基于稀疏学习的突发事件摘要抽取方法与流程
本发明属于文本信息处理领域,涉及一种基于稀疏学习的突发事件摘要抽取方法。
背景技术:
生活在信息时代中,用户获取感兴趣的事件话题的海量报道不再是难题。但是,big data并不意味着big knowledge,尤其是当突发事件发生时,相关事件报道数量呈爆发式增长。这样以来,如何从几何增长的海量新闻数据流中,进行高效,及时而又便捷地动态追踪特定话题突发事件的发展状态,最终形成便于读者阅读的事件发展脉络摘要,从而帮助人们从众多的新闻报道中快速获取到自己所感兴趣的突发事件的最新发展状态,成为一项十分迫切的任务。
传统多文档摘要抽取方法大部分都进行基本层面的冗余信息过滤,从每个时间窗内抽取固定数目的句子,形成固定长度的摘要。然而这种摘要分方法没有从数据集的本质去解决问题——面对海量冗余的新闻数据流,寻找特定话题的相关事件犹如大海捞针,而同一时期的话题数量又是惊人的,因此必须采取有效的特征提取方法,选取能够反映该时期内能够表示事件的最小冗余的话题集合。此外,传统摘要抽取技术往往忽视了新闻文本数据样本之间的语义关系,而只关注单个句子评分,这样的只抽取得分最高的句子作为最终的摘要句子,虽然单句准确率很高,但往往就总体而言,对突发事件的描述往往不够全面或者冗余太大。
技术实现要素:
为解决以上问题,本发明提供一种基于稀疏学习并融合文本语义特征选择的突发事件话题摘要抽取方法,主要从以下方面提高摘要的性能,一方面是对用户的感兴趣的简短事件话题利用外部知识库进行了扩展,另一方把文本的语义特征融合在特征选择的过程中,最后提出一个统一框架。
为实现上述目的,本发明采用如下的技术方案:
一种基于稀疏学习理论的突发事件摘要抽取方法包括以下步骤:
步骤S1、获取TREC 2015Temporal Summarization track提供的21个突发事件话题,对每个突发事件话题进行查询扩展,得到事件话题的扩展话题词项集合;
步骤S2、首先对TREC-TS-2015F-RelOnly数据集进行解密,解压,解析,转换成TREC格式的数据,然后利用Lemur中调优的语言模型作为检索模型,根据每个事件查询扩展后的扩展话题词项对每个事件进行检索,获得与每个事件话题相关的文档集合;
步骤S3、利用非负矩阵分解的方法依次对每个话题的文档集合进行特征选取和语义聚类,得到每个事件的话题聚类结果。
步骤S4、根据最大边缘相关性方法(MMR),从聚类结果中抽取具有代表性的句子作为最终的摘要结果。
作为优选,步骤S3具体为:采用矩阵分解的方法进行特征降维,将语义约束融合到特征降维的聚类过程中,建立基于非负矩阵分解的互信息保留的事件摘要框架,进而得到每个事件话题对应的聚类结果。
本发明的基于稀疏学习的突发事件摘要抽取方法,首先,通过结合多搜索引擎的搜索结果,对简短的事件话题描述进行有效的扩展;然后基于稀疏学习的理论(NMF),提出了一种能够高效解决大规模数据稀疏的特征选取方法;其次,通过综合文本的全局与局部语义约束,从而发掘语义空间中的语义分布特性;最后,将文本全局语义和局部语义约束作为NMF的最优化正则项,建立融合特征选取过程和文本语义的抽取式摘要的统一框架。
本发明提出的基于稀疏学习理论的突发事件摘要抽取方法,在突发事件爆发时,面对海量冗余的新闻报道流,为用户提供事件发展的最新状况信息,并且给用户提出了可回顾性的事件发展脉络,从而使各种用户能够便捷高效地获取自己感兴趣的新闻报道,提高生活和工作的效率。
附图说明
图1是本发明系统的摘要系统整体流程示意图;
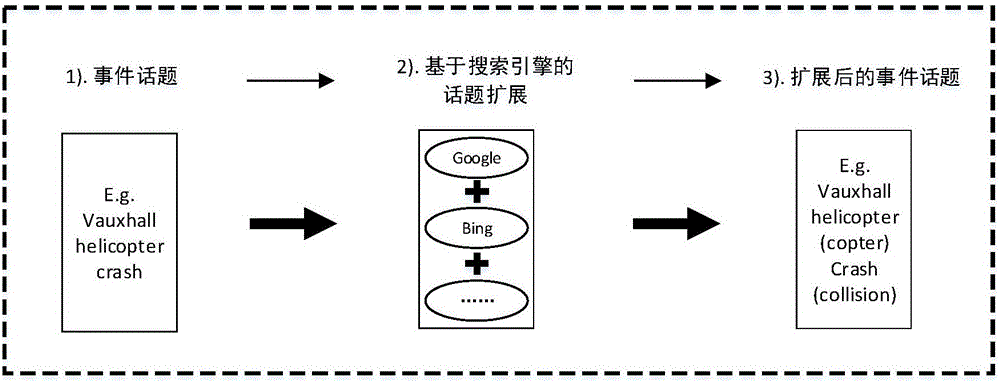
图2是本发明的事件话题扩展流程示意图;
图3是本发明摘要统一框架建模的示意图;
图4是本发明的互信保留语义计算的示意图;
图5是本发明方法和目前经典的方法的实验结果对比图,其中,
图5a为时间延迟的期望增益(类似准确率)对比图;
图5b为延迟全面率(类似召回率)的对比图;
图5c为F measure(类似F值)的对比图。
具体实施方式
以下将结合附图所示的具体实施方式对本发明进行详细描述。
如图1所示,本发明实施例提供一种基于稀疏学习理论的突发事件摘要抽取方法包括:
步骤S1、获取TREC 2015Temporal Summarization track提供的21个突发事件话题,对每个突发事件话题进行查询扩展,得到事件话题的扩展话题词项集合;
步骤S2、首先对TREC-TS-2015F-RelOnly数据集进行解密,解压,解析,转换成TREC格式的数据,然后利用Lemur中调优的语言模型作为检索模型,根据每个事件查询扩展后的扩展话题词项对每个事件进行检索,获得与每个事件话题相关的文档集合;
步骤S3、利用非负矩阵分解的方法依次对每个话题的文档集合进行特征选取和语义聚类,得到每个事件的话题聚类结果。
步骤S4、根据最大边缘相关性方法(MMR),从聚类结果中抽取具有代表性的句子作为最终的摘要结果。
部分一:事件话题扩展
本部分旨在对简短的事件话题利用搜索引擎进行查询扩展,旨在较为准确地描述用户感兴趣的突发事件事件话题,步骤如下:
步骤(1)解压,解析,预处理数据。
步骤(1.1)获取用户感兴趣的事件话题。
步骤(1.2)文本预处理,去除标点符号,将大写字母转换为小写。
步骤(2)爬取网页。
步骤(2.1)将预处理后事件话题分别利用多种搜索引擎的API,返回与该事件话题的相关页面。
步骤(2.2)对应每个搜索引擎的返回结果,只保留最相关的前N个页面的标题,这里N取50。
步骤(3)预处理网页标题
步骤(3.1)对所得页面标题,采用分词工具进行分词。
步骤(3.2)滤除停用词。
步骤(4)形成扩展的事件话题
步骤(4.1)对于同一个话题,对页面中标题出现的过滤后的每个词汇计算共现频数(DF),然后按照该词项的共现页面数(DF)由大到小进行排序,并取前p个作为扩展词项,这里p=10。
步骤(4.2)把原始词项和扩展词项形成最终的每个事件话题的查询词项的集合。
部分二:文档检索
本部分根据查询扩展词项集合,利用检索工具对其进行检索,获得与该数据相关的文本集合,达到数据集初步过滤的效果。
步骤(5)对语料集进行解压,然后运用python streamcorpus工具将其解析为检索工具可检索的格式。
步骤(6)下面是具体的检索过程。每一个事件话题需要按照如下步骤处理。
步骤(6.1)构建索引,运用检索工具对语料集构建索引。
步骤(6.2)选用合适的检索模型,这里选用概率模型。
步骤(6.3)运用检索模型根据扩展后的事件话题对数据集进行检索,获得与该事件话题相关的前q条句子,这里q(介于2000-6000)是选取条数,它根据该话题数据集的规模大小设置。
步骤(6.4)把检索结果保存在对应的文件中。
部分三:特征选取
步骤(7)采用矩阵分解的方法进行特征降维。
步骤(7.1)矩阵分解是一个最优化问题,目标函数的形式如下:
其中,L表示词项文档矩阵,U表示词项话题矩阵,H表示权重系数矩阵,它表示文档对话题的隶属度。f表示用分解后的矩阵重建初始矩阵的误差,是需要优化的目标值,表示矩阵X的F范数的平方。
步骤(7.2)降维过程中添加了两个降低模型复杂度的正则约束项。
部分四:语义约束
本部分针对传统方法在特征选择的过程中往往忽视或者不能有效保留原始高维空间的文本的语义特性的问题,本发明考虑如下解决方法。
步骤(8)采用了考虑数据点之间的全局语义邻近关系的约束;
K1=L*LT (3)
公式(3)中的K1对是高维空间文本之间的全局语义特性的表示。
步骤(9)采用了考虑数据点之间的局部语义相关性的约束;
k=1,2,…n且i,j∈{1,2,…,N}
其中,公式(4)的K2是基于词共现模型和改进互信息的高维空间的语义特性。其中p表示概率,t表示词项,I表示自信息,S表示一条句子,TF表示词项在文档中出现的频率,DF表示词项出现的文档数目。
步骤(10)本发明把全局语义和局部语义加权为一个正则项来约束特征选取的过程。
K=λK1+(1-λ)K2 (8)
公式(8)是综合考虑了文本的全局特性和局部语义特性的成对相似度矩阵K,其中λ是平衡因子,调整文本全局和局部语义特性所占的比例,本系统中,λ取值为0.5,认为文本的全局语义和局部语义特性在降维过程中同等重要,都需要保留。
部分五:统一建模
本部分旨在如何融合语义约束到特征降维的聚类过程中,统一建模。
步骤(11)综上所述,统一建模如下:
其中,α、β、γ分别表示三个正则项的权重系数,用来调整各部分所占的比例。在实验中,参数分别设置如下:α=0.05,β=0.001,γ=0.001。
步骤(12)采用如下经典的交替迭代方法的求解:
迭代公式如下:
其中,A,B,C,D的定义如下:
A=LHT+2αKUHHT,
B=UHHT+2αUHHTUTUHHT+βU,
C=UTL+2αUTKUH,
D=UTUH+2αUTUHHTUTUH+γH. (11)
步骤(13)上述算法的求解伪代码如下:
基于非负矩阵分解的互信息保留的事件摘要框架NMF-NPS(Negative matrix factorization with a neighborhood preserving semantic measure)。如下算法1所示。第一行首先利用全局和局部语义计算数据集的成对相似度矩阵K,4到19行是求解权重系数矩阵U和聚类中心的基向量矩阵H的迭代过程。算法终止的条件有三个,一是达到设定的最大迭代次数,或者优化目标值基本不再变化,或者优化的目标值达到设定的最小值。最后根据分解结果获取聚类结果。
步骤(14)获取聚类结果:
步骤(14.1)获得聚类中心实点,找到每个聚类中心的最近似的实际样本点(矩阵H的每一行向量代表一个聚类中心)。
步骤(14.2)获取每个聚类中心的类簇成员。根据每个样本的权重向量中的最大权重值对应的聚类中心作为该样本的聚类中心。
部分六:抽取摘要
本发明为了减少摘要的长度,和提高摘要的质量,因此只选具有代表性的少数句子。步骤(15)采用了最大边缘相关性(MMR)方法,对聚类结果的每个簇做了如下的两步处理:
步骤(15.1)选取和类簇中心最接近的句子作为该簇代表性句子,
步骤(15.2)在该类簇中选择另外一条和事件话题相关但是和本类簇中心差异较大的那条句子,以保证多样性
如图2所示,本发明的事件话题扩展,具体包括:
步骤(110)、获取事件话题,进行预处理。
步骤(120)、利用爬取相关网页。对于事件话题,分别运用谷歌,微软必应,雅虎浏览器对其检索,获取三个浏览器中最相关的前P个页面的标题,这里P=50。
步骤(130)、对所获的的页面标题集合进行预处理。如去除标点符合,分词,去停用词等。
步骤(140)、统计形成字典并统计每个词项的共现页面标题的个数(DF值),按照DF值由大到小排序。
步骤(150)、取排序序列中的前10个词项作为扩展词项,把原始词项和扩展词项形成最终的每个事件话题的扩展查询词项集。
如图3所示,为本发明的核心算法部分,融合特征选取和语义聚类为一体的统一建模部分,具体包括:
步骤(210)、首先公式的第一部分考虑对每个话题的冗余数据集进行特征降维。
步骤(220)、公式的第二部分是对特征选择的过程进行语义约束,旨在使降维后的低维空间尽大可能保留原始文档空间的全局和局部语义。
步骤(230)、公式的最后两部分是对聚类中心向量矩阵U和权重系数矩阵H做了一定的约束,防止过度拟合。
如图4所示,计算语义部分的成对相似度矩阵K包括:
步骤(310)、一方面在每个话题的相关数据集上,利用基于改进互信息方法和词频模型,计算局部语义相似度矩阵K1。
步骤(320)、另一方面在此话题相关的数据集上,利用样本数据点之间的几何距离计算全局语义相似度矩阵K2。
步骤(330)、最后将全局和局部语义相似度矩阵进行加权组合,形成该话题的成对语义相似度矩阵K。
步骤4中后采用最大边缘相关性方法(MMR),对聚类结果进行摘要。对于每个事件话题经过如下三步操作,形成最终的摘要结果,具体包括:
步骤(410)、首先为了保证话题相关度,选取和每个类簇的聚类中心最相似的那个数据样本点作为代表该类簇的一个样本点。
步骤(420)、然后为了保证较全面地描述该子事件,需要在该类簇中寻找和该聚类中心最不相似的样本点作为代表该类簇的另一个样本点。
步骤(430)、最后根据对摘要集中的样本点根据时间升序排序,获得最终的摘要结果。
如图5a、5b、5c所示,展示了本发明所用方法在对比试验中的性能。评价指标介绍:Latency Gain表示考虑时间延迟的期望增益,类似信息检索中的准确率;Latency Comprehensiveness表示延迟全面率,类似于信息检索中召回率;F measure,是评价摘要的主要指标,它综合考虑以上两个指标的折中,类似于传统信息检索中的F值。
显而易见,本发明中的方法优于目前的经典的AP(Affinity propagation Clustering Algorithm)算法。
在2015年TREC summarization Only国际文本评测任务中也优胜于参赛队与的平均水平,取得第二名的成绩。
综上分析,本发明基于稀疏学习的突发事件摘要抽取方法是有效地的。
应当理解,虽然本说明书根据实施方式加以描述,但是并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为了清楚起见,本领域的技术人员应当将说明书作为一个整体,各个实施方式中的技术方案也可以适当组合,按照本领域技术人员的理解来实施。
上文所列出的一系列详细说明仅仅是针对本发明的可行性实施方式的具体说明,它们并非用于限制本发明的保护范围,凡是未脱离发明技艺精神所作的等效实施方式或变更均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!