如下:
1)使参数n为一个可变长度的特征向量Zpres对于给定的n值,Zpres是由n一个接一个为0形成的矢量,这两个表示等量
2)采取以下形式
其中,作为一个神经网络实现,在每一个步骤中,输出的参数的抽样分布的潜变量,例如,连续变量的高斯分布的平均值和标准偏差
3)Zpres可以理解为一个中断变量,在每一个时间步长,如果网络输出Zpres=1,它描述了至少一个更多的对象,并继续到下一个时间步,如果网络输出Zpres=0,没有更多的对象描述,推理终止,注意调节zi|x,z1:i-1是捕捉潜在变量zi之间的依赖关系的关键。
图3是本发明一种图像推理重建的方法的图像重建示意图。包括一个多重数据集,每个图像包含零个、一个或两个非重叠的物体。随着模型注意窗口的可视化,第一,第二和第三个时间步分别显示为不同颜色方框;没有看到第三种颜色的边框,说明在这个数据没有超过两个时间步。
图4是指定立方体和圆柱体的三维生成模型,概率渲染将场景转化为图像中产生的像素。用概率渲染器的推断计算量很大,容易陷入局部最小值。因此,用推理网络的形式是非常可取的。另外,概率渲染通常不能提供相对的输入梯度,3D场景表示往往涉及离散变量。利用有限差分通过渲染得到的梯度,使用得分函数估计得到相对于离散变量的梯度,最后利用推理结构来处理。
首先考虑场景的三个对象组成的,一个立方体和一个圆柱体,由于场景只包括单个对象,该任务只推断的形状(立方体,圆柱体)和姿势(位置和旋转)的对象中存在的图像,我们训练了一个单一的步骤(n=1)推理网络。网络准确可靠地推断出身份和场景中的物体的姿势。
图5是桌面场景陶器的三维生成模型,考虑两种情况:一个每个对象类型只出现一次,一个对象可以在场景中重复。通过推断统计,改变瓷器的种类和桌面陶器物品数目,在无监督的情况下来完成这项任务。在图中展示了推理的重建,展现了鲁棒性和正确性。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!