一种虚拟现实系统的手部动作捕捉方法与流程
本发明涉及虚拟现实解析技术领域,尤其是一种虚拟现实系统的手部动作捕捉方法。
背景技术:
在传统的手部动作捕捉方法中,系统的设计者自行设计手势的开始动作来划分手部的动作过程的开始、稳定、结束三个阶段,比如做L型的直线等。但这些方法的缺陷在于要求用户在每个手势前都要做一个附加动作使动作捕捉变得繁琐且不友好。
技术实现要素:
本发明提出的一种虚拟现实系统的手部动作捕捉方法,大大提高动作捕捉的正确率及速度,满足实时捕捉的要求。
本发明的技术方案是这样实现的:
一种虚拟现实系统的手部动作捕捉方法,手部的动作过程分为开始、稳定、结束三个阶段,当处于稳定阶段时手是保持不变的,而在开始和结束阶段都有手的运动,具体捕捉过程包括以下步骤:
步骤1:初始化faceLable=0,start=0,gesture=0;
步骤2:摄像头开启后,不断的检测人脸,当检测到可靠人脸时,获得肤色区域的肤色像素建立肤色高斯模型(当建立肤色模型后在后续帧中就不用检测脸部区域);并将此帧图像设定为背景图bgimg,标记faceLable=1转步骤3,否则继续检测视频流直至获取可靠的人脸区域;
步骤3:当在视频流中检测到start=1且gesture=-1时转步骤4,否则继续检测;
步骤4:用当前帧与步骤1中设定的背景图bgimg做差分的到差分二值图chafenimg,获取差分图中的最大运动区域moveROI中的每个像素标记为obj、 bkg或者是unknown从而获得分割模板maskimg,如果maskimg中标记为obj的像素个数大于阈值objNum,则判断此帧为手势稳定帧,令gesture=1转步骤5,否则,用当前帧更新背景bgimg,并重置start=0,gesture=0转步骤3;
步骤5:在moveROI区域中,结合分割模板maskimg,利用Graph Cuts算法进行图像分割,得到手部动作二值图,
本发明通过提供的虚拟现实系统的手部动作捕捉方法,其有益效果在于:实时建立肤色模型,对光照及不同用户肤色的差异具有一定的鲁棒性,并且允许用户的脸部进入摄像头视野减少对用户的限制;采用双阈值法,保证手部像素的正确标记,能获得完整的手部动作;利用背景差分法,可去除背景中的类肤色区域,将分割区域限制在比较小的感兴趣区域moveROI内,大大提高动作捕捉的正确率及速度,满足实时捕捉的要求。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为手部动作的三个阶段转换图;
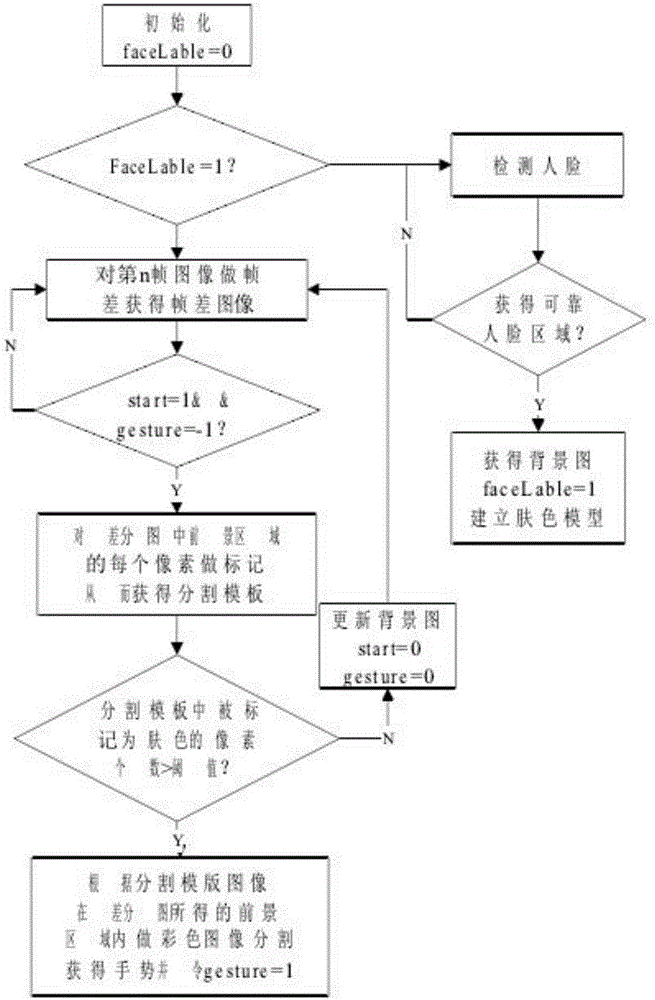
图2为手部动作捕捉流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人 员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本实施例的虚拟现实系统的手部动作捕捉方法,在实施时需要基于以下两点要求:1、视频的前几帧检测人脸时,用户并没有手势;2、为了获得较好的分割效果,用户做手势时要求要在头部以上的区域进行,避免和人脸重合,并且每个手势要停顿几秒。一般情况下,这两点要求是合理的并且可以达到。
在实际情况中,用户手部的动作过程分为开始、稳定、结束三个阶段,开始,即抬起手部到维持某种手势的过程;稳定,即维持某种静态手势的阶段;结束,即手势完成放下手部的过程。三个阶段的转换如图1所示。
本实施例中,采用标识start、gesture来区分这三个阶段,start,标识手势的开始,避免对同一次手势多次重复采集和识别;gesture,标识手势的稳定,只有在这个阶段采集到的手势才是准确的手势。
在自然状态下,当处于稳定阶段时手是保持不变的,而在开始和结束阶段都有手的运动,故将手部动作划分这三个阶段:当前后两帧帧差图中有运动物体时则令start=1;当start=1且又检测到帧差图没有运动物体时令gesture=-1,此时可能为手势的稳定阶段也可能只是背景中其他的运动物体引发了此状态,只有当此帧分割出的前景区域中,肤色像素个数大于某阈值时,才确定此帧为手势稳定的关键帧并令gesture=1,否则用此帧来更新背景,并重置start=0,gesture=0,继续检测视频流。
如图2所示,具体捕捉过程包括以下步骤,:
步骤1:初始化faceLable=0,start=0,gesture=0;
步骤2:摄像头开启后,不断的检测人脸,当检测到可靠人脸时,获得肤色区域的肤色像素建立肤色高斯模型(当建立肤色模型后在后续帧中就不用检测脸部区域);并将此帧图像设定为背景图bgimg,标记faceLable=1转步骤3,否则继续检测视频流直至获取可靠的人脸区域;
步骤3:当在视频流中检测到start=1且gesture=-1时转步骤4,否则继续检测;
步骤4:用当前帧与步骤1中设定的背景图bgimg做差分的到差分二值图chafenimg,获取差分图中的最大运动区域moveROI中的每个像素标记为obj、bkg或者是unknown从而获得分割模板maskimg,如果maskimg中标记为obj的像素个数大于阈值objNum,则判断此帧为手势稳定帧,令gesture=1转步骤5,否则,用当前帧更新背景bgimg,并重置start=0,gesture=0转步骤3;
步骤5:在moveROI区域中,结合分割模板maskimg,利用Graph Cuts算法进行图像分割,得到手部动作二值图,
算式中,maskimg(x)表示分割模板图中点x被标记的值,它的取值是obj、bkg或者是unknown中的一种,chafenimg(x)表示在背景差分图中点x的像素值,若为255表示前景,为0表示背景。p(x)为像素x的肤色概率,TH1、TH2为概率阈值且TH1>TH2。对区域moveROI中的任一点x,若它在差分图中是前景,则它很有可能是手势,此时若其肤色概率值p(x)大于高阈值,就肯定其为手势种子点,若p(x)虽小于高阈值大于低阈值,则不能判定改点为手势还是背景,将其标记为unknown;若它在差分图中为背景,则它很有可能是背景,但是若其肤色概率值p(x)大于高阈值,则不能确定其为手势或北京,也将其标记为unknown;其他情况都将其为背景种子点。算式中的高概率阈值TH1保证被标记为obj的正确率,低概率阈值防止将某些手部像素标记为bkg。
运用本实施例提出的方法,应用在虚拟现实系统中,可实时建立肤色模型,对光照及不同用户肤色的差异具有一定的鲁棒性,并且允许用户的脸部进入摄像头视野减少对用户的限制;采用双阈值法,保证手部像素的正确标记,能获得完整的手部动作;利用背景差分法,可去除背景中的类肤色区域,将分割区域限制在比较小的感兴趣区域moveROI内,大大提高动作捕捉的正确率及速度,满足实时捕捉的要求。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!