一种基于高斯混合模型和变分贝叶斯的粒子滤波方法与流程
本发明涉及信号处理领域,具体涉及一种基于高斯混合模型和变分贝叶斯的粒子滤波方法。
背景技术:
粒子滤波通过非参数化的蒙特卡洛模拟方法来实现递推贝叶斯滤波,适用于任何能用状态空间模型描述的非线性系统,精度可以逼近最优估计。粒子滤波器具有简单、易于实现等特点,它为分析非线性动态系统提供了一种有效的解决方法,从而引起目标跟踪、信号处理以及自动控制等领域的广泛关注。粒子滤波的状态空间模型可描述为:
xk=f(xk-1)+uk
yk=h(xk)+vk
其中f(·),h(·)分别为状态转移方程与观测方程,xk为系统状态,yk为观测值,uk为过程噪声,vk为观测噪声。观测噪声vk通常被假设为零均值高斯白噪声信号,但是实际上vk是非高斯特征的,在通信、导航、声呐、雷达及生物医学等领域中都存在着典型的非高斯噪声环境,如低频大气噪声、水声信号、生物医学中的心电信号。基于高斯噪声模型的信号处理方法在非高斯环境下工作性能会遭受很大损失,甚至无法工作。如果能够辩识非高斯噪声的统计特性并加以利用,则能大幅提高信号处理性能,基于以上缺点,本方法提出一种高斯混合模型(Gaussian Mixture Models,GMM)和变分贝叶斯(Variational Bayesian,VB)的改进的粒子滤波方法,使用多个高斯分布的加权和来逼近真实的观测噪声,从而提高粒子滤波的精度和性能,高斯混合模型可描述为
其中J表示高斯混合模型的高斯项数,αk,j表示在时刻k高斯项j的系数,表示均值为μk,j,协方差为的高斯分布。由于多个高斯分布带来多个参数导致模型复杂且难以求解,本方法利用变分贝叶斯学习方法对含有隐变量的混合高斯模型进行参数估计。变分贝叶斯是在平均场假设下,对每一个参数分布q,用带超参数的先验分布改写参数分布p(x,z),得到相同形式的后验分布,迭代循环求解,变分贝叶斯学习在较好估计精度的前提下有更快的估计速度,更适合于有实时性要求的工程应用领域。
技术实现要素:
本发明的目的是针对上述现有技术的不足,提供了一种基于高斯混合模型和变分贝叶斯的粒子滤波方法。
本发明的目的可以通过如下技术方案实现:
一种基于高斯混合模型和变分贝叶斯的粒子滤波方法,所述方法包括以下步骤:
1、对观测噪声使用高斯混合模型进行建模,初始化初始状态的概率密度函数p(x0),高斯混合模型公式为:
其中J表示高斯混合模型的高斯项数,αk,j表示在时刻k高斯项j的权重系数,表示均值为μk,j,协方差为的高斯分布;
2、基于初始状态的概率密度函数p(x0),随机产生N个初始粒子,N作为计算量和估计精度之间的权衡;
3、初始化观测噪声的高斯混合模型中的未知参数Ψk的超参数λ0,β0,m0,Σ0以及v0,下标0表示初始化值;
4、对T个时刻进行步骤5)至步骤8)的迭代操作;
5、从重要性参考函数生成N个采样粒子选用是先验概率密度函数,从粒子滤波的状态转移方程xk=f(xk-1)+uk中得到;
6、量测更新,根据最新观测值和权值公式计算每个粒子的权值
7、使用变分贝叶斯学习方法通过循环迭代的方法求出高斯混合模型中未知参数的分布,包括以下步骤:
变分贝叶斯期望步骤:隐变量β,m,Σ以及v分布的参数Nk,j、Sk,j参照下式进行更新:
变分贝叶斯最大化步骤:隐变量β,m,Σ以及v按照下式进行更新:
变分贝叶斯期望步骤和变分贝叶斯最大化步骤交替进行,随着迭代的不断重复,变分下限L(q)逐渐增大,直到|L(t+1)(q)-L(t)(q)|<ε,迭代终止,ε是设置的误差限;
8、对粒子权值进行归一化,并针对粒子退化的问题,对粒子集进行重采样:重采样对低权重粒子进行剔除,同时保留高权重粒子。
优选的,所述步骤1具体包括以下步骤:
1.1、预先设定观测噪声的动态空间模型为:
xk=f(xk-1)+uk
yk=h(xk)+vk
其中f(·),h(·)分别为状态转移方程与观测方程,xk为系统状态,yk为观测值,uk为过程噪声,过程噪声uk被假设为零均值、协方差为Qk的高斯白噪声信号,vk为观测噪声,uk和vk是相互独立的,在处理目标跟踪问题时,假设目标的状态转移过程服从一阶马尔可夫模型,即当前时刻的状态xk只与上一时刻的状态xk-1有关,另外假设观测值相互独立,即观测值yk只与k时刻的状态xk有关;
1.2、假设已知k-1时刻的概率密度函数为p(xk-1|Yk-1),其中p(.)指状态的概率密度函数,p(·|·)是指状态的后验概率密度函数,贝叶斯滤波的具体过程如下:
一、预测过程,由p(xk-1|Yk-1)得到p(xk|Yk-1):
p(xk,xk-1|Yk-1)=p(xk|xk-1,Yk-1)p(xk-1|Yk-1)
当给定xk-1时,状态xk与Yk-1相互独立,因此:
p(xk,xk-1|Yk-1)=p(xk|xk-1)p(xk-1|Yk-1)
上式两端对xk-1积分,可得:
p(xk|Yk-1)=∫p(xk|xk-1)p(xk-1|Yk-1)dxk-1
二、更新过程,由p(xk|Yk-1)得到p(xk|Yk):获取k时刻的测量yk后,利用贝叶斯公式对先验概率密度进行更新,得到后验概率密度函数:
假设yk只由xk决定,即:
p(yk|xk,Yk-1)=p(yk|xk)
因此:
其中,p(yk|Yk-1)为归一化常数:
p(yk|Yk-1)=∫p(yk|xk)p(xk|Yk-1)dxk
1.3、根据极大后验准则或最小均方误差准则,将具有极大后验概率密度的状态或条件均值作为系统状态的估计值。
优选的,所述步骤3具体包括以下步骤:
3.1、根据观测噪声的高斯混合模型,对于每一个观测值引入一个隐变量Z,定义Z={z1,z2,…,zS},zs为S维变量,满足zs∈{0,1}而且即隐变量zs中有且仅有一位为1,其他位置都为0,如果zs,j=1,表示第s个观测噪声是由第j个高斯混合模型产生的;
3.2、由隐变量Z的条件概率密度函数p(zs|αk)以及带有隐变量且每个观测样本独立同分布的混合高斯模型概率密度函数p(vk|zs,μk,Λk)表示为:
其中,αk=[αk,1,αk,2,…,αk,J],μk=[μk,1,μk,2,…,μk,J],Λk=[Λk,1,Λk,2,…,Λk,J],Ψk=[αk,μk,Λk,Z]。
优选的,所述步骤6具体包括以下步骤:
6.1、对粒子重采样后,有k-1时刻第i个粒子的权重并且由于权值更新公式简化成
6.2、表示在状态x出现的条件下,测量y出现的概率;由系统状态方可知,测量值就是在真实值附近添加观测噪声,观测噪声的分布通过变分贝叶斯学习得到。
优选的,所述步骤7具体包括以下步骤:
7.1、根据平均场理论高斯混合模型参数的联合概率密度函数q(Ψk)通过参数和潜在变量的划分因式分解,如下所示:
上式中所有的未知的模型参数被假设为独立的,将每一个隐变量划分看成是一个单体,其他划分对其的影响看作是其自身的作用,采用迭代的方法,当变分自由能取得最大值的时候,Ψi与它的互斥集Ψ-i具有如下关系:
每个因子q(Ψi)取决于剩余因子q(Ψj),i≠j,因子初始化,每个因子迭代更新循环增加边缘似然函数的下界直到收敛;
7.2、由于共轭指数模型的性质,权重参数α以及均值μ和方差Λ的后验概率密度分布被定义为:
其中λk,j,βk,j,mk,j,Σk,j,νk,j是高斯混合模型的后验概率密度分布的超参数;Dir(·)表示狄里克利分布,表示高斯分布,表示威沙特分布;
7.3、根据固定分布的参数βk,j,mk,j,Σk,j,νk,j,计算得到隐变量的分布参数γs,j;最新得到的γs,j保持不变,根据下面的参数更新公式更新参数Nk,j,Sk,j:其中表示k时刻第s个样本的观测值,表示k时刻第s个样本的真实值;
根据参数Nk,j,Sk,j按照下面的公式更新参数βk,j,mk,j,Σk,j,νk,j:
如此迭代计算,至变分自由能量F(Ψk)最大,即对数边缘似然函数的下界最大,得到混合高斯模型的变分贝叶斯学习参数估计:每次迭代之后计算下界的变化值,记作ΔF,当该值低于预先设定的近似小量时,认定该算法已经趋于收敛,得到足够逼近原分布的近似分布。
本发明与现有技术相比,具有如下优点和有益效果:
1、本发明使用高斯混合模型来对观测噪声进行建模,使用多个高斯分布的加权和来逼近真实的观测噪声,提高了粒子滤波的精度和性能。
2、本发明使用了变分贝叶斯方法来估计未知的噪声参数,用带超参数的先验分布改写概率密度函数p(x),得到相同形式的后验分布,迭代循环求解,变分贝叶斯方法提供了一种局部最优,但具有确定解的近似后验方法。
3、本发明的改进粒子滤波方法,能够增强粒子权值的准确性以及粒子的多样性,有效提高了目标状态的估计性能,解决了非线性非高斯情况下目标状态的滤波问题。
附图说明
图1为本发明基于高斯混合模型和变分贝叶斯的粒子滤波方法的流程图。
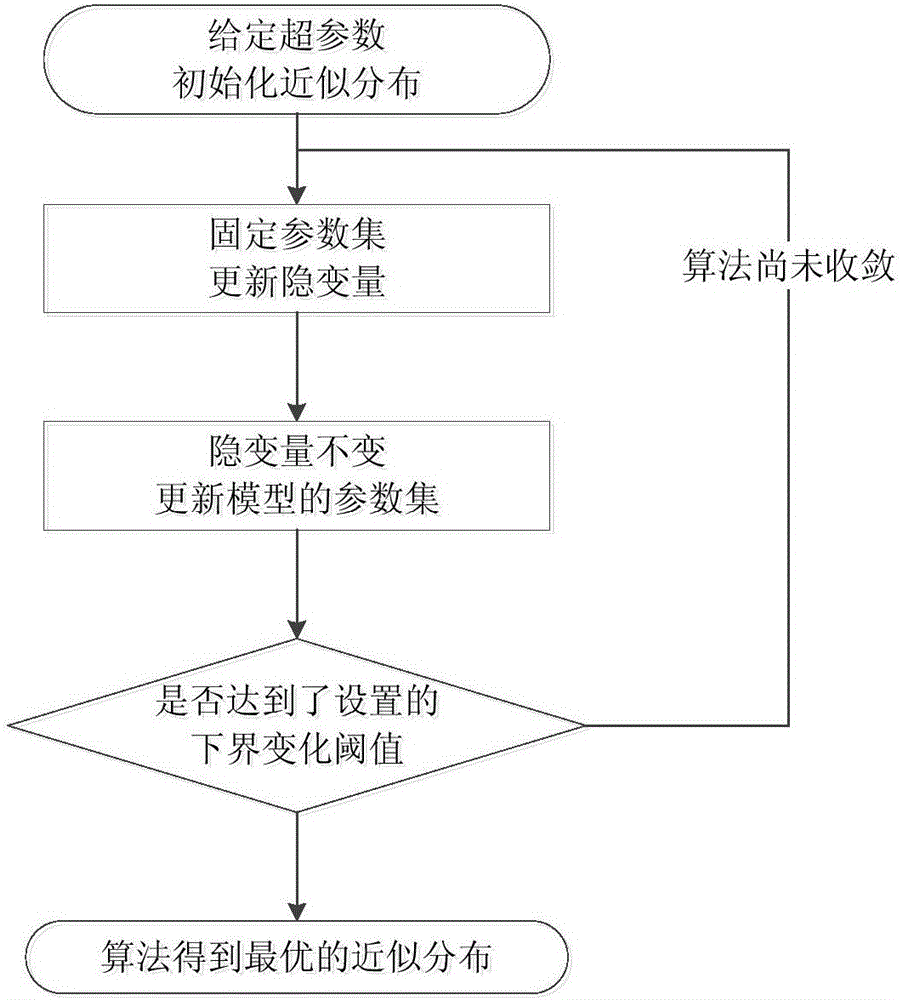
图2为本发明高斯混合模型的变分贝叶斯学习算法流程图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例:
本实施例提供了一种基于高斯混合模型和变分贝叶斯的粒子滤波方法,如图1的流程图所示,所述方法包括以下步骤:
1、对观测噪声使用高斯混合模型进行建模,初始化初始状态的概率密度函数p(x0),高斯混合模型公式为:
其中J表示高斯混合模型的高斯项数,αk,j表示在时刻k高斯项j的权重系数,表示均值为μk,j,协方差为的高斯分布;
2、基于初始状态的概率密度函数p(x0),随机产生N个初始粒子,N作为计算量和估计精度之间的权衡;
3、初始化观测噪声的高斯混合模型中的未知参数Ψk的超参数λ0,β0,m0,Σ0以及v0,下标0表示初始化值;
4、对T个时刻进行步骤5)至步骤8)的迭代操作;
5、从重要性参考函数生成N个采样粒子选用是先验概率,从粒子滤波的状态转移方程xk=f(xk-1)+uk中得到;
6、量测更新,根据最新观测值和权值公式计算每个粒子的权值
7、使用变分贝叶斯学习方法通过循环迭代的方法求出高斯混合模型中未知参数的分布,如图2所示,为本发明高斯混合模型的变分贝叶斯学习算法流程图,包括以下步骤:
变分贝叶斯期望步骤:隐变量β,m,Σ以及v分布的参数Nk,j、Sk,j参照下式进行更新:
变分贝叶斯最大化步骤:隐变量β,m,Σ以及v按照下式进行更新:
变分贝叶斯期望步骤和变分贝叶斯最大化步骤交替进行,随着迭代的不断重复,变分下限L(q)逐渐增大,直到|L(t+1)(q)-L(t)(q)|<ε,迭代终止,ε是设置的误差限;
8、对粒子权值进行归一化,并针对粒子退化的问题,对粒子集进行重采样:重采样对低权重粒子进行剔除,同时保留高权重粒子。
其中,所述步骤1具体包括以下步骤:
1.1、预先设定观测噪声的动态空间模型为:
xk=f(xk-1)+uk
yk=h(xk)+vk
其中f(·),h(·)分别为状态转移方程与观测方程,xk为系统状态,yk为观测值,uk为过程噪声,过程噪声uk被假设为零均值、协方差为Qk的高斯白噪声信号,vk为观测噪声,uk和vk是相互独立的,在处理目标跟踪问题时,假设目标的状态转移过程服从一阶马尔可夫模型,即当前时刻的状态xk只与上一时刻的状态xk-1有关,另外假设观测值相互独立,即观测值yk只与k时刻的状态xk有关;
1.2、假设已知k-1时刻的概率密度函数为p(xk-1|Yk-1),其中p(.)指状态的概率密度函数,贝叶斯滤波的具体过程如下:
一、预测过程,由p(xk-1|Yk-1)得到p(xk|Yk-1):
p(xk,xk-1|Yk-1)=p(xk|xk-1,Yk-1)p(xk-1|Yk-1)
当给定xk-1时,状态xk与Yk-1相互独立,因此:
p(xk,xk-1|Yk-1)=p(xk|xk-1)p(xk-1|Yk-1)
上式两端对xk-1积分,可得:
p(xk|Yk-1)=∫p(xk|xk-1)p(xk-1|Yk-1)dxk-1
二、更新过程,由p(xk|Yk-1)得到p(xk|Yk):获取k时刻的测量yk后,利用贝叶斯公式对先验概率密度进行更新,得到后验概率密度函数:
假设yk只由xk决定,即:
p(yk|xk,Yk-1)=p(yk|xk)
因此:
其中,p(yk|Yk-1)为归一化常数:
p(yk|Yk-1)=∫p(yk|xk)p(xk|Yk-1)dxk
1.3、根据极大后验准则或最小均方误差准则,将具有极大后验概率密度的状态或条件均值作为系统状态的估计值。
其中,所述步骤3具体包括以下步骤:
3.1、根据观测噪声的高斯混合模型,对于每一个观测值引入一个隐变量Z,定义Z={z1,z2,…,zS},zs为S维变量,满足zs∈{0,1}而且即隐变量zs中有且仅有一位为1,其他位置都为0,如果zs,j=1,表示第s个观测噪声是由第j个高斯混合模型产生的;
3.2、由隐变量Z的条件概率密度函数p(zs|αk)以及带有隐变量且每个观测样本独立同分布的混合高斯模型概率密度函数p(vk|zs,μk,Λk)表示为:
其中,αk=[αk,1,αk,2,…,αk,J],μk=[μk,1,μk,2,…,μk,J],Λk=[Λk,1,Λk,2,…,Λk,J],Ψk=[αk,μk,Λk,Z]。
其中,所述步骤6具体包括以下步骤:
6.1、对粒子重采样后,有k-1时刻第i个粒子的权重并且由于权值更新公式简化成
6.2、表示在状态x出现的条件下,测量y出现的概率;由系统状态方可知,测量值就是在真实值附近添加观测噪声,观测噪声的分布通过变分贝叶斯学习得到。
其中,所述步骤7具体包括以下步骤:
7.1、根据平均场理论高斯混合模型参数的联合概率密度函数q(Ψk)通过参数和潜在变量的划分因式分解,如下所示:
上式中所有的未知的模型参数被假设为独立的,将每一个隐变量划分看成是一个单体,其他划分对其的影响看作是其自身的作用,采用迭代的方法,当变分自由能取得最大值的时候,Ψi与它的互斥集Ψ-i具有如下关系:
每个因子q(Ψi)取决于剩余因子q(Ψj),i≠j,因子初始化,每个因子迭代更新循环增加边缘似然函数的下界直到收敛;
7.2、由于共轭指数模型的性质,权重参数α以及均值μ和方差Λ的后验概率密度分布被定义为:
其中λk,j,βk,j,mk,j,Σk,j,νk,j是高斯混合模型的后验概率密度分布的超参数;Dir(·)表示狄里克利分布,表示高斯分布,表示威沙特分布;
7.3、根据固定分布的参数βk,j,mk,j,Σk,j,νk,j,计算得到隐变量的分布参数γs,j;最新得到的γs,j保持不变,根据下面的参数更新公式更新参数Nk,j,Sk,j:其中表示k时刻第s个样本的观测值,表示k时刻第s个样本的真实值;
根据参数Nk,j,Sk,j按照下面的公式更新参数βk,j,mk,j,Σk,j,νk,j:
如此迭代计算,至变分自由能量F(Ψk)最大,即对数边缘似然函数的下界最大,得到混合高斯模型的变分贝叶斯学习参数估计:每次迭代之后计算下界的变化值,记作ΔF,当该值低于预先设定的近似小量时,认定该算法已经趋于收敛,得到足够逼近原分布的近似分布。
以上所述,仅为本发明专利较佳的实施例,但本发明专利的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明专利所公开的范围内,根据本发明专利的技术方案及其发明专利构思加以等同替换或改变,都属于本发明专利的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!