一种基于视频的实时检测行人的方法与流程
本发明涉及一种实时检测行人的方法,特别是涉及一种适用于基于视频的实时检测行人的方法。
背景技术:
行人检测就是检测视频或图片中是否包含行人并标出行人的正确位置,它是机器视觉领域的一个重要分支,在安防监控、人工智能、智能交通等领域都有着重要的应用。作为一项有着巨大应用前景的技术,目前已经有大量针对行人进行检测的方法,但由于现实中行人所在的背景复杂、行人衣着外表和姿势的巨大差异,以及遮挡等因素,复杂场景下高鲁棒性行人检测仍然面临巨大挑战。行人检测的另一个难题在于如何在保证检测结果准确的情况下,快速甚至实时地进行检测。在很多领域,如自动驾驶、监控等领域,不仅要求检测结果准确,而且要求能够实时地进行检测。
现有行人检测的方法非常多,但主要使用两种图像特征:运动信息和形状。前一种方法需要背景提取和图像分割等预处理技术,而基于形状特征的检测方法不需要使用预处理算法,该种方法根据特征的提取方法划分为全局特征法和局部特征法。全局特征和局部特征的区别在于全局特征从整个图像上来提取特征,而局部特征是从图像的局部区域来提取特征。全局特征的经典例子便是独立主成分法(PCA),它的缺点在于对物体的外表、姿势和光照敏感,而局部特征由于从图像的局部提取特征,对物体的外表、姿势和光照并不敏感。典型的局部特征有小波系数、梯度方向和局部协方差等。局部特征又可以进一步分为整体检测和部位检测,部位检测的检测结果是通过另外一个分类器将部位的检测结果组合成最终的行人检测结果。使用部位检测方法的优点是它能很好的应对由于行人肢体移动导致行人外表变化带来的问题,缺点是它令整个检测过程变得更加复杂。基于统计学习的方法是目前行人检测最常用且有效的方法,该方法通过大量训练样本构建行人检测分类器。提取的特征一般有目标的灰度、边缘、纹理、形状和梯度直方图等信息,分类器包括神经网络、SVM和Adaboost等。该方法存在以下难点:行人的姿态、服饰各不相同、提取的特征在特征空间中的分布不够紧凑、分类器的性能受训练样本的影响较大、离线训练时的负样本无法涵盖所有真实应用场景的情况。
传统的方法主要通过计算HOG特征来检测行人,但由于HOG的计算涉及三维线性插值等算法,计算复杂度较高,难以达到实时性要求。而最新的深度学习方法尽管可以达到很高的准确率,但由于模型复杂、依赖并行运算等原因,对硬件性能有极高的要求,无法在实际场合中使用。另外,在进行行人检测时,往往采用滑动窗口法,该方法由于需要检测大量的窗口,非常耗时。
技术实现要素:
本发明要解决的技术问题是提供一种快速有效,特征简单鲁棒,能很好地满足不同场景下的实时性要求的基于视频的实时检测行人的方法。
本发明采用的技术方案如下:一种基于视频的实时检测行人的方法,包括训练阶段和检测阶段;其特征在于:在检测阶段,利用标定过的双目摄像头采集视频,计算每帧图像的视差图;利用视差图将图像分为背景区域和非背景区域;利用上一帧检测结果来确定当前帧需要检测的候选区域,将同时满足既为非背景区域又为候选区域这两个条件的区域作为需要检测区域,后续过程只检测需要检测区域。
在需要检测区域用提前训练好的分类器系数来进行判定是否为行人。
所述方法还包括,在检测阶段,为了避免特征的重复计算,一开始先计算出图像中需要检测区域每个4x4窗口里的特征值,当窗口滑动到特定位置时,只需提取并组和对应窗口里的特征,而不需要再次计算,这样成功地避免了窗口滑动过程中对交叠区域特征的重复计算,在不牺牲检测准确率情况下提升了检测的速度。
所述方法还包括,提前判断负样本减少检测时间,具体方法为:提取每一帧图像需要检测区域的组合特征,及利用Adaboost的级联特性提前判断负样本减少检测时间;所述组合特征由YUV颜色通道特征、6个梯度方向特征、Canny特征和梯度幅值特征组成的组合特征,从而来达到实时检测的目的。
所述组合特征中所有特征的计算均以一个4×4不重叠且相邻的块为基本单位。
所述方法还包括,为了提升检测结果的鲁棒性,将当前帧检测结果与上一帧检测结果进行对比,对于两帧中相差很小的检测框,将当前帧的检测结果更新为上一帧对应的检测结果,从而减少需要检测的区域。
所述方法还包括,对于已经在前几帧连续出现至少两次的检测框,如果当前帧的检测结果中没有该检测框,并且在当前帧对应该检测框位置周围不存在其它的检测框,则在当前帧检测结果中添加该检测框,这样避免了噪声对检测框位置带来的干扰,提升检测结果的稳定性并降低了漏检率。
所述方法还包括,在训练阶段,采集包含行人和不包含行人的图片作为样本,利用Adaboost分类器来进行训练;为了减少检测阶段特征的计算次数,训练多个不同尺度的分类器,使得检测时只需要用不同尺度的窗口在图像上滑动,而不需要将图像缩放后重新计算特征,这样通过将检测阶段的计算转移到训练阶段大大较少了特征的计算次数,加快了检测速度。
所述方法还包括:训练过程中使用特征为由YUV颜色通道特征、6个梯度方向特征、Canny特征和梯度幅值特征组成的组合特征。
所述方法还包括,提取不重叠相邻的4×4窗口里的由YUV颜色通道特征、6个梯度方向特征、Canny特征和梯度幅值特征组成的组合特征,进行特征点的计算,从而简化特征点的计算。
所述方法还包括,为了减少分类器判定时间,在Adaboost分类器的每个弱分类器处设定一个阈值,每个弱分类器和之前所有的弱分类器的判定结果之和都与该阈值进行比较,小于该阈值则认为是负样本并提前退出,这样通过提前排除部分错误正样本加快了检测速度。
与现有技术相比,本发明的有益效果是:能够快速准确检测行人的特征,并且利用视差图和帧间信息减少了待检测区域;在Adaboost分类器每个弱分类器处设定阈值来减少判定阈值;利用帧间信息提升检测结果的鲁棒性。相比传统的HOG等方法,方法复杂度更低、速度更快,能够满足实时准确检测要求。
进一步地,能够实时有效地检测行人,且能达到一个较精确的检测结果。使用由YUV颜色通道特征、6个梯度方向特征、Canny特征和梯度幅值特征组成的组合特征来作为特征;训练多个尺度分类器和提前计算出特征来减少特征的计算来加快检测速度;利用Adaboost的级联特性提前判断负样本减少检测时间。该方法简单有效,复杂度低,能够满足实时准确检测要求。
附图说明
图1为本发明其中一实施例训练阶段的方法流程示意图。
图2为图1所示实施例中检测阶段的方法流程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
本说明书(包括摘要和附图)中公开的任一特征,除非特别叙述,均可被其他等效或者具有类似目的的替代特征加以替换。即,除非特别叙述,每个特征只是一系列等效或类似特征中的一个例子而已。
具体实施例1
一种基于视频的实时检测行人的方法,包括训练阶段和检测阶段;在检测阶段,利用标定过的双目摄像头采集视频,计算每帧图像的视差图;利用视差图将图像分为背景区域和非背景区域;利用上一帧检测结果来确定当前帧需要检测的候选区域,将同时满足既为非背景区域又为候选区域这两个条件的区域作为需要检测区域,后续过程只检测需要检测区域。
在需要检测区域用提前训练好的分类器系数来进行判定是否为行人。
具体实施例2
在具体实施例1的基础上,所述方法还包括,在检测阶段,为了避免特征的重复计算,一开始先计算出图像中需要检测区域每个4x4窗口里的特征值,当窗口滑动到特定位置时,只需提取并组和对应窗口里的特征,而不需要再次计算,这样成功地避免了窗口滑动过程中对交叠区域特征的重复计算,在不牺牲检测准确率情况下提升了检测的速度。
具体实施例3
在具体实施例1或2的基础上,所述方法还包括,提前判断负样本减少检测时间,具体方法为:提取每一帧图像需要检测区域的组合特征,及利用Adaboost的级联特性提前判断负样本减少检测时间;所述组合特征由YUV颜色通道特征、6个梯度方向特征、Canny特征和梯度幅值特征组成的组合特征,从而来达到实时检测的目的。
具体实施例4
在具体实施例1到3之一的基础上,所述组合特征中所有特征的计算均以一个4×4不重叠且相邻的块为基本单位。
具体实施例5
在具体实施例1到4之一的基础上,所述方法还包括,为了提升检测结果的鲁棒性,将当前帧检测结果与上一帧检测结果进行对比,对于两帧中相差很小的检测框,将当前帧的检测结果更新为上一帧对应的检测结果,从而减少需要检测的区域。
具体实施例6
在具体实施例1到5之一的基础上,所述方法还包括,对于已经在前几帧连续出现至少两次的检测框,如果当前帧的检测结果中没有该检测框,并且在当前帧对应该检测框位置周围不存在其它的检测框,则在当前帧检测结果中添加该检测框,这样避免了噪声对检测框位置带来的干扰,提升检测结果的稳定性并降低了漏检率。
具体实施例7
在具体实施例1到6之一的基础上,所述方法还包括,在训练阶段,采集包含行人和不包含行人的图片作为样本,利用Adaboost分类器来进行训练;为了减少检测阶段特征的计算次数,训练多个不同尺度的分类器,使得检测时只需要用不同尺度的窗口在图像上滑动,而不需要将图像缩放后重新计算特征,这样通过将检测阶段的计算转移到训练阶段大大较少了特征的计算次数,加快了检测速度。
具体实施例8
在具体实施例1到7之一的基础上,所述方法还包括:训练过程中使用特征为由YUV颜色通道特征、6个梯度方向特征、Canny特征和梯度幅值特征组成的组合特征。
具体实施例9
在具体实施例1到8之一的基础上,所述方法还包括,提取不重叠相邻的4×4窗口里的由YUV颜色通道特征、6个梯度方向特征、Canny特征和梯度幅值特征组成的组合特征,进行特征点的计算,从而简化特征点的计算。
具体实施例10
在具体实施例1到9之一的基础上,所述方法还包括,为了减少分类器判定时间,在Adaboost分类器的每个弱分类器处设定一个阈值,每个弱分类器和之前所有的弱分类器的判定结果之和都与该阈值进行比较,小于该阈值则认为是负样本并提前退出,这样通过提前排除部分错误正样本加快了检测速度。
具体实施例11
如图1所示,在训练阶段,分为以下四个步骤:
步骤一:采集包含行人和不包含行人的图片作为样本,利用Adaboost分类器来进行训练。在本具体实施例中,以INRIA行人数据库为例,首先从不包含行人的图片中随机选取5000个尺寸为64×128的负样本,和样本库中的2416个正样本一起作为训练样本。利用128个弱分类器对这些样本进行训练来得到检测参数;训练过程中所使用的特征为由YUV颜色通道特征、6个梯度方向特征、Canny特征和梯度幅值特征组成的组合特征,所有特征的计算均以一个4×4不重叠且相邻的块为基本单位。一个4×4块内的特征值计算方法如下:
对于6个梯度方向特征,计算公式如下:
其中,θi为量化的梯度方向,其值为i,G(x,y)为梯度幅值,R(x,y)为梯度方向的弧度值,取值范围为0到π,Θ(x,y)为梯度方向的量化值,为对应梯度方向的值。梯度的计算采用[-1 0 1]和[-1 0 1]T算子,分别在YUV三个通道上计算梯度,取梯度幅值最大的为最终的梯度幅值和梯度方向。统计4×4块内所有6个不同方向的值的和,并求均值来得到各个方向相应的特征值,最后串联即得到一个4×4块内6个梯度方向特征Fg。
梯度幅值特征Fm为4×4块中梯度幅值的均值。
YUV颜色通道特征为分别统计4×4块Y通道特征中像素值的均值,以及4×4块中Y分量对应的UV分量的均值,以YUV420格式(每四个Y共用一组UV分量)为例,一个4×4块Y通道特征为块中Y分量值的均值,U通道特征为块中Y共用的4个U分量的均值,V通道特征为块中Y共用的4个V分量的均值。YUV颜色通道的特征Fc为将三个通道上的特征串联起来:
Fc=[Fy Fu Fv] (4)
其中Fy为Y通道特征,Fu为U通道特征,Fv为V通道特征
Canny特征Fn为计算一副图像的Canny边缘,然后统计每个4×4块所有值的和
最终一个4×4块内的特征F为:
F=[Fg Fm Fc Fn] (5)
一个样本的特征为将每个4×4不重叠且相邻的块的特征串联起来。
步骤二:使用步骤一训练得到的检测参数在500个不包含行人的图片中提取难例(难例是错检的窗口,即将不是行人的窗口检测为行人),如果难例个数多于10000,则随机选取10000个,如果不足,则从上一阶段的负样本中随机选取不足的个数,最终所得10000个样本作为负样本和2416个正样本一起作为训练样本,利用512个弱分类器对训练样本进行训练。
步骤三:使用步骤二训练得到的检测参数在1218个不包含行人的图片中提取难例,如果难例个数多于10000,则随机选取10000个,如果不足,则从上一阶段的负样本中随机选取不足的个数,最终所得10000个样本作为负样本和2416个正样本一起作为训练样本,利用2048个弱分类器对训练样本进行训练。
步骤四:将样本的尺寸缩放为72×144、76×152,再通过步骤一、二、三获得针对样本尺寸为72×144和76×152的检测参数。
步骤五:在每个弱分类器处设定一个相同的阈值-1,后续检测过程中只要该弱分类器和之前的弱分类器的判定结果之和小于该阈值,则直接判定为负样本并提前退出,不进行后续弱分类器的判定。
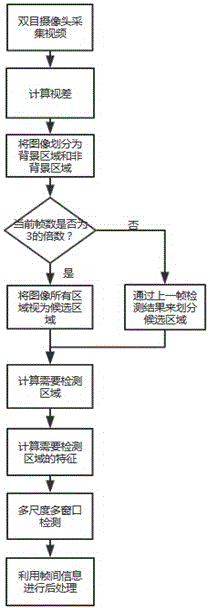
如图2所示,通过训练得到检测参数后,就可进行行人检测。检测过程通过多尺度多窗口来进行检测,检测部分主要分为以下七个步骤:
步骤一:一开始先通过求对应块差值的平方和的块匹配算法来计算图像的视差信息,对计算得到的视差图进行二值化处理,然后用64×128的窗口在二值化后的图上以滑动,行列步进均为16,如果窗口里值为1的像素点所占比例大于1/2,则窗口对应区域为非背景区域,取所有满足上述条件的窗口对应区域的并集即为整个图片的非背景区域。
步骤二:如果当前帧数不是3的倍数时,则利用上一帧检测结果来确定当前帧需要检测的候选区域,候选区域的选择方法为,选取上一帧包括检测框和周围一定范围内的区域来作为检测候选区域。同时满足为非背景区域和候选区域的区域作为需要检测区域,后续过程只检测需要检测区域。如果当前帧数是3的倍数,则非背景区域即为需要检测区域,不利用上一帧信息来计算候选区域
步骤三:计算需要检测区域的特征值,特征的计算方法和训练阶段步骤一的计算方法一致。
步骤四:用尺寸为64×128的窗口在需要检测区域滑动,且行列步进均为8,并利用对应的检测参数来判断窗口中是否包含行人。
步骤五:将窗口尺寸改为72×144、76×152,重复步骤四。
步骤六:将图像以1.33进行上采样和下采样多次,下采样后的图像尺寸必须大于76×152,上采样后的图像根据实际需要进行限定。每次得到采样后的图像后再重复步骤一、二、三、四、五。
步骤七:将得到的判定为行人的窗口进行非极大值抑制后得到初步的检测结果,然后将当前帧检测结果与上一帧检测结果进行对比,对于两帧中相差很小的检测框,将当前帧的检测结果更新为上一帧对应的检测结果;对于已经在前几帧连续出现多次的检测框,如果当前帧的检测结果中没有该检测框并且在当前帧对应该检测框位置周围不存在其它的检测框,则在该帧检测结果中添加该检测框。
具体实施例12
一种基于视频的实时检测行人的方法,包括训练阶段和检测阶段;在检测阶段,为了避免特征的重复计算,一开始先计算出图像中需要检测区域每个4x4窗口里的特征值,当窗口滑动到特定位置时,只需提取并组和对应窗口里的特征,而不需要再次计算,这样成功地避免了窗口滑动过程中对交叠区域特征的重复计算,在不牺牲检测准确率情况下提升了检测的速度。
具体实施例13
一种基于视频的实时检测行人的方法,包括训练阶段和检测阶段;在检测阶段,提前判断负样本减少检测时间,具体方法为:提取每一帧图像需要检测区域的组合特征,及利用Adaboost的级联特性提前判断负样本减少检测时间;所述组合特征由YUV颜色通道特征、6个梯度方向特征、Canny特征和梯度幅值特征组成的组合特征,从而来达到实时检测的目的。
具体实施例14
在具体实施例13的基础上,所述组合特征中所有特征的计算均以一个4×4不重叠且相邻的块为基本单位。
具体实施例15
一种基于视频的实时检测行人的方法,包括训练阶段和检测阶段;在检测阶段,为了提升检测结果的鲁棒性,将当前帧检测结果与上一帧检测结果进行对比,对于两帧中相差很小的检测框,将当前帧的检测结果更新为上一帧对应的检测结果,从而减少需要检测的区域。
具体实施例16
一种基于视频的实时检测行人的方法,包括训练阶段和检测阶段;在检测阶段,对于已经在前几帧连续出现至少两次的检测框,如果当前帧的检测结果中没有该检测框,并且在当前帧对应该检测框位置周围不存在其它的检测框,则在当前帧检测结果中添加该检测框,这样避免了噪声对检测框位置带来的干扰,提升检测结果的稳定性并降低了漏检率。
具体实施例17
一种基于视频的实时检测行人的方法,包括训练阶段和检测阶段;在训练阶段,采集包含行人和不包含行人的图片作为样本,利用Adaboost分类器来进行训练;为了减少检测阶段特征的计算次数,训练多个不同尺度的分类器,使得检测时只需要用不同尺度的窗口在图像上滑动,而不需要将图像缩放后重新计算特征,这样通过将检测阶段的计算转移到训练阶段大大较少了特征的计算次数,加快了检测速度。
具体实施例18
一种基于视频的实时检测行人的方法,包括训练阶段和检测阶段;在训练阶段,训练过程中使用特征为由YUV颜色通道特征、6个梯度方向特征、Canny特征和梯度幅值特征组成的组合特征。
具体实施例19
一种基于视频的实时检测行人的方法,包括训练阶段和检测阶段;在训练阶段,提取不重叠相邻的4×4窗口里的由YUV颜色通道特征、6个梯度方向特征、Canny特征和梯度幅值特征组成的组合特征,进行特征点的计算,从而简化特征点的计算。
具体实施例20
一种基于视频的实时检测行人的方法,包括训练阶段和检测阶段;在训练阶段,为了减少分类器判定时间,在Adaboost分类器的每个弱分类器处设定一个阈值,每个弱分类器和之前所有的弱分类器的判定结果之和都与该阈值进行比较,小于该阈值则认为是负样本并提前退出,这样通过提前排除部分错误正样本加快了检测速度。
- 还没有人留言评论。精彩留言会获得点赞!