一种基于程序分析的软件日志行为自动识别方法与流程
本发明涉及计算机软件中日志行为的识别方法,尤其指大规模软件中面向故障诊断的日志行为识别方法。
背景技术:
当今计算机技术迅速发展、计算能力不断提高,计算机软件系统无论从规模上还是功能上都在增大、增强。随着软件需求的日益复杂,大规模软件系统在军用和民用领域中均被广泛使用。目前,中、小规模软件可以利用形式化等方法有效保障可靠性,但大规模软件的故障诊断主要依靠人力排查,定位问题不及时且效率低,错误重现和调试都十分困难。
软件日志是大型软件中故障诊断的重要手段,它可以记录程序运行时的动态信息,帮助维护人员分析重现错误,进而更正系统错误。规范和充分的日志对于软件故障诊断非常重要,也是良好编程规范的必要因素。但目前软件中的日志多数是依赖编程人员的经验和个人习惯,缺乏统一的被普遍接受的标准,在大型开源软件中利用现有的日志信息进行故障重现和检测难度大、效率低。因此,通过增强日志代码质量,进一步改善大规模软件故障检测技术的研究愈加重要。同时,由于代码量巨大,人工改善软件日志几乎不可能完成,因此自动化地实现日志增强的需求越来越迫切,同时也面临重大挑战。
日志自动增强的主要方法是通过学习软件已有日志,预测需要添加日志的程序点。其中,如何自动、准确地识别软件已有面向故障诊断的日志是日志增强过程中的一个关键技术。目前国际上已有日志的自动化增强工具,其中有代表性的有朱杰明的文章Learning to Log:Helping Developers Make Informed Logging Decisions(为开发人员提供有效日志决策)中设计的LogAdvisor,以及袁丁的文章Be Conservative:Enhancing Failure Diagnosis with Proactive Logging(保守地插入前瞻日志以增强故障诊断能力)中设计的Errlog。已有工作在识别日志时需要用户提供信息(如指定日志函数名),导致日志行为识别时效率、准确性较低,进而影响到后续日志增强的有效性。
如何有效识别计算机软件中面向故障诊断的日志行为,是自动化的日志增强中重要技术问题,如何针对现有日志增强工作难以自动、准确识别软件已有日志行为的问题,提供一种日志行为自动识别方法,为软件日志的自动增强提供技术支持是本领域技术人员极为关注的技术问题。
技术实现要素:
本发明要解决的技术问题是为支持软件日志的自动化增强提供一种精确的日志行为识别方法,解决现有日志增强工作难以自动识别软件已有日志行为的问题,使得日志行为识别过程更为快速、准确。给定目标工程的源代码,本发明可以自动识别出源代码中面向故障诊断的日志行为。
本发明的技术方案包括以下步骤:
第一步、准备输入输出。方法为:
1.1 记目标工程为Proj,将Proj的源代码以函数为单位分割,得到函数集F={func1,func2,...,funcf},其中func1为Proj中的第1个函数,f为Proj中函数的个数。
1.2 建立日志行为集LB,用于保存日志行为识别结果,并初始化为空。
第二步、建立函数的分支语句、函数调用语句和日志语句的集合。方法为:
2.1 令变量i=0。
2.2 令i=i+1,如果i>f,执行第六步;否则执行2.3。
2.3 建立分支集B(i)、调用集C(i)和日志集L(i),分别表示funci中的分支语句集合、函数调用语句集合和日志语句集合,并将B(i)、C(i)和L(i)全部初始化为空。
第三步、填充第二步建立的B(i)、C(i)和L(i)。方法是:
3.1 填充分支集B(i)。使用前端分析工具(如LLVM编译框架的前端工具,LLVM由Chris Lattner等人公开于文章LLVM:a compilation framework for lifelong program analysis&transformation,LLVM:一种支持长期程序分析与代码转换的编译框架)识别funci中的所有分支语句(如C语言中的if/switch语句),并加入B(i)中。得到B(i)={brani,1,brani,2,...,brani,b(i)},其中brani,1为funci的第1个分支语句,b(i)为funci中分支语句的个数。
3.2 填充调用集C(i)。使用前端分析工具识别funci中的所有函数调用语句(如C语言中的函数调用语句malloc()),并加入C(i)中。得到C(i)={calli,1,calli,2,...,calli,c(i)},其中calli,1为funci的第1个函数调用语句,c(i)为funci中函数调用语句的个数。
3.3 填充日志集L(i),方法是:
3.3.1 令变量j=0。
3.3.2 令j=j+1,如果j>c(i),则L(i)={logi,1,logi,2,...,logi,z…,logi,l(i)},其中logi,z为第i个函数的第z个日志语句,1<=z<=l(i),l(i)为第i个函数中日志语句的个数,执行第四步。如果j<=c(i),执行3.3.3。
3.3.3 判断calli,j是否为日志语句,方法是:
3.3.3.1 建立单词集W1和W2,其中W1为由单词{‘error’,‘exit’,‘output’}所产生的同义词集合,即‘error’的同义词、‘exit’的同义词以及‘output’的同义词的并集,(同义词可通过WordNet工具获得,wordnet.princeton.edu),W2为由单词{‘error’,‘exit’,‘limitation’,‘negation’}所产生的同义词集合,即‘error’的同义词、‘exit’的同义词、‘limitation’的同义词、‘negation’的同义词的并集。
3.3.3.2 取calli,j的函数名,得到字符串name-str(i,j),如果有word∈W1且满足word为name-str(i,j)的子串,执行3.3.3.3。否则判定calli,j不是日志语句,执行3.3.2。
3.3.3.3 取calli,j的所有参数,拼接成字符串argu-str(i,j),如果有word∈W2且满足word为argu-str(i,j)的子串,执行3.3.3.4。否则执行3.3.2。
3.3.3.4 将calli,j所表示的函数调用语句作为日志语句加入L(i)中,执行3.3.2。
第四步、筛选出集合C(i)和B(i)之间存在数据依赖的元素。方法是:
4.1 枚举C(i)和B(i)中的元素,方法是:
4.1.1 令变量m=0。
4.1.2 令变量m=m+1,n=0,如果m>c(i),执行第2.2步;否则执行4.1.3。
4.1.3 令变量n=n+1,如果n>b(i),执行4.1.2;否则执行4.2。
4.2 判断brani,n与calli,m之间是否存在数据依赖,若brani,n和calli,m之间存在数据依赖,则执行第五步,若brani,n和calli,m之间不存在数据依赖,则执行4.1.3。判断方法具体为:
4.2.1 使用前端分析工具分别获得brani,n的行号bran-line(i,n)和calli,m的行号call-line(i,m),如果bran-line(i,n)等于call-line(i,m)(即calli,m在brani,n的判断条件中,相当于对calli,m的返回值进行判断,brani,n和calli,m之间必然存在数据依赖),令变量y=0,执行第五步,否则执行4.2.2。
4.2.2 建立brani,n的变量集V(i,n)={vari,n,1,vari,n,2,...,vari,n,v(i,n)},其中vari,n,1为brani,n中的第1个变量,v(i,n)为brani,n中变量的个数。
4.2.3 建立calli,m的参数集A(i,m)={argi,m,1,argi,m,2,...,argi,m,a(i,m)},其中argi,m,1为calli,m中的第1个参数,a(i,m)为calli,m中参数的个数。将calli,m的返回值记为argi,m,0,并加入A(i,m),则集合A(i,m)中有a(i,m)+1个元素。
4.2.4 枚举V(i,n)和A(i,m)中的元素,方法是:
4.2.4.1 令变量x=0。
4.2.4.2 令变量x=x+1,y=-1,如果x>v(i,n),执行4.1.3,否则执行4.2.4.3。
4.2.4.3 令变量y=y+1,如果y>a(i,m),执行4.2.4.2,否则执行4.2.5。
4.2.5 利用别名分析工具(如LLVM编译框架的别名分析工具)判断vari,n,x和argi,m,y是否为别名。如果是别名,说明calli,m和brani,n之间存在数据依赖,执行4.2.6,否则执行4.2.4.3。
4.2.6 确定不同的依赖形式,包括在函数调用前,对函数要读入的变量(即函数参数)进行判断;以及在函数调用后,对函数写入的变量(即函数返回值和指针类型的参数)进行判断。方法是:
4.2.6.1 如果bran-line(i,n)<call-line(i,m)且y>0(即calli,m调用之前,brani,n对calli,m的参数进行判断),执行第五步。否则执行4.2.6.2。
4.2.6.2 如果bran-line(i,n)>call-line(i,m)且y=0(即calli,m调用之后,brani,n对calli,m的返回值进行判断),执行第五步。否则执行4.2.6.3。
4.2.6.3 如果bran-line(i,n)>call-line(i,m)且argi,m,y是指针类型参数(即calli,m调用之后,brani,n对calli,m的指针类型参数进行判断),执行第五步。否则执行4.2.4.3。
第五步、筛选出集合L(i)中与brani,n存在控制依赖的元素。方法是:
5.1 判断brani,n是if语句还是switch语句,是if语句时执行5.2,是switch时执行5.3。
5.2 使用前端分析工具获得if语句包含的then语句块和else语句块,执行5.2.1。
5.2.1 顺序搜索then语句块中的所有语句,当有语句stmt=logi,z时,执行5.2.2,否则执行5.2.3。
5.2.2 建立六元组lb=<i,m,n,y,z,if-then>,并将lb加入日志行为集LB。其中lb表示在目标工程Proj的第i个函数体中,通过第n个判断语句对第m个函数调用语句的第y个参数进行了判断(y等于0时表示函数返回值,y等于1时表示函数的第1个参数,y等于2时表示函数的第2个参数,y等于I时表示函数的第I个参数,I为正整数,依此类推),并在if-then块中加了日志语句,且此日志语句为本函数体中的第z个日志语句,1<=z<=l(i)。
5.2.3 顺序搜索else语句块中的所有语句,当有语句stmt=logi,z时,执行5.2.4,否则执行5.2.5。
5.2.4 建立六元组lb=<i,m,n,y,z,if-else>,并将lb加入日志行为集LB。
5.2.5 calli,m和brani,n之间存在的日志行为识别完成,执行4.1.3。
5.3 使用前端分析工具获得switch语句包含的case语句块和default语句块,执行5.3.1。
5.3.1 顺序搜索case语句块中的所有语句,当有语句stmt=logi,z时,执行5.3.2,否则执行5.3.3。
5.3.2 建立六元组lb=<i,m,n,y,z,switch-case>,并将lb加入日志行为集LB。
5.3.3 顺序搜索default语句块中的所有语句,当有语句stmt=logi,z时,执行5.3.4,否则执行5.3.5。
5.3.4 建立六元组lb=<i,m,n,y,z,switch-default>,并将lb加入日志行为集LB。
5.3.5 calli,m和brani,n之间存在的日志行为识别完成,执行4.1.3。
第六步、识别日志行为结束,输出日志行为集LB。
与现有技术相比,采用本发明可以达到以下技术效果:
1.发明第四步通过判定函数调用语句和分支语句的数据依赖,结合第五步分支语句和日志语句的判定,可以精确识别函数调用语句、分支语句与日志语句之间的对应关系。现有技术(如朱杰明等人的文章Learning to Log:Helping Developers Make Informed Logging Decisions,为开发人员提供有效日志决策)忽略了数据流、控制流在日志行为中的影响,仅能识别出函数调用语句序列和日志语句序列,但无法识别出函数调用语句与日志语句之间的对应关系。
2.发明第3.3步采用基于同义词语义的日志语句识别方法,可以自动识别程序中面向故障诊断的日志语句。现有工作(如袁丁等人的文章Be Conservative:Enhancing Failure Diagnosis with Proactive Logging,保守地插入前瞻日志以增强故障诊断能力)需要用户指定日志函数名等信息,导致自动化程度较低、且难以保证用户输入的完备性和准确性,同时这种方法无法区分面向故障诊断的日志行为和非故障诊断的日志行为。
3.发明第4.1步枚举函数调用语句和分支语句可以识别复杂程序逻辑中的日志行为。对于诸如同一函数调用语句在不同的分支语句下有多个日志语句,或多个函数调用语句在同一分支语句下有同一日志语句等复杂程序逻辑,本发明可精确识别其对应关系。现有工作由于缺乏对日志行为中数据流的分析,导致无法有效识别上述情况。
附图说明
图1是本发明总体流程图。
图2是采样本发明识别日志行为的示例。
具体实施方式
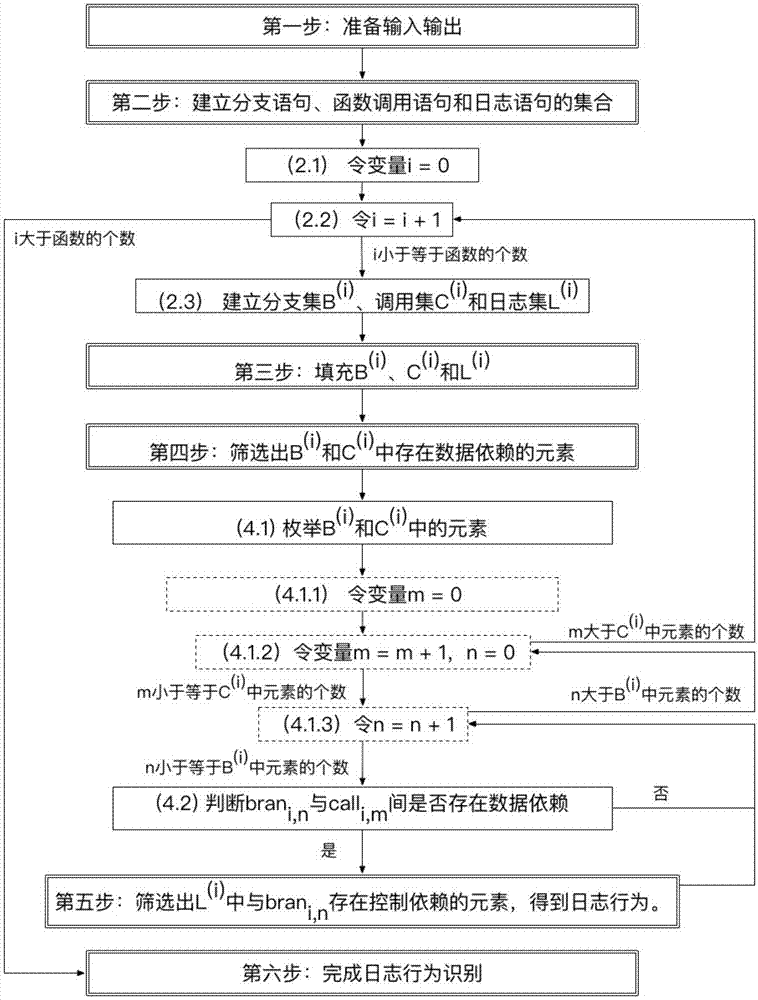
图1是本发明总体流程图。
第一步、准备输入输出。记目标工程为Proj,将Proj的源代码并以函数为单位分割,得到函数集F。建立日志行为集LB,并置为空。其中F为输入,LB为输出。
第二步、建立分支语句、函数调用语句和日志语句的集合。具体为:
2.1 令变量i=0。
2.2 令i=i+1,如果i大于程序中函数的个数,执行第六步;否则执行2.3。
2.3 建立分支集B(i)、调用集C(i)和日志集L(i),并将三个集合置空。
第三步、填充分支语句、函数调用语句和日志语句的集合。识别funci中的函数调用、分支、日志语句,并分别加入相应的集合中。
第四步、筛选出集合C(i)和B(i)中存在数据依赖的元素。具体为:
4.1 枚举B(i)和C(i)中的元素:
4.1.1 令变量m=0。
4.1.2 令变量m=m+1,变量n=0,如果m大于C(i)中元素的个数,执行2.2步;否则执行4.1.3。
4.1.3 令变量n=n+1,如果n大于B(i)中元素的个数,执行4.1.2;否则执行4.2。
4.2 判定brani,n与calli,m之间是否存在数据依赖。对于C(i)中元素calli,m,得到其参数集A(i,m),对于B(i)中元素brani,n,得到其变量集V(i,n),如果A(i,m)与V(i,n)之间有元素存在别名,则也说明calli,m与brani,n存在数据依赖。存在数据依赖则执行第五步,不存在数据依赖则。
第五步、对于存在数据依赖的calli,m与brani,n,筛选出集合L(i)中与brani,n存在控制依赖的元素。取brani,n包含的所有语句块,依次判断每个语句块中是否存在日志语句,如果存在则识别出一个日志行为,加入LB中。执行4.1.3。
第六步:完成日志行为识别,输出日志行为集LB。
图2是采用本发明识别日志行为的示例。
第一步、将图中所示工程源码分割为三个函数体:func1,func2和func3。
第二步、建立分支集B(i)、调用集C(i)和日志集L(i),并置为空。
第三步、填充分支集B(i)、调用集C(i)和日志集L(i),对func1有B(1)={bran1,1},C(1)={call1,1},L(1)={log1,1};对func2有B(2)={bran2,1},C(2)={call2,1},L(2)={log2.1};对func3有B(3)={bran3,1},C(3)={call3,1,call3.2},L(3)={log3,1},其中log("Hello World")输出的内容"Hello World"不是用于故障诊断的信息,不满足3.3.3.3中的规则,所以不加入日志集中,相反log("Failed")的输出内容“Failed”是用于故障诊断的信息,满足3.3.3.3中的规则,则加入日志集中。
第四步、筛选出分支集B(i)和调用集C(i)中存在数据依赖的元素。如果两者在同一行(如func1中的bran1,1与call1,1),则说明存在依赖,执行第五步。否则提取分支语句的变量集,对func2的bran2,1有V(2,1)={var2,1,1},对func3的bran3,1有V(3,1)={var3,1,1,var3,1,2}。提取函数调用语句的参数集,对func2的call2,1有A(2,1)={arg2,1,0,arg2,1,1}(call2,1无返回值,因此为arg2,1,0空),对func3的call3,1有A(3,1)={arg3,1,0},对func3的call3,2有A(3,2)={arg3,2,0,arg3,2,1}。
对于互为别名的变量和参数(如func2的(var2,1,1,arg2,1,1),func3的(var3,1,1,arg3,1,0)和(var3,1,2,arg3,2,1),满足以下三个条件之一时,执行第五步。若不满足,则不做处理。
(1)bran-line(i,n)<call-line(i,m)且y>0,如func2中的(var2,1,1,arg2,1,1)。
(2)bran-line(i,n)>call-line(i,m)且y=0,如func3中的(var3,1,1,arg3,1,0)。
(3)bran-line(i,n)>call-line(i,m)且argi,m,y是指针类型参数,如func3中的(var3,1,2,arg3,2,1)。
第五步、对于存在数据依赖的calli,m与brani,n,筛选出集合L(i)中与brani,n存在控制依赖的元素。如果有满足条件的日志语句,则记录一个日志行为。如:
(1)call1,1与bran1,1有数据依赖且log1,1控制依赖于bran1,1,记录日志行为lb1=<1,1,1,0,1,if-then>;(2)call2,1与bran2,1有数据依赖且log2,1控制依赖于bran2,1,记录日志行为lb2=<2,1,1,1,1,if-then>;(3)call3,1与bran3,1有数据依赖且log3,1控制依赖于bran3,1,记录日志行为lb3=<3,1,1,0,1,if-else>;
(4)call3,2与bran3,1有数据依赖且log3,1控制依赖于bran3,1,记录日志行为lb4=<3,2,1,1,1,if-else>。
第六步、日志行为识别完成,输出日志行为集LB={lb1,lb2,lb3,lb4}。
- 还没有人留言评论。精彩留言会获得点赞!