一种生存风险的大数据分析方法及系统与流程
本发明属于风险分析预测技术领域,具体涉及一种生存风险的大数据分析方法及系统。
背景技术:
目前的生存风险分析主要有两种,一种是疾病风险分析,一种是意外风险分析。保险公司根据对生存风险的分析制定保险产品。
疾病风险分析是有关患病可能程度的分析,它与家庭健康管理、饮食营养、运动、习惯、心理、环境有很大的关系。以抑郁症为例:生活快节奏、紧张、信息量空前巨大、社会关系复杂、作息方式变化、消费取向差异、在公平的理念下不公平的事实拉大、溺爱等原因,都使心理疾病逐渐增多并恶化。
Philip J BatterhamEmail等2009年在BMC上发表了一篇用决策树的方法分析预测抑郁症风险的文献综述。对参与者进行了长达4年的调查、测试,初期症状的抑郁症成为最为强烈抑郁症的风险。然而,症状类别中也出现了大范围的风险状况。
现有技术中自我评价和问卷调查是验证心理疾病的主要方法,它能够计算被测试者的心理特征。心理疾病又不同于常见的身体疾病,投保人在进行心理测试的时候,会出现一些偏差或缺漏,在这种情况下,心理疾病风险得不到准确的分析。澳大利亚保险业曾被指歧视心理疾病患者,因为保险公司没有办法精确地对心理疾病问题的进行评估,从而建立可靠的数据库。保险公司无法为他们无法评估的风险定价,并没有能力评估某些心理疾病复发的可能性。
现有意外风险分析,主要是依靠简单的调查问卷,包括投保人的年龄、性别、职业等,几乎不涉及关乎意外风险的要素调查,比如投保人的活动区域、出行方式等,统一化投保人的意外风险。
以交通意外事故预测分析技术为例,现有的分析技术中比较有代表性的是道路交通事故灰色预测模型,比如基于灰色预测理论的GM(1,1)模型,
设道路交通事故原始数据序列X(0)(t)={X(0)(1),X(0)(2),X(0)(3),…X(0)(n)},运用灰色系统理论可以建立道路交通事故GM(1,1)模型
设式中Y(t)为t时刻GM(1,1)模型求得的道路交通事故预测值,曲线较好地反映了道路交通事故原始数据列的总体变化趋势。
基于灰色预测理论的GM(1,1)模型,分别对道路交通事故的死亡人数、交通事故量进行预测,其结果是可信的。它尤其适合于交通事故预测这样"小样本"的随机不确定问题。但是由于数据量的局限性,导致预测的结果偏差较大,因此不能达到高精准预测的目的。
当今社会,大数据是一把双刃剑,一方面传统行业正在面临大数据的冲击,另一方面大数据也为保险业带来了新的商业价值。众所周知,保险公司等金融企业能够准确评估风险是至关重要的,换言之,风险降低1%也会给企业带来丰厚的利润。
在没有大数据之前,商业数据往往来源于一些被动的调查表格及滞后的统计数据。大数据时代出现之后,海量数据的即时采集和处理成为可能。利用大数据分析结果归纳和演绎出事物的发展规律,可以帮助保险业进行精准营销,即按照客户需要设计保险产品,使更多的群众享受到合理的金融服务。这对于企业精准评估客户风险等级、合理定价保险产品、提升客户满意度、防止客户流失是非常重要的。
例如,本公司的在先技术,申请号201610457015.X的中国发明专利申请中,涉及一种大数据风险分析方法。该发明结合大数据,利用机器学习算法模型分析被保人的日常行为习惯,预测出被保人罹患疾病或发生意外的可能性,从而更为人性化地制定相应的保费标准。进一步对新模型的可行性进行了研究,首先是建立了新模型赔偿率和预测准确率的关系式,发现了预测准确率和赔偿率的负相关关系,并且当预测准确率大于50%时,新模型赔偿率将低于原模型赔偿率。并用MATLAB对模型进行可视化分析。然后进行了新模型盈利分析,建立了低风险客户的折扣、预测准确率以及盈利的三维关系,更为直观地得到新模型下增加的盈利空间。
然而上述大数据中,所述结合大数据的方法如下:先运用Hadoop平台完成对原始数据的预处理以及特征工程的训练,然后利用逻辑回归等二分类算法训练机器学习模型,最后采用AUC方法对所述机器学习模型进行评价。上述过程较为复杂,计算速度不快。
技术实现要素:
为解决以上问题,本发明在大数据的背景下,依托现有数据的优势,结合用户的上网数据、定位信息、通话记录等,更为精准的分析了用户的疾病风险和意外风险。疾病风险分析部分,针对现在容易被忽视但隐患极大的心理疾病风险,通过结合用户的网络行为特征,更全面更精准的评估用户的潜在心理疾病风险。意外风险部分,主要分析了用户的交通事故风险,结合用户的定位信息、搜索记录、上网记录等数据,分析用户的出行习惯,从而确定其发生交通意外事故的风险。总之,本发明弥补了保险行业分析人类风险数据不足的现状,为保险公司设计更为人性化的保险产品提供了思路。
具体的,根据本发明的一个方面,本发明提供了一种生存风险的大数据分析方法,所述方法包括如下步骤:
收集和分析与用户相关的互联网大数据信息;
根据上述互联网大数据信息建立生存风险计算模型;
根据所述模型的计算结果预测用户面临的生存风险。
进一步,如权利要求1所述的生存风险的大数据分析方法,收集和分析与用户相关的互联网大数据信息的方法为:通过爬虫采集用户访问社交网站的记录,进行页面分析并下载上述记录的数据,并结合自我评价、问卷调查计算出的心理特征参数,分析用户的网络行为特征,进行分类得到特征向量。
进一步,如权利要求1所述的生存风险的大数据分析方法,所述生存风险计算模型为最小二乘支持向量机模型,对心理疾病风险进行分析,是基于网络数据分析的心理特征状态计算模型。
进一步,如权利要求1所述的生存风险的大数据分析方法,所述最小二乘支持向量机是通过最小化误差对的平方和寻找数据的最佳函数匹配。
进一步,如权利要求1所述的生存风险的大数据分析方法,收集和分析与用户相关的互联网大数据信息的方法为:收集和分析用户在互联网上记录的驾驶相关信息。
进一步,如权利要求1所述的生存风险的大数据分析方法,所述驾驶相关信息包括用户的驾驶时间、路线、位置,分析上述驾驶相关信息,从而确定是否是超速和/或疲劳驾驶。
进一步,如权利要求1所述的生存风险的大数据分析方法,所述生存风险计算模型为逻辑回归模型。
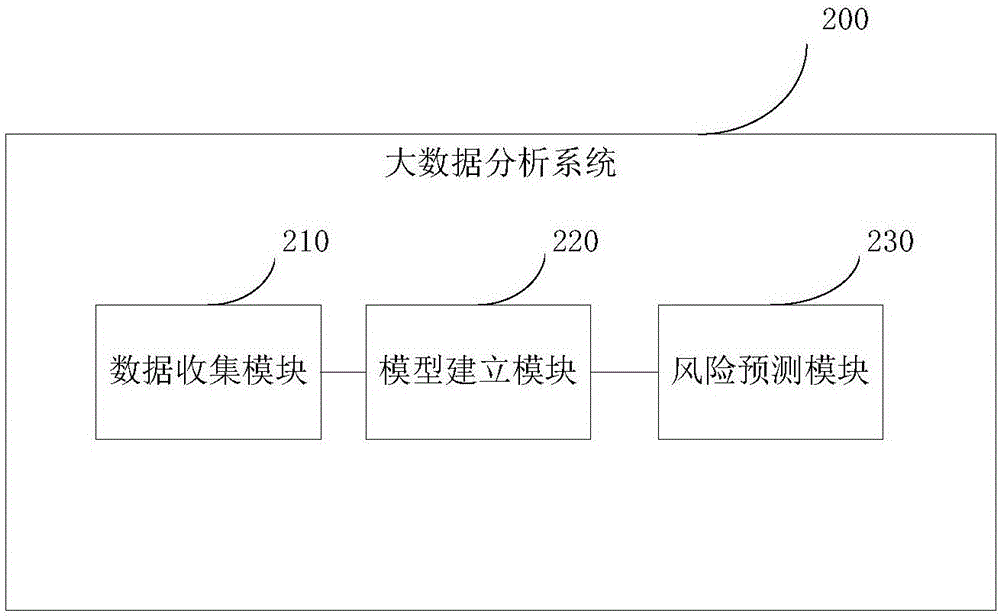
根据本发明的另一个方面,本发明还提供了一种生存风险的大数据分析系统,所述系统包括如下模块:
数据收集模块,用于收集和分析与用户相关的互联网大数据信息。
模型建立模块,用于根据上述互联网大数据信息建立生存风险计算模型。
风险预测模块,用于根据所述模型的计算结果预测用户面临的生存风险。
本发明的有益效果如下:传统的疾病风险分析由于外界的发病率统计资料不完整,只能进行粗略的风险判断和分析。反观,大数据挖掘却是全面性、广泛性地进行所有状况的分析,精确地识别潜在风险,进而得出一份更完整的健康风险预测报告。大数据挖掘能进行精准的疾病预测,准确的预防方案,确实掌握自身的危险因子。
对于意外风险来说,道路交通事故预测对于探究道路交通事故的发生规律,分析现有道路交通条件下交通事故的未来发展趋势以及道路交通控制等具有重要意义。利用大数据技术分析意外风险,大大提高了预测精度,可以对潜在的风险提前进行预防,具有重大的社会效益和经济效益。
同时利用大数据分析预测疾病和意外风险,为保险风险评估与定价带来了前所未有的创新,并极大地丰富了保险风险因子,有力的推进了传统保险行业数据提取的提升。
附图说明
图1为本发明生存风险的大数据分析方法的流程图。
图2为本发明生存风险的大数据分析系统的模块图。
图3为疾病风险的大数据采集流程图。
图4是一个户外活动者的发帖记录、外出旅游频率以及外出旅游时出行方式的概率图。
具体实施方式
下面结合附图和实施例对本发明进行详细的描述。
用户和互联网、移动、社交网络等工具的频繁交互会产生海量的数据,比如,通话记录、上网时间、上网内容、定位信息等。这些数据可以统称为与用户相关的互联网大数据信息。如下表1所示:
如图1所示,本发明所提供的生存风险的大数据分析方法,包括如下步骤:
S110、收集和分析与用户相关的互联网大数据信息。
S120、根据上述互联网大数据信息建立生存风险计算模型。
S130、根据所述模型的计算结果预测用户面临的生存风险。
如图2所示,本发明所提供的生存风险的大数据分析系统200,包括如下模块:
数据收集模块210,用于收集和分析与用户相关的互联网大数据信息。
模型建立模块220,用于根据上述互联网大数据信息建立生存风险计算模型。
风险预测模块230,用于根据所述模型的计算结果预测用户面临的生存风险。
下面根据上述方法和系统分别用于对疾病风险和意外风险进行大数据分析。本发明以抑郁症和交通意外风险为例,分析大数据模式在传统模式的基础下,通过海量数据进行新的风险评估。
实施例1:抑郁症风险分析
步骤一、数据采集和分析
通过计算机技术的发展,网络用户的在线操作痕迹都可以通过网络服务器以网络日志的形式实时地记录下来,而这种记录提供了一种自然发生并且内容极其丰富核数量极其庞大的人类行为的数据。通过爬虫采集和分析这些网络数据,从而实时计算到用户的心理特征。大数据进行数据采集的方法如图3所示,通过爬虫采集用户通过PC端、手机、PAD端访问社交网站的记录,进行页面分析并下载上述记录的数据,并结合自我评价、问卷调查计算出的心理特征参数,分析用户的网络行为特征,进行分类得到特征向量。这些社交网络包括但不限于微博、微信、知乎、Facebook等。
具体而言,对于抑郁症的各项相关数据的提取过程如下:
1.心理健康状态:
心理测试问卷调查是最常见的一种心理预估方法,而问卷内容有一系列的心理健康症状构成,被测试者通过问卷问题测试出心理风险的趋势,一般来说分数越高就代表着被测试者的某种心理健康问题越严重。
2.网络行为特征:
本发明通过爬虫采集,分析出用户的网络行为特征,进行分类。例如:用户的信息类特征:被分析者的个人信息(性别,年龄等);用户的隐私设置类特征:是否有个人隐私保护偏好;用户社会关系网类特征:描述了被测试者在网络平台上的人际互动情况;用户发表言论类的特征:是否有偏激,厌世,激进类的发表言论,或者对别人不同的观点进行攻击,甚至辱骂、报复这类的行为。
本发明通过社交媒体的不同数据,对用户的抑郁症倾向进行识别,结合心理健康状态调查,识别出抑郁症患者风险指数,并建立模型。
在分析过程中发现,抑郁倾向的用户与普通用户存在很大的区别:
1.时间
登录社交网站的时间存在明显差异,抑郁倾向的用户登录时间更偏向晚上11时之后,其夜间活跃度比普通用户平均高出约30%。
2.关键词
抑郁倾向的用户社交网站的关键词中有较多“死”、“抑郁症”、“生命”、“痛苦”等负能量字眼。其中60%为女性,40%为男性。
3.音乐
抑郁倾向的用户分享或者喜欢的音乐多数偏向于黑暗、悲伤、忧郁等类型,并会无数次重复听。
4.色彩
哈佛数据科学家通过对Instagram用户分析发现:普通的用户会把暗色、灰色把负面情绪联系起来,而且更偏爱明亮、鲜艳的颜色,与之相反,抑郁倾向的用户更偏爱暗色、灰色。
5.照片
同时数据科学家发现,和普通的用户相比,抑郁倾向的用户更倾向于不使用任何滤镜。如果使用滤镜,“Inkwell滤镜”是他们的最爱,这个滤镜把照片变成黑白。相反,普通的用户最喜欢Valencia滤镜,它主要用来调亮照片的色彩。
6.关注人群
抑郁症倾向的用户除了喜欢用小号来表达痛苦情绪,还有群落聚集趋势,他们会同时关注很多其他同类人群,有的甚至会习惯每天到已经自杀的用户社交网站上评论‘今天你还好吗?’等。
当然社交网络也可以为抑郁症患者推送正面的信息,美国Allied Health World的一项调查数据显示,接近25%的用户能找到与自己“同病相怜”的人,希望从他们那里获得鼓励。如果模型能发现并满足这类需求,对于抑郁症的治疗也是有正面意义的。
步骤二、数据建模:本发明运用最小二乘支持向量机模型对心理疾病风险进行分析,建立基于网络数据分析的心理特征状态计算模型,从而验证基于网络数据分析的心理疾病的计算方法的可行性。
最小二乘支持向量机是通过最小化误差对的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间的误差的平法和最小,用函数表示为:
最小二乘支持向量机它保持了支持向量机的所有优点,并通过一定的变换,简化了支持向量机的算法。其推导过程为:
设给定一个有l个数据的训练(xiyi),x∈Rn,y∈R,i=1,2,…l,其中xi是输入数据,yi为对应的输出数据。
最小二乘法的目标优化函数为:
s,t,yi=wTφ(xi)+b+ei,i=1,2…l
其中,φ(·):Rn→Rnk为核空间映射函数;w为权值向量;ei为误差变量,b为偏置量;y为调整参数因子。
定义拉格朗日函数:
式中,αi为拉格朗日乘子。对各个变量进行求偏导得到:
通过消去w和e,求解的优化问题转化为求解线性方程:
其中,
,式中a,b可通过上面式子求得,存在映射函数φ
和核函数K(xj,xk),使得φ(xj)Tφ(xk)=K(xj,xk)
用于函数估计的LS-SVM为:
步骤三、根据所述模型的计算结果可以很容易的预测用户面临的心理疾病例如抑郁症的风险。
实施例2:意外风险分析
举个例子,一个极限运动爱好者,发生意外事故的概率比普通人大很多,问题是,如何判断用户是否是极限运动爱好者呢?
步骤一、收集和分析用户在互联网上记录的驾驶相关信息。例如,用户通过手机上的高德地图App进行实时导航,该手机上网后,高德地图可以实时记录用户的驾驶相关信息。通过用户的即时定位信息分析用户的驾驶时间、路线、位置等驾驶相关信息,从而确定是否是超速和/或疲劳驾驶。
下面说明如何利用现有数据来进行用户意外风险分析。
1.行驶里程大
俗话说“常在河边走哪有不湿鞋”,大量资料显示,随着车辆行驶里程的增加,发生交通事故的概率会显著上升。并且,南开大学的学者研究也表明,交通事故损失额与公路里程数之间存在显著正相关关系。
鉴于欧美等发达国家的保险公司数据库中已有行驶里程数的统计数据,美国加州大学伯克利分校的学者Edlin(1998)对单位里程的车险保费进行了研究,其研究结果表明,机动车辆保险成本对行驶里程数的弹性系数在1.42到1.85的范围内。也就是说,机动车辆行驶里程数每增加1%,保险成本将增加1.42%到1.85%。
结合用户的定位信息以及速度,可以判断用户的行程里程数,而不用受限于用户是否开车。
2.超速驾驶
交规中规定驾驶车辆超速50%时,一次性记12分,说明超速驾驶的严重性,十次事故九次快,更是直接说明了超速驾驶的危害。
根据一个超速用户的驾驶出行记录做出的随着时间推移平均速度的变化图,该用户在凌晨4点到6点之间保持平均车速在120km/h以上,因此判断此人发生交通事故的概率将是正常驾驶者的10倍以上。
3.疲劳驾驶
资料显示,2007年,我国直接由疲劳驾驶造成的事故数为3349起,死亡1768人。2002年澳大利亚交通安全委员会支持的一项专门针对疲劳驾驶的研究表明,约20%的道路交通事故由疲劳驾驶造成,且这些交通事故大都是造成人员伤亡的重大交通事故。由此可见,疲劳驾驶是造成重大交通事故的罪魁祸首之一。
研究表明,连续驾驶时间小于4小时时,事故发生率在1%以下;当连续驾驶10小时后,疲劳驾驶导致的事故发生率上升到了5%,当连续驾驶12小时时,疲劳驾驶导致的事故发生率上升到了10%;而当连续驾驶17小时时,疲劳驾驶导致的事故发生率上升到了25%,是连续驾驶10小时的5倍。
上面是一个典型的案例分析。类似于上面分析超速驾驶用户的情况,我们结合用户的即时定位信息可以分析出用户每天的驾驶时间、位置以及持续驾驶的天数,从而确定该用户是否具有疲劳驾驶习惯。
综上,以上分析了导致交通意外事故的几种因素,可见利用现有的大数据优势,可以更精准地预测用户的交通事意外风险。
如图4所示,是一个户外活动者的发帖记录、外出旅游频率以及外出旅游时出行方式的概率图,可以看出该用户关于外出游玩的记录占据发帖纪录的13%,并且一年中有大约150天都在外出旅游,可见该用户是一个典型的户外爱好者,并且其选择的出游方式多为自驾游,众所周知,火车和飞机发生意外的概率是非常小的,而自驾发生意外事故的概率就大得多。并且该用户35%的出游地点为山区,而山区发生意外事故要比平原地区高得多,综上判断该用户是一个意外事故的高风险用户。
步骤二、综合以上研究成果建立了逻辑回归模型,判断用户的风险类型。
设f(x)=θ0+θ1x1+…θnxn=θTx,xi(i=1,2...n)是特征向量(用户是否超速、疲劳驾驶、酒驾、行驶里程大等行为习惯),θ为参数。转换成Logistic模型,Logistic函数形式如下:
则预测函数为
P(y=1|x;θ)=hθ(x)
P(y=0|x;θ)=1-hθ(x)
即当hθ(x)>0.5时,驾驶人为高风险用户;当hθ(x)<0.5时,驾驶人为低风险用户。
构造成本函数,
利用最大似然估计推导得到损失函数的表达式,
J(θ)取得最小值时的θ为要求的最优参数。下面利用梯度下降法求J(θ)的最小值。
根据梯度下降法知θ的更新过程:
上式中α为学习步长,对上式求偏导,
最终的θ更新过程为:至此,得到了最优参数θ,从而可以求得hθ(x),相应地完成了对用户的分类。
步骤三、根据所述模型的计算结果可以很容易的预测用户面临的交通意外风险。
本发明以保险业中的疾病风险和意外风险为例,来说明大数据背景下的风险分析较传统风险分析方式的优势。对于传统的分析方法和大数据下的分析方法比较如下表2所示:
表2
可见,使用本发明的生存风险的大数据分析方法,可以更加准确预测保险用户的生存风险,为保险业制定保险产品提供了极大帮助。
本发明结合现有数据,更加全面地分析客户的生存风险,弥补传统分析方法所带来的弊端,精准的评估出客户风险等级。比如,经常熬夜泡吧的用户,发生疾病的概率会远远高于作息正常的用户;经常超速驾驶的用户,发生交通事故的概率会远远高于安全驾驶的用户。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若对本发明的这些修改和变型属于本发明权利要求及其同等技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!