一种基于白盒的工艺映射方法及装置与流程
本发明涉及微电子领域中的集成电路设计技术领域,尤其涉及一种基于白盒的工艺映射方法及装置。
背景技术:
现场可编程门阵列(Field-Programmable Gate Array,FPGA)是一种具有丰富硬件资源、强大并行处理能力和灵活可重配置能力的逻辑器件。而工艺映射(Technology Mapping)作为FPGA设计过程中的一个重要步骤,将与工艺无关的结构描述映射为工艺相关的物理实现,使得各级综合系统抽象的综合结果能够转化为一种具体的工艺实现。
传统的工艺映射方法只能将单纯的组合逻辑(与、或、非逻辑等)映射到查找表上,随着FPGA芯片的不断发展,越来越多的特殊功能单元(如加法器、DSP等)出现在了FPGA芯片当中。因此,在工艺映射过程中,寻找一种通用的可以处理此类特殊功能单元模块的方法,是亟待解决的问题。
技术实现要素:
一方面,本发明实施例提供了一种基于白盒的工艺映射方法,该方法包括:将RTL级网表逻辑综合成结构化门级网表;遍历门级网表,获取门级网表中所包含的多个白盒;为每个白盒添加门级网表的实现,并为每个白盒生成时延表;根据门级网表、多个白盒以及分别对应多个白盒的多个时延表进行工艺映射,并计算工艺映射后的门级网表的逻辑时延和关键路径。
可选地,在上述方法中,在进行工艺映射时,根据白盒以及白盒的的周边逻辑进行逻辑优化,且不改变白盒的内部逻辑。
可选地,在上述方法中,时延表包括对应白盒的输入信号、对应白盒的输出信号以及输入信号与输出信号之间的时延。
可选地,在上述方法中,白盒为门级网表中的特殊逻辑功能模块,包括算术运算功能模块。
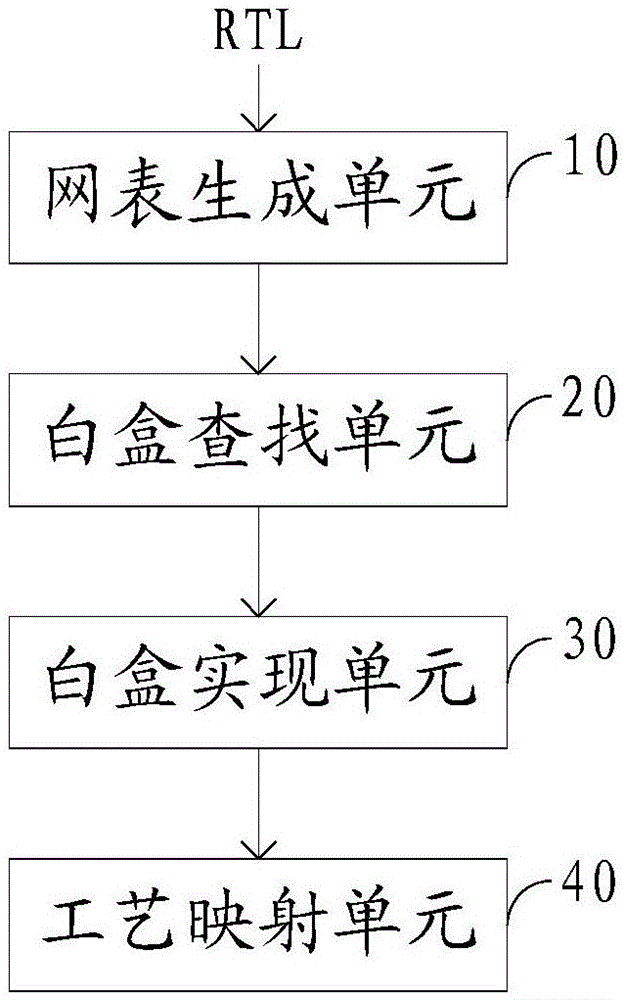
另一方面,本发明实施例提供一种基于白盒的工艺映射装置,该装置包括:网表生成单元用于将接收到的RTL级网表逻辑综合成结构化门级网表;白盒查找单元用于遍历门级网表,查找门级网表中所包含的多个白盒;白盒实现单元用于为每个白盒添加门级网表的实现,并为每个白盒生成时延表;工艺映射单元用于根据门级网表、多个白盒以及分别对应多个白盒的多个时延表进行工艺映射,并计算工艺映射后的门级网表的逻辑时延和关键路径。
本发明实施例所提供的基于白盒的工艺映射方法及装置,将门级网表中的算术逻辑单元识别为白盒,并用标准的组合逻辑门电路进行表示,而后对整个网表进行工艺映射,提供了一种在工艺映射过程中通用的处理特殊功能模块的方法。
附图说明
图1为本发明实施例提供的基于白盒的工艺映射方法流程示意图;
图2为本发明实施例所提供的基于白盒的工艺映射装置结构示意图;
图3为实施例一所提供的门级网表结构示意图;
图4为本发明实施例一全加器的组合逻辑电路结构示意图;
图5为本发明实施例一所提供的由标准逻辑电路组成的门级网表;
图6为本发明实施例一所提供的工艺映射后的网表。
具体实施方式
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
在现有技术中,工艺映射方法只能处理基于标准单元库的纯组合逻辑,并将上述组合逻辑映射到查找表中,但对于具有特殊功能的单元模块,如具有算术运算功能的加法器、减法器、DSP等只能采用将其从网表中暂时切除,同时将该单元模块的输入映射到整个网表的输出以及将该模块的输出映射到整个网表的输入进行妥协处理。显然,随着FPGA技术的发展,在FPGA芯片中,越来越多的加入了完成高速运算的加法器等算术运算功能模块,采用先切除再加入的方式进行工艺映射方法,失去了在工艺映射过程中对算术运算单元模块的逻辑优化过程。
本发明实施例提供一种基于白盒的工艺映射方法,图1为本发明实施例提供的基于白盒的工艺映射方法流程示意图,如图1所示,该方法包括:
步骤S101,将RTL(Register Transfer Level)级网表逻辑综合成结构化门级网表。
步骤S102,遍历门级网表,获取门级网表中所包含的多个白盒。
需要说明的是,在门级网表中将一些特殊逻辑功能模块作为白盒进行识别,如将进行算术运算的加法器、全加器、DSP(Digital Signal Process)等逻辑单元作为白盒,上述特殊逻辑功能模块指在传统工艺映射过程中需采用先切除后添加的无法与其他逻辑资源进行统一逻辑优化的功能模块,并不限于本发明实施例所提供的算术运算功能模块。
在上述步骤中,白盒内部的逻辑单元在下述工艺映射的过程中可以清晰“看见”,且白盒内部的逻辑单元在下述工艺映射过程中保持不变。提出白盒的概念,主要是为了在工艺映射过程中,保持白盒内部逻辑相对稳定的同时,又能保证白盒周围的逻辑依然可以“穿过”白盒完成优化,比如常数传播(constant propagation)。
步骤S103,为每个白盒添加门级网表的实现,并为每个白盒生成时延表。
需要说明的是,为每个白盒添加门级网表的实现即为将白盒所识别的逻辑单元用标准的组合逻辑门电路表示;在为白盒添加实现后,计算白盒当前表示中所有输入到输出的延时值,并将其以表格的形式进行记录(如表1)。
步骤S104,根据门级网表及其对应的多个白盒以及每个白盒的时延表进行逻辑优化完成工艺映射过程,并计算工艺映射后的门级网表的逻辑时延和关键路径。
根据上述方法,本发明实施例还提供一种基于白盒的工艺映射装置,图2为本发明实施例所提供的基于白盒的工艺映射装置结构示意图,如图2所示,该装置包括:
网表生成单元10,用于将接收到的RTL级网表逻辑综合成结构化门级网表。
白盒查找单元20,用于遍历所述门级网表,查找所述门级网表中所包含的多个白盒。
白盒实现单元30,用于为每个所述白盒添加所述门级网表的实现,并为每个所述白盒生成时延表。
工艺映射单元40,用于根据所述门级网表、所述多个白盒以及分别对应所述多个白盒的多个所述时延表进行工艺映射,并计算工艺映射后的所述门级网表的逻辑时延和关键路径。
为了更清楚的表达本发明实施例所提供的技术方案,下面通过具体的实施例进一步进行描述。
实施例一
以某FPGA设计过程中所产生的门级网表的部分逻辑部分为例,图3为实施例一所提供的门级网表结构示意图,如图3所示,网表中包含与门01、全加器02和异或门03,根据本发明实施例所提供的方法具体工艺映射的过程为:
步骤一,在获得图3所示的门级网表后,将全加器02识别为白盒,并将白盒用标准的组合逻辑电路进行表示,并最终获得全部由标准的逻辑电路组成的门级网表(如图5所示)。图4为本发明实施例一全加器的组合逻辑电路结构示意图,如图4所示,对全加器02添加门级网表的实现后,所获得的逻辑电路由一个数据选择器(multiplexer,简称MUX)和两个异或门组成。图5为本发明实施例一所提供的由标准逻辑电路组成的门级网表。
步骤二,计算图4所示逻辑电路的延时值,记录白盒中每个输入到输出的延时值,表1即为获得的延时表。
表1延时表
步骤三,对步骤二获得的门级网表进行逻辑优化,完成工艺映射,图6为本发明实施例一所提供的工艺映射后的网表,如图6所示,该网表由一个LUT、两个异或门以及一个MUX组成。计算网表的延时以及关键路径此处不予赘述。
如若上述工艺映射过程采用传统方法进行,便不能对全加器进行逻辑优化(最终获得的工艺映射后的网表即为图5所示),造成逻辑资源浪费。
专业人员应该还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!