Hadoop分布式算法的WEB界面集成方法及装置与流程
本发明涉及移动通讯领域,特别涉及一种Hadoop分布式算法的WEB界面集成方法及装置。
背景技术:
Hadoop中包含了丰富的组件,Mahout是其中一个很强大的数据挖掘工具,是一个分布式机器学习算法的集合,包括:被称为Taste的分布式协同过滤的实现、分类、聚类等。Mahout最大的优点就是基于hadoop实现,把很多以前运行于单机上的算法,转化为了MapReduce模式,这样大大提升了算法可处理的数据量和处理性能,表1为在Mahout实现的机器学习算法。
表1
企业在使用开源Hadoop建设大数据平台时,在使用Hadoop分布式算法的时候,往往都需要组织熟悉Hadoop架构的软件人员开发各种Mapreduce程序,一方面这些程序的开发周期较长,另一方面这些程序运行在Linux操作系统之中,只能通过Crontab调度的方式进行简单管理。因此,需要一种简单易用的方式,帮助企业屏蔽Hadoop底层技术的复杂性,使企业的人员仅关注数据和业务,尽量减少在程序开发和算法使用方面的难度,快速达到大数据平台的建设目标。
技术实现要素:
为了帮助企业屏蔽Hadoop底层技术的复杂性,使企业的人员仅关注数据和业务,尽量减少在程序开发和算法使用方面的难度,本发明提供了一种Hadoop分布式算法的WEB界面集成方法及装置。
本发明提供的Hadoop分布式算法的WEB界面集成方法,所述WEB界面内加载有若干数据获取组件和若干数据处理组件,所述方法包括:
当某所述数据获取组件被触发后,配置该数据获取组件的输入,并选择一个或多个所述数据处理组件作为该数据获取组件的输出;
配置被选中的数据处理组件的输入,并选择其他的数据处理组件中的一个或多个作为本数据处理组件的输出,形成组件关系网;
当接收到运行指令后,利用所述组件关系网的各组件对被触发的数据获取组件的输入数据进行处理,得到数据处理结果。
本发明提供的Hadoop分布式算法的WEB界面集成装置,所述WEB界面内加载有若干数据获取组件和若干数据处理组件,包括第一配置模块、第二配置模块、及处理模块;
所述第一配置模块,用于当某所述数据获取组件被触发后,配置该数据获取组件的输入,并选择一个或多个所述数据处理组件作为该数据获取组件的输出;
所述第二配置模块,用于配置被选中的数据处理组件的输入,并选择其他的数据处理组件中的一个或多个作为本数据处理组件的输出,形成组件关系网;
所述处理模块,用于当接收到运行指令后,利用所述组件关系网的各组件对被触发的数据获取组件的输入数据进行处理,得到数据处理结果。
本发明有益效果如下:
本发明实施例提供的Hadoop分布式算法的WEB界面集成方法,在WEB界面中将选择的若干个数据获取组件和若干个数据处理组件形成组件关系网,利用所述组件关系网的各组件对被触发的数据获取组件的输入数据进行处理,无需编程,并且能够立即执行看到效果,利于探索性分析。
附图说明
图1是本发明方法实施例的Hadoop分布式算法的WEB界面集成方法的流程图;
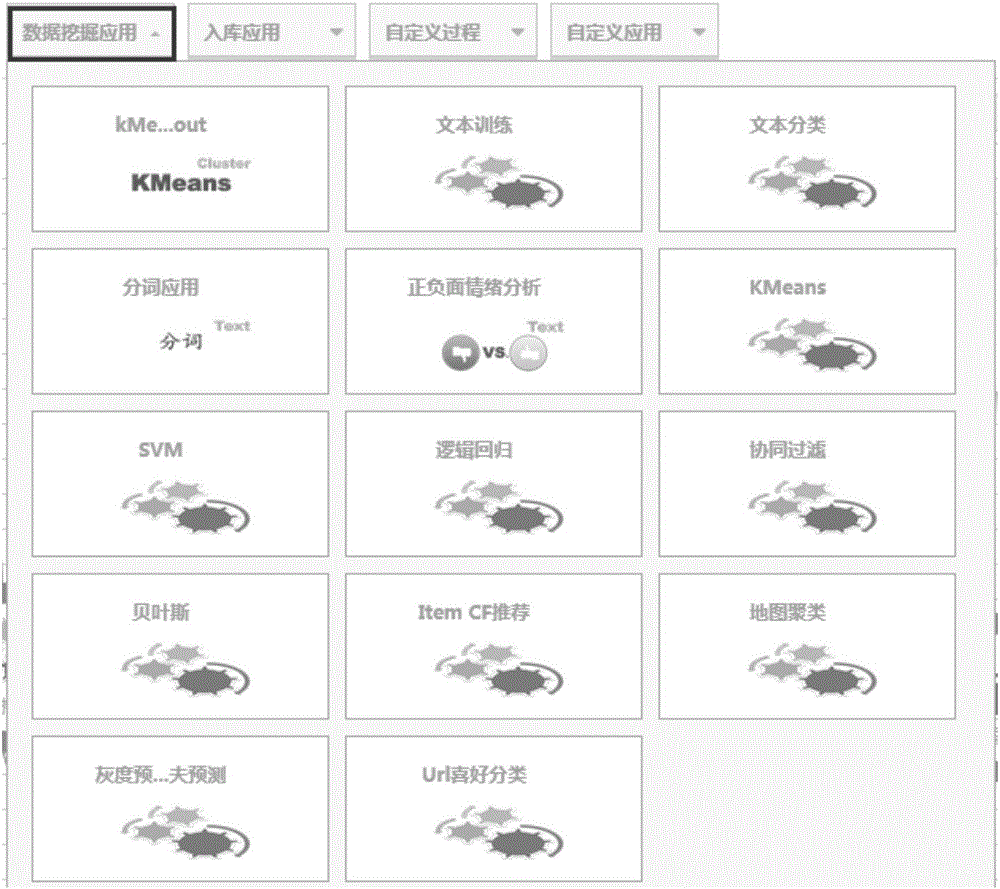
图2是数据挖掘组件的WEB界面示意图;
图3是FTP采集数据组件配置数据输入的WEB界面示意图;
图4是将FTP采集数据组件与Kmeans算法组件连接后的WEB界面示意图;
图5是Kmeans算法组件配置数据输入的WEB界面示意图;
图6是Kmeans算法组件配置数据输出的WEB界面示意图;
图7是本发明装置实施例的Hadoop分布式算法的WEB界面集成装置的结构示意图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
为了帮助企业屏蔽Hadoop底层技术的复杂性,使企业的人员仅关注数据和业务,尽量减少在程序开发和算法使用方面的难度,本发明提供了一种Hadoop分布式算法的WEB界面集成方法及装置。以下结合附图以及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不限定本发明。
根据本发明的方法实施例,提供了一种Hadoop分布式算法的WEB界面集成方法,图1是本发明方法实施例的Hadoop分布式算法的WEB界面集成方法的流程图,所述WEB界面内加载有若干数据获取组件和若干数据处理组件,如图1所示,根据本发明方法实施例的Hadoop分布式算法的WEB界面集成方法包括如下处理:
步骤101:当某所述数据获取组件被触发后,配置该数据获取组件的输入,并选择一个或多个所述数据处理组件作为该数据获取组件的输出。
具体的,本发明实施例的Hadoop分布式算法的WEB界面集成方法,还包括以下步骤:
封装与数据源有关的程序得到若干个数据获取组件;封装与数据处理有关的程序得到若干个数据处理组件。
具体的,所述数据获取组件包括FTP获取组件、MySQL获取组件、URL获取组件、HDFS数据获取组件、网盘数据获取组件等。
具体的,所述数据获取组件的输入配置包括组件的名称、周期模式等,所述数据获取组件的输出配置包括数据输出格式等。
步骤102:配置被选中的数据处理组件的输入,并选择其他的数据处理组件中的一个或多个作为本数据处理组件的输出,形成组件关系网。
具体的,所述数据处理组件包括基础工具组件、常规统计应用组件、数据挖掘应用组件、自定义过程组件、自定义应用组件、入库应用组件等。
具体的,所述数据处理组件的输入配置包括与某个具体的应用相关的配置参数等,所述数据处理组件的输出配置包括数据输出格式等。
优选的,本发明实施例的Hadoop分布式算法的WEB界面集成方法,还包括以下步骤:
通过所述WEB界面显示选择的数据获取组件的输出结果,以供用户判断和调整所述数据获取组件的输入;通过所述WEB界面显示选择的数据处理组件的输出结果,以供用户判断和调整所述数据处理组件的输入;通过所述WEB界面显示所述组件关系网。
具体的,所述形成组件关系网之前还包括以下步骤;
判断所述数据获取组件和所述数据处理组件的配置是否完整;
若所述数据获取组件和所述数据处理组件的配置完整,则形成组件关系网;
若所述数据获取组件和所述数据处理组件的配置不完整,则通过所述WEB界面显示不完整的配置项,并接收用户对不完整配置项的再次输入,直到配置完整。
步骤103:当接收到运行指令后,利用所述组件关系网的各组件对被触发的数据获取组件的输入数据进行处理,得到数据处理结果。
具体的,所述得到数据处理结果之后还包括:
接收用户输入的查看操作、编辑操作、复制操作及删除操作;其中,所述查看操作包括查看数据处理应用的数据处理周期、发布状态;所述编辑操作包括更改数据处理应用的名称、描述、及数据周期周期;所述复制操作包括复制所述数据处理结果;所述删除操作包括删除所述数据处理结果。
为了更加详细的说明本发明的方法实施例,给出一种具体的实施方式。
本发明针对Mahout在开发使用过程中的易用性,提出了纯WEB界面的解决方案,将Mahout算法封装为独立的数据挖掘组件,图2是数据挖掘组件的WEB界面示意图。
当需要使用某个组件时,先选择一个数据输入组件,如FTP采集数据的组件,配置数据输入和输出,图3是FTP采集数据组件配置数据输入的WEB界面示意图。
然后从菜单中拖拽一个Kmeans算法组件,将两个组件连接起来,使FTP获取组件的输出成为Kmeans组件的输入,图4是将FTP采集数据组件与Kmeans算法组件连接后的WEB界面示意图。
配置Kmeans算法的输入参数分组列和任务调度周期,图5是Kmeans算法组件配置数据输入的WEB界面示意图。
设置Kmeans算法的输出数据格式,图6是Kmeans算法组件配置数据输出的WEB界面示意图。
配置完成后,点击组件右侧的‘立即执行’,即可调度Hadoop的Mapreduce任务,后台自动完成任务的执行。
本发明实施例通过WEB界面的拖拽方式,无需编程,就能完成对数据进行分布式处理的功能。并且能够立即执行看到效果,利于探索性分析。
根据本发明的装置实施例,提供了一种Hadoop分布式算法的WEB界面集成装置,图7是本发明装置实施例的Hadoop分布式算法的WEB界面集成装置的结构示意图,如图7所示,根据本发明装置实施例的Hadoop分布式算法的WEB界面集成装置包括:第一配置模块70、第二配置模块72、及处理模块74,以下对本发明实施例的各个模块进行详细的说明。
具体地,所述第一配置模块70,用于当某所述数据获取组件被触发后,配置该数据获取组件的输入,并选择一个或多个所述数据处理组件作为该数据获取组件的输出;
所述第二配置模块72,用于配置被选中的数据处理组件的输入,并选择其他的数据处理组件中的一个或多个作为本数据处理组件的输出,形成组件关系网;
所述处理模块74,用于当接收到运行指令后,利用所述组件关系网的各组件对被触发的数据获取组件的输入数据进行处理,得到数据处理结果。
具体的,所述的Hadoop分布式算法的WEB界面集成装置,还包括数据获取组件封装模块和数据处理组件封装模块;
所述数据获取组件封装模块,用于封装与数据源有关的程序;
所述数据处理组件封装模块,用于封装与数据处理有关的程序。
优选的,所述WEB界面,还用于显示选择的数据获取组件的输出,以供用户判断和调整所述数据获取组件的输入;显示选择的数据处理组件的输出,以供用户判断和调整所述数据处理组件的输入;显示所述组件关系网。
具体的,所述的Hadoop分布式算法的WEB界面集成装置,还包括判断模块:所述判断模块,用于判断所述数据获取组件和所述数据处理组件的配置是否完整;若所述数据获取组件和所述数据处理组件的配置完整,则形成组件关系网;若所述数据获取组件和所述数据处理组件的配置不完整,将不完整的配置项输出至WEB界面。
具体的,所述WEB界面,还用于接收用户输入的查看操作、编辑操作、复制操作及删除操作;其中,所述查看操作包括查看数据处理应用的数据处理周期、发布状态;所述编辑操作包括更改数据处理应用的名称、描述、数据周期周期;所述复制操作包括复制所述数据处理结果;所述删除操作包括删除所述数据处理结果。
以上所述仅为本发明的实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!