一种基于属性相似度的本体匹配方法与流程
本发明属于计算机技术领域,具体涉及一种基于属性相似度的本体匹配方法。
背景技术:
本体定义了概念以及概念之间的关系,即本体给出构成相关领域词汇的基本术语和关系,以及利用这些术语和关系构成的规定这些词汇外延的规则的定义。因而,本体规范了领域中的术语以及它们之间的关系,这些信息的总和就表现为数据的语义。本体匹配技术通常可以分为元素层匹配技术和结构层匹配技术。元素层匹配技术只考虑独立的本体元素,而不考虑这些元素之间的关系,例如,在匹配父概念时不考虑与其子概念以及其他概念之间的关系。结构层匹配技术在匹配时考虑元素间的层级关系以及语义邻居关系等。
元素层匹配技术又可分为基于字符串的技术、基于语言学的技术、基于语言资源的技术、基于约束的技术和联结复用技术等。其中,基于字符串的匹配是提出时间较早也最经常使用的技术。其用来计算单个元素之间的名称以及注释的相似性,具体的计算方法有计算编辑距离、计算单词前后缀相似性、Jaccard Similarity等。上述介绍的方法都是基于字符串的匹配而没有考虑各类数据库资源之间的语义关系,对于具有较多数据资源以及复杂的语义关系的本体,其准确度不能满足属性匹配的需求。
结构层匹配技术包括基于层级表(Taxonomy)的技术、基于图的技术、基于结构库(Repository of Structure)的技术、基于模型的技术和基于统计学的技术。基于层级表的匹配的其主要思想为,如果通过层级关系连接的元素相似,那么与它们相邻的元素也可能相似。基于层级表的匹配仅考虑层级关系而没有考虑同层以及跨越多层的概念之间的语义关系,其往往与外部资源结合起来使用,例如根据语义词典中概念间的上下位关系和同为关系来计算语义的相似度。
技术实现要素:
本发明的目的在于提供一种基于属性相似度的本体匹配方法。
实现本发明目的的技术方案为:一种基于属性相似度的本体匹配方法,该方法包括如下步骤:
步骤1,计算本体资源之间的字符串相似度,进行匹配粒度的锚匹配;
步骤2,对锚匹配的结果进行确认并删除不正确的锚匹配项;
步骤3,根据步骤2的锚匹配结果,对本体中的所有资源进行全匹配,包括计算本体资源的结构相似度、字符串相似度以及属性内容相似度;
步骤4,将步骤3得到的全匹配结果输出到界面,检查是否正确,并将不正确的匹配删除;
步骤5,对步骤4中全匹配的结果进行冲突检测,将冲突检测的结果返回并进行确认,修正其中的冲突。
本发明与现有技术相比,具有以下优点:
本体匹配技术通常可以分为元素层匹配技术和结构层匹配技术;元素层匹配技术只考虑独立的本体元素,而不考虑这些元素之间的关系;结构层匹配技术在匹配时考虑元素间的层级关系以及语义邻居关系等。本发明提出的匹配算法,综合应用了以上两种技术,首先利用元素层匹配技术中的编辑距离计算相似度,得到锚匹配,然后采用结构层匹配技术中的基于层级表匹配思想,搜索锚节点的邻近节点,从而扩展了匹配。
附图说明
图1是本发明基于属性相似度的本体匹配方法流程图。
图2是一个全匹配过程示意图。
图3是类相似度计算示意图。
图4是属性相似度计算示意图。
图5是冲突1示例图。
图6是冲突2示例图。
图7是冲突3示例图。
具体实施方式
结合图1,本发明的一种基于属性相似度的本体匹配方法,该方法包括如下步骤:
步骤1,计算本体资源之间的字符串相似度,进行匹配粒度的锚匹配;
步骤2,对锚匹配的结果进行确认并删除不正确的锚匹配项;
步骤3,根据步骤2的锚匹配结果,对本体中的所有资源进行全匹配,包括计算本体资源的结构相似度、字符串相似度以及属性内容相似度;
步骤4,将步骤3得到的全匹配结果输出到界面,检查是否正确,并将不正确的匹配删除;
步骤5,对步骤4中全匹配的结果进行冲突检测,将冲突检测的结果返回并进行确认,修正其中的冲突。
进一步的,所述步骤1中的锚匹配使用完全匹配的字符串相似度进行匹配,即字符串相似度为1。
进一步的,步骤1具体为:
第一步,读取同义词表,给相应的资源添加同义词;
第二步,计算资源相似度:通过字符串匹配,得到资源间的相似度,资源包括类和属性;
第三步,通过阈值筛选锚匹配:将第二步中相似度大于等于设定阈值的匹配放入锚集合。
进一步的,上述第二步中字符串匹配使用编辑距离和Jaccard相似度,对于字符串a和字符串b,其相似度的计算公式分别为公式(1)和公式(2):
上式中,LD(a,b)表示字符串a和字符串b的编辑距离,Length(a)和Length(b)分别表示字符串a和字符串b的长度,Length(a∪b)表示字符串a和字符串b字符串并集的长度,Length(a∩b)表示字符串a和字符串b交集的长度,Max函数表示求两个参数中较大的值;
字符串的相似度是在上述两种相似度中取最大值:
Sstr(A,B)=Maxa∈X,b∈Y(Max(SLD(a,b),SJS(a,b))) (3)
其中,X表示数据库资源A的字符串名称集合,包括字符串自身及其同义词,Y表示数据库资源B的字符串名称集合。
进一步的,步骤3全匹配的具体过程为:
步骤3-1,设一个待匹配节点集合M为空,一个查询节点集合S为空;
步骤3-2,将锚节点都放入S,锚匹配包含有两个节点,分别来自两个本体;
步骤3-3,搜索S集合的所有邻近节点,逐一检查其是否包含在S集合中,将不包含的邻近节点加入集合S’,搜索完后,将S’中的所有节点同时加入到集合S和集合M;
步骤3-4,如果S’不为空,则进入步骤3-5;如果S’为空,S中的资源数少于两个本体的总资源数,则将没有包含在S中的资源同时放入集合S和集合M,进入步骤3-5;
步骤3-5,分别计算集合M中本体O1到本体O2类间的相似度和属性间的相似度,具体为:
(1)计算类的相似度
假设有两个类节点A,B,他们的相似度计算公式如下:
SC(A,B)=0.5*Sstr(A,B)+0.2*Ssuperclass(A,B)+0.2*Ssubclass(A,B)+0.1*Sproperty(A,B) (4)
其中,Sstr(A,B)是两个数据库资源A、B的字符串相似度,Ssuperclass(A,B)为A,B的父类的相似度,Ssubclass(A,B)为A,B的子类的相似度,Sproperty(A,B)为A,B的相关属性的相似度;
式中,ca,cb分别为A和B的父节点,A.surperclass和B.surperclass分别为A和B的所有父节点的集合;
式中,ca′,cb′分别为A和B的子节点,A.subclass和B.subclass分别为A和B的所有子节点的集合;
A的所有相关属性集合为PA,B的所有相关属性集合为PB,不妨设pa属于PA,pb属于PB,Sp(pa,pb)表示属性pa和pb的相似度;
则A,B的相关属性的相似度为所有相关属性相似度中的最大相似度:
(2)计算属性的相似度
pa和pb的相似度为
式中,Sdomain(pa,pb)为属性pa和pb的domain相似度,Srange(pa,pb)为属性pa和pb的range相似度,Sstr(pa,pb)为属性pa和pb的字符串相似度,Ssubproperty(pa,pb)为子属性的相似度,Ssuperproperty(pa,pb)为父属性的相似度;
Sdomain(pa,pb)=Sc(domain(pa),domain(pb)) (9)
Sc(domain(pa),domain(pb))为两个属性定义域包含的类的相似度;
Srange(pa,pb)=Sc(range(pa),range(pb)) (10)
Sc(range(pa),range(pb))为两个属性值域包含的类的相似度;
为pa和pb子属性的最大相似度;
为pa和pb父属性的最大相似度。
进一步的,步骤5检测的冲突包括:
冲突1:两个属性是匹配的,而其domain和range均不匹配;
冲突2:一个本体中的多个资源和另一个本体的一个资源是匹配的;
冲突3:一个本体中的资源的层次关系,匹配到另一个本体的颠倒的层次关系中。
下面结合具体实施例对本发明做进一步说明。
实施例
本发明的基于属性相似度的本体匹配方法包括以下步骤:
步骤1)锚匹配,是本体匹配过程的基础,是初始确认的相似度为1的资源对。由于锚匹配仅仅是通过字符串相似度快速搜索出来的,一般情况下数量较少,用户很容易就能确认一遍。再通过用户确认锚匹配集合,逐步将锚匹配相关的资源放入待匹配集合计算相似度,这样递归的逐步将所有的资源都放入待匹配集合计算相似度,具体步骤为:
第一步,读取同义词表,给相应的资源添加同义词。同义词表是数据库的管理员事前导入的,由于管理员熟悉数据,知道数据库中有哪些资源,资源名的同义词有哪些,然后将原词和同义词一对一对的写入同义词表。这样待匹配的本体导入后,可以通过查询同义词表,将每个资源名的同义词记录下来,可以简洁有效地提高匹配进度。例如,有“笔记本电脑”两个“手提电脑”两个资源,系统仅仅通过字符串计算相似度,很可能认为这两个资源是不匹配的,但实际情况是这两个资源是可以匹配的。如果在同义词表中写入“笔记本电脑,手提电脑”这个同义词对,当本体导入后,通过查询同义词表,知道“笔记本电脑”和“手提电脑”是同义词,那么这两个资源很容易的就能匹配。
第二步,计算资源相似度。这里是通过字符串匹配,得到资源间的相似度,资源包括类和属性。本体匹配的时候,资源名称的字符串相似度往往对资源整体的相似度有极为重要的影响,而且名称相同的资源,往往都是匹配的。而且计算字符串相似度的复杂度较低,可以很快得出匹配结果,所以在搜索锚匹配的时候通过计算字符串相似度来计算资源的相似度最合适。
第三步,通过阈值筛选锚匹配。将第二步中相似度大于等于阈值0.8的匹配放入锚集合。这里阈值通过配置文件调节,对于不同的本体,最优的阈值不相同。
步骤2)确认锚匹配的结果。将前面搜索到的锚集合的所有结果输出,对每个匹配一一确认是否要删除,确认后,剩下没有删除的就是锚集合。这里确认的锚匹配表示其对应的资源对是完全相似的,需要将其匹配相似度设为1。
步骤3)全匹配。根据步骤2)的锚匹配结果,对本体中的所有资源进行全面的匹配,包括计算本体资源的结构相似度、字符串相似度以及属性内容相似度。该步骤利用上步中得到的锚匹配,逐步做锚匹配相邻资源的匹配。分别考虑类的相似度计算公式和属性的相似度计算公式,两者不尽相同但是联系紧密。类的相似度计算需要考虑相关属性的相似度,属性的相似度计算需要考虑属性定义域和值域的类相似度。当两个本体所有的资源都匹配后,取出大于阈值的所有匹配结果供用户检查。
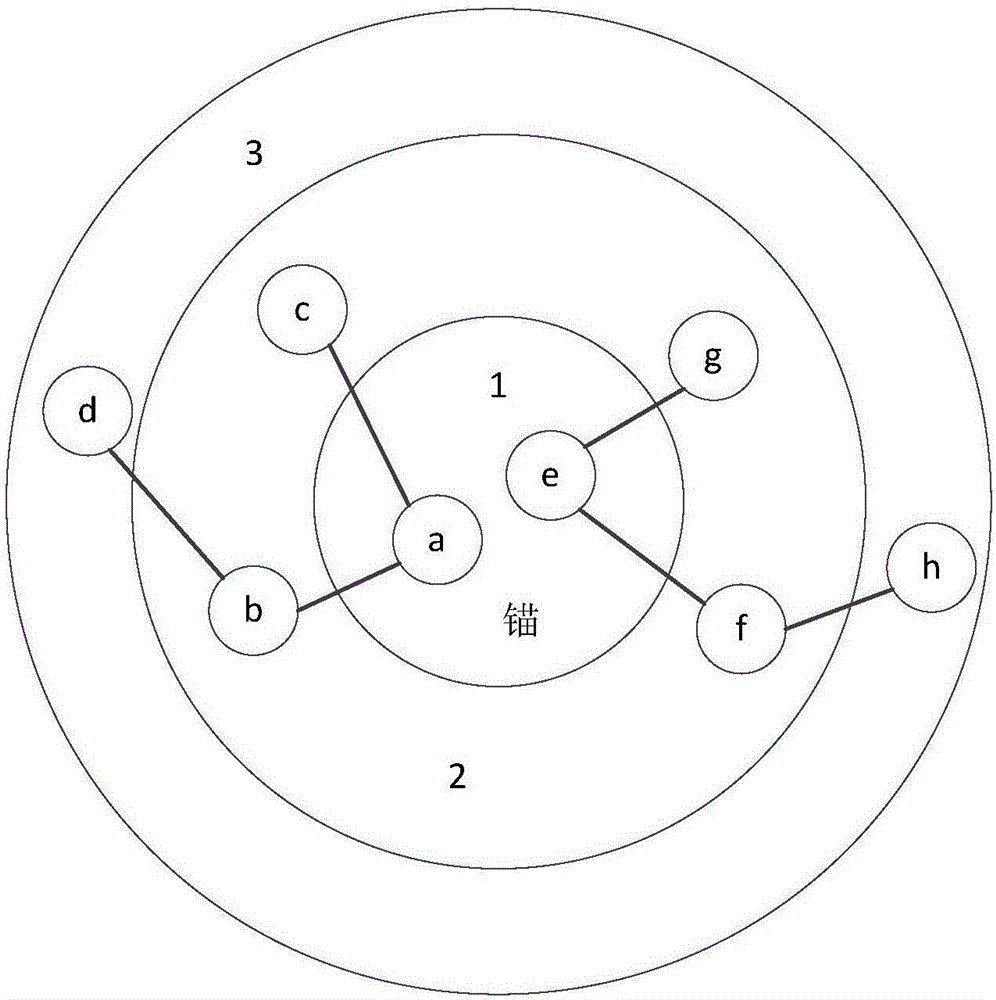
如图2所示,是一个简单的全匹配过程的示意图。首先在第1步中有锚匹配(a,e);然后在第2步中我们将a相关资源b、c,和e的相关资源g、f放入待匹配集合,计算{b,c,f,g}这四个节点间的相似度,这样在计算这四个节点的相似度的时候,就可以考虑与他们有结构关联的a和e的相似度;在第3步中,我们再将{b,c,f,g}相关的资源d和h放入待匹配集合,继续计算{b,c,d,f,g,h}这六个节点间的相似度,这样在计算新加入的节点d和h与其他节点的相似度的时候,就可以考虑与其结构上有联系的资源在第2步中已经计算出的相似度信息,使得语义相似度计算更加准确。本发明中的本体全匹配算法不仅要考虑资源的字符串相似度,也要考虑结构相似度,也就是要考虑资源邻近节点的相似度,在前面的概念中可以看出,一个类的邻近节点不仅有类还有属性,一个属性的邻近节点不仅有属性还有类,因此计算类间的相似度的时候要考虑属性的相似度,计算属性间的相似度的时候也要考虑类的相似度,两者是紧密关联,将本体全匹配构成了一个整体。其具体步骤如下:
第一步,设一个待匹配节点集合M为空;一个查询节点集合S为空;
第二步,将锚节点(即锚匹配包含有两个节点,分别来自两个本体)都放入S;
第三步,搜索S集合的所有邻近节点,逐一检查其是否包含在S集合中,将不包含的邻近节点加入集合S’,搜索完后,将S’中的节点加入集合S和集合M;
第四步,如果S’不为空,则进入5;如果S’为空,S中的资源数少于两个本体的总资源数,则要将没有包含在S中的资源全放入S和M,进入5;
第五步,计算M中节点的相似度,节点有类和属性,我们分别计算M中本体O1到本体O2类间的相似度和属性间的相似度,如图3和图4所示。
步骤4)将步骤3)得到的匹配结果输出到界面,供用户检查是否正确,并将不正确的匹配删除,这样剩下的就是所有的匹配结果。
步骤5)冲突检测。用户确认匹配结果后,因为之后要做本体融合,所以要进行本体冲突检测。主要的检测方面有:
冲突1:两个属性是匹配的,而其domain和range均不匹配,如图5所示;
冲突2:一个本体中的多个资源和另一个本体的一个资源是匹配的,如图6所示;
冲突3:一个本体中的资源的层次关系,匹配到另一个本体的颠倒的层次关系中,如图7所示。
上述实施例仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和等同替换,这些对本发明权利要求进行改进和等同替换后的技术方案,均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!