一种历史平均值管理系统及管理方法与流程
本发明涉及一种数据平均值处理技术,尤其是涉及一种历史平均值管理系统及管理方法。
背景技术:
传统的工业控制系统平均值计算查询系统中,数据存入在关系数据库,由于一个位号光分钟平均值一天就要存储1440条数据,当位号总数过万时,每天增加一千多万条数据。数据越多对查询速度影响越大,所以在这种情况下,往往每隔一段时间就会清除部分数据,这样保存的数据有限,并且直接导致查询的时间段有一定的限制。
技术实现要素:
本发明主要是解决现有技术中平均值查询系统的查询速度慢,且每隔一段时间需要清除部分数据,数据保存有限的问题,提供了一种优化存储结构,查询速度恒定,数据存储量大的历史平均值管理系统及管理方法。
本发明的上述技术问题主要是通过下述技术方案得以解决的:一种历史平均值管理系统,包括客户端和服务器端,所述客户端包括数据查询请求单元,所述服务器端包括数据查询单元、数据源、数据采集单元、环状数据缓冲单元、平均值处理单元、平均值文件单元,数据源、数据采集单元、环状数据缓冲单元、平均值处理单元、平均值文件单元顺序连接,所述数据查询单元分别与环状数据缓冲单元、平均值文件单元相连接,所述数据查询请求单元通过网络与数据查询单元相连接。本发明中数据采集单元对数据源各类型参数的实时变化数据进行采集,即对每秒的瞬时值进行采集;环状数据缓冲单元接收数据采集单元发送来的数据,通过环形保存方式,不间断的进行数据存入,同时通过平均值处理单元进行分钟平均值计算和存储,另外还同时将平均值数据写入平均值文件单元里;平均值处理单元对环状缓冲单元内数据进行分钟平均值计算,以及对平均值文件单元内数据进行小时平均值计算,并控制环状缓冲单元每隔一段时间将数据写入平均值文件单元内;平均值文件单元包括若干平均值文件,每个平均值文件按照设定的数据存储结构存储一个时间区间内的数据,一般以24小时为一个时间区间,计算的分钟平均值数据、小时平均值数据。本发明将数据根据时间区分存入若干平均值文件内,每个文件都具有便于检索的存储结构,这使得用户能够快速进行查询,减少了平均值查询花费时间,在足够大硬盘支持下,可以查询更长的区间数据,解决了传统查询系统中因存储数据增加,影响查询速度,需要每隔一段时间删除部分数据,保存数据有限的问题。本发明通过平均值文件以设定存储结构进行存储数据,使得能保存更长时间的数据平均值,并且查询复杂度恒定,查询时间不会因为时间越久而速度越慢。
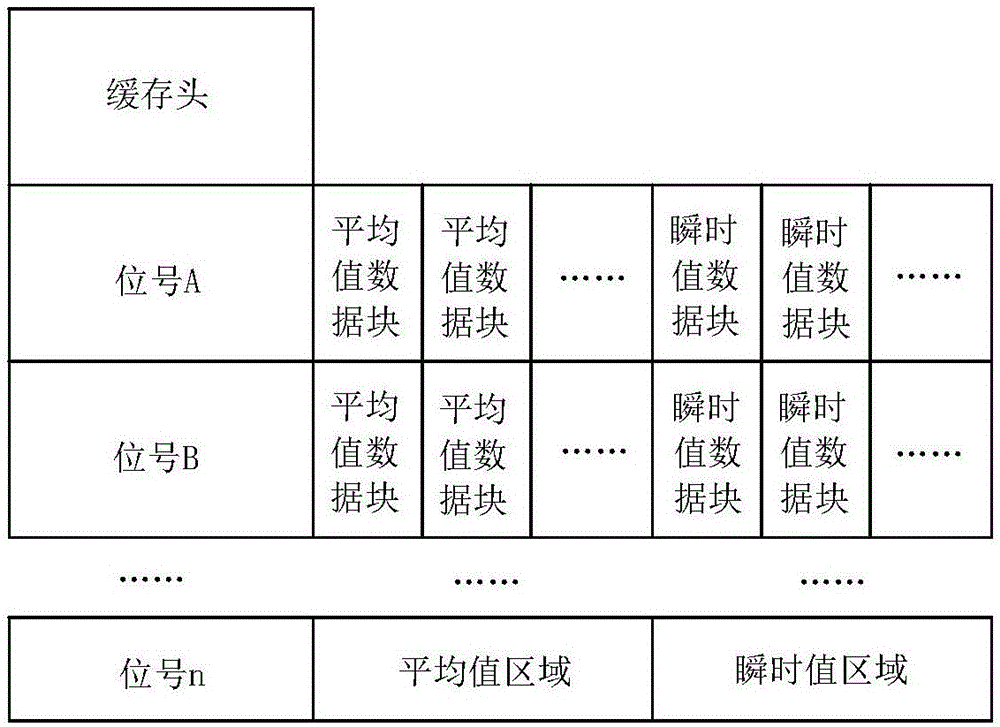
作为一种优选方案,所述环状数据缓冲单元的存储结构包括缓存头、位号头、若干平均值数据块和若干瞬时值数据块,若干平均值数据块和若干瞬时值数据块分别都以循环读写方式呈环形分布;
缓存头:保存所有位号总数和最近一次读取缓存中平均值数据块的时间;
位号头:保存位号名称,位号瞬时值的读指针、写指针,位号平均值的读指针、写指针;每个位号对应一种类型参数的名称。
平均值数据块:保存分钟平均值和分钟时间;分钟时间将去掉秒的数字,只保留年、月、日、时和分。平均值以循环的方式在平均值数据块上进行写入与读取,平均值记录区间的长度可以根据具体要求做相应的增加和删除。
瞬时值数据块:保存瞬时值和写入的时间。瞬时值以循环的方式在平均值数据块上进行写入与读取。
作为一种优选方案,所述平均值文件单元包括若干平均值文件,平均值文件的存储结构包括历史文件头、一级索引、若干二级索引和若干数据块;
历史文件头:保存文件标示、文件版本、字节序、开始时间、结束时间和位号总数;文件标示记录一个特定字符串,标示此文件为平均值文件;文件版本主要区分当文件数据块等长度有变化时,可以应对不同的方法进行处理;字节序主要是区分服务器端上多字节数据保存时,高位和低位的存储位置,一般写入一个32位的int整数,每次取值时可以根据原先数据与写入数据来比较区分字节序是否一致,如果不一致可以不处理,或者用字节序转换的方式进行处理,在当字节序一致时,跳过对该文件字节序转换的步骤;开始时间和结束时间记录文件创建时间和最后一个数据写入的时间;位号总数是填写文件中记录位号的个数。
一级索引:结构包括若干位号头,每个对应的位号头保存位号名称和二级索引地址;
二级索引:结构包括顺序排列的索引头、上一块二级索引地址、下一块二级索引地址、若干小时平均值结构体和若干数据块地址结构体;索引头保存每个位号对应的一级索引地址,上一块二级索引地址保存与位号上方相邻的二级索引地址,下一块二级索引地址保存与位号下方相邻的二级索引地址,小时平均值结构体保存小时时段和小时平均值,数据块地址结构体保存分钟段开始时间、分钟段结束时间和对应数据块地址;每个二级索引长度是固定的,一级索引所要填写的二级索引地址就根据第一个二级索引开始地址逐个加上二级索引的长度就能得出。数据块地址结构体中的数据地址,由每个数据块的总长度计算而来。
数据块:结构包括顺序排列的数据块索引头、若干分钟平均值结构体;数据索引头保存对应二级索引地址,分钟平均值结构体保存分钟段时间和平均值。数据块只需保存一个二级索引地址。
一种历史平均值管理系统管理方法,包括平均值存储步骤和数据查询步骤,
平均值存储步骤包括以下步骤:
SS1.定义环状数据缓冲单元和平均值文件单元的存储结构;
SS2.通过计时,计算环状数据缓冲单元内所有位号一分钟平均值并进行存储;
SS3.通过计时,相隔设定分钟,将该时间段内所有分钟平均值写入对应平均值文件;
SS4.在当前平均值文件将其所有分钟平均值写完毕后,计算小时平均值并关闭文件,返回步骤SS2;
数据查询步骤包括以下步骤:
SI1.分析查询请求,确定查询时间区间、查询类型;
SI2. 查询类型为分钟平均值,根据查询时间区间对应从环状数据缓冲单元、平均值文件查询分钟平均值,进入步骤SI5;
SI3.查询类型为小时平均值,从平均值文件查询小时平均值,进入步骤SI5;
SI4.查询类型为天、月或年平均值,根据小时平均值整理出数据;
SI5.将查询的数据返回数据给客户端。
作为一种优选方案,步骤SS1中定义环状数据缓冲单元的存储结构为:
包括缓存头、位号头、若干平均值数据块和若干瞬时值数据块,若干平均值数据块和若干瞬时值数据块分别都以循环读写方式呈环形分布;
缓存头:保存有位号总数和最近一次读取环状数据缓冲单元中平均值数据块的时间;
位号头:保存位号名称,位号瞬时值的读指针、写指针,位号平均值的读指针、写指针;
平均值数据块:保存分钟平均值和分钟时间;
瞬时值数据块:保存瞬时值和写入的时间;
定义平均值文件单元的存储结构为:
包括若干平均值文件,平均值文件的存储结构包括历史文件头、一级索引、若干二级索引和若干数据块;
历史文件头:保存文件标示、文件版本、字节序、开始时间、结束时间和位号总数;
一级索引:结构包括若干位号头,每个对应的位号头保存位号名称和二级索引地址;
二级索引:结构包括顺序排列的索引头、上一块二级索引地址、下一块二级索引地址、若干小时平均值结构体和若干数据块地址结构体;索引头保存每个位号对应的一级索引地址,上一块二级索引地址保存与位号上方相邻的二级索引地址,下一块二级索引地址保存与位号下方相邻的二级索引地址,小时平均值结构体保存小时时段和小时平均值,数据块地址结构体保存分钟段开始时间、分钟段结束时间和对应数据块地址;
数据块:结构包括顺序排列的数据块索引头、若干分钟平均值结构体;数据索引头保存对应二级索引地址,分钟平均值结构体保存分钟段时间和平均值。
作为一种优选方案,步骤SS2的具体过程为:
计时操作为开启定时器,每秒触发一次,服务器端判断当前时间离上一次计算分钟平均值的时间是否超过一分钟,若否进入步骤SS3,若是则进行所有位号的分钟平均值计算,将计算的分钟平均值写入环状数据单元指定位置内,其中分钟平均值计算过程为:
获取环状数据缓冲单元中对应的瞬时值读指针,从读指针开始找到指定分钟前的一个瞬时值,以及指定分钟时间段内所有瞬时值,从指定分钟的第1秒开始,判断当前秒是否有瞬时值,若有则继续往下一秒执行,若无则用当前秒前的瞬时值作为当前秒瞬时值,如此操作直至补齐整个60秒内的瞬时值,最后对60个瞬时值取平均值得到分钟平均值。这里的时间都会做归零处理,也就是将多余的秒数去掉,如xx年xx月xx日18点20分12秒,归零后变成xx年xx月xx日18点20分0秒。本方案通过对数据补点来计算出分钟平均值。
作为一种优选方案,步骤SS3的具体过程为:
SS31.判断当前平均值文件是否写满,若否进入下一步骤,若是则新建一个平均值文件;
SS32.服务器端将当前时间与上一次写设定分钟平均值的时间进行比较,判断是否超过设定分钟,若否返回步骤SS2,若是则获取环状数据缓冲区平均值读取指针,从平均值读取指针开始往后找,获取设定分钟内所有的分钟平均值,写入平均值文件。平均值文件写的过程为,通过位号在一级索引中找到二级索引的位置,将之前记录的写文件次数作为偏移量(这里写文件次数根据设定多少分钟进行一次写入平均值文件有关,例如每10分钟写入一次,则将一天时间分成1440/10份,在平均值文件内,每次保存当前写入的是第几个10分钟),找到该位号的数据块所在位置,然后将10分钟的平均值分别写入对应数据块中,最后将写文件次数增一,方便下次写入时找到正确的偏移位置。
作为一种优选方案,步骤SS4的具体过程为:
在当前平均值文件将将设定分钟时间段分钟平均值写完毕后,判断平均值文件记录的写文件次数是否达到设定次数,若否返回步骤SS2,若是则计算整个平均值文件中所有时段的小时平均值,并将计算后的值写入对应位置,关闭文件,返回步骤SS2。本方案中依照前面以每10分钟写入一次例子,平均值文件以一天为存储区间,则平均值文件需写入144次。计算小时平均值为最后一个步骤,写完就要关闭平均值文件。
作为一种优选方案,数据查询步骤具体为:
在步骤SI1中,查询请求包括查询位号、查询类型、查询的起始时间以及结束时间,查询类型包括分钟平均值、小时平均值、天平均值、月平均值和年平均值;根据查询类型、查询的起始时间以及结束时间,当查询分钟平均值时,剔除当前时间所在分钟,当查询小时平均值时,剔除当前时间所在小时,以此类推;对查询类型进行判断,是否为分钟平均值、小时平均值、天平均值、月平均值或年平均值;本方案用于剔除无法完整计算的平均值时段,以确定查询时间区间。同时对查询类型进行判断。
在步骤SI2中,判断查询分钟平均值时间区间的时间是否都大于环状数据缓冲单元最后一次记录的写入平均值文件的时间,若是从环状数据缓冲单元中查询分钟平均值,若否再判断分钟平均值时间区间是否有部分时间大于环状数据缓冲单元最后一次记录的写入平均值文件的时间,若有则部分时间从环状数据缓冲单元中查询分钟平均值,时间区间其余部分时间从平均值文件中查询分钟平均值;若没有则直接从平均值文件查询分钟平均值;本方案中从环状数据缓冲单元中查询分钟平均值的方法与写入平均值文件时读取分钟平均值一样。平均值文件内查询分钟平均值时,在二级索引中通过数据块地址结构体进行对开始时间和结束时间的时间匹配,找出所有匹配的数据块。
在步骤SI3中,判断查询小时平均值时间区间对应的小时平均值结构体内数据是否为空,若否从平均值文件中查询小时平均值,若是则计算小时平均值,然后再判断小时平均值区间内是否有一个小时跨越两个平均值文件,若无进入步骤SI5,若有则对该跨越小时的平均值进行重新计算,跨越小时平均值=(W*V1+U*V2)/60 ,其中W为跨越小时前一个小时的小时平均值,U为跨越小时后一个小时的小时平均值,V1为前一个平均值文件结束时间的分钟值,V2为后一个平均值文件开始时间的分钟值;跨越小时平均值根据文件头结构体中的开始时间和结束时间,按比例进行平均值计算。将一小时进行60等分即以分钟为单元,V1+V2=60。例如上一个文件时15:50结束,则V1为50,下一个文件是15:50开始,V2=60-V1=10。
在步骤IS4中,查询类型为天、月或年平均值,根据步骤IS3查询时间区间内小时平均值,根据小时平均值计算出天、月或年平均值,返回数据给客户端。查询天以上的平均值时,需要根据小时平均值计算出天平均值,以此类推计算出相关的平均值。
因此,本发明的优点是:将数据根据时间区分存入若干平均值文件内,每个文件都具有便于检索的存储结构,这使得用户能够快速进行查询,减少了平均值查询花费时间,在足够大硬盘支持下,可以查询更长的区间数据,解决了传统查询系统中因存储数据增加,影响查询速度,需要每隔一段时间删除部分数据,保存数据有限的问题。本发明通过平均值文件以设定存储结构进行存储数据,使得能保存更长时间的数据平均值,并且查询复杂度恒定,查询时间不会因为时间越久而速度越慢。
附图说明
附图1是本发明的一种结构框示图;
附图2是本发明中环状数据缓冲单元的一种存储结构示意图;
附图3是本发明中平均值文件的一种存储结构示意图;
附图4是本发明中平均值存储步骤示意图;
附图5是本发明中数据查询步骤示意图。
1-服务器端 2-客户端 3-数据源 4-数据采集单元 5-环状数据缓冲单元 6-平均值处理单元 7-平均值文件单元 8-数据查询单元 9-数据查询请求单元。
具体实施方式
下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
实施例:
本实施例一种历史平均值管理系统,如图1所示,系统包括客户端2和服务器端1,客户端包括数据查询请求单元9,服务器端包括数据查询单元8、数据源3、数据采集单元4、环状数据缓冲单元5、平均值处理单元6、平均值文件单元7。数据源、数据采集单元、环状数据缓冲单元、平均值处理单元、平均值文件单元顺序连接,数据查询单元分别与环状数据缓冲单元、平均值文件单元相连接,数据查询请求单元通过网络与数据查询单元相连接。
服务器端:用于平均值计算与存储的设备,提供数据采集,平均值计算,以及提供数据查询,通过网络通信的方式与客户端进行通信,传输数据。
客户端:用户向服务器端发送查询请求,并将查询结果进行后续处理的设备。
数据源:采用实时数据库,用于现代工业监控系统中的数据采集和存储。
数据采集单元:安装在服务器端,采集位号的实时数据。位号是底层物理设备所提供的数据点在实时数据库中的唯一编号,除此之外还可能包括实时库服务运行所需的其他虚拟点在实时数据库中的唯一编号,是服务器端中对应的唯一索引。
环状数据缓冲单元:接收数据采集单元压入的数据,通过环形保存方式,不间断进行数据压入,同时向平均值文件单元写入数据。
平均值处理单元:对环状数据缓冲单元中的数据进行分钟平均值计算,小时平均值计算,以及其他平均值进行计算。
数据查询请求单元:用户通过数据查询单元向服务器端发送查询请求。
数据查询单元:根据客户端查询请求从环状数据缓冲单元和平均值文件单元查询相应数据。
如图2所示,环状数据缓冲单元的存储结构包括缓存头、位号头、若干平均值数据块和若干瞬时值数据块,若干平均值数据块和若干瞬时值数据块分别都以循环读写方式呈环形分布;
缓存头:保存所有位号总数和最近一次读取缓存中平均值数据块的时间;
位号头:保存位号名称,位号瞬时值的读指针、写指针,位号平均值的读指针、写指针;
平均值数据块:保存分钟平均值和分钟时间;
瞬时值数据块:保存瞬时值和写入的时间。
如图3所示,平均值文件单元包括若干平均值文件,平均值文件的存储结构包括历史文件头、一级索引、若干二级索引和若干数据块;
历史文件头:保存文件标示、文件版本、字节序、开始时间、结束时间和位号总数;
一级索引:结构包括若干位号头,每个对应的位号头保存位号名称和二级索引地址;
二级索引:结构包括顺序排列的索引头、上一块二级索引地址、下一块二级索引地址、若干小时平均值结构体和若干数据块地址结构体;索引头保存每个位号对应的一级索引地址,上一块二级索引地址保存与位号上方相邻的二级索引地址,下一块二级索引地址保存与位号下方相邻的二级索引地址,小时平均值结构体保存小时时段和小时平均值,数据块地址结构体保存分钟段开始时间、分钟段结束时间和对应数据块地址;
数据块:结构包括顺序排列的数据块索引头、若干分钟平均值结构体;数据索引头保存对应二级索引地址,分钟平均值结构体保存分钟段时间和平均值。
一种历史平均值管理系统管理方法,包括平均值存储步骤和数据查询步骤。
如图4所示,平均值存储步骤包括以下步骤:
SS1.定义环状数据缓冲单元和平均值文件单元的存储结构;
定义环状数据缓冲单元的存储结构为:
包括缓存头、位号头、若干平均值数据块和若干瞬时值数据块,若干平均值数据块和若干瞬时值数据块分别都以循环读写方式呈环形分布;
缓存头:保存有位号总数和最近一次读取缓存中平均值数据块的时间;
位号头:保存位号名称,位号瞬时值的读指针、写指针,位号平均值的读指针、写指针;
平均值数据块:保存分钟平均值和分钟时间;本实施例中以采用20分钟平均值区间为例,也就是最大20个平均值记录,以循环方式写入和读取,平均值记录区间长度可以根据具体要求做相应的增加或删除。
瞬时值数据块:保存瞬时值和写入的时间。本实施例中以采用20分钟瞬时值区间为例,也就是最大1200个瞬时值记录,以循环的方式写入与读取,可根据要求做相应的增加或删除。
本实施例以10分钟一次数据写入为例,只要在下一个10分钟到来之前完成平均值数据的写入,那这个系统是有效的,如果全部位号一次平均值写文件不能在10分钟内完成,那么就需要增加环状数据缓冲单元的存储空间长度。
定义平均值文件单元的存储结构为:
包括若干平均值文件,平均值文件的存储结构包括历史文件头、一级索引、若干二级索引和若干数据块;
历史文件头:保存文件标示、文件版本、字节序、开始时间、结束时间和位号总数;
一级索引:结构包括若干位号头,每个对应的位号头保存位号名称和二级索引地址;通过需要保持平均值的位号总数,预先设置一段位号头长度乘以位号总数的预留空间,假设位号总个数为M,位号头在服务器端上的长度为N,那一级索引所需的空间就是M*N的长度。存储时,将每个位号和对应的二级索引地址依次填入地址空间。二级索引地址由每个二级索引的总长度计算而来。
二级索引:结构包括顺序排列的索引头、上一块二级索引地址、下一块二级索引地址、若干小时平均值结构体和若干数据块地址结构体;索引头保存每个位号对应的一级索引地址,上一块二级索引地址保存与位号上方相邻的二级索引地址,下一块二级索引地址保存与位号下方相邻的二级索引地址,小时平均值结构体保存小时时段和小时平均值,数据块地址结构体保存分钟段开始时间、分钟段结束时间和对应数据块地址;本实施例以一天的时间段作为一个平均值文件,小时平均值需要至少预留n+1个小时的预留长度也就是25个小时平均值结构体的长度。本实施例以数据块记录10分钟平均值为例,则一个位号需要1440/10=144个数据块,则对应的也有144个数据块地址结构体。假设二级索引的索引头、上一块二级索引地址、下一块二级索引地址的总长度为A,一个小时平均值结构体长度为B,一个地址数据块结构体长度为C,则一个二级索引的长度为:A+B*25+C*144。由于每个二级索引长度是固定的,一级索引所要填写的二级索引地址就是根据第一个二级索引开始地址逐个加上二级索引的长度就能得出。数据块地址结构中的数据地址,由每个数据块总长度计算而来。
数据块:结构包括顺序排列的数据块索引头、若干分钟平均值结构体;数据索引头保存对应二级索引地址,分钟平均值结构体保存分钟段时间和平均值。
SS2.通过计时,计算环状数据缓冲单元内所有位号一分钟平均值并进行存储;
计时操作为开启定时器,每秒触发一次,服务器端判断当前时间离上一次计算分钟平均值的时间是否超过一分钟,若否进入步骤SS3,若是则进行所有位号的分钟平均值计算,将计算的分钟平均值写入环状数据单元指定位置内。
其中分钟平均值计算过程为:
获取环状数据缓冲单元中对应的瞬时值读指针,从读指针开始找到指定分钟前的一个瞬时值,以及分钟时间段内所有瞬时值,从指定分钟的第1秒开始,判断当前秒是否有瞬时值,若有则继续往下一秒执行,若无则用当前秒前的瞬时值作为当前秒瞬时值,如此操作直至补齐整个60秒内的瞬时值,最后对60个瞬时值取平均值得到分钟平均值。
SS3.通过计时,相隔设定分钟,将该时间段内所有分钟平均值写入对应平均值文件;
SS31.判断当前平均值文件是否写满,若否进入下一步骤,若是则新建一个平均值文件;
SS32.服务器端将当前时间与上一次写设定分钟平均值的时间进行比较,判断是否超过设定分钟,若否返回步骤SS2,若是则获取环状数据缓冲区平均值读取指针,从平均值读取指针开始往后找,获取设定分钟内所有的分钟平均值,写入平均值文件。服务器端将当前时间与上一次写10分钟时间段内平均值的时间进行比较,判断是否超过10分钟,若否返回步骤SS2,若是则获取环状数据缓冲区平均值读取指针,从平均值读取指针开始往后找,获取10分钟内所有的分钟平均值;写入的具体方法是,通过位号在一级索引中找到二级索引的位置,将之前记录的写文件次数(将一天时间分成144份,每次保存当前写入的是第几个10分钟)作为偏移量,找到该位号的数据块所在位置,然后将10分钟的平均值写入数据块中,最后将写文件次数增一。
SS4.在当前平均值文件将其所有分钟平均值写完毕后,计算小时平均值并关闭文件,返回步骤SS2;
在当前平均值文件将设定分钟时间段分钟平均值写完毕后,判断平均值文件记录的写文件次数是否达到144次,若否返回步骤SS2,若是则计算整个平均值文件中所有时段的小时平均值,并将计算后的值写入对应位置,关闭文件,返回步骤SS2。
如图5所示,数据查询步骤包括以下步骤:
SI1.分析查询请求,确定查询时间区间、查询类型;
在步骤SI1中,查询请求包括查询位号、查询类型、查询的起始时间以及结束时间,查询类型包括分钟平均值、小时平均值、天平均值、月平均值和年平均值;根据查询类型、查询的起始时间以及结束时间,当查询分钟平均值时,剔除当前时间所在分钟,当查询小时平均值时,剔除当前时间所在小时,以此类推,以剔除无法完整计算的平均值时段;对查询类型进行判断,是否为分钟平均值、小时平均值、天平均值、月平均值或年平均值;
SI2. 查询类型为分钟平均值,根据查询时间区间对应从环状数据缓冲单元、平均值文件查询分钟平均值,进入步骤SI5;
判断查询分钟平均值时间区间的时间是否都大于环状数据缓冲单元最后一次记录的写入平均值文件的时间,若是从环状数据缓冲单元中查询分钟平均值,若否再判断分钟平均值时间区间是否有部分时间大于环状数据缓冲单元最后一次记录的写入平均值文件的时间,若有则部分时间从环状数据缓冲单元中查询分钟平均值,时间区间其余部分时间从平均值文件中查询分钟平均值;若没有则直接从平均值文件查询分钟平均值;
SI3. 查询类型为小时平均值,从平均值文件查询小时平均值,进入步骤SI5;
判断查询小时平均值时间区间对应的小时平均值结构体内数据是否为空,若否从平均值文件中查询小时平均值,若是则计算小时平均值,然后再判断小时平均值区间内是否有一个小时跨越两个平均值文件,若无进入步骤SI5,若有则对该跨越小时的平均值进行重新计算,跨越小时平均值=(W*V1+U*V2)/60 ,其中W为跨越小时前一个小时的小时平均值,U为跨越小时后一个小时的小时平均值,V1为前一个平均值文件结束时间的分钟值,V2为后一个平均值文件开始时间的分钟值
SI4. 查询类型为天、月或年平均值,根据步骤IS3获取查询时间区间内小时平均值,根据小时平均值计算出天、月或年平均值;
根据小时平均值进行计算,返回数据给客户端,若否也返回数据给客户端;
SI5. 将查询的数据返回数据给客户端。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
尽管本文较多地使用了服务器端、客户端、数据源、数据采集单元等术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
- 还没有人留言评论。精彩留言会获得点赞!