基于凸优化局部低秩矩阵近似的推荐系统数据补全方法与流程
本发明涉及推荐系统领域,尤其是涉及一种基于凸优化局部低秩矩阵近似的推荐系统数据补全方法。
背景技术:
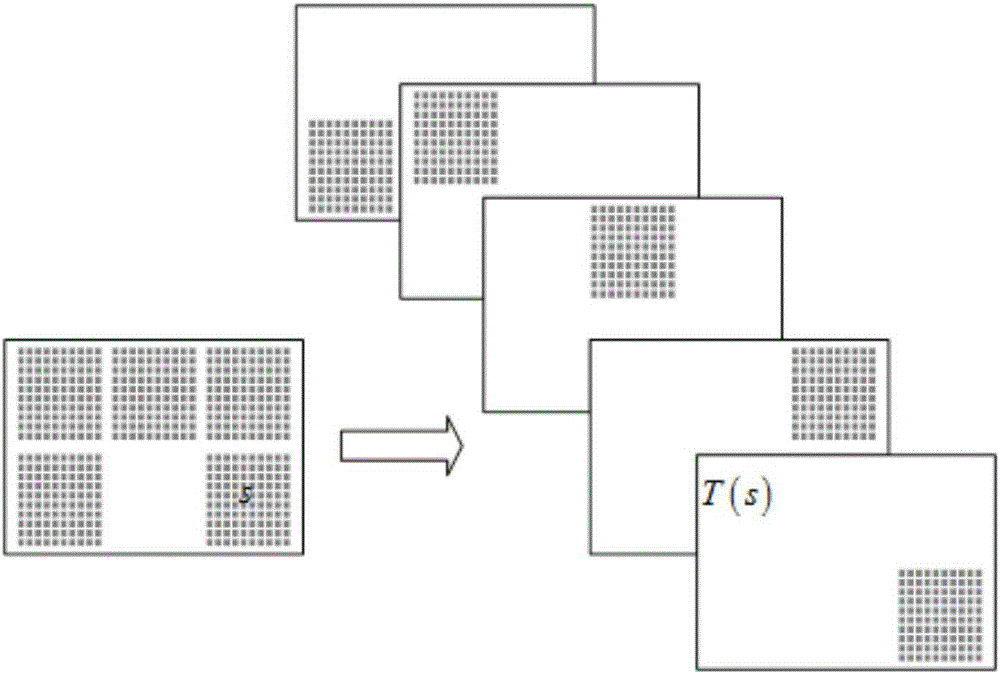
:当前,个性化推荐服务在现实中应用广泛。个性化推荐服务的主要产物就是推荐系统,推荐系统是根据用户过往的记录信息,包括购买记录、浏览记录、评分等,来分析预测用户对于其他产品的喜好程度,挖掘潜在的消费需求。推荐系统不仅有很大的学术价值,在电子商务领域更是研究的热点,许多电子商务系统通过推荐系统向用户推荐个性化信息,例如电子商务网站Amazon每年销售收入的20%—30%来自推荐系统;电影租赁网站Netflix有近60%的用户是通过推荐系统找到自己感兴趣的电影。1992年,GoWberg等人首次提出了协同过滤算法,并且建立了首个个性化推荐系统。1995年3月,有学者提出了个性化导航的WebWatcher系统,斯坦福大学的学者则提出了LIRA个性化推荐系统。1997年明尼苏达大学的研究人员创建了在线电影推荐系统MovieLens,是协同过滤推荐技术发展中一个开创性的进步,MovieLens通过利用用户对电影感兴趣的程度与协同过滤推荐技术向用户推荐其可能感兴趣且没看过的电影。2001年,纽约大学的GediminasAdoavicius等人提出了基于用户建模的电子商务推荐系统1Pro;IBM实现了基于关联规则的个性化推荐系统Webspheret。2001年,Amazon将推荐系统应用到电子商务系统中,个性化推荐开始从学术研究迈向实际应用,此后,协同过滤推荐算法获得了巨大的成功并被广泛应用到电子商务系统中。2006年,Netflix设立了NetflixPrize,要求参赛者利用其公司提供的数据集来实现一个推荐系统,使得RMSE(RootMeanSquareError)均方差误差比NetFlix系统中的RMSE提高10%,其奖金是100万美元,该比赛引起了很大的轰动,并使得众多的研究人员投身其中。2007年,Google根据用户最近搜索去挖掘用户的兴趣爱好,从而依据关键字在在线广告AdWorks中提供给用户个性化推荐服务。1999年,清华大学路海明等人提出了基于多代理技术的混合智能个性化推荐服务。2000年,北京大学余锦凤等人开始研究个性化定制服务。2001年,南京大学的潘金贵等人研发了个性化信息检索智能系统DOLTRI-AgentPW;清华大学冯韩等人设计了混合推荐系统OpenBookmarkPU,该系统混合向量空间法与协同过滤法进行推荐。2002年,上海理工大学陈世平等人设计了面向领域的智能检索系统Myspy,使用多代理技术来巧理Web文档索引数据库。2003年邓爱林等人的《基于物品评分预测的协同过滤推荐算法》;2004年余力等的《电子商务个性化推荐研究》;2007年彭玉等的《基于属性相似性的Item-based协同过滤算法》;2009年彭德巍等的《一种基于用户特征和时间的协同过滤推荐算法》这些优秀的论文代表了中国学术界在个性化技术的发展。2008年,阿里巴巴旗下的淘宝网推出了个性化推荐系统,旨在帮助用户在大量的商品中查找自己感兴趣的物品。2011年,百度推出了个性化推荐首页,根据用户的兴趣和行为向其推荐符合其需求的信息。2014年,阿里巴巴举办"天猫推荐算法大赛",掀起了国内的研究热潮。但是,近年来随着互联网和电子商务的飞速发展,用户数目和物品数目都变成了非常庞大的数字,而这两组庞大的数字结合成为更加庞大的用户-物品评分矩阵,但是,由于每个用户所能接触的物品有限,被用户打过分的只能占到少数,从而使得该用户-物品评分矩阵中的绝大部分数呈现空缺,进而使得该用户-物品评分矩阵具有较高的稀疏性,这样当数据推荐系统来预测用户对某一物品的评分时,由于用户间的评分重叠较少,通过相似用户的评分数据来为用户的某一物品预测的评分显然准确度并不高。因此,如何建立数据全面的推荐系统是有必要解决的问题。技术实现要素:本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于凸优化局部低秩矩阵近似的推荐系统数据补全方法,能够在保证运算速度与准确性的条件下,完成推荐系统矩阵数据补全。本发明的目的可以通过以下技术方案来实现:一种基于凸优化局部低秩矩阵近似的推荐系统数据补全方法,包括以下步骤:1)根据推荐系统中用户对产品的评分构建推荐系统数据矩阵M,用户对产品未评分的数据在M中以0元素表示;2)选取锚点,采用核光滑方法将所述推荐系统数据矩阵划分为若干个局部矩阵,局部矩阵的个数与所述锚点的个数相同;3)根据凸优化局部低秩矩阵近似算法求解矩阵补全模型,根据所述矩阵补全模型补全矩阵M中的0元素,得到补全之后的推荐系统数据矩阵X。所述步骤1)具体为:将推荐系统中用户对产品的评分分为五个等级,以1到5表示,等级超高表示用户对产品的喜爱程度越高,用0表示用户对产品未评分,从而形成推荐系统数据矩阵M,且M∈Rm×n,满足条件:其中,m、n表示推荐系统数据中用户个数和产品个数,即矩阵M的行列值,ПA(M)来表示M中从下标到对应数值的映射,A表示M中已知的数据,(ai,bi)表示M中的已知元素。所述步骤2)中的锚点为从训练集中均匀抽取的样本点,其中训练集来自推荐系统数据矩阵M,大小是M的50%。所述步骤2)中,核光滑方法采用的核光滑函数Kh为:Kh(s1,s2)=(1-d(s1,s2)2)1[d(s1,s2)<h]其中,h为带宽,s1、s2分别为矩阵M中的两个元素,d(s1,s2)表示元素s1,s2之间的相似性。所述步骤2)中,获得的各局部矩阵之间具有重叠。所述步骤3)中,根据凸优化局部低秩矩阵近似算法求解得到的矩阵补全模型为:s.t.XΩ=MΩ其中,q为局部矩阵个数,为求迹范数,表示第i个锚点确定的局部矩阵补全后的矩阵数据,Ω表示矩阵中已知的元素。与现有技术相比,本发明具有以下优点:(1)本发明基于局部低秩矩阵近似的方法降低了矩阵是全局低秩的假设,,基于矩阵全局低秩假设往往受限于大型矩阵,而假设矩阵是局部近似的,更符合实际情况,且更加适用于大型矩阵数据;(2)基于凸优化局部低秩矩阵近似的推荐系统数据补全方法是完全的凸优化问题,更易于求解获取最优解,提高补全矩阵的准确性;(3)本发明方法可以方便的应用在个性化推荐系统上,此外,还适用于图像恢复。附图说明图1为本发明的流程示意图;图2为本发明全局矩阵划分为多个局部矩阵的示意图。具体实施方式下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。如图1所示,本实施例提供一种基于凸优化局部低秩矩阵近似的推荐系统数据补全方法,包括以下步骤:(1)根据推荐系统中用户对产品的评分构建推荐系统数据矩阵M,具体地,将推荐系统中用户对产品的评分分为五个等级,以1到5表示,等级超高表示用户对产品的喜爱程度越高,用0表示用户对产品未评分,从而形成推荐系统数据矩阵M,且M∈Rm×n,满足条件:其中,m、n表示推荐系统数据中用户个数和产品个数,即矩阵M的行列值,∏A(M)来表示M中从下标到对应数值的映射,A表示M中已知的数据,(ai,bi)表示M中的已知元素。矩阵M中的0元素表示未知数据,是需要补全的数据。(2)选取锚点,采用核光滑方法将所述推荐系统数据矩阵划分为若干个局部矩阵,局部矩阵的个数与所述锚点的个数相同,且获得的各局部矩阵之间具有重叠。具体过程如下:201)首先选出锚点,这里有三种方法从样本中均匀的抽取锚点,第一种方法是从样本[m]×[n]中均匀的抽取锚点;第二种方法是从训练集中抽取锚点;第三种方法是从测试集上选取。本发明是采用第二种方法,并选取出q个锚点。202)确定采用的核光滑函数,常用的核光滑函数有uniformkernel、triangularkernel和Epanechnikovkernel,本发明采用的是Epanechnikovkernel,公式是:Kh(s1,s2)=(1-d(s1,s2)2)1[d(s1,s2)<h]其中,h为带宽,s1、s2分别为矩阵M中的两个元素,d(s1,s2)表示元素s1,s2之间的相似性。针对锚点的行列,具体采用的核光滑公式是:其中,(a,b)和(c,d)是矩阵M中两个元素的行列坐标,K和K′分别是行和列上的核光滑函数,h1,h2表示带宽,取h1=0.8,h2=0.8。Epanechnikovkernel公式中的d表示元素之间的相似性,例如求取用户i和用户j之间的相似性,公式是:对于q个锚点具体的坐标为(at,bt)其中t=1,...,q,分别进行如下求解:从矩阵M第1行到矩阵的第m行:计算从矩阵M第1列到矩阵的第n列:计算203)最后计算得到对应锚点的q个矩阵,划分结果如图2所示。(3)根据凸优化局部低秩矩阵近似算法求解矩阵补全模型,根据所述矩阵补全模型补全矩阵M中的0元素,得到补全之后的推荐系统数据矩阵X。根据凸优化局部低秩矩阵近似算法求解得到的矩阵补全模型为:s.t.XΩ=MΩ其中,q为局部矩阵个数,为求迹范数,表示第i个锚点确定的局部矩阵补全后的矩阵数据,Ω表示矩阵中已知的元素。上述矩阵补全模型的求解是一个凸优化问题,可以采用ADMM方法求解,从而获得补全之后的矩阵数据X。推荐系统中通常通过推荐算法的预测评分与用户的实际评分是否接近来评价算法的准确性。现在普遍使用RMSE(均方根误差)来判断预测的准确度:计算本发明实施例中通过补全后的矩阵X和原矩阵M计算RMSE的值。与当前流行的SVD算法和LLORMA算法进行比较,得到的结果如表1所示,RMSE越小代表算法的准确度越好,通过结果发现本发明实施例效果好于SVD算法和LLORMA算法,说明本发明方法矩阵补全的准确度明显优于现在比较优秀的SVD算法和LLORMA算法。表1SVDLLORMA本发明r=50.88350.86040.8580r=100.87640.84440.8385r=150.87580.83650.8333以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1