一种监控系统及方法与流程
本发明涉及服务器监控领域,尤其涉及一种监控系统及方法。
背景技术:
近年,伴随着应用软件系统体系膨胀,架构的扩展,软件体系已经越来越难以把控,软件运行过程中出现的问题也越来越复杂,难以解决,而一些时延要求高的内容,甚至会因为数据的丢失造成不必要的经济损失,这就要提前监控系统,监控系统的全流程,做到无缝监控,并同时可以监控多个系统。
目前的系统监控多是用shell脚本的形式,去监控系统运行状况的CPU、内存、网络、无效链接、运行日志等,一般都是单台设备监控;或者是将系统的日志存入数据库中,然后系统再对各个节点的日志进行分析。这样的方式比较简单,一般设备较少时采用,而且监控的内容也十分有限,而且监控内容一般不做更进一步存储、分析,对系统的进一步建设,指导意义有限。在新的项目做监控的时候,还需要针对特例重新开发,无法通过配置,实现复用。
技术实现要素:
本发明的目的在于,解决现有的服务器监控技术领域中无法同时对多台服务器进行监控,并且对新的项目做监控时需要重新开发监控系统而无法实现复用的问题,提供了一种监控系统及方法。
为了实现上述目的,一方面,本发明提供了一种监控系统。该监控系统包括监控装置和一台或多台服务器;监控装置包括:接收模块、存储模块和分析模块;一台或多台服务器中的任一台服务器包括数据搜集客户端;接收模块,用于接收由数据搜集客户端收集的服务器日志数据,日志数据包括服务器的运行参数、中间运行日志和应用日志;存储模块,用于依据模型库的配置确定日志数据的存储方式,并根据存储方式对日志数据进行存储;分析模块,用于根据日志数据的存储方式从模型库中选择相应类型的模型,并根据相应类型的模型对存储后的日志数据进行分析;监控者基于日志数据的分析结果进行监控。
优选地,数据搜集客户端采用单项传输机制将搜集的服务器日志数据传输给监控装置。
优选地,存储模块具体用于:依据模型库的配置确定日志数据的存储方式为File类型,并根据File类型对日志数据进行存储;和/或
依据模型库的配置确定日志数据的存储方式为Hdfs类型,并根据Hdfs类型对日志数据进行存储;和/或
依据模型库的配置确定日志数据的存储方式为Redis类型,并根据Redis类型对日志数据进行存储。
优选地,分析模块具体用于:根据日志数据的存储方式为File类型从模型库中选择数据库类型的模型,并根据数据库类型的模型对存储后的日志数据进行分析;根据日志数据的存储方式为Hdfs类型从模型库中选择大数据类型的模型,并根据大数据类型的模型对存储后的日志数据进行分析;根据日志数据的存储方式为Redis类型从模型库中选择内存计算类型的模型,并根据内存计算类型的模型对存储后的日志数据进行分析;监控者基于日志数据的分析结果进行监控。
优选地,监控装置还包括预先建立的模型库。
另一方面,本发明还提供了一种监控方法。该方法包括步骤:接收由数据搜集客户端搜集的服务器日志数据,日志数据包括服务器的运行参数、中间运行日志和应用日志;依据模型库的配置确定日志数据的存储方式,并根据存储方式对日志数据进行存储;根据日志数据的存储方式从模型库中选择相应类型的模型,并根据相应类型的模型对存储后的日志数据进行分析;监控者基于日志数据的分析结果进行监控。
优选地,数据搜集客户端采用单项传输机制对搜集的服务器日志数据进行传输。
优选地,依据模型库的配置确定日志数据的存储方式,并根据存储方式对日志数据进行存储步骤具体包括:依据模型库的配置确定日志数据的存储方式为File类型,并根据File类型对日志数据进行存储;和/或
依据模型库的配置确定日志数据的存储方式为Hdfs类型,并根据Hdfs类型对日志数据进行存储;和/或
依据模型库的配置确定日志数据的存储方式为Redis类型,并根据Redis类型对日志数据进行存储。
优选地,根据日志数据的存储方式从模型库中选择相应类型的模型,并根据相应类型的模型对存储后的日志数据进行分析步骤具体包括:根据日志数据的存储方式为File类型从模型库中选择数据库类型的模型,并根据数据库类型的模型对存储后的日志数据进行分析;根据日志数据的存储方式为Hdfs类型从模型库中选择大数据类型的模型,并根据大数据类型的模型对存储后的日志数据进行分析;根据日志数据的存储方式为Redis类型从模型库中选择内存计算类型的模型,并根据内存计算类型的模型对存储后的日志数据进行分析。
优选地,还包括预先建立模型库。
本发明提供的一种监控系统及方法,可以采集并处理多个服务器上的数据,可以在新的项目上进行复用,实现对多个服务器和多个项目进行集中监控。
附图说明
图1为本发明实施例提供的一种监控系统的结构示意图;
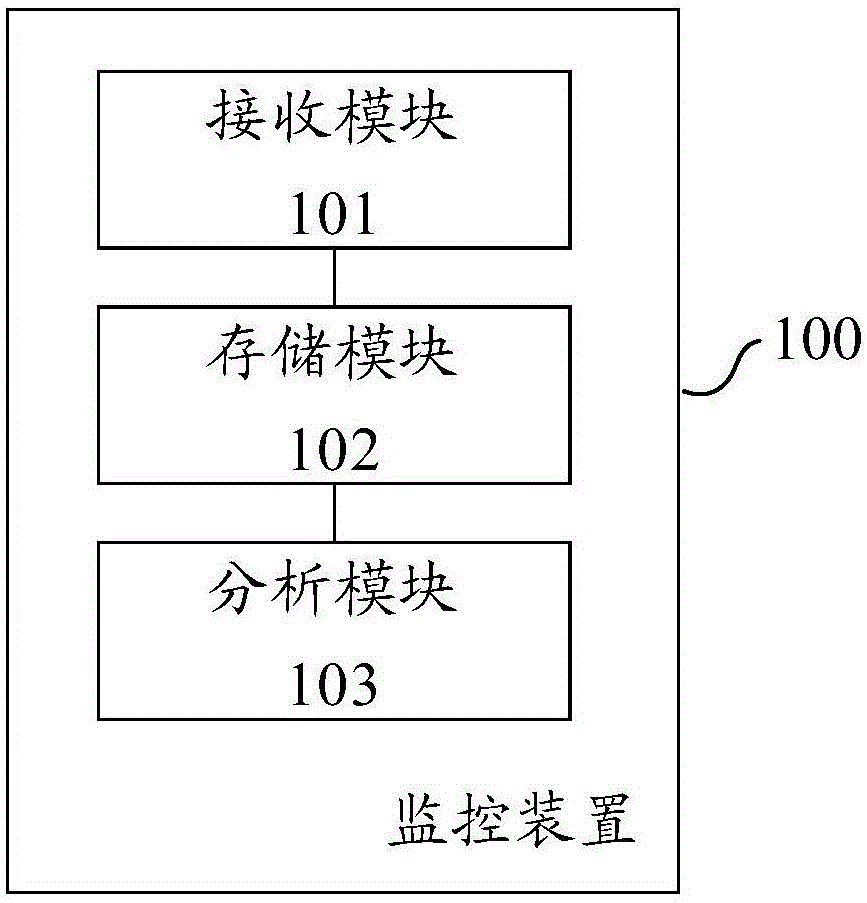
图2为图1中监控装置的结构示意图;
图3为图2中分析模块采用的模型库中各类型的模型配置流程示意图,包括图3a、图3b和图3c:
图3a为模型库中数据库类型的模型配置流程示意图,
图3b为模型库中大数据类型的模型配置流程示意图,
图3c为模型库中内存计算类型的模型配置流程示意图;
图4为本发明实施例提供的一种监控方法的流程示意图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细、清楚、完整的说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
图1为本发明实施例提供的一种监控系统的结构示意图。如图1所示,该监控系统包括监控装置100和服务器1,服务器2,…,服务器n(n为正整数),即一台或多台服务器。一台或多台服务器中的任一台服务器都包括数据搜集客户端。
图2为图1中监控装置的结构示意图。如图2所示,该监控装置100包括:接收模块101、存储模块102和分析模块103。
接收模块101用于接收由数据搜集客户端收集的服务器日志数据。数据搜集客户端收集的服务器日志数据包括服务器的运行参数、中间运行日志和应用日志。其中,服务器运行参数包括CPU、内存和网络参数以及无效链接等;中间运行日志包括中间件中各容器参数,堆栈参数、数据库连接参数等;应用日志包括各种操作执行的成功、失败情况,或者用户注册、登录及其他情况的异常。数据搜集客户端对服务器数据可以根据模型库的配置,只搜集经存储后可以输入模型库中的模型进行分析的数据,以减少资源的占用,避免影响服务器的性能。并采用单项传输机制将搜集的服务器日志数据传输给监控装置,因单项传输无需进行心跳检测,从而可以减少对网络的占用。
例如,在每台服务器上安装的数据搜集客户端为Scribe客户端。Scribe客户端可以对任意数量的服务器的日志数据进行分布式搜集,当需要搜集对新的服务器的日志数据时,通过安装Scribe客户端即可进行扩展。而且通过Scribe客户端进行传输可以实现高容错,当存储模块的网络或者机器出现故障时,Scribe客户端会将日志转存到本地或者另一个位置,当Scribe服务器恢复后,Scribe客户端会将转存的日志重新传输给存储模块。此外,Scribe客户端对服务器日志数据的搜集不是采用抓取方式,而是采用Push方式,对CPU的占用极低。
存储模块102用于依据模型库的配置确定日志数据的存储方式,并根据存储方式对日志数据进行存储。
依据模型库的配置确定日志数据的存储方式为File类型,并根据File类型对日志数据进行存储,以将其加载至各种数据仓库中,进行数据汇聚。依据模型库的配置确定日志数据的存储方式为Hdfs类型,并根据Hdfs类型对日志数据进行存储,以将其导入大数据平台,并采用大数据处理的方式对数据进行离线处理或者实时处理。依据模型库的配置确定日志数据的存储方式为Redis类型,并根据Redis类型对日志数据进行存储,在数据量较小时,直接把日志数据加载至Rddis服务器,以便于其它程序进行访问和进行内存计算。
该监控系统还包括预先建立的模型库。图3为图2中分析模块采用的模型库中各类型的模型配置流程示意图。如图3a所示,数据库类型模型的配置包括步骤201-203:
步骤201,从ORACLE、MYSQL等多种类型的数据库中,导入数据库数据源、数据处理分层结构、各层处理过程和结果存储位置等。数据分层后各层的数据结果可作为下一层数据处理的数据源头,处理的结果将被保存于结果存储位置中的指定位置。通过基于原子操作的基础设置可以将数据库类型模型的算法解析成不同的可执行SQL,对模型而言具体的数据库类型不影响分析结果。
步骤202,校验步骤201中的数据库类型模型的配置是否符合规范,以用于进一步的触发执行,如果不符合规范,则继续配置。
步骤203,为配置符合规范的数据库类型模型配置触发条件,即指某一个时间点对库中数据进行处理,将处理后的数据达到阈值的数据进行输出。并打开执行开关。
如图3b所示,大数据类型模型的配置包括步骤301-303:
步骤301,导入Hdfs数据源,即采用Hdfs方式存储的日志数据;导入预先准备的数据处理脚本或者java多线程运行程序,以及结果存储位置等,可以实现离线处理或者在线实时处理。其中,处理脚本和java多线程运行程序均可以运行在Hadoop、Strom等数据平台,并且java多线程运行程序相较于处理脚本,在借助数据平台进行大规模的数据处理具有更高的扩展性,处理的结果将被保存于结果存储位置中的指定位置。
步骤302,校验步骤301中的大数据类型模型的配置是否符合规范,以用于进一步的触发执行,如果不符合规范,则继续配置。
步骤303,为配置符合规范的大数据类型模型配置触发条件,即对大数据平台中数据按照shell脚本或者java程序进行实时或者定时处理后,进行输出。并打开执行开关。
如图3c所示,内存计算类型模型的配置包括步骤401-403:
步骤401,导入集群数据接口,导入数据处理java代码和结果存储位置等。java平台在软件开发中具有高扩展性,利用java代码可以灵活的对Redis集群中的数据进行处理,处理的结果将被保存于结果存储位置中的指定位置。
步骤402,校验步骤401中的内存计算类型模型的配置是否符合规范,以用于进一步的触发执行,如果不符合规范,则继续配置。
步骤403,为配置符合规范的内存计算类型模型配置触发条件,即处理后的数据达到对应阈值的数据,进行输出。并打开执行开关。
用户可以根据需要采用同一种存储方式对所有日志数据进行存储,也可以采用多种存储方式对相同的日志数据进行存储。不同的分析模型可以得到不同导向的分析结果,包括运行综合指数、服务器运行平稳度、项目优化导向等。运行综合指数是通过数据分析后得到的系统运行的指标的综合指数,运行平稳度是指根据历史数据,获取当前指标的方差,从而反映运行平稳度。优化向导是根据历史数据和当前综合指数生成,比如单位时间里,应该优化的指标。基于同一日志数据的不同导向的分析结果,还可以进一步分析出各个导向分析结果之间的关联关系。
分析模块103用于根据日志数据的存储方式从模型库中选择相应类型的模型,并根据相应类型的模型对存储后的日志数据进行分析;监控者基于日志数据的分析结果进行监控。
具体地,根据日志数据的存储方式为File类型从模型库中选择数据库类型的模型,并根据数据库类型的模型对存储后的日志数据进行分析;根据日志数据的存储方式为Hdfs类型从模型库中选择大数据类型的模型,并根据大数据类型的模型对存储后的日志数据进行分析;根据日志数据的存储方式为Redis类型从模型库中选择内存计算类型的模型,并根据内存计算类型的模型对存储后的日志数据进行分析;监控者基于日志数据的分析结果进行监控。
例如,根据日志数据的存储方式为File类型从模型库中选择并触发数据库类型的模型,将File类型的日志数据输入数据库类型的模型中以得到分析结果。根据日志数据的存储方式为Hdfs类型从模型库中选择并触发大数据类型的模型,将Hdfs类型的日志数据输入大数据类型的模型中以得到分析结果。根据日志数据的存储方式为Redis类型从模型库中选择并触发内存计算类型的模型,将Redis类型的日志数据输入内存计算类型的模型中以得到分析结果。监控者基于日志数据的分析结果进行监控。
监控装置还可以包括推送模块,推送模块用于将分析结果制作成报表并设定优先级,根据优先级将报表形式的分析结果以短信或者邮件的方式推送给监控者,以便于监控者根据分析结果进行监控,也可以将分析结果保存在预置数据库中,以便于监控者根据权限随时取用。
本发明实施例提供的一种监控系统,可以采集并处理多个服务器上的数据,可以在新的项目上进行复用,实现对多个服务器和多个项目进行集中监控。
图4为本发明实施例提供的一种监控方法的流程示意图。如图4所示,该方法包括步骤501-503:
步骤501,接收由数据搜集客户端搜集的服务器日志数据,日志数据包括服务器的运行参数、中间运行日志和应用日志。
其中,数据搜集客户端可以采用单项传输机制对搜集的服务器日志数据进行传输,数据搜集客户端可以为Scribe客户端。
步骤502,依据模型库的配置确定日志数据的存储方式,并根据存储方式对日志数据进行存储;
具体地,依据模型库的配置确定日志数据的存储方式为File类型,并根据File类型对日志数据进行存储;和/或依据模型库的配置确定日志数据的存储方式为Hdfs类型,并根据Hdfs类型对日志数据进行存储;和/或依据模型库的配置确定日志数据的存储方式为Redis类型,并根据Redis类型对日志数据进行存储。
步骤503,根据日志数据的存储方式从模型库中选择相应类型的模型,并根据相应类型的模型对存储后的日志数据进行分析;监控者基于日志数据的分析结果进行监控。
具体地,根据日志数据的存储方式为File类型从模型库中选择数据库类型的模型,并根据数据库类型的模型对存储后的日志数据进行分析。根据日志数据的存储方式为Hdfs类型从模型库中选择大数据类型的模型,并根据大数据类型的模型对存储后的日志数据进行分析。根据日志数据的存储方式为Redis类型从模型库中选择内存计算类型的模型,并根据内存计算类型的模型对存储后的日志数据进行分析。
本发明实施例中的方法与前述系统相对应,在此不进行赘述。
本发明实施例提供的一种监控方法,可以采集并处理多个服务器上的数据,可以在新的项目上进行复用,实现对多个服务器和多个项目进行集中监控。
以上的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!