一种数据管理方法与装置与流程
本发明涉及云存储技术领域,具体涉及一种数据管理方法及装置。
背景技术:
在本世纪初,数据中心都面临着“基础设施导向型”应用设计带来的一个重要现实:服务器的使用不足。多数服务器的运行使用率都低于10%。这些服务器的电源和冷却成本远远大于实际需要。Farm资源处理机的操作管理费用非常高。而首席信息官(Chief Information Office,CIO)并未针对“我们如何改进”这个问题给出很好的答案。
与之一起的是由VMwareTM开创的服务器虚拟化。使用这个软件,虚拟化可以使单一的、未充分利用的物理服务器有条理地被分成多个虚拟服务器。整合多余的计算能力的经济效益是十分显著的。随着工作负载的虚拟化,它们变得更具有便携性、可移植性。将一个应用的工作负载隐蔽地从一个虚拟分区移动到另一个上面,甚至是远距离的移动也同时成为了现实。可以肯定的说,云计算中的这种移动,没有服务器虚拟化的帮助是不可能成为现实的,而这种力量和影响的创新相结合直至今天仍然被时刻关注着。
每个主要行业的分析师都同意数据在以令人震惊的速度增长。除了普遍理解的业务数据,如今移动设备、传感器、社交媒体和其他数据源正在以高速率生成以艾字节为单位的数据。对于存储公司,这种垂直增长已经成为股东价值增长的重要因素。然而现实却是,大多数消费者的存储现状与本世纪初的服务器现象惊人地相似。大部分存储未得到充分利用。大部分已经被利用的存储都是用于数据的多余拷贝,这些拷贝是通过孤立的数据保护和高可用性应用进行的(例如,备份、快照、灾难恢复、业务连续性、开发与测试、法规遵从性、分析及其他)。而这些应用创建副本时并不知道哪些副本是已经存在。据互联网数据中心(Internet Data Center,IDC)分析,在2014年企业要花费460亿美元或提供将近48千兆字节的空间来存储副本。在数据中心过多的“拷贝数据”是导致过度支出、业务效率低下、高额环境开支(例如电源和冷却)的原因。
技术实现要素:
本发明实施例的目的在于提供一种数据管理方法,用以解决现有技术中在对数据管理时效率低下,导致环境开支较高的技术问题。
为实现上述目的,本发明的数据管理方法包括如下步骤:
通过预设数据接口获取生产数据,并存储至云服务器的快照池中;
将所述快照池中的生产数据备份至重复数据删除池;
接收客户机发送的恢复第一生产数据的请求;
根据所述请求的内容,对所述快照池中所存储的所述第一生产数据进行恢复。
作为优选,所述方法包括:
所述预设数据接口包括VMware数据保护的应用程序编程接口(Application Programming Interface,API)、应用程序接口和文件系统快照接口。
作为优选,若所述预设数据接口为VMware数据保护的应用程序编程接口,则通过数据接口获取生产数据,包括:
通过VMware服务器获取所述生产数据,其中获取所述生产数据的方式包括带外模式、旁路模式和带内模式。
作为优选,若所述预设数据接口为应用程序接口,则通过数据接口获取生产数据,包括:
将所述生产数据镜像拷贝至所述快照池。
作为优选,将所述快照池中的生产数据备份至重复数据删除池,包括:
将所述生产数据根据预设重删压缩率进行优化处理;
将所述优化处理后的生产数据根据预设压缩率进行压缩;
将所述压缩后的生产数据备份至所述重复数据删除池。
作为优选,根据所述请求的内容,对所述快照池中所存储的所述第一生产数据进行恢复,包括:
根据所述快照池中的生产数据形成所述第一生产数据;
对所述第一生产数据进行快照,以生成虚拟数据;
将所述虚拟数据挂载到所述客户机。
作为优选,包括:
所述生产数据包括全量数据和增量数据。
作为优选,根据所述快照池中的生产数据形成所述第一生产数据,包括:
将所述生产数据中的全量数据和与所述第一生产数据相关的增量数据合成为所述第一生产数据。
作为优选,将所述生产数据中的全量数据和与所述第一生产数据相关的增量数据合成为所述第一生产数据,包括;
对所述生产数据的全量数据进行变化块追踪,以获得所述生产数据在预设时间点的增量数据;
将所述全量数据与所述预设时间点的增量数据合成为所述第一生产数据。
本发明实施例还提供一种数据管理装置,包括:
获取模块,配置为通过数据接口获取生产数据,并存储至云服务器中的快照池中;
备份模块,配置为将所述快照池中的生产数据备份至重复数据删除池;
接收模块,配置为接收客户机发送的恢复第一生产数据的请求;
恢复模块,配置为根据所述请求的内容,对所述快照池中所存储的所述第一生产数据进行恢复。
本发明方法具有如下优点:本发明实施例的技术方案通过数据接口将生产数据存储至云服务器的快照池中,同时将生产数据备份至重复数据删除池,以做长期的保存,同时根据客户机的恢复第一生产数据的请求,对所述快照池中所存储的所述第一生产数据进行恢复,提高了恢复效率。
附图说明
图1为本发明的数据管理方法的实施例一的流程图;
图2为本发明的数据管理方法的实施例二的流程图;
图3为本发明的数据管理方法的实施例二的数据获取过程示意图;
图4为本发明的数据管理方法的实施例二的云服务器的快照池和重复数据删除池的示意图;
图5为本发明的数据管理方法的实施例二的获取全量数据和增量数据的示意图;
图6为本发明的数据管理方法的实施例二的获取某一时间点的全量数据的示意图;
图7为本发明的数据管理方法的实施例二的数据恢复的示意图;
图8为本发明的数据管理方法的实施例二的某客户机的数据备份的示意图;
图9为本发明的数据管理装置的实施例一的示意图。
具体实施方式
以下实施例用于说明本发明,但不用来限制本发明的范围。
实施例1
图1为本发明的可穿戴设备的控制方法实施例一的流程图,如图1所示,本实施例的可穿戴设备的控制方法,具体可以包括如下步骤:
S101,通过预设数据接口获取生产数据,并存储至云服务器中的快照池中。
其中,生产数据是指客户机所使用的数据。生产数据包括全量数据和增量数据;其中全量数据是在初次获取时获取的最原始的数据,增量数据是对全量数据进行更新操作以后形成的数据。
对于生产数据需要在云服务器中进行备份,在第一次获取客户机的数据量,获取的是客户机的全量数据,在以后的时间时获取客户机的增量数据,在优选的实施方案中,可以每隔预设的时间间隔获取一次生产数据,存储在去服务器中进行备份。
快照技术是一种摄影技术,随着存储应用需求的提高,用户需要在线方式进行数据保护,快照就是在线存储设备防范数据丢失的有效方法之一。快照是指关于指定数据集合的一个完全可用拷贝,该拷贝包括相应数据在某个时间点(拷贝开始的时间点)的映像。快照可以是其所表示的数据的一个副本,也可以是数据的一个数据品。
具体地,本实施例涉及的云服务器中包括快照池。
也就是说,本实施例在具体实施时,是将获取的生产数据在快照池中进行备份。
S102,将所述快照池中的生产数据备份至重复数据删除池。
具体地,由于快照池保存数据的时间较短,而生产数据是非常巨大的,因此,为了能对生产数据进行长期保存,本实施例还将快照池中的生产数据备份至重复数据删除池,以使数据在重复数据删除池中进行长期保存,例如一年。需要说明的是,这一备份过程是在后台进行的,和对客户机的生产数据备份无关,因此,将快照池中的数据备份至重复数据删除池的这一过程不会影响到客户机的运行。
S103,接收客户机发送的恢复第一生产数据的请求。
具体地,当有客户机的数据发生异常,需要进行备份时,客户机向云服务器发送恢复第一生产数据的请求。其中第一生产数据可能是全量数据,也可能是某一时间增量数据。
S104,根据所述请求的内容,对所述快照池中所存储的所述第一生产数据进行恢复。
具体地,云服务器在接收到恢复第一生产数据的请求后,请求的内容中包含了第一生产数据的信息,例如,第一数据为增量数据,以及第一生产数据所对应的时间点,这时,云服务器在快照池中根据该对应时间点,获取该对应时间点的增量数据,如果在该对应时间点之前还有其他增量数据,则需要将该增量数据、其他增量数据和全量数据进行合成,以形成第一生产数据,然后将该生产数据发送至客户机。
本发明实施例的技术方案通过数据接口将生产数据存储至云服务器的快照池中,同时将生产数据备份至重复数据删除池,以做长期的保存,同时根据客户机的恢复第一生产数据的请求,对所述快照池中所存储的所述第一生产数据进行恢复,提高了恢复效率。
实施例2
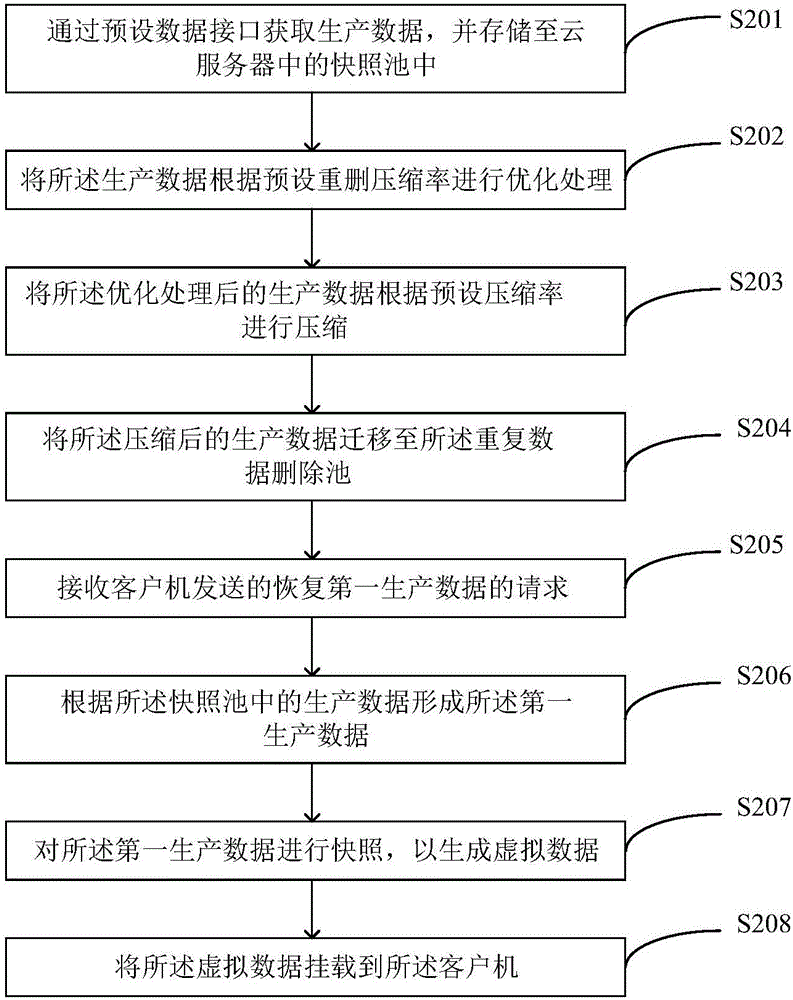
图2为本发明的可穿戴设备的控制方法的实施例二的流程图,本实施例的可穿戴设备的控制方法在如图1所示的实施例的基础上,进一步更加详细地介绍本发明的技术方案。如图2所示,本实施例的可穿戴设备的控制方法,具体可以包括如下步骤:
S201,通过预设数据接口获取生产数据,并存储至云服务器中的快照池中。
其中,所述预设数据接口包括VMware数据保护的应用程序编程接口(Application Programming Interface,API)、应用程序接口和文件系统快照接口。
进一步地,若所述预设数据接口为VMware数据保护的应用程序编程接口,则步骤S201包括:
A,通过VMware服务器获取所述生产数据,其中获取所述生产数据的方式包括带外模式、旁路模式和带内模式。
具体地,在VMware的环境下,无需安装代理程序,云服务器通过VMware数据保护接口(VMware Data Protection API)直接和VCENTER 服务器和ESX服务器通信,通过过程中的数据传输方式包括带外模式(Out-of-Band)、旁路模式(Side-Band)和带内模式(In-Band)。
进一步地,若所述预设数据接口为应用程序接口,则步骤S201包括:
B,将所述生产数据镜像拷贝至所述快照池。
例如,可以采用Oracle数据库的RMAN接口。
如图3所示,为Oracle数据库的RMAN接口获取数据的过程。首先应用程序服务器获取客户机的数据,例如可以获取开放式系统的直连式存储(Direct Attached Storage,DAS)、存储阵列和文件服务器上的生产数据,然后应用程序将这些生产数据通过应用程序接口即RMAN接口,将数据挂载至小型计算机接口(Internet Small Computer System Interface,ISCSI),再传输至云服务器中的快照池中,快照池再将该生产数据备份到重复数据删除池。
在这种情况下,应用程序服务器好需要安装一个针对Oracle RMAN的代理程序,云服务器通过RMAN的镜像拷贝(Image Copy)功能来获取全量数据和增量数据。这时,数据的传输方式包括带外模式和带内模式。
进一步地,若预设数据接口为文件系统快照接口,则可以采用文件系统的快照功能作为接口。
S202,将所述生产数据根据预设重删压缩率进行优化处理。
根据如图1所示实施例的介绍,快照池对生产数据保存的时间较短,因此还需要将生产数据备份至重复数据删除池。由于生产数据是海量的,虽然重复数据删除池空间较大,但也是有限的,因此,需要将快照池中的生产数据进行进一步的数据,以减小这些数据所占的空间,使重复数据删除池能够存储更多的数据。
因此需要对生产数据根据预设的重删压缩率进行优化处理,举例来说,可以将数据以4K为单位进行去重计算,例如,1024K的数据,将其分割成256个数据块(block),每个数据块大小为4K,这些数据块中必然存在重复,相同的数据块仅保留唯一一个,将其他重复的数据块删除,同时,为该唯一一个数据块建立一个数据索引,在需要调用这1024K数据时,将这些数据块进行重新组合,需要使用重复数据块时,根据数据索引来调用该唯一一个保留的数据块,由此可以重新组成该1024K的数据。
S203,将所述优化处理后的生产数据根据预设压缩率进行压缩。
具体地,本实施例在对数据进行重删压缩后,还要进行数据压缩,例如,可以采用64K为单位进行压缩,以便于进一步节省重复数据删除池的空间。
S204,将所述压缩后的生产数据备份至所述重复数据删除池。
如图4所示,客户机、应用程序服务器与云服务器通过网络连接,云服务器包括快照池和重复数据删除池,快照池中包括全量数据和增量数据,并以快照形式保存,例如,快照1为初始时间点的全量数据,快照2为第一时间点的增量数据……由图中采用的是指针式快照,也就是说所有的数据存储于磁盘存储单元中,而快照1、快照2……快照n,只是指示数据所处位置的指针被拷贝。
S205,接收客户机发送的恢复第一生产数据的请求。
具体地,当有客户机的数据发生异常,需要进行备份时,客户机向云服务器发送恢复第一生产数据的请求。其中第一生产数据可能是全量数据,也可能是某一时间增量数据。
S206,根据所述快照池中的生产数据形成所述第一生产数据;
如上所述,所述生产数据包括全量数据和增量数据。
则步骤S206可以包括:
C,将所述生产数据中的全量数据和与所述第一生产数据相关的增量数据合成为所述第一生产数据。
进一步地,步骤C包括;
D,对所述生产数据的全量数据进行变化块追踪(Change Block Track,CBT),以获得所述生产数据在预设时间点的增量数据;
E,将所述全量数据与所述预设时间点的增量数据合成为所述第一生产数据。
具体地,利用CBT方法,可以从最初的全量数据产生变化的时候,通过预设数据接口对数据块(block)进行跟踪,由此能够知道该全量数据在什么时候产生了哪些变化,在下一次追踪过程中,仅根据上一次变化后的增量数据进行追踪,而不需要通过与全量数据进行完整对比的方式。
如表1所示,表1示出了采用不同的数据接口获取数据的方法、形成增量数据的方法、增量级别和增量合成结果。
表1:
由表1可以看出,采用VMware的应用程序编程接口,可以利用VMware的快照功能获取生产数据,获取增量数据的方法,采用数据块追踪方法,增量级别为数据块,合成的结果为虚拟数据,也就是说,快照为指针式快照。采用其他接口获取生产数据,并形成增量数据的方法如表1所示。
增量合成的过程介绍如下,不同的增量数据实际是不同时间点的增量,例如,获取增量数据的时间间隔为一天,则第一天获取了全量数据,第二天获取了该全量数据的增量数据,第三天再次获取第二天的增量数据的增量数据,……以此类推,当客户机发生数据异常时,需要恢复到第三天的增量数据,则将第三天的增量数据和第二天的增量数据和第一天的全量数据进行合成处理,形成第一生产数据。在具体实施时,获取增量数据的时间间隔可以根据客户机的需要进行定制,例如,每隔一小时获取一次增量数据。
具体地如图5所示,由左至右分别为全量数据、第一时间点的增量数据、第二时间点的增量数据和第三时间点的增量数据。
在需要恢复某一时间点的第一生产数据时,如图6所示,例如恢复第二时间点的第一生产数据,则将第二时间点的增量数据与第一时间点的增量数据与全量数据进行合成,形成第一生产数据,并直接挂载给应用程序服务器,对第三时间点的数据恢复过程以此类推。
S207对所述第一生产数据进行快照,以生成虚拟数据。
S208,将所述虚拟数据挂载到所述客户机。
具体地,本实施例所涉及的挂载操作,实际上也是快照操作,即对所备份的生产数据(即快照池中的快照)再做快照,并将此快照挂载给客户机,此快照没有份数限制,因此,一份某一时间点的备份的生产数据可以通过快照生成多份虚拟数据,挂载给不同的主机,从而实现了快速恢复,同时还能够提供开发测试、数据分析等不同的业务类型。
将快照挂载至不同的客户机的过程,如图7所示。
另外,本实施例在试验阶段获得了以下试验数据:
一,在两台云服务器之间进行数据复制,复制的频率可以根据客户机的需要进行定制,其复原时间目标(RTO,Recovery Time Objective)可达到5分钟,复原点目标(RPO,Recovery Point Objective)可达30分钟。
其中,复原时间目标是指企业可容许中断时间长度;复原点目标是当数据恢复后,恢复后的数据对应的时间点。
二,云服务器保护数据库每15分钟备份一次归档日志,且极少占用计算资源,PRO最大可达15分钟,针对数据库和虚拟化系统的恢复速度极快,1TB数据从还原到启动的时间仅需要3分钟,即RTO为3分钟,虚拟机的恢复时间为25秒,即RTO为25秒,也就是说,本实施例的数据管理方法可用于客户机的应用服务,可以在数分钟内将业务恢复。
三,本实施例的云服务器可以将任务时间点的业务应用瞬间提供给测试开发使用的系统,可以节省开发周期达40%,同时开发人员可以根据自己的权限将开发系统回滚或挂载到任意时间点,且能够保证数据库的逻辑一致性。
以某客户机为例,某客户机可以为测试开发系统、物理服务器、生产应用系统、物理容灾系统和虚拟化系统。如图8所示,设置两个云服务器,分别为主数据中心和异地数据中心,通过旁路模式将客户机的生产数据传输至主数据中心,同时将主数据中心的生产数据进行以预设的重删压缩率进行块级重删压缩操作,将压缩后的数据备份至异地数据中心。同时传统的数据备份方法依然可以并行实施,例如同时将生产数据备份到磁带库中。
本发明实施例的技术方案,将生产数据进行重删压缩处理后,保存至重复数据删除池中,实现了在能够达到快速恢复数据的同时,还可以长久的保存数据。
实施例3
图9为本发明的数据管理装置实施例一的示意图,如图9所示,本实施例的数据管理装置,具体可以包括获取模块91、备份模块92、接收模块93和发送模块94。
获取模块91,配置为通过数据接口获取生产数据,并存储至云服务器中的快照池中;
备份模块92,配置为将所述快照池中的生产数据备份至重复数据删除池;
接收模块93,配置为接收客户机发送的恢复第一生产数据的请求;
恢复模块94,配置为根据所述请求的内容,对所述快照池中所存储的所述第一生产数据进行恢复。
本实施例的数据管理装置,通过采用上述模块对数据进行管理的实现机制与上述图1所示实施例的数据管理方法的实现机制相同,详细可以参考上述图1所示实施例的记载,在此不再赘述。
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!