驾驶员开车接打电话的状态识别方法及装置与流程
本申请涉及视频监控领域,尤其涉及一种驾驶员开车接打电话的状态识别方法及装置。
背景技术:
驾驶员在开车过程中若接打电话,会大大增加交通事故的发生率,因而需要对驾驶员卡车接打电话的状态进行有效识别,作为其是否违章的重要证据。
随着图像处理技术、计算机视觉技术、深度学习技术以及嵌入式技术的不断发展,如何对车辆(含车内人员)违章进行自动判别及取证已经成为当前智能交通中的一个研究热点。
现有技术提供了一种识别驾驶员打手机行为的方法(CN105868690A),首先采集驾驶舱内的视频流,再通过人脸部件模型定位人脸区域,接着进行人脸矫正,使用非线性判别关系,训练两组参数进行是否打电话判别,其中训练分类模型包括耳部区域训练集、打手机训练集和未打手机训练集。该方法采用DPM(Deformable Part Model,可变形部件模型)部件检测算法进行人脸区域定位,检测非常耗时,对遮挡或人脸模糊情况的检测准确率影响较大;该方法采用非线性分类方法进行是否打电话判别,通过训练耳部区域、打手机区域、未打手机区域进行识别,准确率较低。
现有技术还提供一种驾驶员行车途中接打手机行为的自动监控方法(CN103366506A),其通过图像获取装置,首先获取驾驶员头部及附近区域,使用肤色检测得到驾驶员脸部及手部在图像中的位置,再使用支持向量机进行分类,对接打手机的驾驶员发出警告。该方法采用肤色检测得到驾驶员脸部及手部在图像中的位置,而驾驶室成像复杂,复杂场景下的车窗内采光及特殊天气会对成像影响较大,因此该方法漏检、误检均较多。
技术实现要素:
有鉴于此,本申请提供一种驾驶员开车接打电话的状态识别方法及装置,以解决现有技术中存在的驾驶员开车接打电话的状态识别准确率较低的问题。
具体地,本申请是通过如下技术方案实现的:
根据本申请的第一方面,提供一种驾驶员开车接打电话的状态识别方法,所述方法包括:
对监控图像中目标车辆的车窗进行定位;
根据车窗的定位信息以及目标车辆的车牌信息,获得驾驶员检测候选区域;
利用方向梯度直方图和支持向量机对所述驾驶员检测候选区域进行检测,获得所述驾驶员的头肩区域;
将所述头肩区域依次输入第一层CNN网络和第二层CNN网络,所述第一层CNN网络对所述头肩区域进行初步筛选,获得疑似接打电话的驾驶员的头肩区域,所述第二层CNN网络对所述第一层CNN网络的输出结果进一步筛选,获得所述驾驶员接打电话的状态。
可选地,在将所述头肩区域输入第一层CNN网络和第二层CNN网络之前,还包括:
提取所述头肩区域的方向梯度直方图特征和局部二值特征,并将所述方向梯度直方图特征和局部二值特征进行组合,以形成一个多维的特征向量;
利用线性判别分析对所述特征向量进行分类,过滤掉非头肩区域。
可选地,所述方法还包括:
将所述疑似接打电话的驾驶员的头肩区域划分为左边区域、右边区域和整体区域;
将所述左边区域、右边区域和整体区域分别输入第二层CNN网络,获得所述驾驶员接打电话的状态,所述驾驶员接打电话的状态包括:左边接打电话、右边接打电话、未打电话以及无法判罚。
可选地,所述方法还包括:
若当前帧监控图像识别结果为驾驶员处于接打电话状态,则对当前帧监控图像的下一帧监控图像继续识别,若所述下一帧监控图像的识别结果为驾驶员处于接打电话状态,则进行告警;否则,放弃告警。
可选地,所述车窗的定位信息获取过程包括:
根据所述目标车辆的车牌信息,获取车窗右上角区域;
利用定位滤波器定位车窗右上角点的位置信息。
根据本申请的第二方面,提供一种驾驶员开车接打电话的状态识别装置,所述装置包括:
定位模块,对监控图像中目标车辆的车窗进行定位;
区域获取模块,根据车窗的定位信息以及目标车辆的车牌信息,获得驾驶员检测候选区域;
目标检测模块,利用方向梯度直方图和支持向量机对所述驾驶员检测候选区域进行检测,获得所述驾驶员的头肩区域;
识别模块,将所述头肩区域依次输入第一层CNN网络和第二层CNN网络,所述第一层CNN网络对所述头肩区域进行初步筛选,获得疑似接打电话的驾驶员的头肩区域,所述第二层CNN网络对所述第一层CNN网络的输出结果进一步筛选,获得所述驾驶员接打电话的状态。
可选地,所述目标检测模块还包括:
特征提取子模块,提取所述头肩区域的方向梯度直方图特征和局部二值特征,并将所述方向梯度直方图特征和局部二值特征进行组合,以形成一个多维的特征向量;
过滤子模块,利用线性判别分析对所述特征向量进行分类,过滤掉非头肩区域。
可选地,所述识别模块还包括:
划分子模块,将所述疑似接打电话的驾驶员的头肩区域划分为左边区域、右边区域和整体区域;
融合识别子模块,将所述左边区域、右边区域和整体区域分别输入第二层CNN网络,获得所述驾驶员接打电话的状态,所述驾驶员接打电话的状态包括:左边接打电话、右边接打电话、未打电话以及无法判罚。
可选地,所述装置还包括:
多帧验证模块,若当前帧监控图像识别结果为驾驶员处于接打电话状态,则对当前帧监控图像的下一帧监控图像继续识别,若所述下一帧监控图像的识别结果为驾驶员处于接打电话状态,则进行告警;否则,放弃告警。
可选地,所述定位模块包括:
根据所述目标车辆的车牌信息,获取车窗右上角区域;
利用定位滤波器定位车窗右上角点的位置信息。
本申请的有益效果:通过车辆车窗区域定位、驾驶员目标检测(头肩区域检测)以及级联的CNN网络这些纯视频检测的步骤,能够免去人工检测开车接打电话状态的耗时耗力,并且能够排除复杂场景下的非真实接打电话的误捡,提高识别精度,相比较于传统方法,判罚准确率更高,对场景的适应性、鲁棒性均更佳。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本申请。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本申请的实施例,并与说明书一起用于解释本申请的原理。
图1是本申请实施例提供的一种驾驶员开车接打电话的状态识别方法流程图;
图2是本申请实施例提供的一种目标检测的流程图;
图3是本申请实施例提供的一种目标识别的流程图;
图4是本申请实施例提供的一种驾驶员开车接打电话的状态识别装置结构框图;
图5是本申请实施例提供的目标检测模块的结构框图;
图6是本申请实施例提供的识别模块的结构框图;
图7是本申请实施例提供的又一种驾驶员开车接打电话的状态识别装置结构框图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。另外,在不冲突的情况下,下述的实施例及实施例中的特征可以相互组合。
在本申请使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本申请。在本申请和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
应当理解,尽管在本申请可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本申请范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所使用的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”。
参见图1,本实施例提供的一种驾驶员开车接打电话的状态识别方法,所述方法可以包括:
S101:对监控图像中目标车辆的车窗进行定位。
其中,监控场景可选择车流量较多或事故易发道路场景,例如,普通卡口道路,所述监控图像为卡口摄像头所拍摄。
在一实施例中,针对采集到的监控图像fsrc(x,y),x,y分别为监控图像上点的横坐标和纵坐标,监控图像的宽为Width、高为Height,假设已经获得图像中目标车辆的车牌信息,所述车牌信息可以包括车牌颜色LpColor和车牌信息Lp:(x,y,w,h),其中,Lp(x,y)分别是车牌的横坐标和纵坐标(车牌左上角的横坐标和纵坐标或者车牌中心的横坐标或纵坐标等),Lp(w,h)分别是车牌的宽和高。
其中,车窗定位不限于以下方案,例如,可以使用Hough直线检测定位车窗,或者通过Adaboost(一种迭代算法)车窗检测定位车窗,或者使用车窗右上角点定位来确定车窗区域。
在本实施例中,使用车窗右上角点定位来确定车窗区域。
具体地,所述车窗的定位信息获取过程包括:
根据所述目标车辆的车牌信息,获取车窗右上角区域;
利用定位滤波器定位车窗右上角点的位置信息。
本实施例中,首先通过车牌信息预估车窗右上角区域,再使用定位滤波器定位右上角点的位置信息。
对于一张候选的车窗右上角图像fun(x,y),利用定位滤波器对候选图像fun(x,y)进行卷积的计算公式为:
公式(1)中,x,y分别为候选图像中点的横坐标和纵坐标;
表示卷积操作,g(x,y)为候选图像fun(x,y)与定位滤波器卷积结果。
通过公式(1)进行计算,找出g(x,y)峰值点即为车窗右上角点位置信息RgtUp(x,y)。
本实施例中,车窗右上角点定位滤波器是通过批量已标定好的图像训练得到:
公式(2)中,hi(x,y)为第i张车窗右上角图片对应的定位滤波器,
a′i为归一化处理后的滤波器权重系数,
本实施例中,
公式(3)中,xi、yi为标定的车窗右上角点的位置信息;
δ为经验系数;
fun(x,y)为已知车窗右上角图像,根据公式(1)和(3)可以反推出hi(x,y),通过批量已标注图像,计算得到定位滤波器
S102:根据车窗的定位信息以及目标车辆的车牌信息,获得驾驶员检测候选区域。
其中,驾驶员检测候选区域的形状可根据需要设定为规则的形状。本实施例中,驾驶员检测候选区域的形状选择长方形。
根据步骤S101已获得目标车辆的车窗右上角点位置信息RgtUp(x,y),结合车牌信息Lp:(x,y,w,h),计算获得驾驶员检测候选区域Driver(x,y,w,h):
Driver(x)=min(RgtUp(x)-α*Lp(w),0) (2)
Driver(y)=min(RgtUp(y)-β*Lp(w),0) (3)
Driver(w)=min(γ*Lp(w),Width-Driver(x)) (4)
Driver(h)=min(ε*Lp(w),Height-Driver(y)) (5)
公式(2)-(5)中,Driver(x,y)分别是驾驶员检测候选区域的顶点(例如可以为左上角顶点、左下角顶点、右上角顶点和右下角顶点)横坐标和纵坐标;
Driver(w,h)分别是驾驶员检测候选区域的宽和高;
α、β、ε和γ均为预设的经验系数,其中,α∈[1,2],β∈[0.5,1],ε∈[2.5,3.5],γ∈[1.5,2.5]。
本实施例中,α=1.5,β=0.5,γ=2.0,ε=3.0。
根据上述公式(2)-(5),可以计算获得驾驶员检测候选区域Driver(x,y,w,h)。
S103:利用方向梯度直方图和支持向量机对所述驾驶员检测候选区域进行检测,获得所述驾驶员的头肩区域。
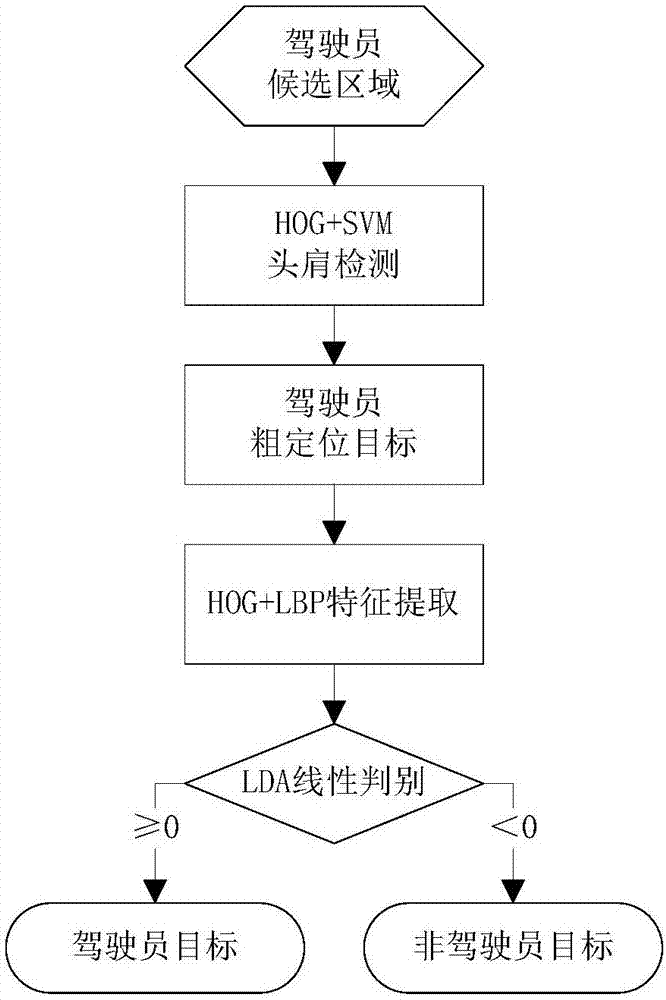
参见图2,在该步骤中,采用方向梯度直方图(HOG,Histogram of Oriented Gradient)结合支持向量机(SVM,Support Vector Machine)分类对驾驶员区域粗定位,获得所述驾驶员的头肩区域。在提取驾驶员检测候选区域的HOG特征后,将HOG特征输入SVM进行训练,从而对驾驶员区域进行粗定位。
本实施例中,在对驾驶员检测候选区域进行方向梯度直方图特征提取后,通过滑窗检测的方式获取相应滑窗大小的方向梯度直方图特征,并分别输入SVM进行分类,获得驾驶员头肩检测。而使用方向梯度直方图特征的头肩检测相比较于肤色人脸检测,DPM或Adaboost人脸检测的优势在于,对于人脸遮挡(遮阳板遮挡人脸或车窗局部遮挡人脸等)或者人脸反光模糊情况下,驾驶员检测成功率更高(3%到5%的范围)。
步骤S103检测驾驶员头肩区域的分类结果可分为头肩目标和非头肩目标,但仍然存在较多的误检,对结果影响较大,因此需要对方向梯度直方图结合支持向量机所提取的头肩区域进一步降误检。
又参见图2,本实施例中,所述驾驶员开车接打电话的状态识别方法还可以包括:
提取所述头肩区域(通过步骤S103获得的头肩区域)的梯度方向直方图特征和局部二值特征(LBP,Local Binary Pattern),并将所述梯度方向直方图特征和局部二值特征进行组合,以形成一个多维的特征向量;
利用线性判别分析(LDA,Linear Discriminant Analysis)对所述特征向量进行分类,过滤掉非头肩区域。
其中,LDA属于一种线性学习方法,也称Fisher判别分析(即费希尔判别分析),该方法将给定的样本集投影到一条直线上,能把不同类别样本的投影点最大的分离,同类别的样本尽可能接近。
本实施例中,利用LDA,对步骤S103检测到的头肩窗口进行过滤,分为有人和无人两类,过滤掉非头肩的区域,以降低误检率,提高检测精度。
在一实施例中,对驾驶员检测候选区域进行HOG特征提取的过程可以包括:
图像归一化为40*40,共有16个block,其中,一个block(即区间)由4个cell(即细胞单元)组成,一个cell为8*8的像素集合,以8个像素为步长进行扫描,每个cell有9个bin(即9份),因此HOG特征维数为16*4*9=576维。
而对驾驶员检测候选区域进行LBP特征提取的过程可以包括:
采用均匀LBP模式,从256维降到59维(59维即为均匀LBP模式),图像归一化为48*48,并分为3*3块,每块大小为16*16,每块有59维特征,因此LBP特征维数为3*3*59=531维。
在HOG特征和LBP特征后,将HOG和LBP组合,得到一个n(n为自然数)维的特征向量X(x1,x2,x3,…,xn)。可选地,n=1009。
利用LDA线性判别分析对训练样本(即上述n维的特征向量)进行迭代训练,得到一组最优的训练参数W(w1,w2,w3,…,wn)。
h=w1*x1+w2*x2+w3*x3+…+wn*xn+b1 (6)
公式(6)中,h为线性判别分析的结果;
x1,x2,x3,…,xn为特征向量X中的特征值;
w1,w2,w3,…,wn、b1为训练参数。
测试时,将提取的特征向量X(x1,x2,x3,…,xn)代入公式(6)中,求得h,若h大于等于0,则认为步骤S103输出的头肩区域为最终的头肩区域;若h小于0,则认为步骤S103输出的头肩区域为非头肩区域,可直接过滤掉该非头肩区域。
即根据h是否大于等于0来对步骤S103输出的头肩区域进一步筛选,最终获得较为精确的头肩区域,减少非头肩区域的干扰,从而提高检测精度。
S104:将所述头肩区域依次输入第一层CNN(Convolutional Neural Network,卷积神经网络)网络和第二层CNN网络,所述第一层CNN网络对所述头肩区域进行初步筛选,获得疑似接打电话的驾驶员的头肩区域,所述第二层CNN网络对所述第一层CNN网络的输出结果(即第一层CNN网络输出的疑似接打电话的驾驶员的头肩区域)进一步筛选,获得所述驾驶员接打电话的状态。
本实施例中,所述第一层CNN网络的层数小于所述第二层CNN网络的层数,且所述第一层CNN网络的卷积核数目小于所述第二层CNN网络的卷积核数目。
其中,CNN网络包括输入层,Nc个卷积层,Np个下采样层,Nf个全连接层。
具体地,每层卷积层包括Nc_Ck个卷积核,卷积核大小为Ckm*Ckm,步长为1,每层下采样层的核大小为Pkm*Pkm,步长为Pkm,所述全连接层的最后一层全连接层输出的神经元数量为需要分类数目。
参见图3,本实施例中,第一层CNN网络输出两类,接打电话和不接打电话这两个驾驶员接打电话状态,即第一层CNN网络输出为2。
第二层CNN网络为精细分类,输出为4,即4个驾驶员接打电话状态(左边打电话、右边打电话、未打电话以及无法判罚)。
其中,所述Nc∈[2,10],Np∈[2,10],Nf∈[1,3];
Nc_Ck∈[Nc_Ckmin,Nc_Ckmax],Nc_Ckmin∈[6,16];
Ckm∈[3,7],Pkm∈[2,4]。
在步骤S104中,首先将在步骤S103中获得头肩区域输入第一层CNN网络,以获得接打电话和不接打电话这两个状态,实现快速、粗略识别。
其中,第一层CNN网络的结构较为简单,采用较少的网络层数和卷积核数目。目的是快速过滤,尽可能多的保留打电话的监控图片,同时排除非打电话的监控图片。
第一层CNN网络的输出结果为两类,即打电话和不打电话,从而可以过滤掉大量的非打电话的监控图像,不必再进行下一层(即第二层CNN网络)精细分类(即减少输入至第二层CNN网络的监控图像的数量),既降低了精细分类的耗时,同时可以减少开车接打打电话的误判率。
相比第一层CNN网络,第二层CNN网络结构较为复杂,从而实现精细识别。
又参见图3,所述驾驶员开车接打电话的状态识别方法还包括:
将所述疑似接打电话的驾驶员的头肩区域(即所述第一层CNN网络输出疑似接打电话的驾驶员的头肩区域)划分为左边区域、右边区域和整体区域;
将所述左边区域、右边区域和整体区域分别输入第二层CNN网络,获得所述驾驶员接打电话的状态,所述驾驶员接打电话的状态包括:左边接打电话、右边接打电话、未打电话以及无法判罚。
假设驾驶员的头肩区域为Call(x,y,w,h),其中,Call(x,y)为头肩区域的横坐标和纵坐标,Call(w,h)为头肩区域的宽和高。
本实施例中,将头肩区域归一化为w*h,即w=150,h=100,则待识别的头肩区域分为如下三块:左边区域为Call(x,y,α*w,h),右边区域为Call(x+(1-α)*w,y,α*w,h),总体区域为Call(x,y,w,h)。其中,α为经验系数。可选地,α=2/3。
在将待识别的头肩区域分为三块后,需要将划分的左边区域、右边区域和总体区域输入第二层CNN网络进行多特征融合判别。由此可见,本实施例使用头肩检测进行驾驶员目标粗定位,再结合多特征融合判别分析进行驾驶员误检消除,从而降低误检率。
本实施例中,为了更加精准地识别出驾驶员开车接打电话的状态,提高识别的精确度,所述驾驶员开车接打电话的状态识别方法还包括:
若当前帧监控图像识别结果为驾驶员处于接打电话状态,则对当前帧监控图像的下一帧监控图像继续识别,若所述下一帧监控图像的识别结果为驾驶员处于接打电话状态,则进行告警;否则,放弃告警。
当然,也可根据需要选择所需识别的监控图像的帧数,例如至少两帧连续的监控图像。
如图4所示,为本申请提供的驾驶员开车接打电话的状态识别装置的结构框图,与上述驾驶员开车接打电话的状态识别方法相对应,可参照上述驾驶员开车接打电话的状态识别方法的实施例来理解或解释该驾驶员开车接打电话的状态识别装置的内容。
参见图4,本实施例提供的一种驾驶员开车接打电话的状态识别装置,所述装置可以包括定位模块100、区域获取模块200、目标检测模块300以及识别模块400。
其中,定位模块100,用于对监控图像中目标车辆的车窗进行定位;
区域获取模块200,根据车窗的定位信息以及目标车辆的车牌信息,获得驾驶员检测候选区域;
目标检测模块300,利用方向梯度直方图和支持向量机对所述驾驶员检测候选区域进行检测,获得所述驾驶员的头肩区域;
识别模块400,将所述头肩区域依次输入第一层CNN网络和第二层CNN网络,所述第一层CNN网络对所述头肩区域进行初步筛选,获得疑似接打电话的驾驶员的头肩区域,所述第二层CNN网络对所述第一层CNN网络的输出结果进一步筛选,获得所述驾驶员接打电话的状态。
其中,所述第一层CNN网络的层数小于所述第二层CNN网络的层数,且所述第一层CNN网络的卷积核数目小于所述第二层CNN网络的卷积核数目。
进一步地,所述定位模块100可以包括:
根据所述目标车辆的车牌信息,获取车窗右上角区域;
利用定位滤波器定位车窗右上角点的位置信息。
进一步地,参见图5,所述目标检测模块300还可以包括特征提取子模块301和过滤子模块302。
其中,特征提取子模块301,用于提取所述头肩区域的方向梯度直方图特征和局部二值特征,并将所述方向梯度直方图特征和局部二值特征进行组合,以形成一个多维的特征向量;
过滤子模块302,利用线性判别分析对所述特征向量进行分类,过滤掉非头肩区域。
进一步地,参见图6,所述识别模块400还可以包括划分子模块401和融合识别子模块402。
其中,划分子模块401,将所述疑似接打电话的驾驶员的头肩区域(所述第一层CNN网络输出疑似接打电话的驾驶员的头肩区域)划分为左边区域、右边区域和整体区域;
融合识别子模块402,将所述左边区域、右边区域和整体区域分别输入第二层CNN网络,获得所述驾驶员接打电话的状态,所述驾驶员接打电话的状态包括:左边接打电话、右边接打电话、未打电话以及无法判罚。
参见图7,所述驾驶员开车接打电话的状态识别装置还可包括:
多帧验证模块500,若当前帧监控图像识别结果为驾驶员处于接打电话状态,则对当前帧监控图像的下一帧监控图像继续识别,若所述下一帧监控图像的识别结果为驾驶员处于接打电话状态,则进行告警;否则,放弃告警。
综上所述,本申请的驾驶员开车接打电话的状态识别方法及装置通过车辆车窗区域定位、驾驶员目标检测(头肩区域检测)以及级联的CNN网络这些纯视频检测的步骤,能够免去人工检测开车接打电话状态的耗时耗力,并且能够排除复杂场景下的非真实接打电话的误捡,提高识别精度,相比较于传统方法,判罚准确率更高,对场景的适应性、鲁棒性均更佳。
以上所述仅为本申请的较佳实施例而已,并不用以限制本申请,凡在本申请的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本申请保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!