一种欺诈网站的检测方法与流程
本发明涉及网络安全领域,尤其涉及一种含有欺诈信息网站的检测方法。
背景技术:
在信息技术飞速发展的今天,中国网民的数量的逐年增长,但对于大多数安全意识相对缺乏的网民来说,欺诈网站侵害人民财产安全是一个严重问题。网络欺诈,是指通过声称来自正规或知名机构等的欺骗性垃圾邮件或者仿照正规网站页面等方式,意图引诱收件人给出敏感信息(包括但不限于账号、密码、信用卡信息等)的一种攻击形式。欺诈网站可以是高度模仿真正网站骗取用户输入账号密码,也可以是含有中奖、博彩、虚假广告等欺诈信息的危害人民群众财产安全的网站。
对于常见的黑名单过滤技术、利用收集欺诈网站作为数据库,然后使用其匹配新网页相似度从而判断欺诈网站的方法,无法有效辨识新类型的欺诈网站,同时又存在系统检测时资源分配不均匀的问题。因此,如何能够有效检测出未记录在黑名单中的欺诈网站,同时能够合理分配资源利用,从而达到避免或减少用户损失的目的,成为欺诈网站检测系统的重点所在。
技术实现要素:
本发明所要解决的技术问题就是提供一种欺诈网站的检测方法,它能既准确又快速地识别未记录在黑名单中的欺诈网站,还能合理分配系统资源。
本发明所要解决的技术问题是通过这样的技术方案实现的,它包括有以下步骤:
步骤1、获取网站统一资源定位符URL;
步骤2、根据获得的网站统一资源定位符URL在系统已有的网站数据库中匹配,网站URL不存在于数据库中,则执行步骤3;若网站存在于数据库中,则结束;
步骤3、检测网站流量排名数值是否大于100万,若获得的网站排名数值大于100万,则执行步骤5;否则,则执行步骤4;
步骤4、检测网站流量排名数值是否大于10万,若获得的网站排名数值大于10万,则执行步骤6;若获得的网站排名数值小于10万,则执行步骤7;
步骤5、通过获取的统一资源定位符URL经过检测域名是否匹配和检测网站标题、检测网站页面内容、检测网站DOM文档对象模型、检测页面图片中存在的欺诈信息,计算安全系数,返回安全系数的结果与所设定排名数值大于100万的阈值比较,将待检测网站分为欺诈网站和可信网站两类,然后执行步骤8;
步骤6、通过检测网站页面内容、检测网站DOM文档对象模型,计算安全系数,返回安全系数的结果与所设定排名数值10万-100万的阈值比较,将待检测网站分为欺诈网站和可信网站两类,然后执行步骤8;
步骤7、通过检测网站页面内容,计算安全系数,返回安全系数与所设定的排名数值小于10万的阈值比较,将待检测网站分为欺诈网站和可信网站两类,然后执行步骤8;
步骤8、根据识别的结果更新网站数据库。
本发明的技术效果:
本发明在步骤2利用已建立的网站数据库,并在步骤5、步骤6和步骤7针对不同流量网站分层次检测,与现有技术中单纯依赖黑白名单和关键词匹配的欺诈网站检测方法相比,提高了欺诈网站检测的准确性,对不同可信度的网站分层次检测,既提高了检测速度,又节省了系统资源。
附图说明
本发明的附图说明如下:
图1为本发明的流程图;
图2为本发明在网站流量排名数值大于100万的判别流程图;
图3为本发明在网站流量排名数值100与10万之间的判别流程图;
图4为本发明在网站流量排名数值小于10万的判别流程图。
具体实施方式
下面结合附图和实施例对本发明作进一步说明:
如图1所示,本发明开始于步骤S10,并获取网站统一资源定位符URL;
当访问网站时,系统获取即将访问的待检测URL(Uniform Resource Locator,网站统一资源定位符),例如,当用户访问、下载互联网资源时,系统会获得即将访问的网络地址的值即为待检测的URL,URL的值不受本发明限制。
步骤S101,根据获得的网站统一资源定位符URL,在系统已有的网站数据库中匹配,若获得的网站URL不存在于数据库中则执行步骤S102;若存在于数据库中,则跳转至步骤S60退出程序;
所述网站数据库由系统不断学习增加得到,网站数据库包含有欺诈网站和可信网站两类,网站数据库中的域名数量等不受本发明专利限制。通过获取待检测网站的URL获取对应域名信息,与欺诈网站中的现有欺诈网站域名进行匹配。获取域名的方法为,通过正则表达式做关键词匹配得到。例如在Linux操作系统中就可以使用grep“.*\{1,15\}\..*\{1,15\}\.[a-z]\{2,8\}”,提取出字符串中的值即为网站域名。
步骤S102,检测网站流量排名数值是否大于100万,若获得的网站排名数值大于100万,则执行步骤S20;否则,则执行步骤S103;
步骤S103,检测网站流量排名数值是否大于10万,若获得的网站排名数值大于10万,则执行步骤S30;若获得的网站排名数值小于10万,则执行步骤S40;
上述步骤S102,S103中网站流量排名数值是通过Alexa排名检测得到,Alexa排名是指网站的世界排名,是一种较为权威的网站访问量评价指标,Alexa每三个月公布一次新的网站综合排名。此排名的依据是用户链接数(Users Reach)和页面浏览数(Page Views)三个月累积的几何平均值。Alexa排名可以较好的说明的网站在互联网中的用户访问情况,对于网站页面内容而言访问量可以间接可以体现一个网站的安全性。
根据待所提取的网站域名获取Alexa排名值。提取域名部分,例如,当网站的URL为:http://www.boc.cn/fimarkets/fund/201603/t20160322_6581374.html,对应的域名则为 boc.cn ,通过获取的Alexa用户接口API查询其Alexa排名:http://data.alexa.com/data/+wQ411en8000lAcli=10&dat=snba&ver=7.0&cdt=alx_vw=20&wid=12206&act=00000000000&ss=1680x1050&bw=964&t=0&ttl=35371&vis=1&rq=4&url=TargetURL,使用脚本程序每次检测将其中的TargetURL替换为要检测的网站域名,例如http://www.boc.cn 根据其返回值中的<REACH RANK="1957"/>可提取出其全球排名值为1957,如果返回的结果为空,则表示网站创建时间较短或未收录,仍属于检测网站流量排名数值大于100万的情况;
若待检测网站的统一资源定位符URL为IP地址形式,例如103.42.31.55,则同样认为其不安全,也按检测网站流量排名数值大于100万的情况处理。
步骤S20,通过获取的统一资源定位符URL经过检测域名是否匹配和检测网站标题、检测网站页面内容、检测网站DOM文档对象模型、检测页面图片中存在的欺诈信息,计算安全系数,返回安全系数的结果与所设定排名数值大于100万的阈值比较,将待检测网站分为欺诈网站和可信网站两类,然后执行步骤S50;
步骤S30,通过检测网站页面内容、检测网站DOM文档对象模型,计算安全系数,返回安全系数的结果与所设定排名数值10万-100万的阈值比较,将待检测网站分为欺诈网站和可信网站两类,然后执行步骤S50;
步骤S40,通过检测网站页面内容,计算安全系数,将返回安全系数与所设定的排名数值小于10万的阈值进行比较,将待检测网站分为欺诈网站和可信网站两类,然后执行步骤S50;
步骤S50,根据识别的结果更新网站数据库;
步骤S60,程序结束。
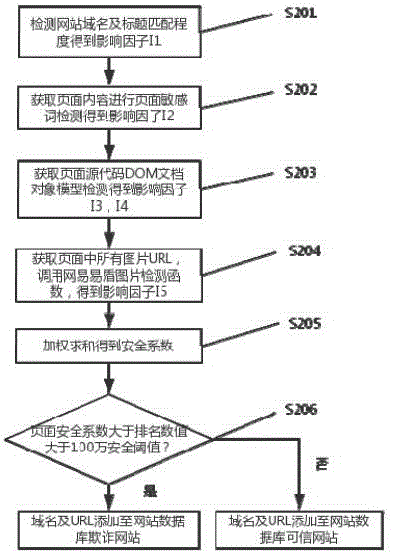
如图2所示,在步骤S20中,在网站流量排名数值大于100万的情况下,判断待检测网站的步骤如下:
步骤S201,检测网站域名与中网可信网站匹配和检测网站标题得到第一影响因子I1;
本步骤中,获取待检测网站域名和网站标题,针对网站域名,利用中网可信网站查询接口查询该域名,根据返回结果与待检测网站域名是否对应确定网站是否可信;如果网站域名为网站可信,则将第一影响因子I1暂时置为0;若返回网站不可信,则将第一影响因子I1暂时置为1;再检测网站标题,网站标题中若存在敏感关键词,则将第一影响因子I1置2;若网站标题中不含有敏感关键词,则影响因子I1保持为刚才得到的数值1或0。
所述中网可信网站查询接口为http://t.knet.cn所提供网站可信度查询用户接口函数,通过提交所需查询网站域名,返回网站的备案信息。获取网页源代码,获取方法例如在linux下就可以使用curl http://www.xx.com/1.html来获得。利用正则表达式匹配获取网站源代码中<title></title>部分中的字符串为网站标题,通过中网可信网站查询接口来查询该URL对应域名的可信度。若查询无返回结果,则认为该网站可疑,存在虚假诈骗欺诈网站的可能;若返回结果备案信息为表示为官方网站,则可以认为是安全网站。根据返回的结果是否为官网且备案将第一影响因子I1暂时置为1或0;同时对网站标题做基于敏感关键词的正则表达式匹配,若在待检测的网站标题中存在如“娱乐城”、“好消息”、“积分兑换”等敏感关键词,则认为该网站页面内容可能遭恶意篡改,则将影响因子I1置2,若网站标题中不含有敏感关键词,则影响因子I1的值为刚检测过后确定的值1或0。
步骤S202,获取所述URL对应网站页面的内容,对页面内容做敏感关键词及含有通配符的混淆敏感关键词匹配,根据页面含有敏感关键词和混淆敏感关键词的数量,将第二影响因子I2置为2,1或0;
所述敏感关键词匹配的方法为:获取页面内容,对源代码中的Unicode编码为中文字符的通过正则匹配编码提取出来,对提取出的词汇做分词处理,所述分词算法为较为常用的基于字符串匹配的算法,使用其双向最大匹配法,双向最大匹配法为正向最大匹配算法和逆向最大匹配算法进行综合得到的;
正向最大匹配算法为:进行对字符由左到右、由右到左两次扫描取得待切分语句中的最大4个字符,使用增加欺诈网站敏感关键词汇的大机器字典进行匹配,若匹配成功则将这个匹配的到的字符串作为一个词汇切分出来,若匹配不成功,则将这个匹配字符串的前面一个词去掉,剩下作为新的字符串继续匹配,直到换分出所有的词为止;逆向最大匹配算法为正向最大匹配的逆向算法,具体方法类似;所述大机器字典可在各大开源社区获得,具体的字典内容不受本发明限制;
对得到分词后的网页分词字典进行字符串匹配,匹配的关键词为“中奖”、“赠送”、“老虎机”,“获奖”,“积分兑换”等,同时为了应对欺诈网站中的“中。奖”、“场外a幸运”“观众”、“真 人真 钱”等避免关键词检测的情况,在关键词报警数据库中加入“中*奖”、“账*号”等含有通配符形式的字符串,进行混淆关键词匹配。当页面中的敏感关键词数量少于关键词报警阈值时,第二影响因子I2置0;当页面中的敏感关键词数量大于关键词报警阈值时,则将第二影响因子I2置1;若含有混淆敏感关键词的数量大于混淆关键词报警阈值,则将第二影响因子I2置2。
步骤S203,获取网站页面访问页面的源代码,利用正则表达式提取出DOM文档对象模型中的所有站外信息,将提取出的非本域名的URL进行网站流量排名检测,当排名数值超过100万的URL数量占提取出的总的URL的比例超过站外URL比例阈值时,将第三影响因子I3置1,否则置0。所谓站外URL是指本页面中指向非本页面资源的URL;检测页面中所含有的信息输入框的数量及对应的名称,若含有信息输入框,同时信息输入框的名称为敏感关键词,则将第四影响因子I4置1,否则置0;
本步骤中,通过获取的网站页面的源代码,提取出页面中所有的链接信息,以及页面中是否含有用户输入信息的输入框及含有的输入框的数量和输入框的名称。具体为,获取页面中所有的链接,使用正则表达式提取<a href=””></a>中所有的“http://xxx.xxx.xxx”信息,并将获取的URL使用Alexa排名检测模块查看其全球排名,如果排名大于100万的域名超过站外URL比例阈值,则将第三影响因子I3置1。同时获取页面内所有的表单信息,提取页面中所有的<form></form>代码,若没有<form></form>代码,则表示不含有用户输入信息部分;若含有该部分代码,则表示网站有需要用户提交数据的区域,接下来进一步检测<form></form>代码中是否含有敏感关键词,比如“姓名”、“手机号”、“身份证号”、“银行卡号”、“账号”、“密码”等词,若含有,则表示页面需要用户提交个人隐私信息,可能含有欺诈风险,则将第四影响因子I4置1。
步骤S204,获取网站页面中所有的图片URL,调用网易易盾的图片检测接口函数,传入页面中所有图片的地址,根据返回数据中的分类信息得到页面图片中含有的广告和欺诈类型图片的比例,该值与页面非法图片比例阈值相比较,超过该阈值则将第五影响因子I5置1,否则置0;
所述获取图片的URL地址,为使用正则表达式匹配并提取页面中所有含有 .jpg |.bmp|.png等格式的链接;所述网易易盾图片检测服务,利用正则表达式获取待检测网站中的所有图片的URL,使用网易易盾提供的图片检测服务,接口函数调用地址:https://api.aq.163.com/v2/image/check,利用程序在代码中的imageurl处的“name”及“data”参数处自动添加网页中图片的地址,根据返回的数据中的result参数中的label分类信息:100:色情,200:广告,300:暴恐,400:违禁,500:涉政,来判断页面中的涉及的五种类型的图片的数量,涉嫌五种情况的图片数量与总图片数目的比值,定为欺诈类型图片的比例。
步骤S205,根据获得的五个影响因子,加权求和得到安全系数;
步骤S206,将步骤S205计算得到的安全系数与排名数值大于100万安全阈值相比较,把待检测网站分为欺诈网站和可信网站两类。
如图3所示,在步骤S30中,网站流量排名数值在10-100万之间的情况下,判断待检测网站的步骤如下:
步骤S301,获取所述URL对应网站页面的内容,对页面内容做敏感关键词及含有通配符的混淆敏感关键词匹配,根据页面含有敏感关键词和混淆敏感关键词的数量,将第二影响因子I2置为2,1或0;
本步骤中与步骤S202相同。
步骤S302,获取网站页面访问页面的源代码,利用正则表达式提取出DOM文档对象模型中的所有站外信息,将提取出的非本域名的URL进行网站流量排名检测,当排名数值超过100万的URL数量占提取出的总的URL的比例超过站外URL比例阈值时,第三影响因子I3置1,否则置0。检测页面中所含有的信息输入框的数量及对应的名称,若含有信息输入框,同时信息输入框的名称为敏感关键词,则将第四影响因子I4置1,否则置0;
本步骤与步骤S203相同。
步骤S303,根据步骤S301所得的第二影响因子I2和步骤S302所得的第三影响因子I3、第四影响因子I4,加权求和得到安全系数;
步骤S304,将步骤S303计算得到的安全系数与排名数值10万-100万安全阈值相比较,把待检测网站分为欺诈网站和可信网站两类。
如图4所示,在步骤S40中,网站流量排名数值小于10万的情况下,判断待检测网站的步骤如下:
步骤S401,获取所述URL对应网站页面的内容,对页面内容做敏感关键词及含有通配符的混淆敏感关键词匹配,根据页面含有敏感关键词和混淆敏感关键词的数量,将第二影响因子I2置为2,1或0;
本步骤中与步骤S202相同。
步骤S402,将步骤S401计算得到的第二影响因子I2加权计算后作为安全系数;
步骤S403,将步骤S402计算得到的安全系数与排名数值小于10万的安全阈值相比较,把待检测网站分为欺诈网站和可信网站两类。
本发明中的阈值和权重由每个阈值的判定模型决定,它们的具体值需要经过大量欺诈网站和正常网站样本的统计获得:
所述关键词报警阈值为,通过将页面的源代码中的中文字符提取出来,提取原则为匹配Unicode编码为“\u4e00-\u9fa5”的中文字符,然后对提取出的字符串做分词处理,所述分词算法为较为常用的基于字符串匹配的算法,使用其双向最大匹配法,进行对字符由左到右、由右到左两次扫描,得到分词后的网页分词字典。对得到的网页分词字典做字符串匹配。本发明中根据样本的计算结果将关键词报警阈值中的敏感关键词比例设定为10%,将混淆敏感关键词的比例设定为5%。
所述站外URL比例阈值为,通过获取的页面源代码,利用正则表达式匹配提取出所有的URL链接信息,对所得的URL做提取出其中的域名,并去掉重复和自身的域名和html代码头部的http://www.w3.org,对所得到的域名做Alexa的网站排名查询。通过样本分析统计,本发明中将站外URL比例阈值设为30%。
所述页面非法图片比例阈值为,通过比较涉嫌欺诈信息的图片数目与总的图片数目得到的临界值,通过样本分析统计,本发明中将页面非法图片比例阈值设为30%。
所述排名数值大于100万阈值为2,排名数值10万-100万阈值为2,排名数值小于10万阈值为1。当检测过程返回的安全系数的结果大于阈值时,则表明网站可能存在潜在风险。
根据待检测网站的各个检测分支的影响因子,对待检测网站的安全系数的计算包括具体包括 :所述第一影响因子I1、第二影响因子I2、第三影响因子I3、第四影响因子I4和第五影响因子I5 分配对应的权重,获取第一影响因子I1、第二影响因子I2、第三影响因子I3、第四影响因子I4和第五影响因子I5与对应权重乘积的累加值;若所述求得累加值大于预设欺诈网站判断阈值,则判定所述待检测网站为欺诈网站。
具体地,例如为第一影响因子I1分配第一权重值 w1、为第二影响因子I2分配第二权重值 w2、为第三影响因子I3 分配第三权重值 w3、为第四影响因子I4 分配第四权重值 w4、为第五影响因子I5分配第五权重值 w5,则该影响因子的累加值为 w1×I1+w2×I2+w3×I3+w4×I4+ w5×I5。 将该特征累加值与一个预设阈值相比较,若得到的该特征累加值大于预设阈值,则判定所述待检测网站为可能存在欺诈信息的欺诈网站等,若小于或等于预设阈值,则判定所述待检测网站不为欺诈网站。
其中,第一权重值 w1、第二权重值 w2、第三权重值 w3、第四权重值 w4、第五权重值 w5均大于0且小于等于 1,且第一权重值w1、第二权重值 w2、第三权重值w3、第四权重值 w4、第五权重值 w5以及各个参数比较所预设阈值均由数值判定模型提供。在本实施例中,各影响因子的所有权重定为1。
- 还没有人留言评论。精彩留言会获得点赞!