基于位置服务的个人健康状态评估方法及装置与流程
本发明涉及信息处理技术领域,尤其涉及一种基于位置服务的个人健康状态评估方法及装置。
背景技术:
健康保险(Health insurance)是当前保险机构所提供的保险业务中的一项重要险种,是以被保险人的身体为保险标的,使被保险人在疾病或意外事故所致伤害时发生的费用或损失获得补偿的保险。保险机构在给用户提供健康保险业务时,需先评估用户的个人健康状态,再根据用户的个人健康状态决定是否给该用户办理健康保险。
当前健康保险办理过程中,用户个人健康状况的评估主要采用如下方式:其一是,机构人员通过调查问卷或者当面询问方式了解用户的健康习惯和病历等信息,进而评估用户个人健康状态。该评估方式中,用户在回答调查问卷或者机构人员所提出的问题时具有较强的主观性、随意性和不确定性,即用户可能隐瞒个人健康状态,使得评估结果无法真实反映用户的个人健康状态。其二是,机构人员通过查看用户的得病记录来了解用户的个人健康状态。该评估方式中,用户可能提供虚假的得病记录以隐瞒个人健康状态,保险机构无法进行准确性核实;而且,在保险业务实际办理过程中,只有少数用户持有得病记录,得病记录的数据饱和度很低,无法更好地应用在保险机构办理健康保险业务过程中。现有个人健康状态评估方式获取的个人健康状态存在客观性低的缺陷,无法真实客观地反映用户的个人健康状态的问题。
技术实现要素:
本发明要解决的技术问题在于,针对现有个人健康状态评估方式获得的个人健康状态存在客观性低的缺陷,提供一种基于位置服务的个人健康状态评估方法及装置。
本发明解决其技术问题所采用的技术方案是:一种基于位置服务的个人健康状态评估方法,包括:
基于位置服务获取用户的地理位置信息,所述地理位置信息包括与时间相关联的POI信息;
对任一用户在预设期间内所有的POI信息进行聚类分析,获取地理位置动态特征;
基于所述地理位置动态特征,获取与所述地理位置动态特征相对应的用户健康评分;
基于所述用户健康评分和训练好的有监督学习模型,获取个人健康状态评估结果。
优选地,还包括:获取用户的用户健康评分和医疗健康信息;将所述用户健康评分和所述医疗健康信息输入机器学习模型中进行逻辑回归处理,以获取所述训练好的有监督学习模型。
优选地,所述对任一用户在预设期间内所有的POI信息进行聚类分析,获取地理位置动态特征,包括:
采用DBSCAN聚类算法对任一用户在预设期间内所有的POI信息进行聚类,以获取若干子集群;
采用K-MEANS聚类算法对每一所述子集群进行迭代聚合,以获取每一所述子集群的质心POI信息,将所述质心POI信息作为所述地理位置动态特征输出。
优选地,所述基于所述地理位置动态特征,获取与所述地理位置动态特征相对应的用户健康评分,包括:
确定每一所述地理位置动态特征所属的健康特征,所述健康特征包括生活习惯特征、锻炼习惯特征和就医习惯特征;
基于每一所述健康特征对应的所有地理位置动态特征的频率和时间确定所述健康特征分值;
采用预设健康评分模型对所述健康特征分值进行处理,获取所述用户健康评分。
优选地,所述预设健康评分模型包括X=∑Si*Wi;X为用户健康评分,i是健康特征,Si是健康特征i对应的分值,Wi是健康特征i对应的权重;所述健康特征包括生活习惯特征、锻炼习惯特征和就医习惯特征,还包括年龄特征、医保使用特征和商保使用特征。
本发明还提供一种基于位置服务的个人健康状态评估装置,包括:
信息获取单元,用于基于位置服务获取用户的地理位置信息,所述地理位置信息包括与时间相关联的POI信息;
聚类分析单元,用于对任一用户在预设期间内所有的POI信息进行聚类分析,获取地理位置动态特征;
健康评分获取单元,用于基于所述地理位置动态特征,获取与所述地理位置动态特征相对应的用户健康评分;
评估结果获取单元,用于基于所述用户健康评分和训练好的有监督学习模型,获取个人健康状态评估结果。
优选地,还包括学习模型训练单元,用于获取用户的用户健康评分和医疗健康信息;将所述用户健康评分和所述医疗健康信息输入机器学习模型中进行逻辑回归处理,以获取所述训练好的有监督学习模型。
优选地,所述聚类分析单元包括:
第一聚类子单元,用于采用DBSCAN聚类算法对任一用户在预设期间内所有的POI信息进行聚类,以获取若干子集群;
第二聚类子单元,用于采用K-MEANS聚类算法对每一所述子集群进行迭代聚合,以获取每一所述子集群的质心POI信息,将所述质心POI信息作为所述地理位置动态特征输出。
优选地,所述健康评分获取单元包括:
健康特征获取子单元,用于确定每一所述地理位置动态特征所属的健康特征,所述健康特征包括生活习惯特征、锻炼习惯特征和就医习惯特征;
健康分值获取子单元,用于基于每一所述健康特征对应的所有地理位置动态特征的频率和时间确定所述健康特征分值;
健康评分获取子单元,用于采用预设健康评分模型对所述健康特征分值进行处理,获取所述用户健康评分。
优选地,所述预设健康评分模型包括X=∑Si*Wi;X为用户健康评分,i是健康特征,Si是健康特征i对应的分值,Wi是健康特征i对应的权重;所述健康特征包括生活习惯特征、锻炼习惯特征和就医习惯特征,还包括年龄特征、医保使用特征和商保使用特征。
本发明与现有技术相比具有如下优点:本发明所提供的基于位置服务的个人健康状态评估方法及装置中,通过对获取到的用户在预设期间内的地理位置信息进行聚类分析以获取地理位置动态特征;并基于地理位置动态特征获取对应的用户健康评分;再将用户健康评分输入训练好的有监督学习模型进行处理,以获取最终的个人健康状态评估结果,此过程不受用户主观因素影响,可显著提高用户个人健康状态评估结果的客观性和准确性。而且,该基于位置服务的个人健康状态评估方法及装置中,可基于任一用户的用户健康评分获取对应的个人健康状态评估结果,数据饱和度高、覆盖率广,能够更精准地评估用户个人健康状态,以解决现有技术中因用户得病记录缺失无法评估用户的个人健康状态的问题。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明实施例1中基于位置服务的个人健康状态评估方法的一流程图。
图2是本发明实施例2中基于位置服务的个人健康状态评估装置的一原理框图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
实施例1
图1示出本实施例中的基于位置服务的个人健康状态评估方法的一流程图。该基于位置服务的个人健康状态评估方法的工作原理是通过采集用户在一段时间内的活动轨迹,基于客观存在的活动轨迹与个人健康状态的关联关系,推定用户的个人健康状态,以提高评估出的个人健康状态的客观性。如图1所示,基于位置服务的个人健康状态评估方法包括:
S1:基于位置服务获取用户的地理位置信息,地理位置信息包括与时间相关联的POI信息。
以任一用户一天的地理位置信息为例,该地理位置信息中包括0:00—24:00的POI信息,每一POI信息用于指示电子地图中的一点,包括POI点名称、经度和纬度等信息。基于用户的地理位置信息,可了解用户每天经过的家庭住址、办公场所、上下班时间、常去的娱乐、购物、健身等信息。可以理解地,基于位置服务获取用户的地理位置信息,具有较强的客观性和可靠性。
基于位置服务(Location Based Service,简称LBS)是通过电信移动运营商的无线电通讯网络(如GSM网、CDMA网)或外部定位方式(如GPS)获取移动终端用户的位置信息(地理坐标,或大地坐标),在地理信息系统(Geographic Information System,简称GIS)平台的支持下,为用户提供相应服务的一种增值业务。总体来看,LBS由移动通信网络和计算机网络结合而成,两个网络之间通过网关实现交互。移动终端通过移动通信网络发出请求,经过网关传递给LBS服务平台;LBS服务平台根据用户请求和用户当前位置进行处理,并将结果通过网关返回给用户。POI(Point Of Interest,即兴趣点或信息点),包括名称、类型、经度、纬度等资料,以使POI可在电子地图上呈现,以标示电子地图上的某个地标、景点等地点信息。
本实施例中,基于位置服务的移动终端为智能手机,通过开启智能手机上的定位功能,以使LBS服务平台实时获取智能手机的地理位置信息,从而了解携带该智能手机的用户的地理位置信息。地理位置信息包括与时间相关联的POI信息中的时间包括日期和时刻,通过该地理位置信息可了解用户在任一时刻所处的POI信息。可以理解地,地理位置信息与用户ID相关联,用户ID用于识别唯一识别用户,可以是身份证号或手机号。
可以理解地,为了减少数据处理量,提高处理效率,可预先设置时间阈值,以使基于位置服务获取用户的地理位置信息时,只获取用户在任一地点停留时间达到该时间阈值的POI信息,以避免采集到的与时间相关联的POI信息的数据量较多,导致处理效率低的问题。
S2:对任一用户在预设期间内所有的POI信息进行聚类分析,获取地理位置动态特征。
其中,地理位置动态特征是对用户在预设期间内所有POI信息进行聚类分析的结果,可体现用户的日常活动轨迹。其中,预设期间可以是当前系统时间之前的任意一段时间,可以为一周、一个月、三个月或半年,可根据需求自主设置。可以理解地,预设期间越长,其采集到的地理位置信息的数据量越多,处理结果的准确性越高;预设期间越短,其处理效率越高。
进一步地,步骤S2具体包括如下步骤:
S21:采用DBSCAN聚类算法对任一用户在预设期间内所有的POI信息进行聚类,以获取若干子集群。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。DBSCAN算法具有聚类速度快且能够有效处理噪声和发现任意形成的空间聚类的优点。
具体地,预设扫描半径(以下简称为eps)和最小包含点数(minPts),任选一个未被访问(unvisited)的POI信息开始,找出与其距离在eps之内(包括eps)的所有POI信息,将POI信息与距离在eps之内的所有POI信息作为一个子集群输出,以将用户所有POI信息在电子地图上划分出若干常去场所,即每一子集群对应一常去场所。
S22:采用K-MEANS聚类算法对每一子集群进行迭代聚合,以获取每一子集群的质心POI信息,将质心POI信息作为地理位置动态特征输出。
K-MEANS算法是很典型的基于距离的算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。其计算公式为其中,k个初始类聚类中心点的选取对聚类结果具有较大的影响,因为在该算法第一步中是随机的选取任意k个对象作为初始聚类的中心,初始地代表一个簇。该算法在每次迭代中对数据集中剩余的每个对象,根据其与各个簇中心的距离将每个对象重新赋给最近的簇。若一次迭代前后,J的值没有发生变化,说明算法已经收敛。K-MEANS算法可快速简单地对数据进行聚类,对大数据集具有较高的效率且可伸缩性,时间复杂度近于线性,而且适合挖掘大规模数据集。
本实施例中,采用K-MEANS算法对每一子集群中的POI信息进行迭代聚合,直到最后一次迭代时,迭代前后数值没有发生变化,则获取该子集群的质心POI信息,将每一质心POI信息作为一地理位置动态特征输出。
若用户某天的地理位置信息包括与时间相关联的如下POI信息:A、B、C、D、E、F、G、H、F、I、J、K……E、D、A,若A为家庭住址,B和C分别为家庭住址附近eps内的地点,D和E为工作路上获取的地点,F为办公地址,G为办公地址附近eps内的地点,H、I、J、K为消费场所等。步骤S21中采用DBSCAN聚类算法进行聚类时,通过设置扫描半径(eps)和最小包含点数(minPts),例如可将家庭住址和家庭住址附近eps内所有的POI信息聚类为一子集群输出,将办公场所和办公场所附近eps内所有的POI信息聚类为另一子集群输出。步骤S22对每一子集群采用K-MEANS聚类算法进行迭代聚合,以获取每一子集群的质心POI信息,将每一质心POI信息作为一地理位置动态特征输出。
S3:基于地理位置动态特征,获取与地理位置动态特征相对应的用户健康评分。
由于地理位置动态特征是通过对基于位置服务获取到的地理位置信息进行聚类分析获取到的,其过程不受人为因素影响,使得基于地理位置动态特征获取到的用户健康评分同样不受人为因素影响,客观性强。
进一步地,步骤S3具体包括如下步骤:
S31:确定每一地理位置动态特征所属的健康特征,健康特征包括生活习惯特征、锻炼习惯特征和就医习惯特征。
其中,生活习惯特征包括上班时间在办公场所的上班特征、下班时间在办公场所的加班特征、上班时间离开办公场所的出差特征和夜间在娱乐场所的夜间娱乐特征等。锻炼习惯特征包括在公园、健身房等锻炼场所特征。就医活动特征包括在医院、药店等医疗场所特征。可以理解地,在对用户在预设期间内所有的POI信息进行聚类分析时,可基本确定该用户的上下班时间、办公场所、家庭住址等基本信息。
S32:基于每一健康特征对应的所有地理位置动态特征的频率和时间确定健康特征分值。
由于健康特征包括生活习惯特征、锻炼习惯特征和就医习惯特征,相应地,健康特征分值包括生活习惯特征的分值、锻炼习惯特征的分值和就医习惯特征的分值。以锻炼习惯特征的分值为例,锻炼习惯特征的分值根据用户在公园、健身房等锻炼场所的频率和时间确定。以30岁的成年人每周锻炼10小时最佳,对应的分值为100;若用户在一周内在公园、健身房等锻炼场所的时间达到10小时,则其对应的锻炼习惯特征的分值为100分;每小于1小时,则其对应的锻炼习惯特征的分值减小10。同理,可确定生活习惯特征的分值和就医习惯特征的分值。
S33:采用预设健康评分模型对健康特征分值进行处理,获取用户健康评分。
其中,预设健康评分模型包括X=∑Si*Wi;X为用户健康评分,i是健康特征,Si是健康特征i对应的分值,Wi是健康特征i对应的权重;健康特征不仅包括生活习惯特征、锻炼习惯特征、就医习惯特征等可通过地理位置信息确定的特征,还包括年龄特征、医保使用特征和商保使用特征等客观特征。可以理解地,每一健康特征对应的权重依据该健康特征对个人健康状态的影响程度确定。
S4:基于用户健康评分和训练好的有监督学习模型,获取个人健康状态评估结果。
可以理解地,在训练好的有监督学习模型中,输入用户健康评分,即可输出个人健康状态评估结果,以使保险机构可基于个人健康状态评估结果,客观了解办理健康保险的用户的个人健康状态。由于个人健康状态评估结果不是通过用户反馈的问卷内容或者自主提供的得病记录获取,不受用户主观因素影响,可显著提高用户个人健康状态评估结果的准确性和客观性。而且,该基于位置服务的个人健康状态评估方法,可基于任一用户健康评分和训练好的有监督学习模型,获取相应的个人健康状态评估结果,其数据饱和度高、覆盖率广,能够更精准地评估用户个人健康状态,可解决现有技术中因用户得病记录缺失无法评估用户的个人健康状态的问题。
进一步地,该基于位置服务的个人健康状态评估方法还包括:获取任一用户的用户健康评分和医疗健康信息;将用户健康评分和医疗健康信息输入机器学习模型中进行逻辑回归处理,以获取训练好的有监督学习模型。
其中,医疗健康信息可以是保险机构从各大医疗机构中获取得到的,将用户的医疗健康信息和用户健康评分作为有监督学习模型的训练集,用于训练有监督学习模型,从而实现基于用户健康评分和训练好的有监督学习模型对未知医疗健康信息的个人健康状态评估。
其中,逻辑回归(Logistic Regression)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性。逻辑回归(Logistic Regression)是一个被logistic方程归一化后的线性回归。在逻辑回归(Logistic Regression)中,若设样本是{x,y},y是0或者1,表示正类或者负类,x是我们的m维的样本特征向量。那么这个样本x属于正类,也就是y=1的“概率”可以通过下面的逻辑函数来表示:
其中,θ是模型参数,也就是回归系数,σ是sigmoid函数。实际上这个函数是由下面的对数几率(也就是x属于正类的可能性和负类的可能性的比值的对数)变换得到的:
本实施例所提供的基于位置服务的个人健康状态评估方法中,通过对获取到的用户在预设期间内的地理位置信息进行聚类分析以获取地理位置动态特征;并基于地理位置动态特征获取对应的用户健康评分;再将用户健康评分输入训练好的有监督学习模型进行处理,以获取最终的个人健康状态评估结果,此过程不受用户主观因素影响,可显著提高用户个人健康状态评估结果的客观性和准确性。而且,该基于位置服务的个人健康状态评估方法中,可基于任一用户的用户健康评分获取对应的个人健康状态评估结果,数据饱和度高、覆盖率广,能够更精准地评估用户个人健康状态,可解决现有技术中因用户得病记录缺失无法评估用户的个人健康状态的问题。
在一具体实施例中,设有10000个用户在保险机构中办理健康保险,其中30%的用户的医疗健康信息可从各大医疗机构的数据库中获取,该医疗健康信息包括但不限于体检信息;其余70%的用户未在各大医疗机构办理过相应的体检信息,无法获取其对应的医疗健康信息。保险机构通过获取10000个用户的地理位置信息;并对预设期间内任一用户的POI信息进行聚类分析后获取地理位置动态特征;再采用预设健康评分模型对地理位置动态特征进行处理,以获取10000个用户对应的用户健康评分;再将10000*30%个用户的用户健康信息和医疗健康信息输入机器学习模型,进行逻辑回归处理,以输出训练好的有监督学习模型;然后将10000*70%个用户的用户健康信息输入训练好的有监督学习模型,以获取未知医疗健康信息的用户的个人健康状态评估结果。
本实施例所提供的基于位置服务的个人健康状态评估方法,基于用户在预设期间内的地理位置信息进行处理,以获取最终的个人健康状态评估结果,此过程不受用户主观因素影响,可显著提高用户个人健康状态评估结果的客观性和准确性。而且,该基于位置服务的个人健康状态评估方法中,将同时存在用户健康评分和对应的医疗健康信息的所有数据集作为机器学习模型的训练集,通过对所有医疗健康信息和用户健康评进行逻辑回归处理,以获取训练好的有监督学习模型;再基于训练好的有监督学习模型对不存在医疗健康信息的任一用户的用户健康评分进行处理,输出对应的个人健康状态评估结果。该基于位置服务的个人健康状态评估方法的数据饱和度高、覆盖率广,能够更精准地评估用户个人健康状态,以解决现有技术中因用户得病记录缺失无法评估用户的个人健康状态的问题。
实施例2
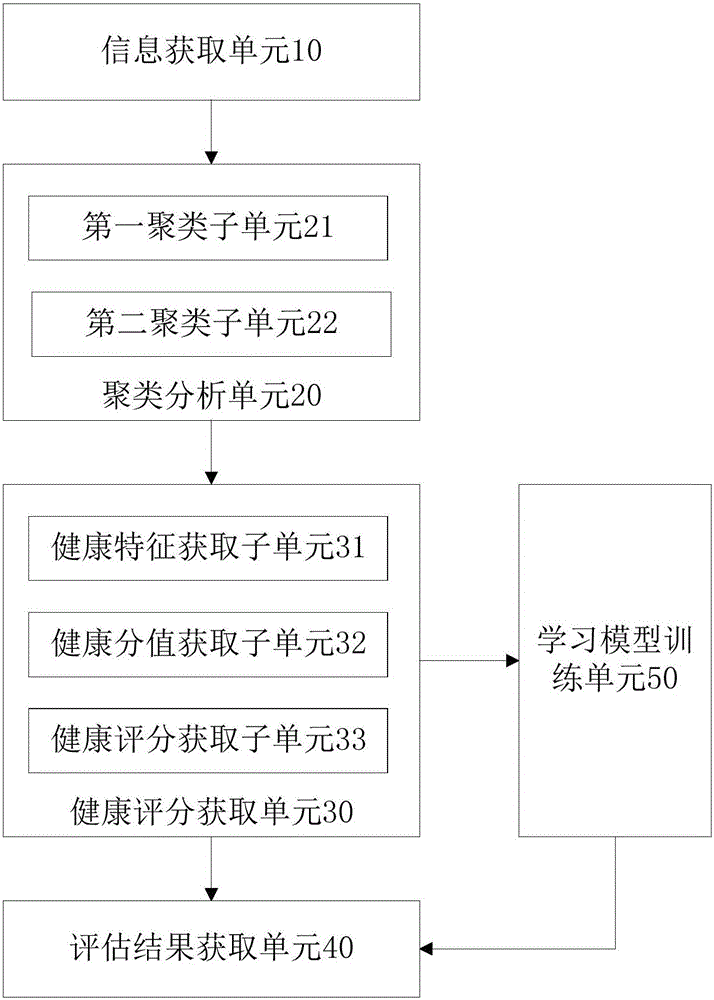
图2示出本实施例中的基于位置服务的个人健康状态评估装置的一原理框图。该基于位置服务的个人健康状态评估装置的工作原理是通过采集用户在一段时间内的活动轨迹,基于客观存在的活动轨迹与个人健康状态的关联关系,推定用户的个人健康状态,以提高评估出的个人健康状态的客观性。如图2所示,基于位置服务的个人健康状态评估装置包括信息获取单元10、聚类分析单元20、健康评分获取单元30、评估结果获取单元40和学习模型训练单元50。
信息获取单元10,用于基于位置服务获取用户的地理位置信息,地理位置信息包括与时间相关联的POI信息。
以任一用户一天的地理位置信息为例,该地理位置信息中包括0:00—24:00的POI信息,每一POI信息用于指示电子地图中的一点,包括POI点名称、经度和纬度等信息。基于用户的地理位置信息,可了解用户每天经过的家庭住址、办公场所、上下班时间、常去的娱乐、购物、健身等信息。可以理解地,基于位置服务获取用户的地理位置信息,具有较强的客观性和可靠性。基于位置服务(Location Based Service,简称LBS)是通过电信移动运营商的无线电通讯网络(如GSM网、CDMA网)或外部定位方式(如GPS)获取移动终端用户的位置信息(地理坐标,或大地坐标),在地理信息系统(Geographic Information System,简称GIS)平台的支持下,为用户提供相应服务的一种增值业务。总体来看,LBS由移动通信网络和计算机网络结合而成,两个网络之间通过网关实现交互。移动终端通过移动通信网络发出请求,经过网关传递给LBS服务平台;LBS服务平台根据用户请求和用户当前位置进行处理,并将结果通过网关返回给用户。POI(Point Of Interest,即兴趣点或信息点),包括名称、类型、经度、纬度等资料,以使POI可在电子地图上呈现,以标示电子地图上的某个地标、景点等地点信息。
本实施例中,基于位置服务的移动终端为智能手机,通过开启智能手机上的定位功能,以使LBS服务平台实时获取智能手机的地理位置信息,从而了解携带该智能手机的用户的地理位置信息。地理位置信息包括与时间相关联的POI信息中的时间包括日期和时刻,通过该地理位置信息可了解用户在任一时刻所处的POI信息。可以理解地,地理位置信息与用户ID相关联,用户ID用于识别唯一识别用户,可以是身份证号或手机号。
可以理解地,为了减少数据处理量,提高处理效率,可预先设置时间阈值,以使基于位置服务获取用户的地理位置信息时,只获取用户在任一地点停留时间达到该时间阈值的POI信息,以避免采集到的与时间相关联的POI信息的数据量较多,导致处理效率低的问题。
聚类分析单元20,用于对任一用户在预设期间内所有的POI信息进行聚类分析,获取地理位置动态特征。
其中,地理位置动态特征是对用户在预设期间内所有POI信息进行聚类分析的结果,可体现用户的日常活动轨迹。其中,预设期间可以是当前系统时间之前的任意一段时间,可以为一周、一个月、三个月或半年,可根据需求自主设置。可以理解地,预设期间越长,其采集到的地理位置信息的数据量越多,处理结果的准确性越高;预设期间越短,其处理效率越高。
聚类分析单元20具体包括第一聚类子单元21和第二聚类子单元22。
第一聚类子单元21,用于采用DBSCAN聚类算法对任一用户在预设期间内所有的POI信息进行聚类,以获取若干子集群。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类装置)是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
具体地,预设扫描半径(以下简称为eps)和最小包含点数(minPts),任选一个未被访问(unvisited)的POI信息开始,找出与其距离在eps之内(包括eps)的所有POI信息,将POI信息与距离在eps之内的所有POI信息作为一个子集群输出,以将用户所有POI信息在电子地图上划分出若干常去场所,即每一子集群对应一常去场所。
第二聚类子单元22,用于采用K-MEANS聚类算法对每一子集群进行迭代聚合,以获取每一子集群的质心POI信息,将质心POI信息作为地理位置动态特征输出。
K-MEANS算法是很典型的基于距离的算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。其计算公式为其中,k个初始类聚类中心点的选取对聚类结果具有较大的影响,因为在该算法第一步中是随机的选取任意k个对象作为初始聚类的中心,初始地代表一个簇。该算法在每次迭代中对数据集中剩余的每个对象,根据其与各个簇中心的距离将每个对象重新赋给最近的簇。若一次迭代前后,J的值没有发生变化,说明算法已经收敛。K-MEANS算法可快速简单地对数据进行聚类,对大数据集具有较高的效率且可伸缩性,时间复杂度近于线性,而且适合挖掘大规模数据集。
本实施例中,采用K-MEANS算法对每一子集群中的POI信息进行迭代聚合,直到最后一次迭代时,迭代前后数值没有发生变化,则获取该子集群的质心POI信息,将每一质心POI信息作为一地理位置动态特征输出。
若用户某天的地理位置信息包括与时间相关联的如下POI信息:A、B、C、D、E、F、G、H、F、I、J、K……E、D、A,若A为家庭住址,B和C分别为家庭住址附近eps内的地点,D和E为工作路上获取的地点,F为办公地址,G为办公地址附近eps内的地点,H、I、J、K为消费场所等。第一聚类子单元21采用DBSCAN聚类算法进行聚类时,通过设置扫描半径(eps)和最小包含点数(minPts),例如可将家庭住址和家庭住址附近eps内所有的POI信息聚类为一子集群输出,将办公场所和办公场所附近eps内所有的POI信息聚类为另一子集群输出等。第二聚类子单元22对每一子集群采用K-MEANS聚类算法进行迭代聚合,以获取每一子集群的质心POI信息,将每一质心POI信息作为一地理位置动态特征输出。
健康评分获取单元30,用于基于地理位置动态特征,获取与地理位置动态特征相对应的用户健康评分。
由于地理位置动态特征是通过对基于位置服务获取到的地理位置信息进行聚类分析获取到的,其过程不受人为因素影响,使得基于地理位置动态特征获取到的用户健康评分同样不受人为因素影响,客观性强。
进一步地,健康评分获取单元30具体包括健康特征获取子单元31、健康分值获取子单元32和健康评分获取子单元33。
健康特征获取子单元31,用于确定每一地理位置动态特征所属的健康特征,健康特征包括生活习惯特征、锻炼习惯特征和就医习惯特征。
其中,生活习惯特征包括上班时间在办公场所的上班特征、下班时间在办公场所的加班特征、上班时间离开办公场所的出差特征和夜间在娱乐场所的夜间娱乐特征等。锻炼习惯特征包括在公园、健身房等锻炼场所特征。就医活动特征包括在医院、药店等医疗场所特征。可以理解地,在对用户在预设期间内所有的POI信息进行聚类分析时,可基本确定该用户的上下班时间、办公场所、家庭住址等基本信息。
健康分值获取子单元32,用于基于每一健康特征对应的所有地理位置动态特征的频率和时间确定健康特征分值。
由于健康特征包括生活习惯特征、锻炼习惯特征和就医习惯特征,相应地,健康特征分值包括生活习惯特征的分值、锻炼习惯特征的分值和就医习惯特征的分值。以锻炼习惯特征的分值为例,锻炼习惯特征的分值根据用户在公园、健身房等锻炼场所的频率和时间确定。以30岁的成年人每周锻炼10小时最佳,对应的分值为100;若用户在一周内在公园、健身房等锻炼场所的时间达到10小时,则其对应的锻炼习惯特征的分值为100分;每小于1小时,则其对应的锻炼习惯特征的分值减小10。同理,可确定生活习惯特征的分值和就医习惯特征的分值。
健康评分获取子单元33,用于采用预设健康评分模型对健康特征分值进行处理,获取用户健康评分。
其中,预设健康评分模型包括X=∑Si*Wi;X为用户健康评分,i是健康特征,Si是健康特征i对应的分值,Wi是健康特征i对应的权重;健康特征不仅包括生活习惯特征、锻炼习惯特征、就医习惯特征等可通过地理位置信息确定的特征,还包括年龄特征、医保使用特征和商保使用特征等客观特征。可以理解地,每一健康特征对应的权重依据该健康特征对个人健康状态的影响程度确定。
评估结果获取单元40,用于基于用户健康评分和训练好的有监督学习模型,获取个人健康状态评估结果。
可以理解地,在训练好的有监督学习模型中,输入用户健康评分,即可输出个人健康状态评估结果,以使保险机构可基于个人健康状态评估结果客观了解办理健康保险的用户的个人健康状态。由于个人健康状态评估结果不是通过用户反馈的问卷内容或者自主提供的得病记录获取,不受用户主观因素影响,可显著提高用户个人健康状态评估结果的准确性和客观性。而且,该基于位置服务的个人健康状态评估装置可基于任一用户健康评分和训练好的有监督学习模型,获取相应的个人健康状态评估结果,其数据饱和度高、覆盖率广,能够更精准地评估用户个人健康状态,可解决现有技术中因用户得病记录缺失无法评估用户的个人健康状态的问题。
进一步地,该基于位置服务的个人健康状态评估装置还包括学习模型训练单元50,用于获取任一用户的用户健康评分和医疗健康信息;将用户健康评分和医疗健康信息输入机器学习模型中进行逻辑回归处理,以获取训练好的有监督学习模型。
其中,医疗健康信息可以是保险机构从各大医疗机构中获取得到的,将用户的医疗健康信息和用户健康评分作为有监督学习模型的训练集,用于训练有监督学习模型,从而实现基于用户健康评分和训练好的有监督学习模型对未知医疗健康信息的个人健康状态评估。
其中,逻辑回归(Logistic Regression)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性。逻辑回归(Logistic Regression)是一个被logistic方程归一化后的线性回归。在逻辑回归(Logistic Regression)中,若设样本是{x,y},y是0或者1,表示正类或者负类,x是我们的m维的样本特征向量。那么这个样本x属于正类,也就是y=1的“概率”可以通过下面的逻辑函数来表示:
其中,θ是模型参数,也就是回归系数,σ是sigmoid函数。实际上这个函数是由下面的对数几率(也就是x属于正类的可能性和负类的可能性的比值的对数)变换得到的:
本实施例所提供的基于位置服务的个人健康状态评估装置中,通过对获取到的用户在预设期间内的地理位置信息进行聚类分析以获取地理位置动态特征;并基于地理位置动态特征获取对应的用户健康评分;再将用户健康评分输入训练好的有监督学习模型进行处理,以获取最终的个人健康状态评估结果,此过程不受用户主观因素影响,可显著提高用户个人健康状态评估结果的客观性和准确性。而且,该基于位置服务的个人健康状态评估装置中,可基于任一用户的用户健康评分获取对应的个人健康状态评估结果,数据饱和度高、覆盖率广,能够更精准地评估用户个人健康状态,可解决现有技术中因用户得病记录缺失无法评估用户的个人健康状态的问题。
在一具体实施例中,设有10000个用户在保险机构中办理健康保险,其中30%的用户的医疗健康信息可从各大医疗机构的数据库中获取,该医疗健康信息包括但不限于体检信息;其余70%的用户未在各大医疗机构办理过相应的体检信息,无法获取其对应的医疗健康信息。保险机构通过获取10000个用户的地理位置信息;并对预设期间内任一用户的POI信息进行聚类分析后获取地理位置动态特征;再采用预设健康评分模型对地理位置动态特征进行处理,以获取10000个用户对应的用户健康评分;再将10000*30%个用户的用户健康信息和医疗健康信息输入机器学习模型,进行逻辑回归处理,以输出训练好的有监督学习模型;然后将10000*70%个用户的用户健康信息输入训练好的有监督学习模型,以获取未知医疗健康信息的用户的个人健康状态评估结果。
本实施例所提供的基于位置服务的个人健康状态评估装置,基于用户在预设期间内的地理位置信息进行处理,以获取最终的个人健康状态评估结果,此过程不受用户主观因素影响,可显著提高用户个人健康状态评估结果的客观性和准确性。而且,该基于位置服务的个人健康状态评估装置中,将同时存在用户健康评分和对应的医疗健康信息的所有数据集作为机器学习模型的训练集,通过对所有医疗健康信息和用户健康评进行逻辑回归处理,以获取训练好的有监督学习模型;再基于训练好的有监督学习模型对不存在医疗健康信息的任一用户的用户健康评分进行处理,输出对应的个人健康状态评估结果。该基于位置服务的个人健康状态评估装置的数据饱和度高、覆盖率广,能够更精准地评估用户个人健康状态,以解决现有技术中因用户得病记录缺失无法评估用户的个人健康状态的问题。
本发明是通过几个具体实施例进行说明的,本领域技术人员应当明白,在不脱离本发明范围的情况下,还可以对本发明进行各种变换和等同替代。另外,针对特定情形或具体情况,可以对本发明做各种修改,而不脱离本发明的范围。因此,本发明不局限于所公开的具体实施例,而应当包括落入本发明权利要求范围内的全部实施方式。
- 还没有人留言评论。精彩留言会获得点赞!