专家库建立办法和装置的制作方法
本发明涉及专家库的建立。
背景技术:
专家是特定领域有卓越表现和高度专业能力的个人。一方面,专家可以在科技项目开发中起到重要的作用,另一方面,很多评审等活动需要专家的参与,例如招标等。实际上,2003年发改委还专门制定了《评标专家和评标专家库管理暂行办法》。但是目前所建立的专家数据库要么局限在人员手工的收集,要么是专家自己的报名。现有技术中,没有好的办法根据大量的信息(例如互联网信息)或大的总库中寻找特定专家的办法。
技术实现要素:
本发明针对现有技术的以上缺点做出,用以克服现有技术的一个或更多个缺点,至少提供一种有益的选择。
根据本发明的一个方面,提供了一种专家库建立方法,包括以下步骤:样本收集步骤,收集特定领域的专家样本,包括专家的论文、专利和项目,形成训练集;专家分类模型建立步骤,根据训练库建立专家模型;直接专家识别步骤,利用所建立的专家模型,对全部待分类专家进行识别和分类,判断其是否属于所述特定领域的专家;合作专家识别步骤,根据待分类专家与所述特定领域的专家的合作度确定待分类专家是否属于领域专家。
根据本发明的另一方面,提供了一种专家库建立装置,包括:专家样本收集装置,收集特定领域的专家样本,包括专家的论文、专利和项目,形成训练集;专家分类模型建立装置,根据训练库建立专家分类模型;直接专家识别装置,利用所建立的专家分类模型,对全部待分类专家进行识别和分类,判断其是否属于所述特定领域的专家;合作专家识别装置,根据待分类专家与所述特定领域的专家的合作度确定待分类专家是否属于所述特定领域的专家。
根据本发明的实施方式,可以快速而准确地建立专家库。
附图说明
附图仅仅是示例性的,不是对本发明的保护范围的限制。
图1示出了依据本发明的一种实施方式的专家库建立方法的流程图。
图2示出了依据本发明的另一种实施方式的专家库建立方法的流程图。
图3示出了依据本发明的一种实施方式的专家库建立装置的示意图。
具体实施方式
下面结合附图对本发明的具体实施方式进行描述,对本发明的以下描述仅仅是为了本领域技术人员能够实现本发明,不是对本发明的保护范围的限制。
图1示出了依据本发明的一种实施方式的专家库建立方法的流程图。如图1所示,首先在步骤101中进行专家样本收集。收集特定领域的专家的样本,包含该专家所作的论文、专利、项目。这些样本可被分为训练集和测试集。训练集用于建立专家模型,测试集用于测试和改进专家模型。根据本发明的一种实施方式,训练集中的样本数目是测试集中的样本数目的4.5倍到9倍。另外,根据本发明的一种实施方式,将训练集分为论文训练集、专利训练集和项目训练集。将测试集分为论文测试集、专利测试集和项目测试集。训练集中出现的样本被称为训练语料。测试集中的出现的样本被称为测试语料。
接着在步骤102,构建专家分类模型。该步骤可以分为专家分类模型构建步骤1021和专家分类模型修正步骤1022。在专家分类模型构建步骤中,利用训练集构建专利分类模型。在专家分类模型修正步骤中,利用测试集对专家分类模型进行测试,并调整参数,得到错判、漏判率都较低的模型。
根据本发明的一种实施方式,专家分类模型构建步骤中,利用向量空间模型来表达文本。将文档转化为m维词条空间中的一个向量d=(W1,W2,W3…Wm)T,其中Wi为向量在第i个词条上的权重。根据一种实施方式,依据以下公式计算各词条的权重:
其中,w(t,d)为词条t在文本d中的权重,tf(t,d)为词条t在文本d中的词频,N为训练文本的总数,nt为训练文本中出现t的文本数。根据本发明的一种实施方式,对于2008年之后的专利文件,tf(t,d)另外乘以1.1到1.5之间的系数,对于2002年之前的专利文献,tf(t,d)另外乘以0.8到0.95之间的系数。该系数的大小根据专利所涉及的技术领域确定。
根据本发明的一种实施方式,利用文档频率法进行特征选择。词条的文档频率是指在训练语料中出现该词条的文档数。将文档频率小于预定义阈值的低频词从原始向量空间中移除。依据本发明的一种实施方式,低频词为在所有训练语料中出现该词条的文档数低于第一阈值,并且在近3年的训练语料中,出现该词条的文档数低于第二阈值。依据该实施方式,可以避免将新出现的边缘学科的专家排除在外。另外依据本发明的一种实施方式,包括新词确认步骤。在该步骤中,对于这样的低频词,即3年前的所有训练语料中均未出现,但是在近3年的训练语料中有第三阈值的文档中出现该词的,进行提示,由创建专家库的人员确认是否列入低频词。
根据本发明的一种实施方式,采用SVM方法作为分类器算法。
依据本发明一种实施方式,SVM利用公式2作为分类函数,并以公式3为约束条件。
yi[(ω·xi)+b]-1≥0,i=1,2,...,n (3)
其中,ω为间隔系数。所述间隔是指该最优分类面到最近样本的距离,即2/||ω||。分类线方程为y=xω+b,(xi,yi)表示样本坐标,i=1,2,...,n,x∈Rd,y∈{+1,-1}。αi为每个约束条件(公式3)对应的Lagrange乘子。b*是分类阈值,可以用任一个支持向量(满足公式3中的等号)求得。
应该注意,以上的描述均为示意性的,并不是对本发明的限制,受益于本发明的技术人员可以想到用其他的方法,例如回归模型法、最近邻分类法、朴素贝叶斯分类法、决策树法、规则学习算法、相关反馈法、选举分类法、神经网络法、纠错输出编码法、最大熵法、休眠专家法等作为分类其的算法。
进一步,在步骤103,利用所建立的专家模型,对全部待分类专家进行识别和分类,判断其是否属于该特定领域的专家。根据一种实施方式,将待分类专家的论文、专利或项目与专家库模型进行比对,如果距离小于阈值,则可判断该专家为该领域专家,并将其并入该专家库。
根据一种实施方式,专家模型还分为专利子模型、论文子模型、项目子模型。待分类专家与总模型之间的距离小于所述阈值时,还进一步与各子模型进行比对,与任一子模型之间的距离小于特定阈值时即可认为该专家属于该领域专家。
进一步,在步骤104,计算剩余待分类专家中各专家的合作度。剩余待分类专家即全部待分类专家去除在步骤103中已经被确定为该领域专家的专家之后剩余的专家。将专家之间的关系分为一度合作关系、N度合作关系(一般取N为大于等于2小于等于5)以及无合作关系。具有直接合作关系的专家,例如论文的共同作者、专利的发明人、项目的共同参与者为一度合作关系。具有间接合作关系的专家,例如论文X(一度合作文本)的共同作者为A、B,论文Y(二度合作文本)的共同作者为B、C,则A与C之间通过一个连接人B而发生关联,成为二度合作关系。如果C进一步与D合作发表了论文Z(三度合作文本),则A与D之间的关系为三度合作关系,依次类推。合作关系可以根据全专家数据库、全论文数据库等获得。
根据一种实施方式,待分类专家与已识别出的领域专家之间的合作度如下地进行计算:
首先计算已识别出的领域专家中与待分类专家为一度合作者的人数,以及一度合作的论文、专利、项目以及它们的数量,即合作次数。根据合作次数确定一度合作权重系数j1,合作的次数越多,一度合作权重系数j1越大,例如可以对各次合作进行求和。根据一种实施方式,还根据合作的论文、专利、项目的质量调整各次合作权重系数。即计算所合作的论文、专利、项目与专家分类模型之间的距离,距离越小,各次一度合作权重系数越大。
同样地,计算已识别出的领域专家中与待分类专家为二度合作者的人数,以及二度合作的论文、专利、项目以及数量,即合作次数。然后计算二度合作权重系数j2。合作的次数越多,二度合作权重系数j2越大,例如可以对各次合作进行求和。根据一种实施方式,正对每次二次合作,还根据合作的论文、专利、项目的质量调整合作权重系数。即计算出一度合作的论文、专利、项目(一度合作文本)与专家分类模型之间的距离,以及该二度合作文件与专家分类模型之间的距离,并计算综合距离,距离越小,每次的二度合作权重系数越大。综合距离为考虑一度合作论文的权重调节系数和二度合作论文的权重调节系数之后得到的距离。
对于单次合作,一度合作权重系数大于二度合作系数。
根据具体情况,可以确定一直计算到几度合作关系。但一般来说,计算到4度合作关系就可以了。
然后根据所计算出的合作人数和合作权重系数,计算合作度。
例如合作度H=所有的一度合作系数j1和所有的二度合作系数j2的和。
然后,在步骤105,将合作度大于阈值的专家加入到该领域的专家库中。
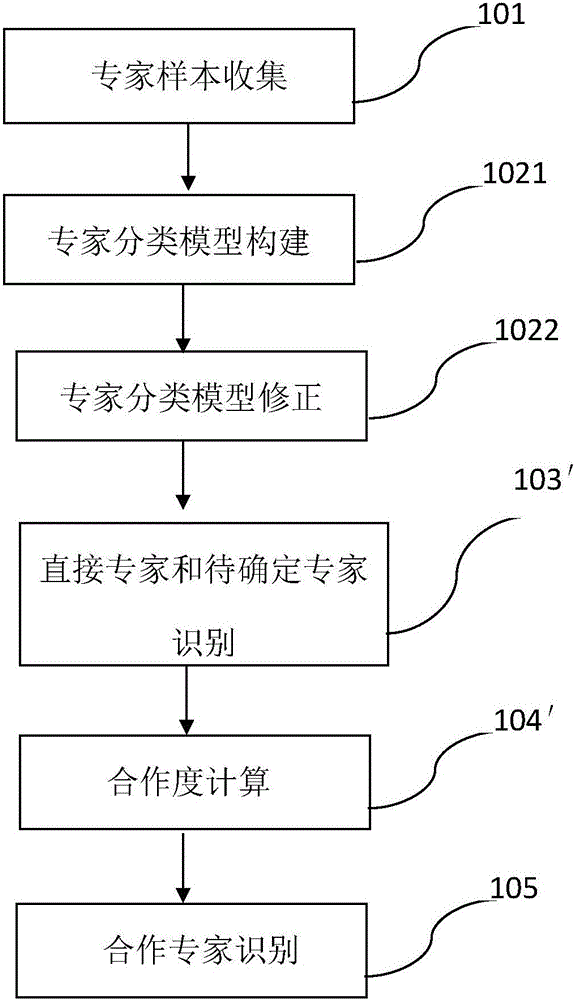
图2示出了依据本发明的另一种实施方式的专家库建立方法的流程图。
图2所示的专家库建立方法与图1所示的专家库建立方法基本相同。不同之处在于,在步骤103′处,不但与图1所示的步骤103相同,利用所建立的专家模型,对全部待分类专家进行识别和分类,判断其是否属于特定的某个领域的专家;还同时确定待进一步确认专家。即将待分类专家的论文、专利或项目与专家库模型进行比对,如果距离小于第一阈值,则可判断该专家为该领域专家,并将其并入该专家库。如果距离虽然大于第一阈值但是小于第二阈值,则将其列为待进一步确认专家。
在步骤104′,仅仅针对待确认专家而不是针对所有的剩余专家,进行合作度计算。
下面描述本发明的专家库建立装置,可以参考上文对方法的描述来理解本发明的装置。
图3示出了依据本发明的一种实施方式的专家库建立装置的示意图。如图3所示,依据本发明的一种实施方式的专家库建立装置,包括:专家样本收集装置31,收集特定领域的专家样本,包括专家的论文、专利和项目,形成训练集;专家分类模型建立装置32,该专家分类模型建立装置32包括专家分类模型构建装置321,用于根据训练库建立专家分类模型;直接专家识别装置33,利用所建立的专家分类模型,对全部待分类专家进行识别和分类,判断其是否属于所述特定领域的专家;合作度计算装置34,确定待分类专家与所述特定领域的专家的合作度;以及合作专家识别装置35,根据待分类专家与所述特定领域的专家的合作度确定待分类专家是否属于所述特定领域的专家。
根据一种实施方式,专家样本收集装置31还收集该特定领域的专家样本来形成测试集,所述专家分类模型建立装置32还包括专家分类模型修正装置322,专家分类模型修正装置322使用所述测试集对所述专家分类模型进行测试和修正。
根据一种实施方式,所述合作专家识别装置包括:一度合作者确定装置,计算已识别出的所述特定领域专家中与待分类专家为一度合作者的人数,一度合作的论文、专利、项目以及其数量,即一度合作次数;一度合作权重系数确定装置,针对各一度合作者,根据所述一度合作的论文、专利、项目以及所述一度合作次数,确定各一度合作者的权重系数;二度合作者确定装置,计算已识别出的所述特定领域专家中与待分类专家为二度合作者的人数,二度合作的论文、专利、项目以及其数量,即二度合作次数;二度合作权重系数确定装置,针对各二度合作者,根据所述一度合作的论文、专利、项目以及所述二度合作次数,所述二度合作的论文、专利、项目以及所述合作次数确定各二度合作者的权重系数,合作度计算装置,根据各所述一度合作者的权重系数和各所述二度合作者的权重系数计算各待分类专家与所述特定领域的专家的合作度。
根据一种实施方式,在所述一度合作权重系数装置中,根据合作次数确定一度合作权重系数j1,合作的次数越多,一度合作权重系数j1越大,还根据合作的论文、专利、项目的质量调整各次合作权重系数,即计算所合作的论文、专利、项目与专家分类模型之间的距离,距离越小,该次一度合作权重系数越大。
根据一种实施方式,在所述二度合作权重系数确定装置中,二次合作的次数越多,二度合作权重系数j2越大,还根据一度合作的论文、专利、项目的质量、二度合作论文的质量调整每次二度合作的二次合作权重系数。
根据一种实施方式,在所述二度合作权重系数确定装置中,计算一度合作的论文、专利、项目与专家分类模型之间的距离,以及该二度合作的论文、专利、项目与专家分类模型之间的距离,并计算综合距离,距离越小,则该次二度合作权重系数越大,综合距离为考虑一度合作论文的权重调节系数和二度合作论文的权重调节系数之后得到的距离。
根据一种实施方式,专家分类模型建立装置包括利用文档频率法进行特征选择的装置:将文档频率小于预定义阈值的低频词从原始向量空间中移除,所述低频词为在所有训练集的样本中出现该词条的文档数低于第一阈值,并且在近3年的训练集的样本中,出现该词条的文档数低于第二阈值。
根据一种实施方式,所述利用文档频率法进行特征选择的装置包括新词确认步骤:对于这样的低频词,即3年前的所有训练集的样本中均未出现,但是在近3年的训练集的样本中有大于第三阈值的样本中出现该词的,进行提示,由所述方法的使用者确认是否列入低频词。
根据一种实施方式,所述专家分类模型建立装置还包括:使用向量空间模型来表达文本的装置,以及采用SVM方法进行分类的装置;其中,在使用向量空间模型来表达文本时,将文档转化为m维词条空间中的一个向量d=(W1,W2,W3…Wm)T,其中Wi为向量在第i个词条上的权重并依据以下公式计算各词条的权重:
其中,w(t,d)为词条t在文本d中的权重,tf(t,d)为词条t在文本d中的词频,N为训练文本的总数,nt为训练文本中出现t的文本数,对于2008年之后的专利文件,tf(t,d)另外乘以1.1到1.5之间的系数,对于2002年之前的专利文献,tf(t,d)另外乘以0.8到0.95之间的系数。该系数的大小根据专利所涉及的技术领域确定;
所述SVM方法利用公式2作为分类函数,并以公式3为约束条件,
yi[(ω·xi)+b]-1≥0,i=1,2,...,n (3)
其中,ω为间隔系数,所述间隔是指该最优分类面到最近样本的距离,即2/||ω||,分类线方程为y=xω+b,(xi,yi)表示样本坐标,i=1,2,...,n,y∈{+1,-1}。αi为每个约束条件对应的拉格朗日乘子,b*是分类阈值,能够通过满足公式3中的等号而求得。
应该理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因而,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。此外,本发明的权利要求旨在涵盖落入权利要求范围和边界或者这种范围和边界的等同形式内的全部变型和改进。
- 还没有人留言评论。精彩留言会获得点赞!