一种神经网络加速器以及神经网络模型的实现方法与流程
本发明涉及一种神经网络的数据处理方法,尤其涉及一种神经网络加速器的实现方法。
本发明涉及一种模型的实现方法,尤其涉及一种神经网络模型的实现方法。
背景技术:
人工神经网络(Artificial Neural Network,ANN),是20世纪80年代以来人工智能领域兴起的研究热点。它从信息处理角度对人脑神经元网络进行抽象,建立某种简单模型,并按不同的连接方式组成不同的网络。在工程与学术界也常简称为神经网络或类神经网络。神经网络是一种运算模型,由大量的节点(或称神经元)之间相互连接构成,如图1所示的是一个神经元的示意图,每个节点代表一种特定的输出函数,称为激励函数;每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式、权重值和激励函数的不同而不同。而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
近年来异构加速器凭借其优秀的性能功耗比成为了目前体系结构研究的主流方向。同时随着深度学习的兴起,深度学习神经网络的研究也重新回到了机器学习领域的潮头。深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。因此,如何在加速器上高效地实现神经网络处理系统受到了学术界和工业界广泛的关注。目前,深度学习算法可实现在云端的CPU上,虽然负载能力强,但是在性能和功耗上均不占优势,且成本十分昂贵,工作频率高达2~3GHz,而相比之下,人脑工作频率仅为几赫兹,而且并行且分布式的人脑结构与连续且集中式的冯诺依曼架构显然大大不同,且分立的内存与处理器之间出现了数据带宽瓶颈,因此这种实现方式并非有效而经济的。另一种深度学习的方法就是采用GPU(图形处理器)来加速GPU出色的浮点计算性能,深度学习需要很高的内在并行度、大量的浮点计算能力以及矩阵预算,而GPU可以提供这些能力,并且在相同的精度下,拥有更快的处理速度、更少的服务器投入和更低的功耗。但是GPU成本高、能耗大,且主要性能瓶颈在于PCIE(外设部件互联标准)带宽对于数据传输的限制。
人类大脑的神经元尽管传导信号的速度很慢,但是却拥有庞大的数量,而且每个神经元都通过成千上万个突触与其他神经元相连,形成超级庞大的神经元回路,以分布式和并发式的方式传导信号,从而弥补了单神经元处理速度的不足。IBM主导的SyNAPSE巨型神经网络芯片,在70毫瓦的功率上提供100万个“神经元”内核、2.56亿个“突触”内核以及4096个“神经突触”内核,甚至允许神经网络和机器学习负载能力超越了冯·诺依曼架构。可见,采用深度定制的人工神经网络专属芯片无论是在集成度、功耗和机器学习负载上都具备明显优势。但是这种晶片采用的是易失性的SRAM(Static Random Access Memory,静态随机存取存储器)作为数据存储,虽然SRAM读写速度极快,但是大脑神经网络并不需要极高的处理速度,而更高的存储密度以及并行性才是优先考虑的。而且其占用芯片面积和功耗都非常大,且掉电后数据将全部丢失,不可恢复,也就是在掉电之前必须要将SRAM中大脑学习的数据保存至额外的非易失存储器中,耗电又耗时。传统的用软件实现方式来模拟实现神经元和突触,在功耗和性能上都不占优势(需要开启能耗高的CPU或者GPU),而且在模拟复杂的大脑皮质行为模型和神经元结构时的可伸缩性、灵活性方面都较差。
技术实现要素:
针对目前通过软件实现神经网络加速器但存在灵活性差,通过硬件实现但是存在数据存储带宽受限制,掉电后数据容易丢失的问题,本发明提供一种实现神经网络加速器以及神经网络模型的方法。
本发明解决技术问题所采用的技术方案为:
一种神经网络加速器的实现方法,包括非易失性存储器,所述非易失性存储器包括在后道制造工艺流程中制备的数据存储阵列,
在制备所述数据存储阵列的前道制造工艺流程中,在所述数据存储阵列下方的硅衬底上制备神经网络加速器电路。
优选地,还包括在制备所述数据存储阵列的前道制造工艺流程中,在所述数据存储阵列下方的硅衬底上制备外围逻辑电路。
优选地,所述神经网络加速器电路用于执行数学运算、数组运算、矩阵运算、状态操作、检查点操作或序列和同步操作。
优选地,所述神经网络加速器电路还包括晶体管逻辑电路,用于实现反馈型神经网络。
优选地,所述反馈型神经网络包括Elman网络和Hopfield网络。
优选地,所述非易失性存储器为3D NAND存储器或3D相变存储器。
优选地,所述数据存储单元为垂直堆叠的多层数据存储单元。
一种神经网络模型的实现方法,包括上述所述的权利要求,所述神经网络模型包括从其他神经元X1~Xn传过来的输入信号、从神经元j到神经元i的连接权信号Wij(j=1~n)、偏置、激活函数、运算函数和输出信号,
所述激活函数和运算函数通过所述神经网络加速器电路实现;
所述输入信号、连接权值、偏置和输出信号保存至所述非易失性存储器的数据存储阵列中。
优选地,对所述输入信号、连接权信号、偏置、激活函数、运算函数进行公式运算或逻辑运算,所述公式运算或逻辑运算通过所述神经网络加速器电路实现。
本发明的有益效果:本发明采用3D非易失性存储器来存储大脑神经元深度学习的结果,极大的满足成万上亿个神经元和突触在深度学习过程中对存储容量的需求,而且直接在3D数据存储阵列的下方实现神经网络加速器电路,使得数据存储带宽不受限制,并且掉电后数据依然不丢失,是一种低功耗、低成本、高性能的实现方法。还能通过该神经网络加速器电路和数据存储阵列实现神经网络模型,极大地降低了对内存的消耗,提高了性能。
附图说明
图1为现有技术中一种神经元示意图;
图2a为本发明的非易失性存储器结构的立体示意图;
图2b为本发明的非易失性存储器结构的截面示意图;
图3为M-P模型的神经网络模型;
图4为本发明的实现图3的一种神经网络模型的实现方法示意图;
图5为本发明的对输入信号进行微分运算的一种神经网络模型的实现方法示意图;
图6为本发明的对输入信号进行积分运算的一种神经网络模型的实现方法示意图;
图7为Hopfield神经网络示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
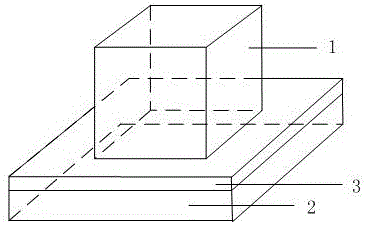
本发明提出一种基于非易失性存储器的一种神经网络加速器的实现方法。非易失性存储器采用非平面设计,在垂直方向上采用后道制造工艺流程(BEOL)堆叠多层数据存储单元以获得更高的存储密度,在更小的空间内容纳更高存储容量,进而带来很大的成本节约、能耗降低,例如3D NAND存储器和3D相变存储器。在这些3D数据存储阵列1下方是采用前道制造工艺流程(FEOL)制备的存储器的外围逻辑电路。随着存储器芯片容量的不断提高,数据存储阵列1容量越来越大,而相应的外围逻辑电路面积却增加不大,因而会空出很多额外的面积。本发明的一种神经网络加速器的实现方法,如图2a和2b所示,是基于3D非易失性存储器工艺,在前道制作工艺流程中在数据存储阵列1的下方制备神经网络加速器电路3,也就是在存储器的硅衬底2上的外围逻辑电路旁的空白区域制备神经网络加速器电路3,也就是神经网络加速器。神经网络加速器就是用硬件电路来实现所有的神经元和突触,而存储器用作存储输入和输出数据。
所述的神经网络加速器电路3能够实现多种公式的运算及操作,具体有:元素级的数学运算:比如加法、减法、乘法、除法、指数运算、对数运算、积分运算、微分运算、大于、小于以及等于运算等;数组运算,比如数组合并、数组切片、数组分解、数组排序数组变形及数组洗牌等;矩阵运算,比如矩阵乘法、矩阵反转及矩阵行列式等;状态操作,比如赋值;神经网络构建模块;比如检查点操作,保存和恢复;序列和同步操作,比如入队、出队等;控制流操作等。
本发明还基于上述的神经网络加速器提出一种神经网络模型的实现方法。一种称为M-P模型(McCulloch-Pitts Model)的神经网络模型如图3所示,采用矩阵相乘和加法运算实现,X1~Xn是从其他神经元传来的输入信号,Wij(j=1~n)表示从神经元j到神经元i的连接权值,b代表偏置。那么神经元i的输出与输入的关系表示为:
yi=f(neti)
图中yi表示神经元i的输出,函数f称为激活函数或转移函数,net称为净激活。若神经元的净激活net为正,称该神经元处于激活状态或兴奋状态;若净激活net为负,则称神经元处于抑制状态。上述神经网络模型或者成为一个处理单元,显然可以通过软件来实现上述过程。但本发明采取硬件电路来实现,如图4所示,其中矩阵相乘运算、加法运算以及激活函数均可利用3D非易失性存储器数据存储阵列1下方的硅片空间并采用前道制作工艺流程制成的神经网络加速器的硬件电路来实现,而神经元i的数据输入信号X1~Xn、神经元之间的连接权值Wij(j=1~n)、偏置信号值b以及神经元的输出信号值yi均可以保存在3D非易失性存储器的数据存储阵列1中,不仅充分利用了3D非易失性存储器数据存储阵列1下方的空余硅片面积,而且使神经元网络能够获得极高的存储密度,大大节省了数据传输功耗。
进一步的,许多优化算法,包括常见的机器学习训练算法,比如随机微分下降算法,需要对一系列输入信号进行微分或者积分运算,如图5和图6所示,这类运算如果用软件实现则非常消耗内存。微分和积分运算同样可以利用本发明的一种神经网络模型的实现方法来实现:对输入信号进行微分运算的神经网络模型,是基于神经网络加速器来实现,其中矩阵相乘的微分运算、加法的微分运算以及激活函数的微分运算均可利用神经网络加速器的硬件电路实现,而神经元的数据输入信号的微分值dy/dx、神经元之间连接权值的微分值dy/dW、偏置信号的微分值dy/db以及神经元的输出信号值t均可以保存在3D非易失性存储器的数据存储阵列1中。同理,对一系列输入信号进行高阶微分和高阶积分的神经网络模型也能够采用本发明的方法来实现。
反馈型神经网络是一种从输出到输入具有反馈连接的神经网络,其结构要比一般神经网络要复杂得多。典型的反馈型神经网络有:Elman网络和Hopfield网络。例如图7所示的是一个Hopfield网络,在图中,第0层仅仅是作为网络的输人,它不是实际神经元,所以无计算功能;而第一层是实际神经元,故而执行对输入信息和权系数乘积的累加和,并由非线性函数f处理后产生输出信息。f是一个简单的阀值函数,如果神经元的输出信息大于偏置b,那么,神经元的输出就取值为1;小于偏置b,则神经元的输出就取值为偏置b。显然该反馈网络也能够用本发明的实现神经网络模型的方法来实现,利用3D非易失性存储器数据存储阵列1下方的晶体管逻辑电路实现上述神经元网络模型。
本发明采用3D非易失性存储器用来存储神经元和突触的输入数据以及存储输出结果,大大提高了存储密度,降低成本,并且能够保证掉电后数据不丢失。相比之下,传统的用软件实现方式来模拟实现神经元和突触,在功耗和性能上都不占优势,可伸缩性、灵活性方面都较差。传统的神经网络硬件实现方式采用的是易失性的SRAM存储器,占用芯片面积和功耗都非常大,且掉电后数据丢失。本发明采用非易失性存储器来存储大脑神经元深度学习的结果,极大的满足成万上亿个神经元和突触在深度学习过程中对存储容量的需求,而且直接在数据存储阵列1的下方制备神经网络加速器,使得数据存储带宽不受限制,并且掉电后数据依然不丢失。因此本发明基于非易失性存储器工艺实现的神经网络加速器是一种低功耗、低成本、高性能的实现方法。
以上所述仅为本发明较佳的实施例,并非因此限制本发明的实施方式及保护范围,对于本领域技术人员而言,应当能够意识到凡运用本发明说明书及图示内容所做出的等同替换和显而易见的变化所得到的方案,均应当包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!